





1. seq2seq介绍
[1]Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." *Advances in neural information processing systems*. 2014.
[2]Cho, Kyunghyun, et al. "Learning phrase representations using RNN encoder-decoder for statistical machine translation." *arXiv preprint arXiv:1406.1078* (2014).
2. seq2seq的内部结构
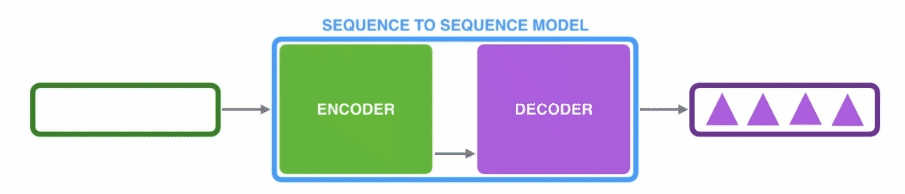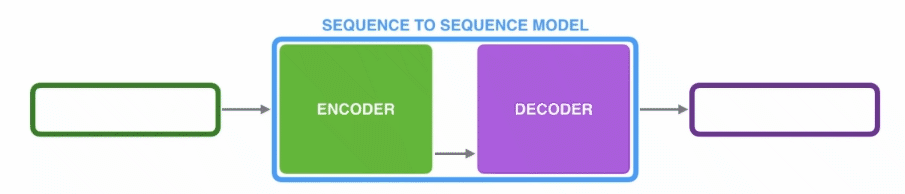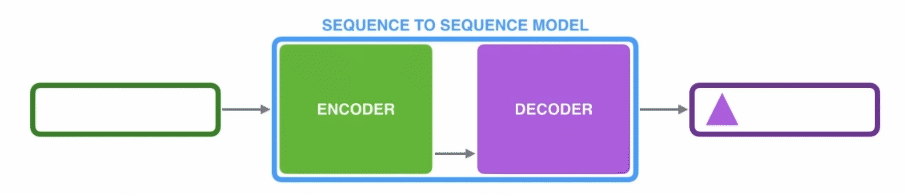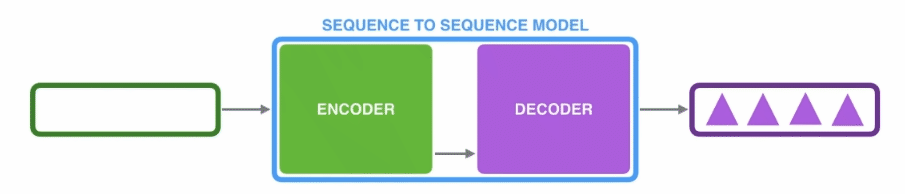
