




本期是必读论文系列的最后一期,会和往期内容一起汇总在【必读论文】分类中,关注后可以在消息页面底部的菜单栏中找到。无论您是新手还是有一定经验的从业者,希望这个系列能为您提供有价值的知识和见解。
本期内容包含以下三篇论文:
DiskANN: 单节点快速精准十亿点最近邻搜索
VectorSearch

论文下载链接:https://dl.acm.org/doi/pdf/10.5555/3454287.3455520
文章核心
文章提出了 DiskANN,这是一种可以有效支持大规模数据的驻留在 SSD 上的 ANNS 系统,其核心是名为 Vamana 的新的基于图的 ANN 算法。文章做出了以下几点技术贡献:
DiskANN 可以在具有 64GB 内存的工作站上对数百个维度的十亿点数据集进行索引和搜索,提供在单条查询 recall@1 > 95% 的情况下平均时延不超过 5ms 的性能表现。
一种名为 Vamana 的新算法,可以生成直径比 NSG 和 HNSW 更小的图索引,从而使 DiskANN 能够最大限度地减少顺序磁盘读取的次数。
Vamana 也可以在内存中使用,其搜索性能匹配或超过目前最先进的内存算法(例如 HNSW 和 NSG)。
多个用于大型数据集的有重叠部分的分区的较小 Vamana 索引可以轻松合并为一个索引,该索引提供与为整个数据集构建的单次索引几乎相同的搜索性能。这可以解决为太大而无法放入内存的数据集建立索引的问题。
Vamana 可以与现成的向量压缩方案(例如乘积量化)相结合来构建 DiskANN 系统。图索引以及数据集的全量向量存储在磁盘上,而压缩向量缓存在内存中。
Vamana
大多数基于图的 ANN 算法在搜索时采用贪婪搜索(GreedySearch),GreedySearch 从一个随机起始点开始,通过不断地在候选集中选择距离查询点最近的点并探索其邻居,直到找不到更近的点为止。GreedySearch 流程如下图所示:

满足稀疏邻域图(SNG)属性的图可以很好的帮助贪婪搜索快速收敛到任何查询的最近邻居,当前大多数基于图的 ANN 算法在构图时都尝试近似 SNG。SNG 构图时每个点 p 的外邻居确定算法如下:初始化集合 S = P \ {p},只要 S != ∅,添加一条从 p 到 p* 的有向边,其中 p* 是 S 中最接近 p 的点,并从 S 中删除所有满足 d(p, p’) > d(p*, p’)的点 p’。
然而在 SNG 图直径非常大的情况下,例如图的节点在一维实线上线性排列,贪婪搜索会对图的所有节点进行遍历,造成多次读取操作。当此类图存储在磁盘中时,搜索会产生大量磁盘读取延迟。
为了解决上述问题,Vamana 算法修改了 SNG 构图时每个点 p 的外邻居确定算法,通过引入乘法因子 α > 1 增加图的长边,加快贪婪搜索的收敛速度。流程如下图所示:

由此,就可以得到 Vamana 的索引建立算法流程:
初始化一张随机近邻图;
计算全局质心,以距离全局离质心最近的点作为搜索算法的起始节点;
基于步骤 1 初始化的随机近邻图和步骤 2 中确定的起始节点对每个点做 GreedySearch,将搜索路径上所有的点作为候选邻居集,执行 α = 1 的 RobustPrune;
调整 α > 1(论文推荐 1.2)重复步骤 3。
流程如下图所示:

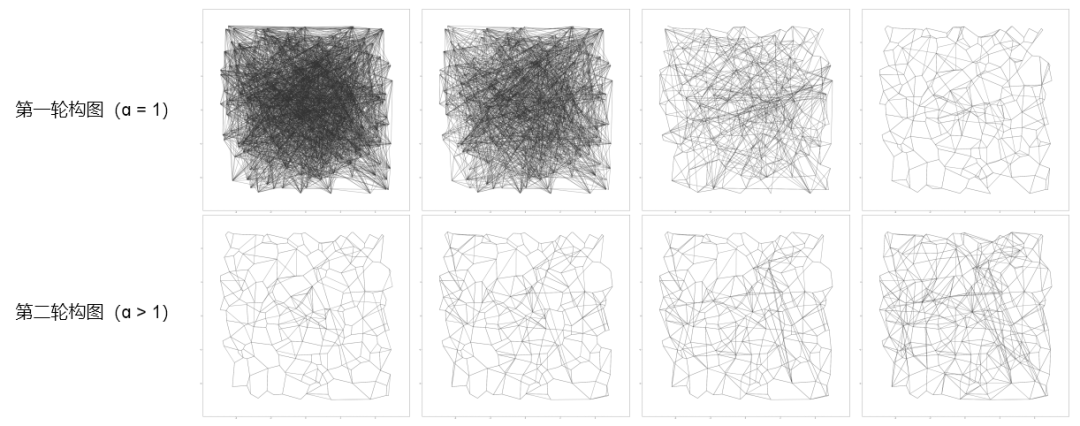
Vamana 算法在 200 数据量 2 维数据集上的构图过程如下:
DiskANN
DiskANN 的设计思想非常简单:在数据集 P 上运行 Vamana 索引建立算法并将结果图存储在 SSD 上。在搜索时,每当 GreedySearch 需要点 p 的外邻居时,只需从 SSD 中获取此信息即可。但单个具有 64GB 内存的工作站根本无法存放 10 亿数据量数据集,因此带来了两个问题,无法在内存中进行索引的构建或搜索。
对于索引构建的问题,DiskANN 在构建索引时通过 k-means 聚类的方式将整个数据集划分成 k 个簇,然后将每个节点分配到最近的 l 个簇中,每个簇分别构建 Vamana 图,这样就可以在内存中进行索引的构建,最后通过简单的边并集将所有不同的图合并为一个图。
