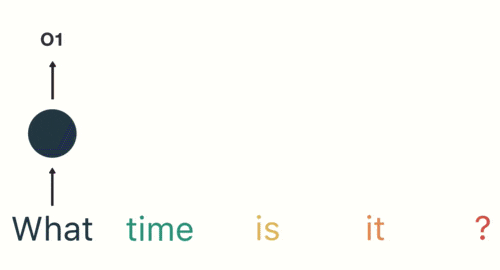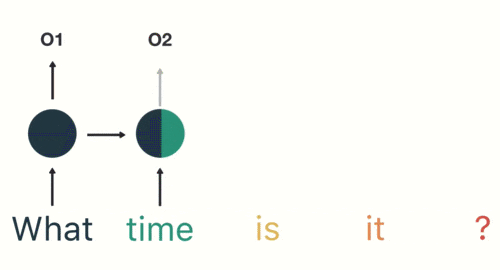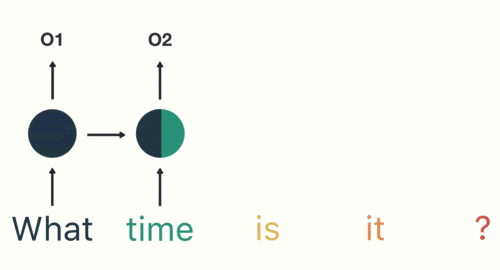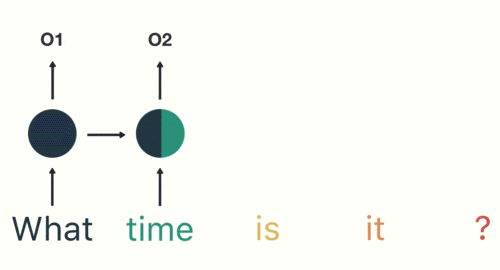大家好,好久不见,请忽略我花里胡哨的文章题目🤗。之前我们一起学习了深度学习神经网络的构建,还了解了通过损失函数来优化模型,在掌握了基本的深度学习知识后,接下来我们一起来看一下神经网络的变体—— 循环神经网络(RNN,Recurrent neural network)
从名 字也 可以看的出来,循环神经网络就是一个循环过程,不断的做递归计算,那么为什么要提出RNN呢?
语言模型是用来评估一段词序列的可能性,即建模一个句子出现的概率。 马尔可夫假设(Markov假设)
Bengio在2003年第一次尝试用神经网络来做对于语言模型的概率拟合,但是传统的前馈神经网络的效果并不好,后来Mikolov 在2010年发表的论文 《Recurrent neural network based language model》正式揭开了循环神经网络RNN运用到语言模型中的序幕。 https://www.fit.vutbr.cz/research/groups/speech/publi/2010/mikolov_interspeech2010_IS100722.pdf
假如我们要处理一段文本序列,对于我们人类而言,看到一段文字会根据之前的文字来理解后面的文本内容,即通过上下文关系来把握一个单词的语义。但是传统的前馈神经网络很难用上下文来表示一个单词,所以就引出了这种天生就适合处理序列任务的RNN。RNN也并不是指单独的一个模型,而是一类模型,一般来说只要是输入一个序列 LSTM , Seq2Seq 都有用到RNN单元。
参考于Luis Serrano 的一个例子来理解RNN,给大家讲一个小故事,
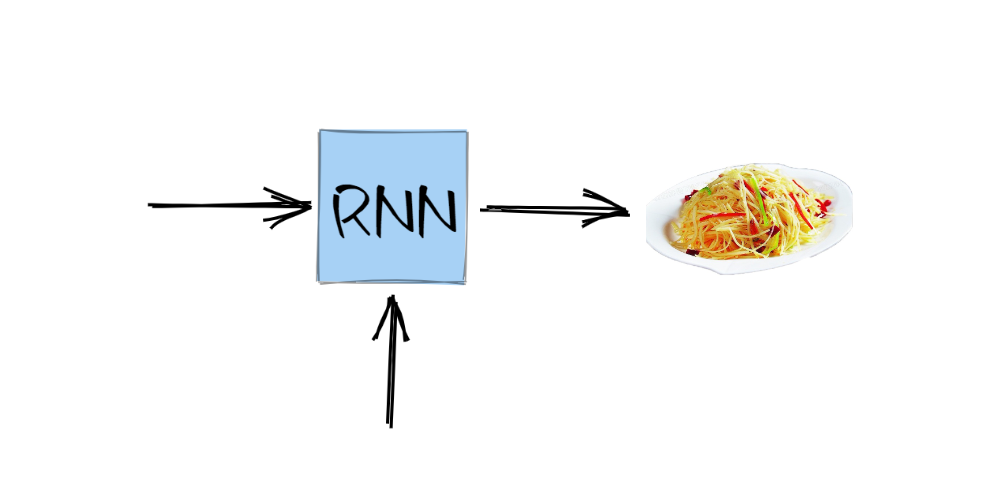
假设你有一位非常好的室友小明👨💼,他特别喜欢做饭,拿手好菜是 土豆丝 、 小龙虾 和 锅包肉.