2.1 encoder和decoder
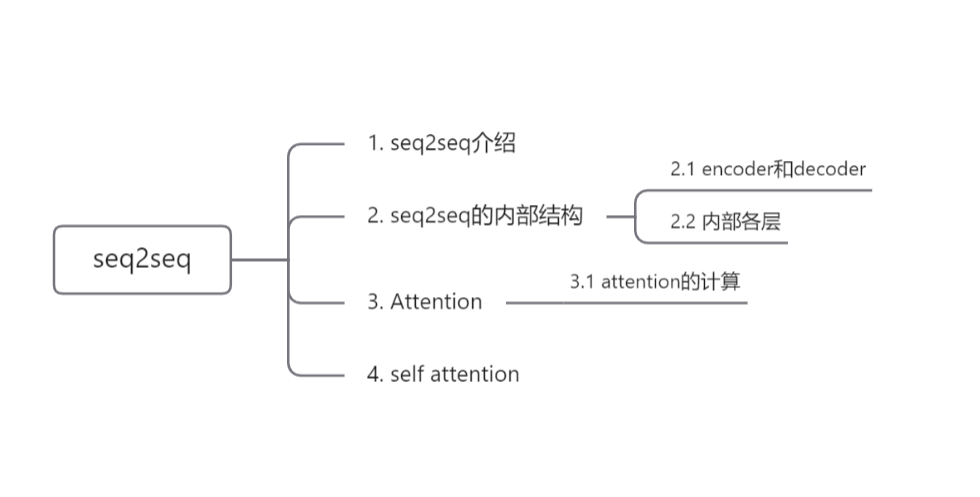
输入一个序列,encoder相当于一个特征提取器,以隐藏状态向量的形式捕获输入序列的上下文信息,传输到解码器中,解码器会根据编码器中的向量和当前的输入解码出对应的输出序列。
这是宏观上来介绍seq2seq的模型结构,因为处理序列类型的任务,所以其内部的encoder和decoder可以使用LSTM或者其它的RNN模型,这部分可以参考之前的两篇文章RNN和LSTM
假设使用simpleRNN作为内部结构,那么其中encoder向decoder传递的就是最后一个隐藏状态h,即为一个固定长度的向量,decoder在得到encoder的输入后,将该向量解码成输出序列
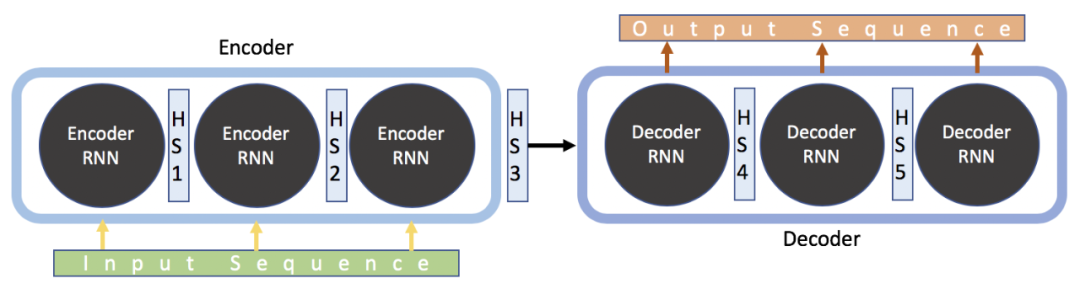
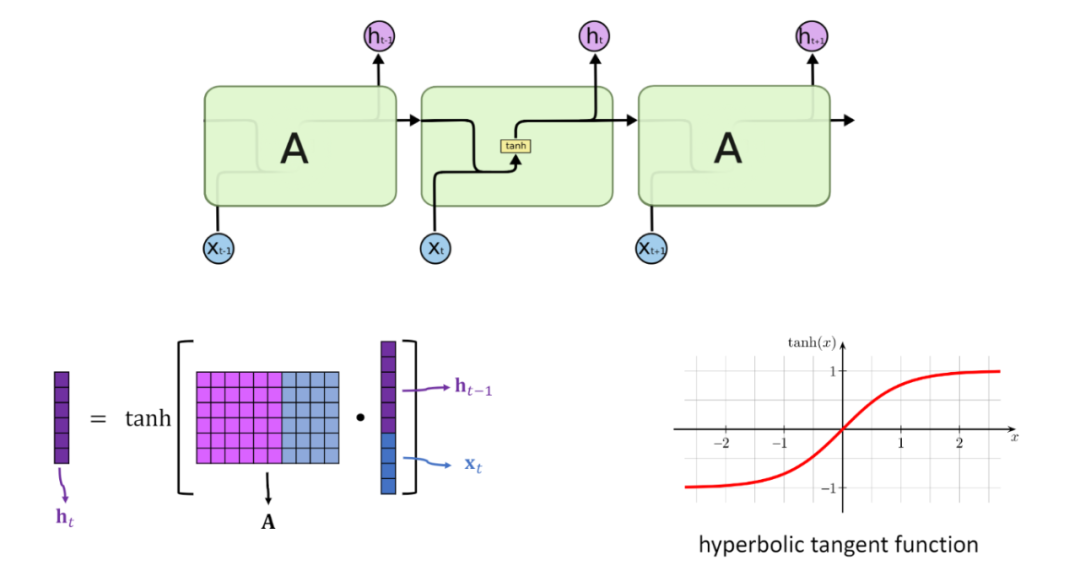
打开来看encoder和decoder的内部