对于搜索的问题,DiskANN 采用乘积量化将每个数据点压缩,压缩向量存储在内存中,原始向量和图存储在 SSD 上。尽管在搜索时使用压缩向量,但因为 Vamana 在构建图索引时使用原始向量,所以搜索时能够有效地引导搜索到图的正确区域,并且最终计算也使用原始向量。
为了保证在 SSD 上的搜索时延表现,DiskANN 还引入了以下优化策略:
在磁盘上存储每个数据点的全精度向量,后跟其 R 个邻居的id。如果图节点的度小于 R,则用零填充。这样简化了任意点对应的数据在磁盘内的偏移量计算。
因为从 SSD 中获取少量随机扇区所需的时间几乎与获取一个扇区所需的时间相同,所以在进行 GreedySearch 时一次性缓存少量 W 个未访问点的邻居信息,可以做到减少磁盘访问次数又不增加单次磁盘访问延迟。这种修改后的搜索算法称被为 BeamSearch。
为了进一步减少每次查询的磁盘访问次数,可以基于已知的查询分布,在内存中缓存与数据点子集关联的数据,或者简单地缓存距起始节点 3 或 4 跳的所有数据点。
实验
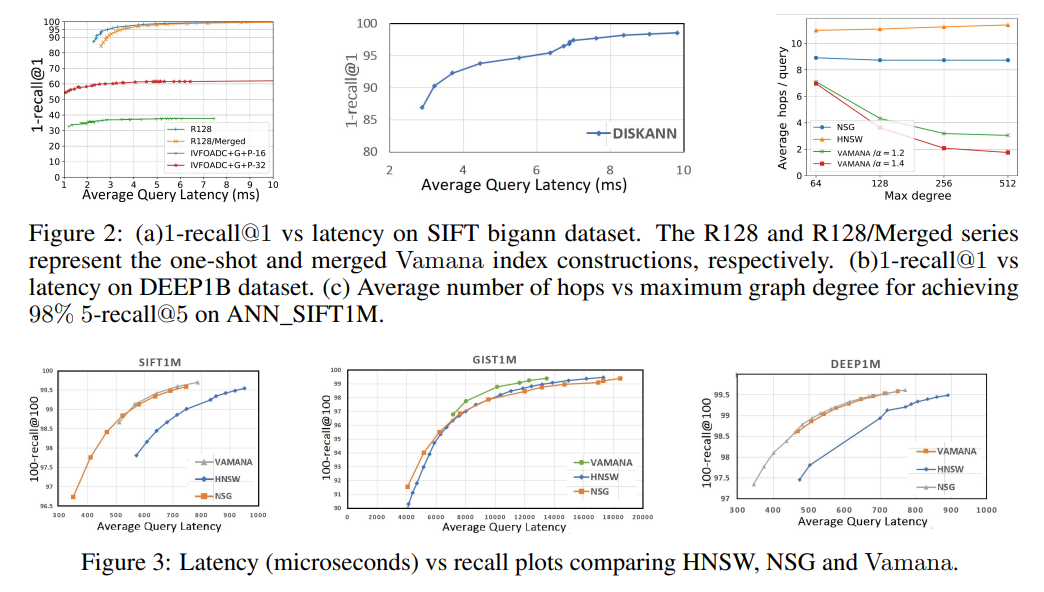
Vamana 与其他 ANN 算法比较结果如下:
FreshDiskANN:一种用于流式相似性搜索的快速、准确的基于图的 ANN 索引
VectorSearch

论文下载链接:https://arxiv.org/pdf/2105.09613.pdf
文章核心
文章提出了 FreshDiskANN 系统,用于解决欧几里得空间中具有实时新鲜数据点的fresh-ANNS问题,并且所需机器的数量相比其他先进技术少 5 到 10 倍。文章做出了以下几点技术贡献:
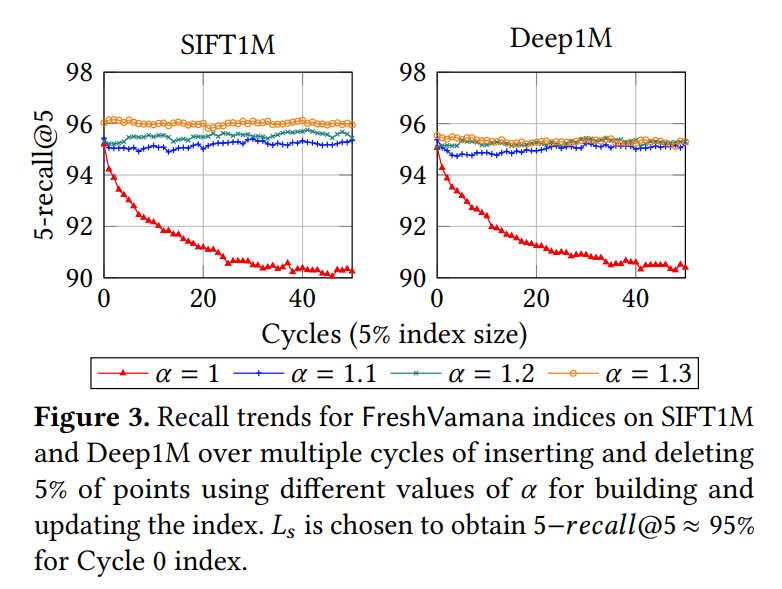
演示了简单的图更新规则如何导致 HNSW 和 NSG 等流行的基于图的算法在插入和删除流上的索引质量下降。
开发了 FreshVamana,这是第一个支持插入和删除的基于图的索引,并实证了其在长时间更新流中的稳定性。
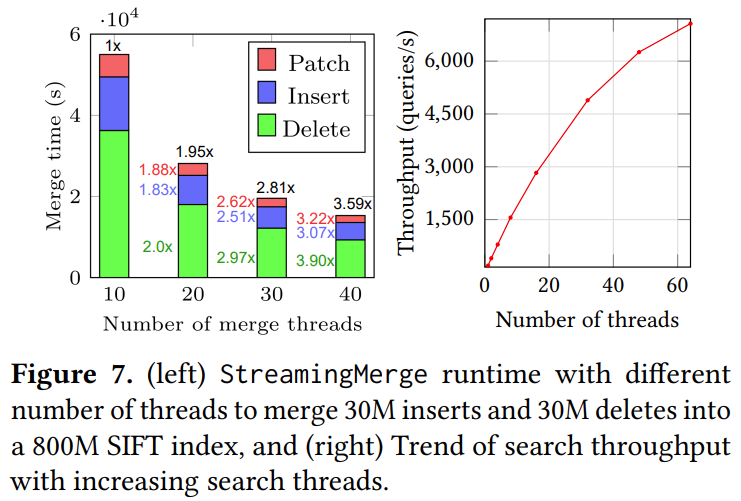
