




本篇开始解析部分内核的钨丝计划相关源码。
3.1 概述
在Spark的近期发展中,最引人关注的是钨丝计划(Project Tungsten)。该计划可以从Databricks公司发布的官方博客获取,具体(参考地址https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html),从博客中可以知道,目前Spark计算框架的瓶颈主要在于CPU与内存,而不是磁盘IO及网络开销,随着带宽增大、SSD或者磁盘阵列的使用,这部分开销已经不再是Spark计算框架的瓶颈,而对应的,在序列化、反序列化及Hash等场景下,CPU和内存方面已经成为当前的主要瓶颈,因此,作为性能提升的下一阶段的钨丝计划(Project Tungsten)也就因此诞生了。
关于性能方面的详细信息,可以参考上述博客中的相关介绍,以及《Making Sense of Performance in Data Analytics Frameworks》这篇论文。
Project Tungsten主要包含了以下三大方面:
内存管理(Memory Management)和二进制处理(Binary Processing):利用应用的语义(application semantics)来更明确地管理内存,同时消除JVM对象模型和垃圾回收开销。
缓存友好的计算(Cache-aware Computation):使用算法和数据结构来实现内存分级结构(MemoryHierarchy)。
代码生成(Code Generation,CG):使用代码生成来利用新型编译器和CPU。
当前钨丝计划的详细信息可以参考官网上的两个开发阶段,如图3-1及3-2所示:
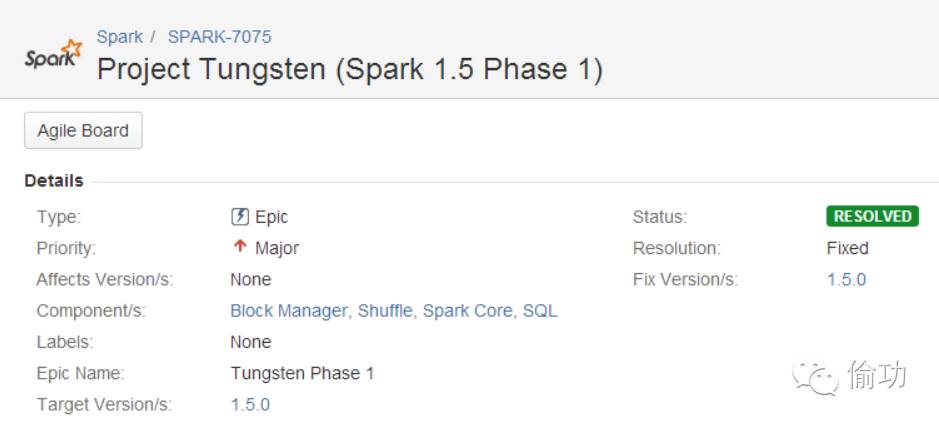
图3-1 ProjectTungsten 第一阶段
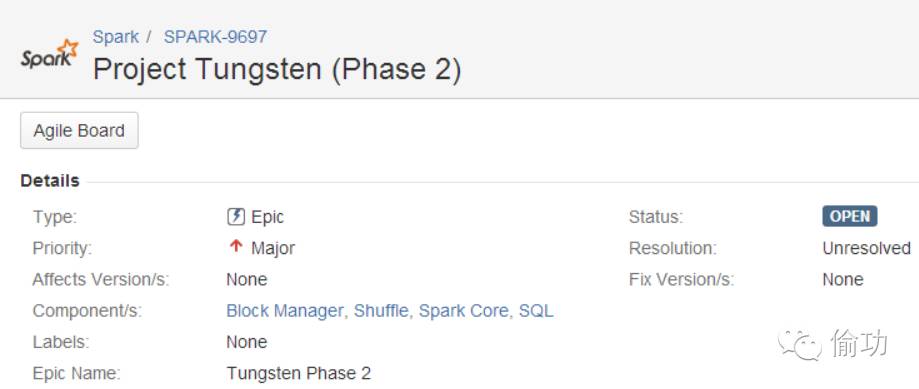
图3-2 ProjectTungsten 第二阶段
更多ProjectTungsten内容可以跟踪这两个阶段的各个issues。
本章的主要目的在于通过部分源码,解析内核部分与Project Tungsten有关的内容。对应Spark SQL部分相关的源码,解析的方式基本是一致的,且部分设计文档在官方资料(尤其是issues)中不少都已经给出,而且非常详细,因此本章不再重复这部分内容。