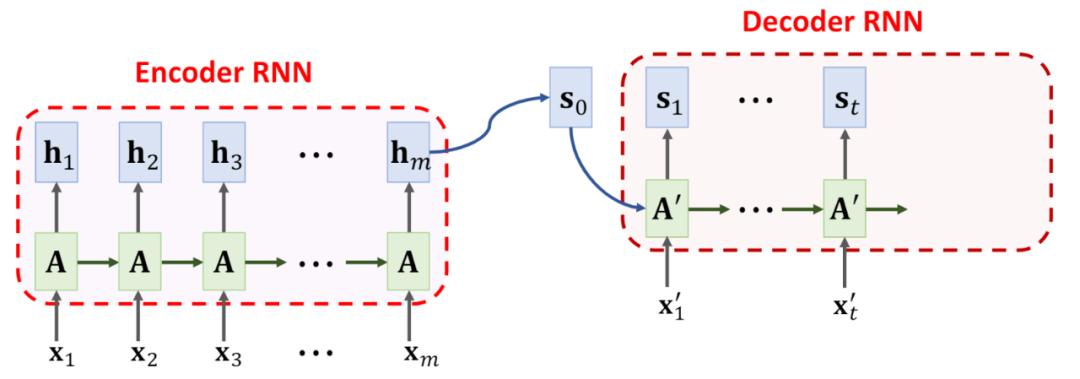
2.2 内部各层
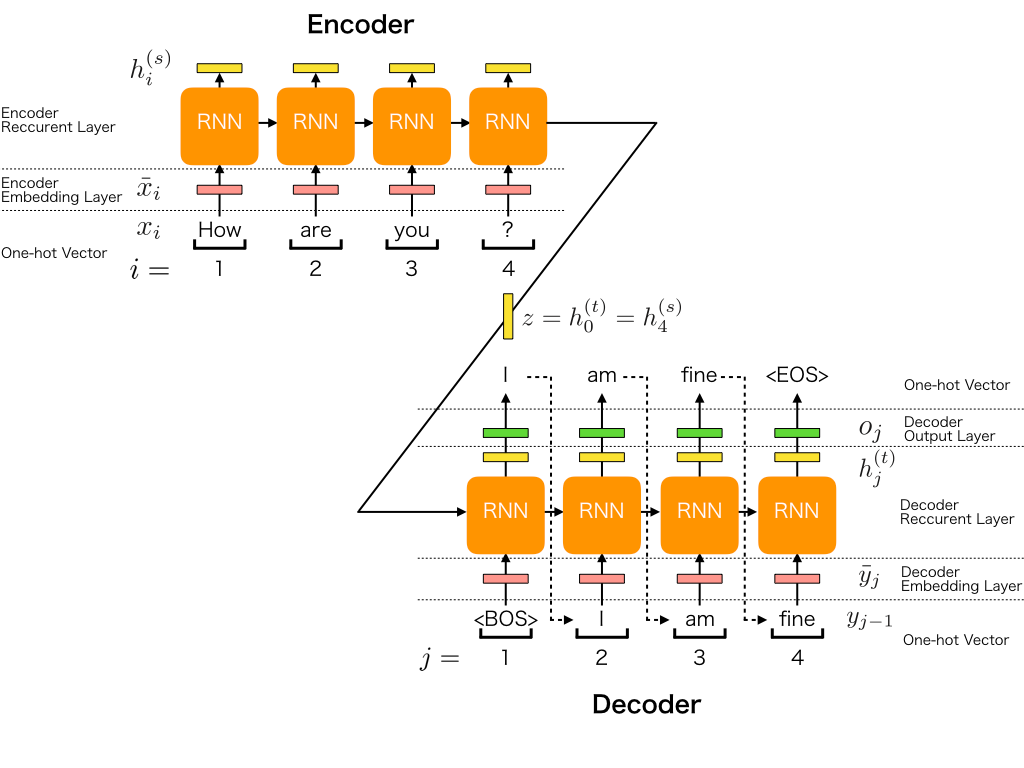
3. Attention
我们有时在生活或者学习中也会忘记一些东西,那么防止遗忘的方式就是重复,不断的回忆之前学过的知识,以此来达到记忆和加深理解的效果,所以将这个方法转移到解决RNN的问题上,通过Attention的名字大概也能猜到其核心思路,那就是不断的去回忆encoder中的语义信息,并且会特别注意某些词,这就使得处理长序列的问题可以避免信息损失,事实证明attention的效果非常好,以至于现在遍地都是attention。
[3]Bahdanau, D., Cho, K., and Bengio, Y., “Neural Machine Translation by Jointly Learning to Align and Translate”, <i>arXiv e-prints</i>, 2014.