系统将大部分图形索引存储在 SSD 上,仅将最新更新存储在内存中。为了支持这一点,设计了一种新颖的两遍 StreamingMerge 算法,该算法以一种非常高效的写入方式将内存中索引与 SSD 索引合并。合并过程的时间和空间复杂度与更改集成正比,从而可以使用比从头开始重建大型索引少一个数量级的计算和内存,在 RAM 有限的机器上更新大型十亿点索引。
设计了 FreshDiskANN 系统,其中包含一个覆盖大多数数据点的长期驻留 SSD 的索引,以及一个用于聚合最近更新的短期内存索引。FreshDiskANN 会定期在后台使用 StreamingMerge 算法将短期索引合并到长期索引中,以限制短期索引的内存占用,从而限制整个系统的内存占用。
FreshVamana
因为流行的基于图的算法在构图时采用非常激进的裁边策略来构建高度稀疏的图结构,所以当更新图时,图结构会变得稀疏,降低图的可导航性,导致了图索引质量下降。FreshVamana 采用了 Vamana 中的 RobustPrune 以构建更密集的图,确保了图的持续导航性和在多次修改后保持稳定的召回率的能力。
FreshVamana 的节点插入流程与 Vamana 一致。流程如下图所示:

FreshVamana 删除节点 𝑝 时,只要 (𝑝′, 𝑝) 和 (𝑝, 𝑝′′) 是当前图中的有向边,就添加边 (𝑝’, 𝑝′′),如果违反了任何节点的度数限制,就运行 RobustPrune 来控制度数。流程如下图所示:

由于删除操作及编辑 𝑝 的所有邻居的邻域,因此删除后立即合并的方式成本较高。FreshVamana 采用惰性删除策略:当删除点 𝑝 时,将 𝑝 添加到删除列表而不更改图表,在累积大量删除点后,使用 FreshVamana 删除节点流程批量更新图。
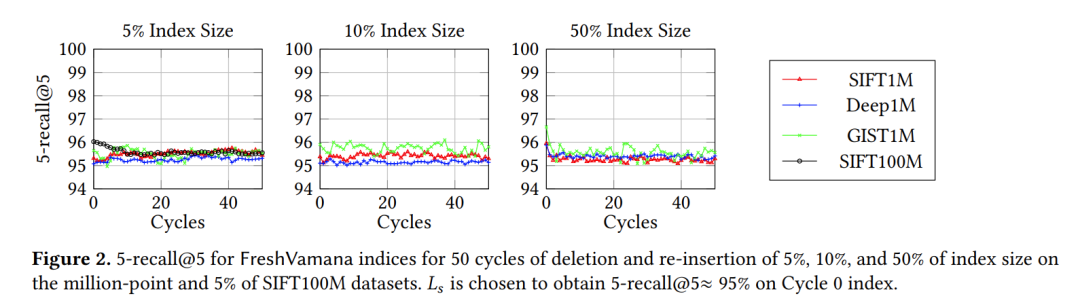
FreshVamana 在长时间更新流中的稳定性表现如下:
FreshDiskANN
FreshDiskANN 的主要思想和 DiskANN 一致。另外,FreshDiskANN 通过将索引分为两部分,包含最近更新的 FreshVamana 组件存储在内存中,更大的长期数据图索引存储在 SSD 中,解决了即时更新存储在 SSD 的 FreshVamana 索引带来的 SSD 高负载性能下降问题。
