




IMCI利用DataPack上的统计信息来跳过不需要访问的pack,类似于Clickhouse中的skipping index以及infobright里的knowledge grid,在IMCI中称为Pruner(粗糙索引),Pruner可以帮助IMCI优化查询性能。其基本原理是在查询时利用统计信息与过滤条件进行剪枝,判断是否需要扫描某个pack。由于统计信息内存占用较少,可以常驻内存。如果剪枝成功,则可以减少IO次数和条件判断次数,从而提升查询性能。
对于一个DataPack来说,被Pruner过滤后有三种可能的结果:Accept(AC)、Reject(RE)以及Partial Accept(PA)。被Accept的DataPack,无需对每条记录进行过滤,减少了计算开销;被Reject的DataPack,与本次查询无关,无需加载进内存,同时减少IO与计算开销,避免LRU Cache污染;被Partial Accept的DataPack,则需要进一步扫描每条记录来筛选出符合条件的记录。
IMCI的Pruner有minmax和Bloom filter两种类型,分别适用于不同的场景。此外,IMCI还针对Nullable列进行了优化,在查询时Pruner可以跳过包含Null值的DataPack,进一步提升查询速度。
Minmax
minmax索引是针对大型数据集的一种增强型索引技术。它通过存储每个数据块的最小值和最大值来为数据集构建索引,从而提供快速和高效的数据检索。minmax索引适用于数据集中、数值连续的数据,例如时间戳或实数值。它将数据集拆分成块,然后计算每个块的最小值和最大值,存储在索引中。当进行数据查询时,minmax索引可以根据查询范围的最小值和最大值快速定位数据块,从而减少对不相关数据的访问。以下图为例,A、B列包含3个DataPack,条件A>15 and B<10结合minmax索引,最终RowGroup2与RowGroup3可跳过,只需访问RowGroup1,从而减少了2/3的扫描代价。