[4]Luong, M.-T., Pham, H., and Manning, C. D., “Effective Approaches to Attention-based Neural Machine Translation”, <i>arXiv e-prints</i>, 2015.
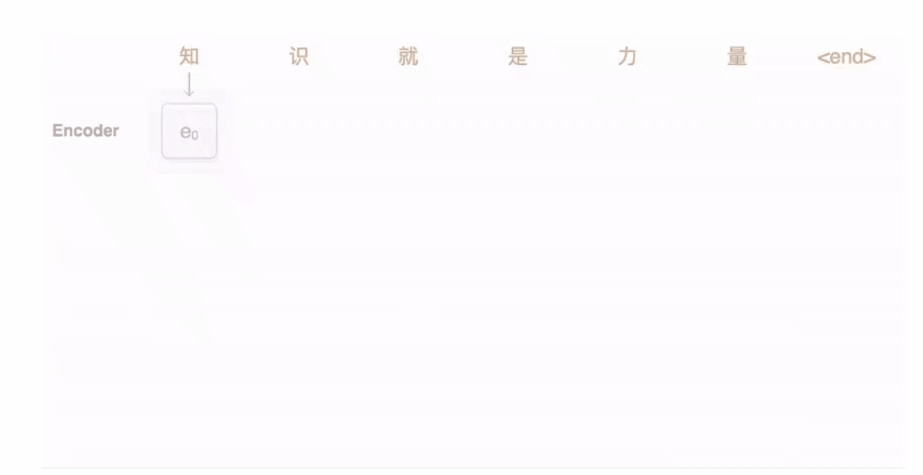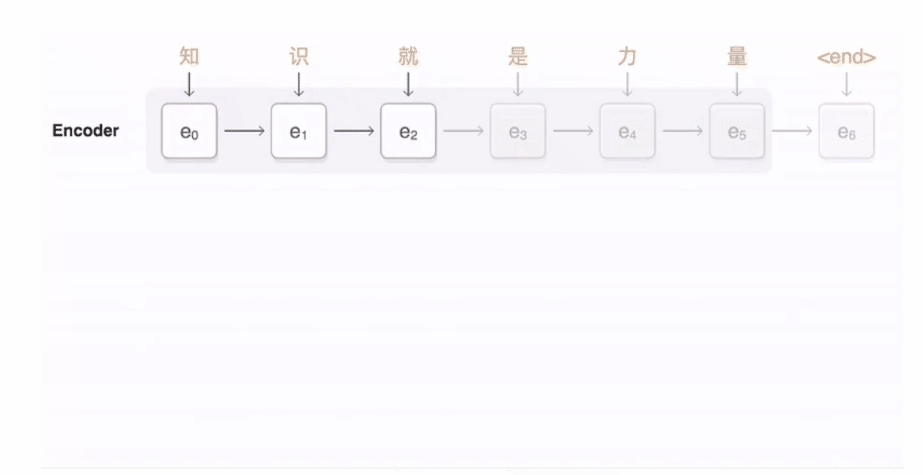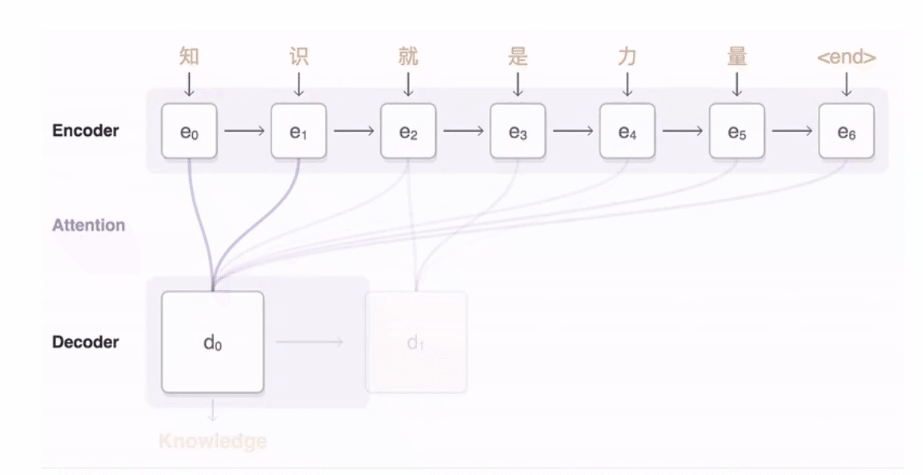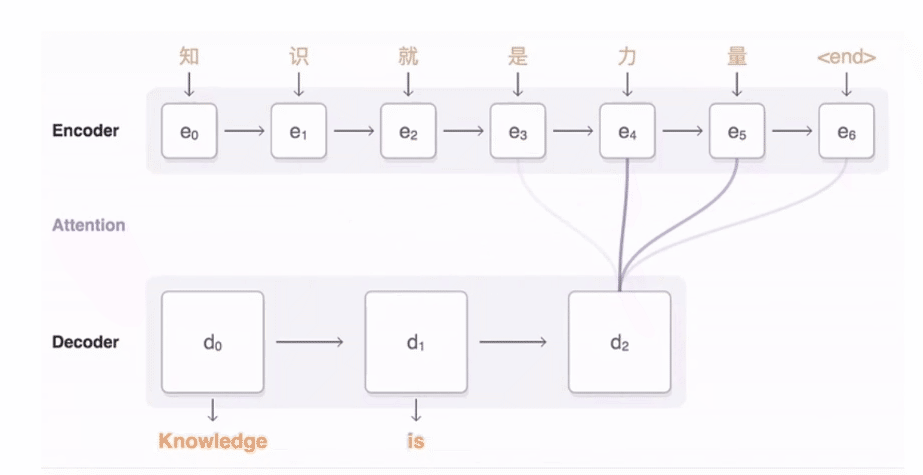
