




问题现象
事情是这样的,各位看官且看之,中秋国庆期间测试机房由于线路变更需要断电,故需要关掉所以测试机器,等待变更完成后,测试环境的 RAC 有一个节点数据库启动不了,检查发现节点 2 的 ARCH 磁盘没有正常挂载。

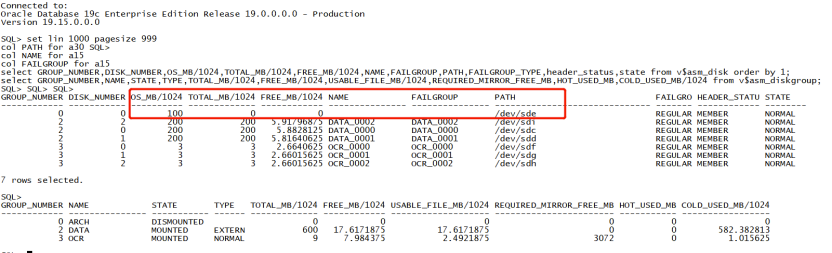
登录到 ASM 实例,查看 ASM 磁盘及路径发现归档盘 ARCH 没挂载,磁盘路径为 ‘/dev/sde’。
su - grid sqlplus / as sysasm Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.15.0.0.0 SQL> set lin 1000 pagesize 999 col PATH for a30 col NAME for a15 col FAILGROUP for a15 select GROUP_NUMBER,DISK_NUMBER,OS_MB/1024,TOTAL_MB/1024,FREE_MB/1024,NAME,FAILGROUP,PATH,FAILGROUP_TYPE,header_status,state from v$asm_disk order by 1; select GROUP_NUMBER,NAME,STATE,TYPE,TOTAL_MB/1024,FREE_MB/1024,USABLE_FILE_MB/1024,REQUIRED_MIRROR_FREE_MB,HOT_USED_MB,COLD_USED_MB/1024 from v$asm_diskgroup; SQL> SQL> SQL> GROUP_NUMBER DISK_NUMBER OS_MB/1024 TOTAL_MB/1024 FREE_MB/1024 NAME FAILGROUP PATH FAILGRO HEADER_STATU STATE ------------ ----------- ---------- ------------- ------------ --------------- --------------- ------------------------------ ------- ------------ -------- 0 0 100 0 0 /dev/sde REGULAR MEMBER NORMAL 2 2 200 200 5.91796875 DATA_0002 DATA_0002 /dev/sdi REGULAR MEMBER NORMAL 2 0 200 200 5.8828125 DATA_0000 DATA_0000 /dev/sdc REGULAR MEMBER NORMAL 2 1 200 200 5.81640625 DATA_0001 DATA_0001 /dev/sdd REGULAR MEMBER NORMAL 3 0 3 3 2.6640625 OCR_0000 OCR_0000 /dev/sdf REGULAR MEMBER NORMAL 3 1 3 3 2.66015625 OCR_0001 OCR_0001 /dev/sdg REGULAR MEMBER NORMAL 3 2 3 3 2.66015625 OCR_0002 OCR_0002 /dev/sdh REGULAR MEMBER NORMAL 7 rows selected. SQL> GROUP_NUMBER NAME STATE TYPE TOTAL_MB/1024 FREE_MB/1024 USABLE_FILE_MB/1024 REQUIRED_MIRROR_FREE_MB HOT_USED_MB COLD_USED_MB/1024 ------------ --------------- ----------- ------ ------------- ------------ ------------------- ----------------------- ----------- ----------------- 0 ARCH DISMOUNTED 0 0 0 0 0 0 2 DATA MOUNTED EXTERN 600 17.6171875 17.6171875 0 0 582.382813 3 OCR MOUNTED NORMAL 9 7.984375 2.4921875 3072 0 1.015625复制