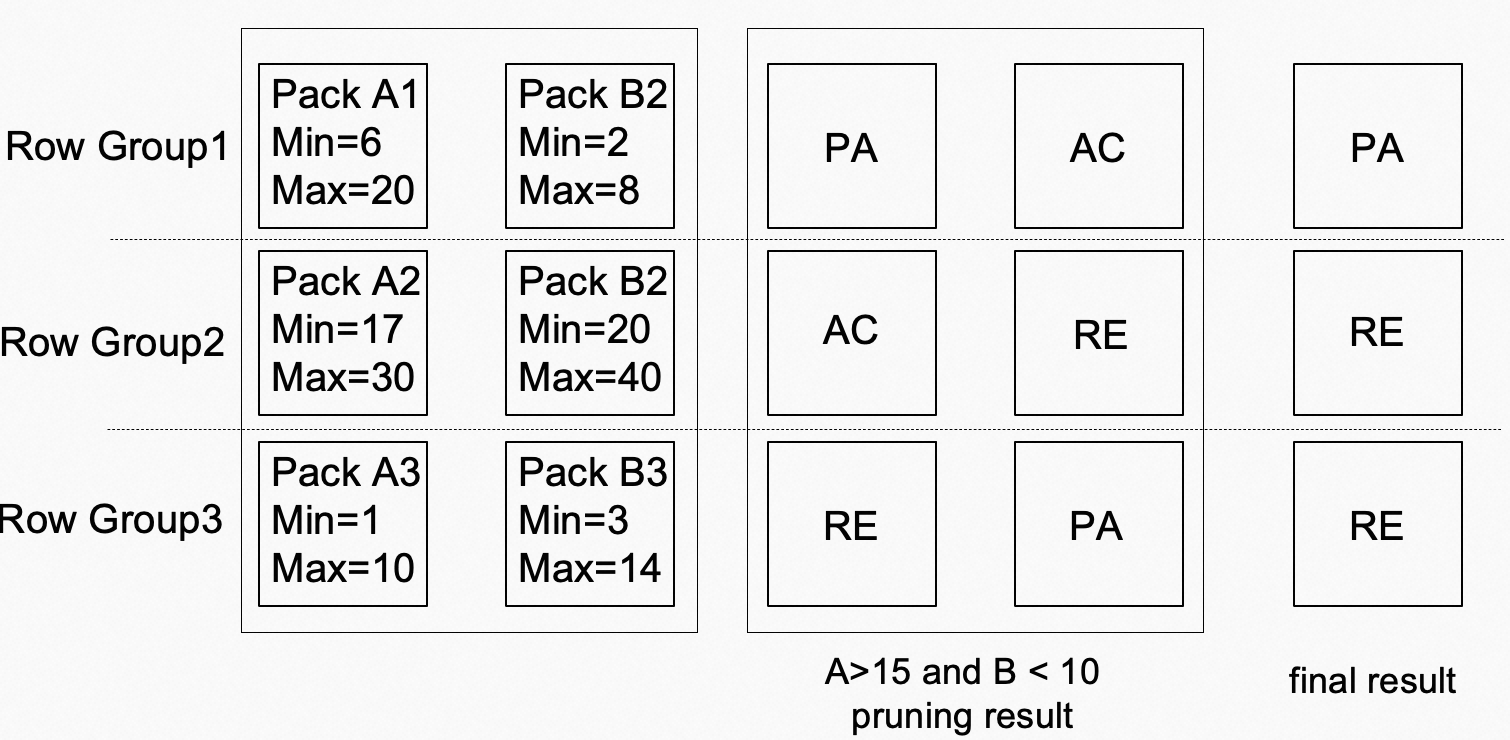
minmax索引的优点是它可以在非常快的时间内处理非常大的数据集。它能够减少为了处理查询而必须扫描的数据量,因为它只需要处理与查询范围相关的数据块。另外,minmax索引有助于减少存储索引所需的空间,因为它只需要存储每个块的最小值和最大值,而不是所有数据的索引。
Bloom filter
Bloom filter是一种常用的概率型数据结构,用于判断一个元素是否属于某个集合中。它使用一个比特数组和一组哈希函数来存储和搜索元素。当一个元素被添加到过滤器中时,哈希函数将元素映射到比特数组中的几个位置,并将相应的比特设置为1。当检查一个元素是否在过滤器中时,哈希函数再次应用于该元素,如果所有相应的比特位都是1,则该元素可能在集合中。然而,如果任何一个相应的比特位为0,则该元素肯定不在集合中。Bloom filter是具有空间效率的表示方法,可以快速确定一个元素在不在集合中,但它们可能会产生误报(false positives)- 查询一个不在集合中的元素可能会错误地指示它在集合中。
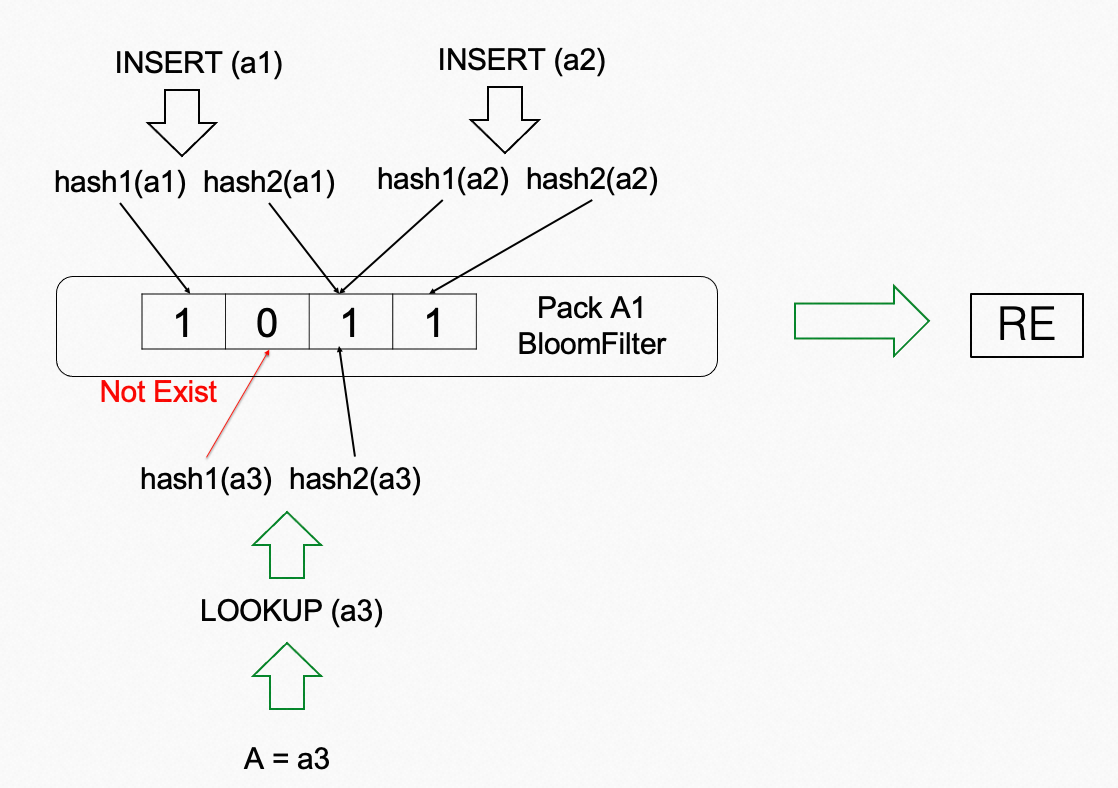
Bloom filter的优点是高效、空间效率高、可扩展性强和误判率可控。这些优点使Bloom filter成为处理大规模数据集中的元素存在性问题的一种非常有用的数据结构。
Bloom filter与minmax也可以结合使用,IMCI会根据两者的综合结果来判断是否要跳过某个数据块。