对seq2seq来说,Attention机制就是在decoder每次输出预测的时候,会重复查看encoder中的隐藏状态,以此来避免遗忘信息。那么如何衡量每个词的重要程度,即要特别注意哪些词,这就需要给序列中的每个词分一个权重,这个权重的计算就需要encoder和decoder的隐藏状态,可以想象成一个函数f,函数的输入就是上面提到的隐藏状态。
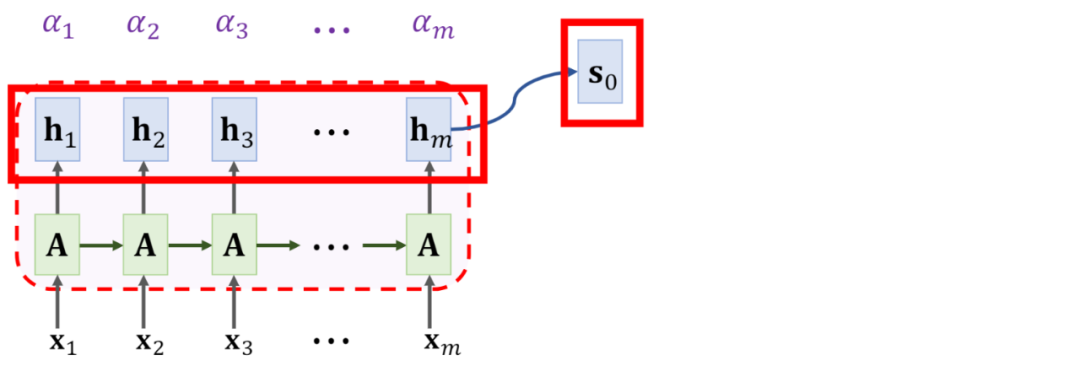
上图中的α就是decoder在当前时间步对encoder中的隐藏状态的关注程度(隐藏状态包含了词的信息),也就是说,decoder每个时间步的关注点是不同的,这也符合常识,比如decoder中的当前输入是“吃”,那么就会更关注encoder中与食物有关的词。