然后通过操作系统层 lsblk 命令查看 /dev/sde 大小 100G,然后通过 ASM 命令挂载 ARCH 磁盘却不成功,报错丢失磁盘。
[root@jiekexu2 dev]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 200G 0 disk |-sda1 8:1 0 1G 0 part /boot `-sda2 8:2 0 199G 0 part |-rootvg-lvroot 253:0 0 191.1G 0 lvm / `-rootvg-lvswap 253:1 0 15.9G 0 lvm [SWAP] sdb 8:16 0 8G 0 disk `-rootvg-lvswap 253:1 0 15.9G 0 lvm [SWAP] sdc 8:32 0 200G 0 disk sdd 8:48 0 200G 0 disk sde 8:64 0 100G 0 disk sdf 8:80 0 3G 0 disk sdg 8:96 0 3G 0 disk sdh 8:112 0 3G 0 disk sdi 8:128 0 200G 0 disk sdj 8:144 0 100G 0 disk sdk 8:160 0 200G 0 disk sr0 11:0 1 1024M 0 rom jiekexu2:/home/grid(+ASM2)$ asmcmd ASMCMD> mount ARCH ORA-15032: not all alterations performed ORA-15040: diskgroup is incomplete ORA-15042: ASM disk "1" is missing from group number "1" (DBD ERROR: OCIStmtExecute) ASMCMD> exit复制
下面我们通过 ASM 实例的 alter 日志,切实看到 ARCH 盘有两块磁盘,一块是 (/dev/sde),另一块则为空()看不到。那么我们来看看节点 1 的 ARCH 磁盘及相关权限吧。
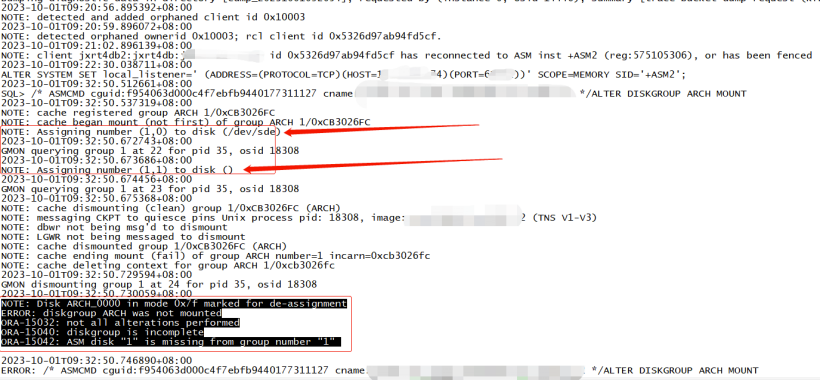
节点 1/2 权限对比
通过节点 1 发现 ARCH 磁盘组有两块磁盘(/dev/sde)和(/dev/sdj),属组则为 grid:asmadmin,但是节点 2 (/dev/sde)权限属组正常,(/dev/sdj)属组为 root:disk,这显然是有问题的,正因为这里的属组权限不对,上面最开始查看磁盘 ARCH 盘时仅显示一块(/dev/sde)。
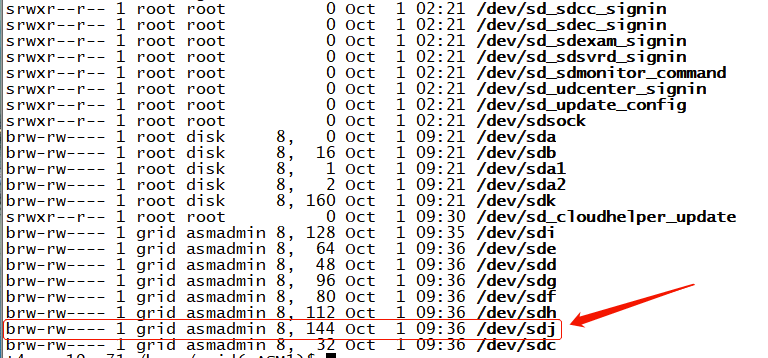
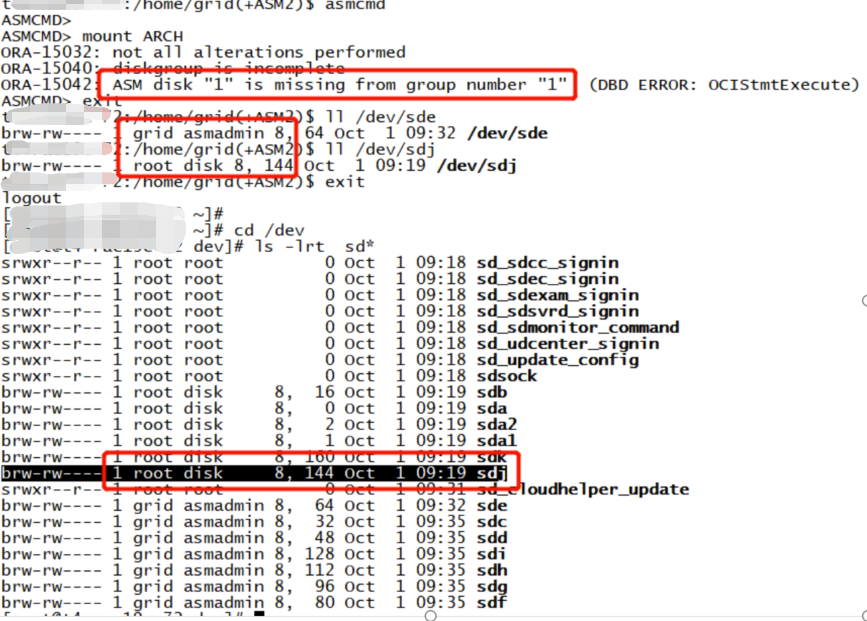
解决问题
下面检查一下 udev 配置文件是否出现问题,然后我们修改(/dev/sdj)属组为 grid:asmadmin,并重新触发 udev 规则,然后再尝试去挂载磁盘组。
jiekexu2:/home/grid(+ASM2)$ more /etc/udev/rules.d/99-oracle-asmdisks.rules KERNEL=="sd*", ACTION=="add|change", SUBSYSTEM=="block", PROGRAM=="/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c29bd4635c80a3011779bc1a7f99", SYMLINK+="asmdisks/asmdiskb", OWNER= "grid", GROUP="asmadmin", MODE="0660" KERNEL=="sd*", ACTION=="add|change", SUBSYSTEM=="block", PROGRAM=="/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c2947f3b25a26a2bd31496cd2f59", SYMLINK+="asmdisks/asmdiskc", OWNER= "grid", GROUP="asmadmin", MODE="0660" KERNEL=="sd*", ACTION=="add|change", SUBSYSTEM=="block", PROGRAM=="/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