FreshDiskANN 维护两种类型的索引:一个存储在 SSD 的长期索引(LTI)和一个或多个存储在内存的临时索引(TempIndex),以及一个存在于删除列表。其中,TempIndex 包含最近插入的数据点,删除列表是存在于 LTI 或 TempIndex 中但已被用户请求删除的点的列表。为了帮助崩溃恢复,TempIndex 分为 RW-TempIndex 和 RO-TempIndex,RW-TempIndex 接收插入节点,FreshDiskANN 定期将 RW-TempIndex 转换为 RO-TempIndex 并将其快照到持久存储中,然后再创建一个新的空 RW TempIndex 来接收新插入节点。
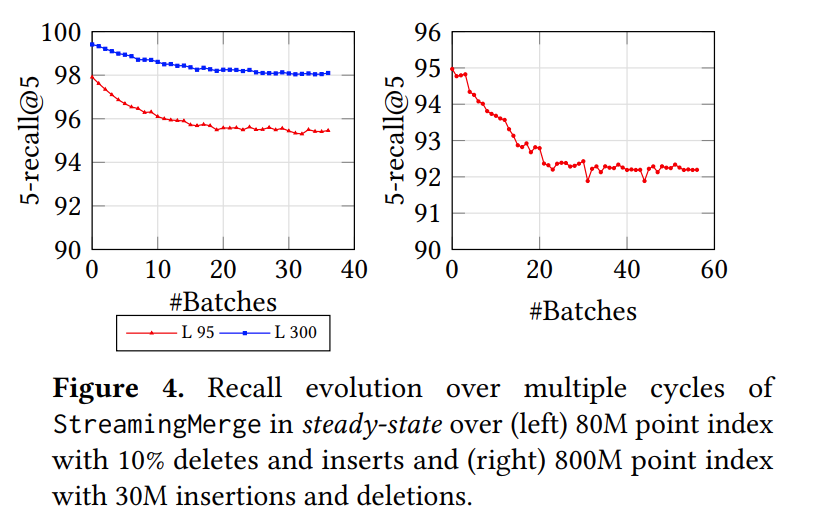
FreshDiskANN 将 RO-TempIndex 和删除列表中的删除合并入 LTI 的过程被称为 StreamingMerge Procedure。值得注意的是,StreamingMerge Procedure 中涉及的任何距离计算都使用压缩向量数据。StreamingMerge Procedure 流程如下:
从 SSD 中逐块加载 LTI 进入内存,使用多线程对块中存在于删除列表的节点执行 FreshVamana 删除节点流程,最终将修改后的中间 LTI 写回 SSD。
在存储在 SSD 上的中间 LTI 上对 RO-TempIndex 中的每一个节点执行 FreshVamana 插入节点流程,但不即时执行 FreshVamana 插入节点流程的添加反向边步骤,而是先存入内存数据结构 ∆ 中,目的是为了减少 SSD 的随机读写。
从 SSD 中逐块获取中间 LTI 中的所有节点,并行地从 Δ 中添加每个节点的相关出边,如果添加后节点度数超过 R,则运行 RobustPrune,最终将修改后的最终 LTI 写回 SSD。
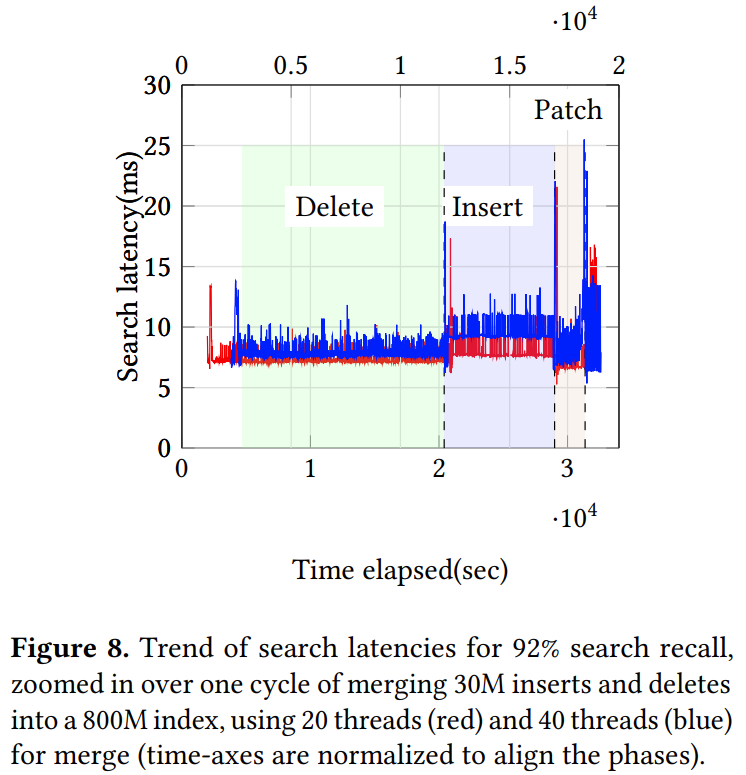