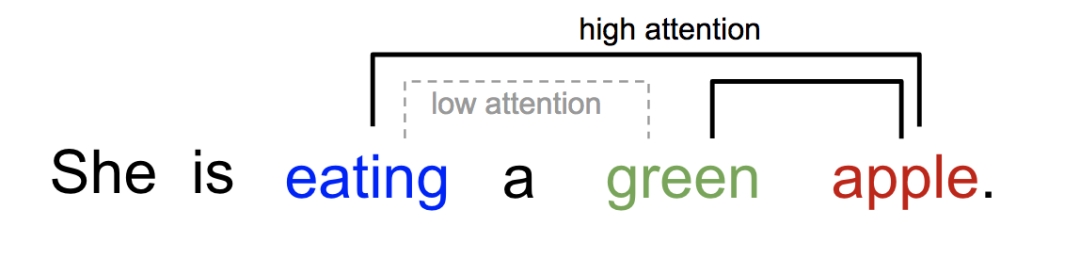
这里因为decoder中每个时间步的状态不同,那么在与encoder中的所有状态做计算时,计算出的权重也就不同。
如何去计算这个权重α呢?
3.1 Attention的计算
在第一篇提出attention的论文中,其计算方法如下
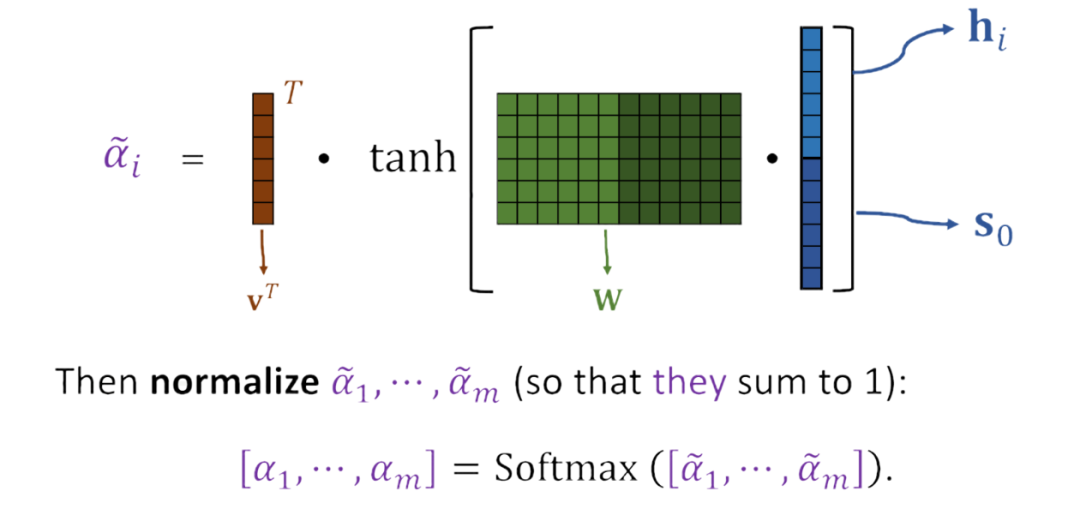

图中的描述很清楚,说明一下,
现在我们得到了每个隐状态h的权重,接下来要做的就是去“注意”。在未引入attention之前,decoder只是使用encoder中的最后一个状态来计算,现在则要注意全局状态,那就是用计算出来的权重和encoder中的所有隐藏状态作加权求和。