c29ad3307c8874aaeb6b5c83f2f8", SYMLINK+="asmdisks/asmdiskd", OWNER= "grid", GROUP="asmadmin", MODE="0660" KERNEL=="sd*", ACTION=="add|change", SUBSYSTEM=="block", PROGRAM=="/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c29756eabbaea24471e77a46d1bf", SYMLINK+="asmdisks/asmdiske", OWNER= "grid", GROUP="asmadmin", MODE="0660" KERNEL=="sd*", ACTION=="add|change", SUBSYSTEM=="block", PROGRAM=="/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c296f7ef4f660d24ecdc32fd5216", SYMLINK+="asmdisks/asmdiskf", OWNER= "grid", GROUP="asmadmin", MODE="0660" KERNEL=="sd*", ACTION=="add|change", SUBSYSTEM=="block", PROGRAM=="/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c29ef6de29e246eec5d21ae13f74", SYMLINK+="asmdisks/asmdiskg", OWNER= "grid", GROUP="asmadmin", MODE="0660" KERNEL=="sd*", ACTION=="add|change", SUBSYSTEM=="block", PROGRAM=="/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c2995925bb888b965036ad9d9807", SYMLINK+="asmdisks/asmdiski", OWNER= "grid", GROUP="asmadmin", MODE="0660" KERNEL=="sd*", ACTION=="add|change", SUBSYSTEM=="block", PROGRAM=="/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c294342f0d7dd282c4a632d82c47", SYMLINK+="asmdisks/asmdiskj", OWNER= "grid", GROUP="asmadmin", MODE="0660" jiekexu2:/home/grid(+ASM2)$ ll /dev/sde brw-rw---- 1 grid asmadmin 8, 64 Oct 1 09:46 /dev/sde jiekexu2:/home/grid(+ASM2)$ ll /dev/sdj brw-rw---- 1 root disk 8, 144 Oct 1 09:19 /dev/sdj jiekexu2:/home/grid(+ASM2)$ exit logout [root@jiekexu2 ~]# udevadm control --reload-rules [root@jiekexu2 ~]# ll /dev/sdj brw-rw---- 1 root disk 8, 144 Oct 1 09:19 /dev/sdj [root@jiekexu2 ~]# ll /dev/sde brw-rw---- 1 grid asmadmin 8, 64 Oct 1 09:46 /dev/sde [root@jiekexu2 ~]# udevadm trigger [root@jiekexu2 ~]# ll /dev/sdj brw-rw---- 1 root disk 8, 144 Oct 1 09:50 /dev/sdj [root@jiekexu2 ~]# ll /dev/sde brw-rw---- 1 grid asmadmin 8, 64 Oct 1 09:50 /dev/sde [root@jiekexu2 ~]# chown grid:asmadmin /dev/sdj [root@jiekexu2 ~]# ll /dev/sdj brw-rw---- 1 grid asmadmin 8, 144 Oct 1 09:50 /dev/sdj复制