FreshDiskANN 在长时间 StreamingMerge Procedure 更新流中的稳定性表现如下:
实验
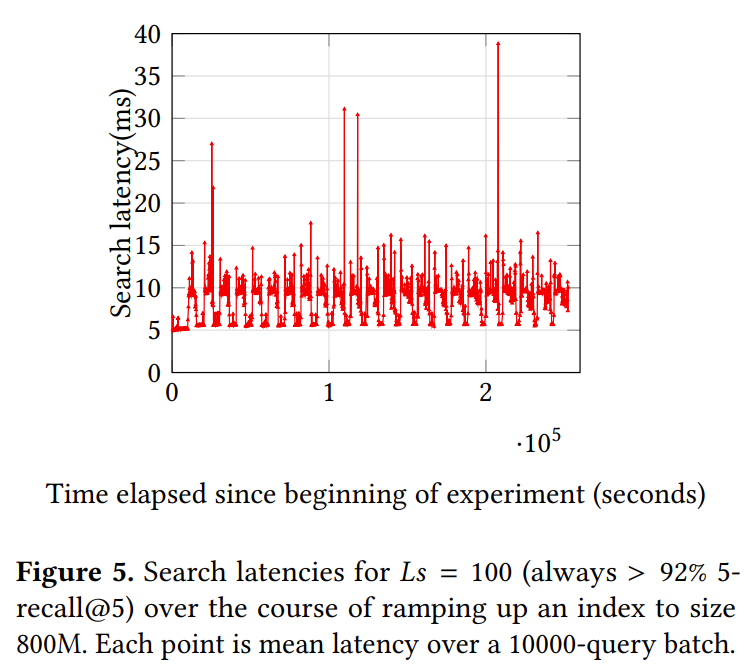
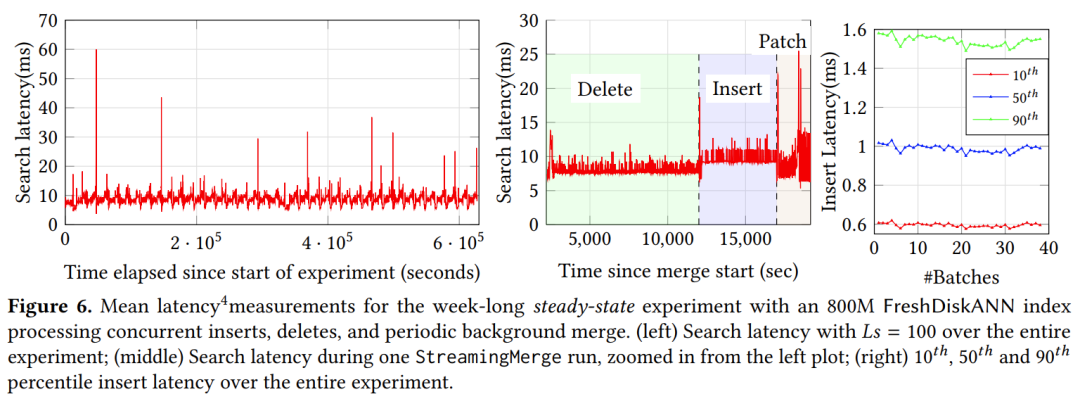
FreshDiskANN 在数据集不同更新阶段下的性能表现如下:
DiskANN++:使用查询敏感度入口顶点对同构映射图索引进行高效的基于页面的搜索
VectorSearch

论文下载链接:https://arxiv.org/pdf/2105.09613.pdf
文章核心
文章提出了 DiskANN++, 用于解决 DiskANN 存在的两个严重影响整体效率的 I/O 问题:(1) 从入口节点到查询邻域的路由路径较长,导致大量 I/O 请求;(2) 在路由过程中的冗余 I/O 请求。文章做出了以下几点技术贡献:
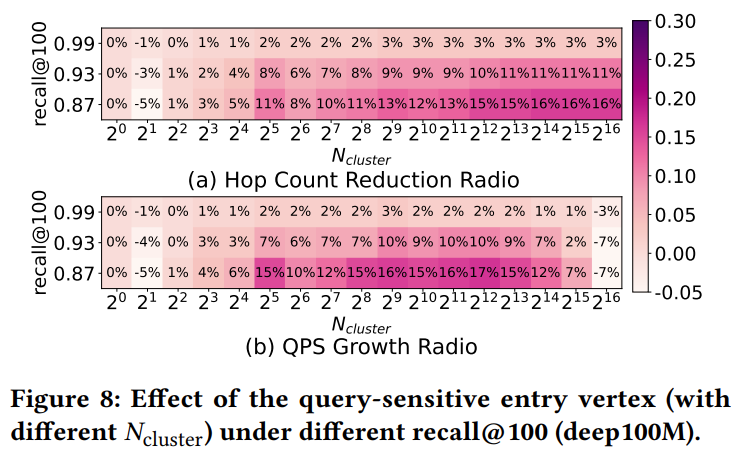
提出了一种查询敏感入口节点选择策略来动态确定入口节点,解决了由于从较远的入口节点到查询的路由路径较长而导致的 NN 接近阶段的 I/O 问题 。
提出了Vamana的同构映射,将非常接近的节点分配给同一个 SSD 页面,从而细化 SSD 布局,从而有效地增强每个单独 SSD I/O 请求的数据价值。
设计了一种名为 Pagesearch 的新颖搜索算法,基于精细的 SSD 布局进行页面级优化,利用空闲的 CPU 资源来更新更有价值的节点的全局候选者,从而减少冗余的 SSD I/O 请求并加速收敛。
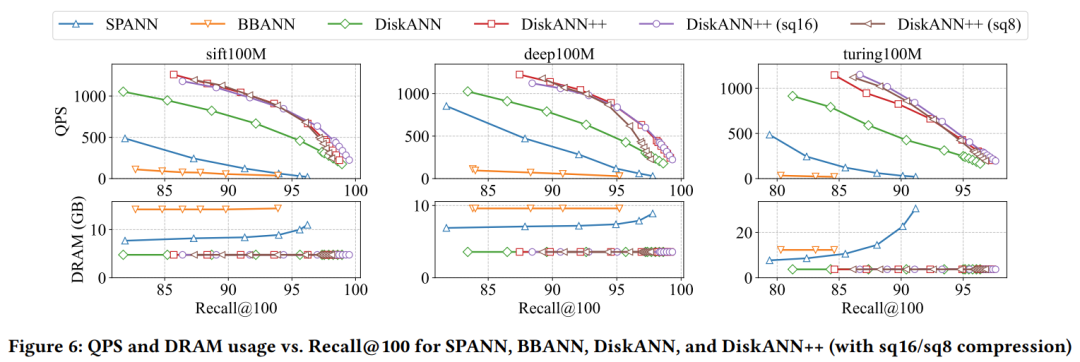
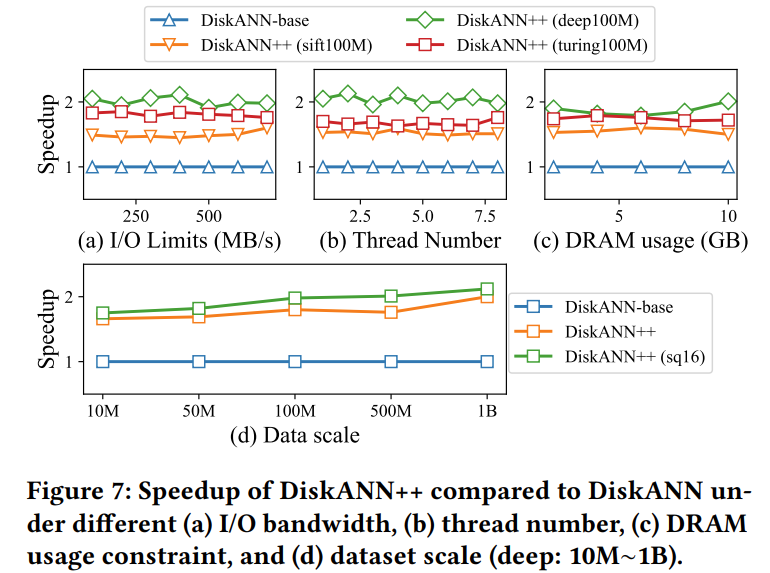
在不同类型和规模的公共和商业数据集上,在不同的硬件资源配置下进行的大量实验表明,DiskANN++ 实现了 1.5 倍到 2.2 倍的显著 QPS 提升。
Query-Sensitive Entry Vertex