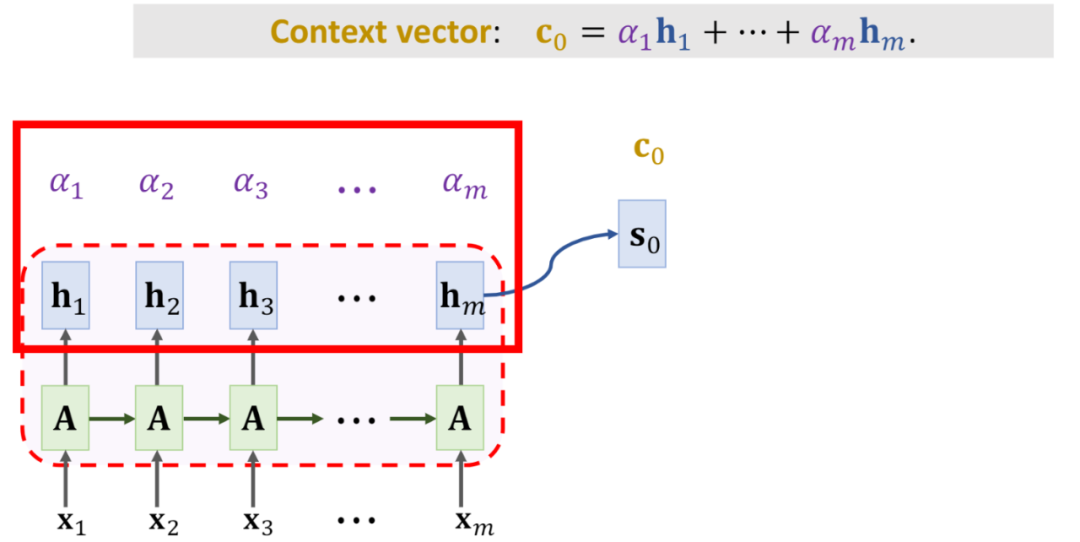
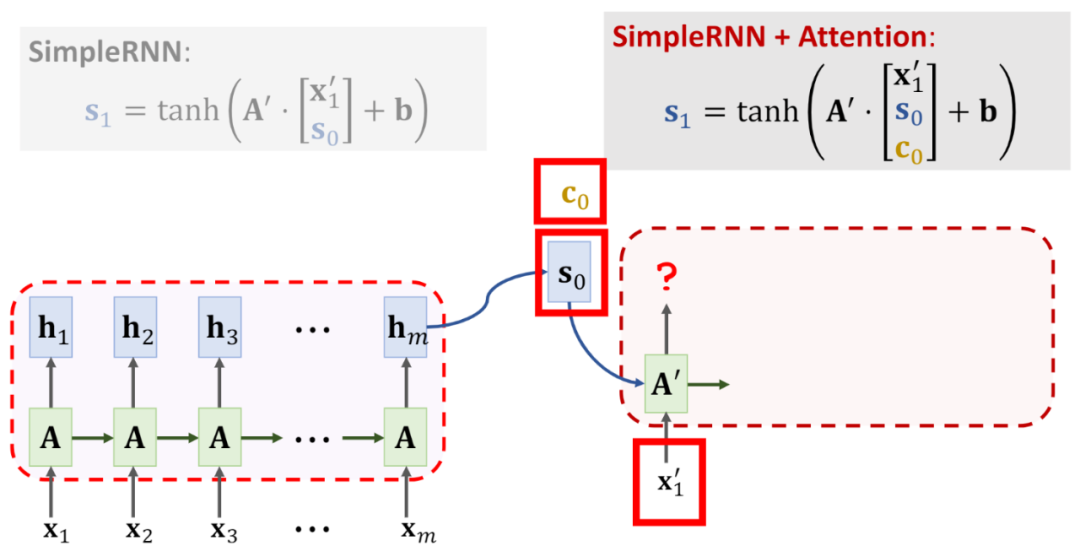
对这个过程的宏观可视化,也就是在传递给解码器的时候,是将编码器所有的隐藏状态都传递,而不仅仅是传递最后一个
4. self Attention
[5]Cheng, J., Dong, L., and Lapata, M., “Long Short-Term Memory-Networks for Machine Reading”, arXiv e-prints, 2016.