接下来我们则登录 ASM 实例,查看磁盘路径可以正常显示 sdj 和 sde,也可以正常挂载 ARCH。
su - grid sqlplus / as sysasm alter diskgroup ARCH mount;复制
登录数据库发现数据库实例已经自启动了。
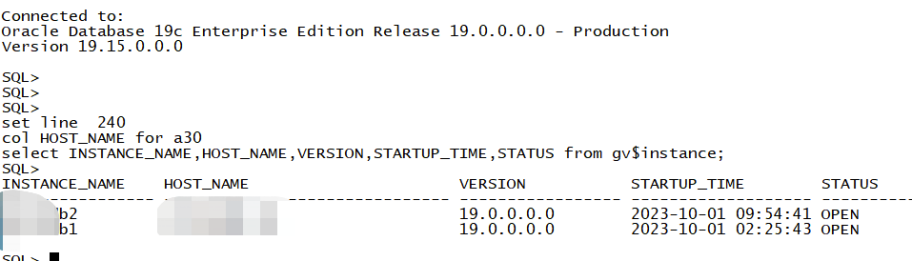
另外一套 RAC 也是节点 2 数据库无法启动,DATA 磁盘组无法正常挂载。经查看 ASM 实例日志也是 DATA 磁盘组缺失一块磁盘,缺失的磁盘权限也变成 root:disk,如法炮制,修改属组重新挂载即可恢复正常。
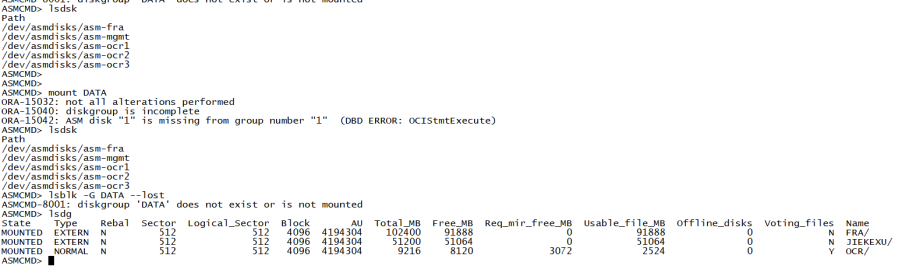
2023-10-01T09:18:17.259212+08:00 ERROR: /* ASMCMD cguid:cae29900570ecf7ebfd17fbf776d2840 cname:jieke-rac-scan nodename:jieke-rac-87 */ALTER DISKGROUP data MOUNT 2023-10-01T09:18:17.650518+08:00 ASM Health Checker found 1 new failures 2023-10-01T10:21:30.690039+08:00 SQL> /* ASMCMD cguid:cae29900570ecf7ebfd17fbf776d2840 cname:jieke-rac-scan nodename:jieke-rac-87 */ALTER DISKGROUP DATA MOUNT 2023-10-01T10:21:30.795687+08:00 NOTE: cache registered group DATA 1/0x36302669 NOTE: cache began mount (not first) of group DATA 1/0x36302669 NOTE: Assigning number (1,0) to disk (/dev/asmdisks/asm-data) 2023-10-01T10:21:31.238030+08:00 GMON querying group 1 at 38 for pid 37, osid 59371 2023-10-01T10:21:31.269748+08:00 NOTE: Assigning number (1,1) to disk () 2023-10-01T10:21:31.285726+08:00 GMON querying group 1 at 39 for pid 37, osid 59371 2023-10-01T10:21:31.286854+08:00 NOTE: cache dismounting (clean) group 1/0x36302669 (DATA) NOTE: messaging CKPT to quiesce pins Unix process pid: 59371, image: oracle@jieke-rac-87 (TNS V1-V3) NOTE: dbwr not being msg'd to dismount NOTE: LGWR not being messaged to dismount NOTE: cache dismounted group 1/0x36302669 (DATA) NOTE: cache ending mount (fail) of group DATA number=1 incarn=0x36302669 NOTE: cache deleting context for group DATA 1/0x36302669 2023-10-01T10:21:31.386823+08:00 GMON dismounting group 1 at 40 for pid 37, osid 59371 2023-10-01T10:21:31.387863+08:00 NOTE: Disk DATA_0000 in mode 0x7f marked for de-assignment ERROR: diskgroup DATA was not mounted ORA-15032: not all alterations performed ORA-15040: diskgroup is incomplete ORA-15042: ASM disk "1" is missing from group number "1"复制