查询敏感入口节点选择策略的基本思想总结为:首先准备一组有代表性的候选入口节点,然后从候选入口节点中为每个传入的查询选择合适的入口节点。
给定向量数据集和数据集的 Vamana 图索引,候选入口节点的生成流程如下:
使用 kmeans 将数据集聚类成 N 簇,这一步用于逻辑划分原始向量空间。
将每个簇的质心作为输入查询向量来在 Vamana 图索引中查找其最近 1 个邻居。
在线性表中记录 N 簇质心的所有最近邻居作为候选入口节点。
由于每个候选点都是数据集的一个簇的代表节点,因此将传入查询所在簇的候选点作为入口节点是合理的。入口节点选择流程如下:
计算每个候选节点到查询向量的距离。
选择距离最近的节点作为入口节点。
查询敏感入口节点带来的运行效率提升来自于入口节点选择所花费的时间和由于缩短的路由路径而节省的 SSD I/O 时间之间的权衡。由于读取 SSD 页面比从内存读取慢得多,因此很自然地看到与原始 DiskANN 相比具有良好的效率。
Isomorphic Mapping on Vamana
DiskANN 的冗余 I/O 请求问题,主要是由每个 SSD 页面的数据值较低引起的。每个 SSD 页面较低的数据值增加了 I/O 请求的总数,使许多页面被冗余访问。DiskANN++ 在 Vamana 上使用基于包合并的同构映射来细化其 SSD 布局,从而增加每个 SSD 页的数据值。基于包合并的同构映射包括两个步骤:打包和合并。
同构映射的定义如下:给定图 𝐺 = (𝑉 , 𝐸) 和 𝐺′ = (𝑉′, 𝐸′) 的两种 SSD 布局 𝐿 和 𝐿′。我们认为 𝑓 : 𝐿.IDs → 𝐿′.IDs 是它们逻辑视图(或逻辑布局)上的同构映射,当且仅当 𝑓 是满足三个条件的双射:(1) 𝐿 和 𝐿′ 包含相同数量的数据块。(2) ∀𝑏𝑣𝑖,𝑏𝑣𝑗 ∈ 𝐿,如果它们的恒等式𝑣𝑖 ≠ 𝑣𝑗,则𝑓(𝑣𝑖) ≠ 𝑓(𝑣𝑗)。(3) ∀𝑏𝑣𝑖,𝑏𝑣𝑗 ∈ 𝐿,若 ∃𝑒(𝑣𝑖, 𝑣𝑗) ∈ 𝐸,则 𝑒 (𝑣′𝑖, 𝑣′𝑗) ∈ 𝐸′ 其中 𝑣′𝑖 = 𝑓(𝑣𝑖) 和 𝑣′𝑗 = 𝑓(𝑣𝑗)。
基于包合并的同构映射的可视化流程如下图所示:
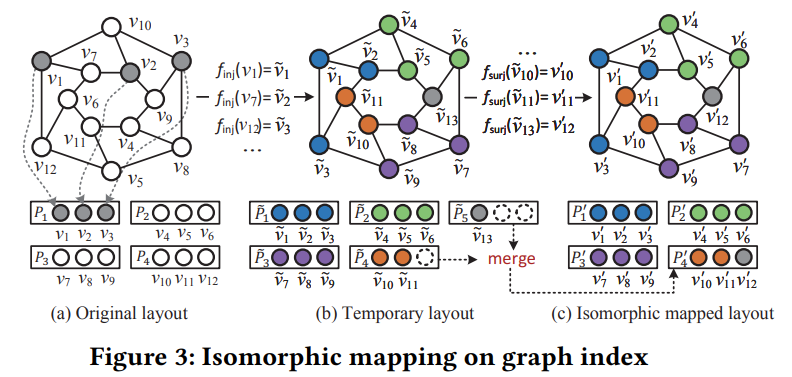