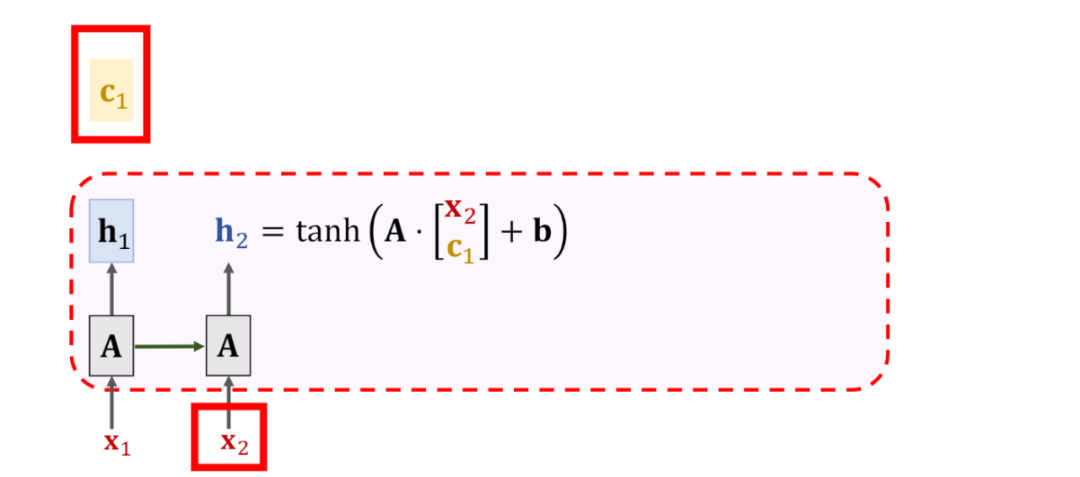
得到当前时间步的隐状态之后,同样的还是需要计算每个隐藏状态的权重,只不过这里就不需要decoder中的状态了,只考虑当前状态与其它状态的对比

如此循环下去,就可以得到整个序列中的各个词之间的关联度,到序列最后,信息的传递没有损失,因为每次都会利用权重得到各个词之间的相关性,也就是上下文向量每次都会回忆一遍序列的内容。

[6]Vaswani, A., “Attention Is All You Need”, <i>arXiv e-prints</i>, 2017.
[7]Liu, Z., “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”, <i>arXiv e-prints</i>, 2021.

以上便是本文的全部内容了,希望能给到你一点点的帮助
如果感觉还不错的话,感谢点赞和关注
分享知识,记录生活,一起进步🐐
Reference
https://dataxujing.github.io/seq2seqlearn/
https://towardsdatascience.com/day-1-2-attention-seq2seq-models-65df3f49e263
https://bgg.medium.com/seq2seq-pay-attention-to-self-attention-part-1-d332e85e9aad
Attention机制详解(一)——Seq2Seq中的Attention - 川陀学者的文章 - 知乎 https://zhuanlan.zhihu.com/p/47063917
https://github.com/wangshusen/DeepLearning/blob/master/Slides/9_RNN_9.pdf
http://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/

3. 神经网络为何沉寂多年?一文体会深度学习的巨人之力——反向传播算法
4. 庖丁解牛看循环,图文并茂学原理,万字解析RNN——循环神经网络
5. LSTM是怎么改善SimpleRNN缺点,其作者又为何与主流学术圈分道扬镳?

点个在看你最好看