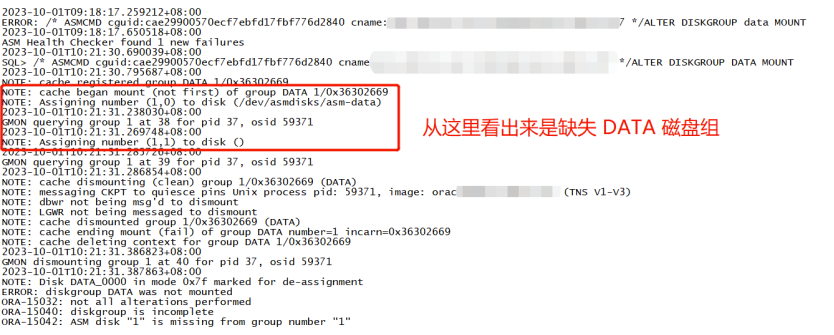
SQL> set lin 1000 pagesize 999 col PATH for a30 col NAME for a15 col FAILGROUP for a15 select GROUP_NUMBER,DISK_NUMBER,OS_MB/1024,TOTAL_MB/1024,FREE_MB/1024,NAME,FAILGROUP,PATH,FAILGROUP_TYPE,header_status,state from v$asm_disk order by 1; select GROUP_NUMBER,NAME,STATE,TYPE,TOTAL_MB/1024,FREE_MB/1024,USABLE_FILE_MB/1024,REQUIRED_MIRROR_FREE_MB,HOT_USED_MB,COLD_USED_MB/1024 from v$asm_diskgroup; SQL> SQL> SQL> GROUP_NUMBER DISK_NUMBER OS_MB/1024 TOTAL_MB/1024 FREE_MB/1024 NAME FAILGROUP PATH FAILGRO HEADER_STATU STATE ------------ ----------- ---------- ------------- ------------ --------------- --------------- ------------------------------ ------- ------------ -------- 1 0 300 300 100.4375 DATA_0000 DATA_0000 /dev/asmdisks/asm-data REGULAR MEMBER NORMAL 1 1 300 300 100.449219 DATA_0001 DATA_0001 /dev/asmdisks/asm-data01 REGULAR MEMBER NORMAL 2 0 100 100 89.7578125 FRA_0000 FRA_0000 /dev/asmdisks/asm-fra REGULAR MEMBER NORMAL 3 0 50 50 49.8671875 TEST_0000 TEST_0000 /dev/asmdisks/asm-mgmt REGULAR MEMBER NORMAL 5 3 3 3 2.6484375 OCR_0003 OCR_0003 /dev/asmdisks/asm-ocr3 REGULAR MEMBER NORMAL 5 2 3 3 2.63671875 OCR_0002 OCR_0002 /dev/asmdisks/asm-ocr1 REGULAR MEMBER NORMAL 5 1 3 3 2.64453125 OCR_0001 OCR_0001 /dev/asmdisks/asm-ocr2 REGULAR MEMBER NORMAL 7 rows selected. SQL> GROUP_NUMBER NAME STATE TYPE TOTAL_MB/1024 FREE_MB/1024 USABLE_FILE_MB/1024 REQUIRED_MIRROR_FREE_MB HOT_USED_MB COLD_USED_MB/1024 ------------ --------------- ----------- ------ ------------- ------------ ------------------- ----------------------- ----------- ----------------- 1 DATA MOUNTED EXTERN 600 200.886719 200.886719 0 0 399.113281 2 FRA MOUNTED EXTERN 100 89.7578125 89.7578125 0 0 10.2421875 3 JIEKEXU MOUNTED EXTERN 50 49.8671875 49.8671875 0 0 .1328125 5 OCR MOUNTED NORMAL 9 7.9296875 2.46484375 3072 0 1.0703125复制