打包算法通过三步返回具有 𝑓inj 的临时逻辑布局 𝐿.~ID。打包算法流程如下图所示:

临时逻辑布局仍然存在一个问题:某些页面未满,并且原始寻址模式对它无效。因此需要一个合并阶段,其目标是实现满射 𝑓surj : 𝐿.~IDs → 𝐿′.IDs,将来自非完整页面的数据块组合以形成新的完整页面。合并算法流程如下图所示:

最后使用原始逻辑布局 𝐿.IDs 和输出最终逻辑布局 𝐿′.IDs 以及两个映射 𝑓inj 和 𝑓surj 更新 SSD 布局。
Page-Based Search
为了利用同构映射 Vamana 的精细 SSD 布局的优势,DiskANN++ 使用了一种基于主动过滤的异步页面扩展作为节点扩展的补充,从而形成了新的 Pagesearch 作为 Beamsearch 的替代方案。
Pagesearch 依赖于一个称为页面堆的页面缓存池,在此基础上设计了页面扩展策略来主动过滤更有用的节点作为节点扩展的候选者。此外,在处理 SSD I/O 请求的同时,利用 CPU 的停顿周期异步执行建议的页面扩展。这样就提高了CPU的利用率,从而提高了整体的QPS。
Beamsearch 和 Pagesearch 的可视化流程如下图所示:
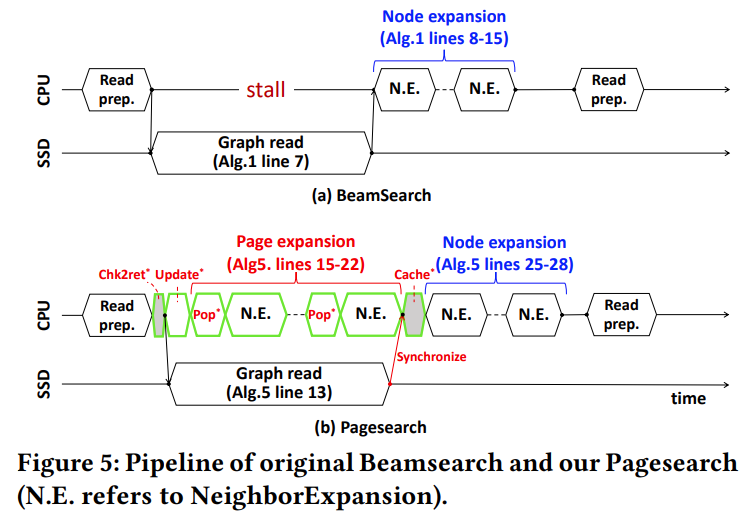
页面堆具有以下基本运算符:
Cache():将 4k 对齐的页面缓存到内存池中,并将页面内的节点注册到循环队列中。
Update():计算循环队列中每个节点与查询之间的全向量距离。根据这些距离,使用这些节点更新最小堆并将它们从循环队列中删除。该最小堆将在页面扩展步骤中使用。
Check2ret():检查内存池中是否存在给定页面的数据块。如果找到数据块,则将其作为输出返回,否则报告无。
Pop():从最小堆中弹出到给定查询的最小距离的 top-1 节点。
Pagesearch 的流程如下图所示:

实验
DiskANN++ 相关测试结果如下:

向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