国庆放假回来后,对节点 2 进行了重启,重启后发现磁盘属组又变回了 root:disk,这两套 RAC 关机重启导致共享磁盘属组发生变化,发现一个共同的点就是变化的磁盘均是最后一块盘(ARCH_0001 和 DATA_0001),而这最后一块盘是后期添加的,那么可能出问题的就是 udev 配置文件了,但是上次通过在 CRT 中的 more 命令查看没有问题,这次用 vi 打开发现最后一行是有换行,“OWNER=” 后面出现了换行,另一套也是最后一行出现了换行,使用 xshell 打开如下图所示:

将其换行删除,然后重载 udev 规则就可以了。
# vi /etc/udev/rules.d/99-oracle-asmdisks.rules # udevadm control --reload-rules # udevadm trigger复制
DROPPED 状态的磁盘
几个月前的一天,突然发现此 RAC 有一块 OCR 盘出现故障,状态变为 FORCING ,磁盘 name 则以下划线命名 _DROPPED_0000_OCR ,查看 ASM 和集群日志均没有发现异常的地方。查看 CRS 集群和数据库均是正常状态,也可以正常启动关闭集群,但就是这块盘的状态是异常的。查询信息如下图所示:
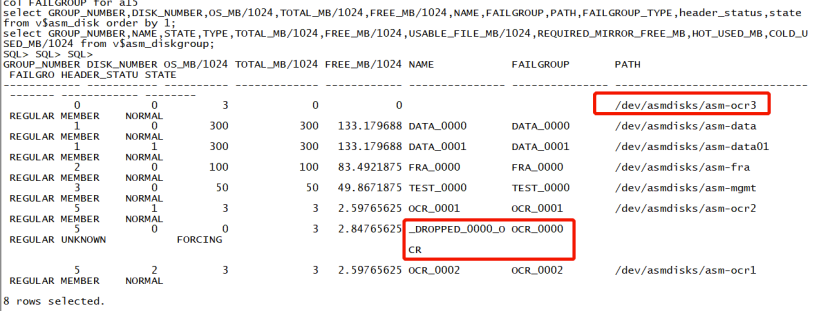
解决办法
使用 lsblk 查看 sdg sdh sdi 三块 3G 的磁盘及对应的权限没有问题。
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 100G 0 disk |-sda1 8:1 0 1G 0 part /boot `-sda2 8:2 0 99G 0 part |-rootvg-lvroot 253:0 0 91.1G 0 lvm / `-rootvg-lvswap 253:1 0 7.9G 0 lvm [SWAP] sdb 8:16 0 100G 0 disk `-u01vg-lvu01 253:2 0 100G 0 lvm /u01 sdc 8:32 0 50G 0 disk sdd 8:48 0 300G 0 disk sde 8:64 0 100G 0 disk sdf 8:80 0 50G 0 disk sdg 8:96 0 3G 0 disk sdh 8:112 0 3G 0 disk sdi 8:128 0 3G 0 disk sdj 8:144 0 300G 0 disk sr0 11:0 1 1024M 0 rom [root@jiekexu-rac1 /]# ll /dev/asmdisks/asm-ocr3 lrwxrwxrwx 1 root root 6 Jul 1 16:51 /dev/asmdisks/asm-ocr3 -> ../sdi [root@jiekexu-rac1 /]# ll /dev/sdi brw-rw---- 1 grid asmadmin 8, 128 Jul 1 17:12 /dev/sdi复制
直接强制将第三块盘添加进 OCR 磁盘组即可。
SQL> alter diskgroup OCR add disk '/dev/asmdisks/asm-ocr3' force; Diskgroup altered.复制
再次查看磁盘组状态则正常,只不过是作为一块新盘添加进去,从添加进去的磁盘名 OCR-0003 就可以看到,因为原来的名字为 OCR-0000。

全文完,希望可以帮到正在阅读的你,如果觉得此文对你有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【JiekeXu DBA之路】,第一时间一起学习新知识!
————————————————————————————
公众号:JiekeXu DBA之路
CSDN :https://blog.csdn.net/JiekeXu
墨天轮:https://www.modb.pro/u/4347
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————

评论

 0 点赞
0 点赞