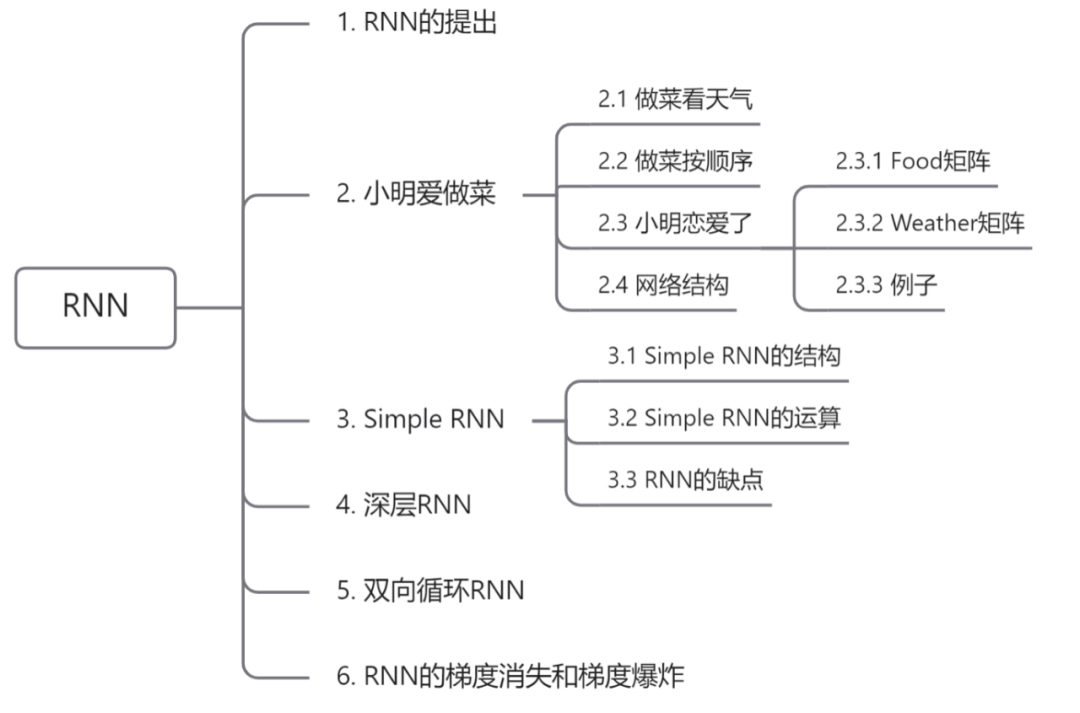
但是小明脾气有些古怪,做什么菜看天气状况来定,当外面是 晴天 时,小明心情愉悦,就做一份土豆丝,简单又下饭。而当外面是 雨天 时,小明就在家做小龙虾,正好打发时间。
将这个规律转移到神经网络中,即输入为晴天时,输出就是土豆丝,输入为雨天时,输出则为小龙虾
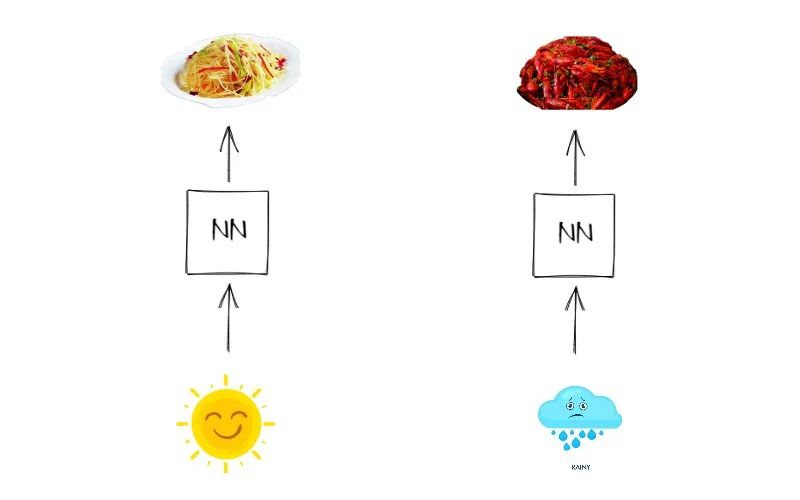
同样的,神经网络的输入需要用数学表示,对于文本可以用 one-hot编码 ,就是将每个单词用一个向量表示,向量的维度是词表的大小。这个方法效率不高且非常容易产生维度爆炸的问题,后来又有了 分布式表示(Distributed Representation) ,这里先不深究。回到故事中,这时候我们考虑将天气和菜用向量表示出来作为神经网络的输入和输出,简单表示如下
有了上面的向量表达,当输入为晴天的
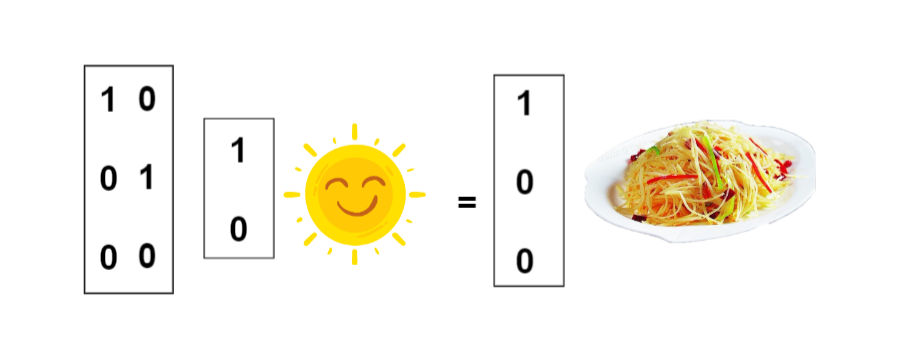
将神经网络的内部展开,即为
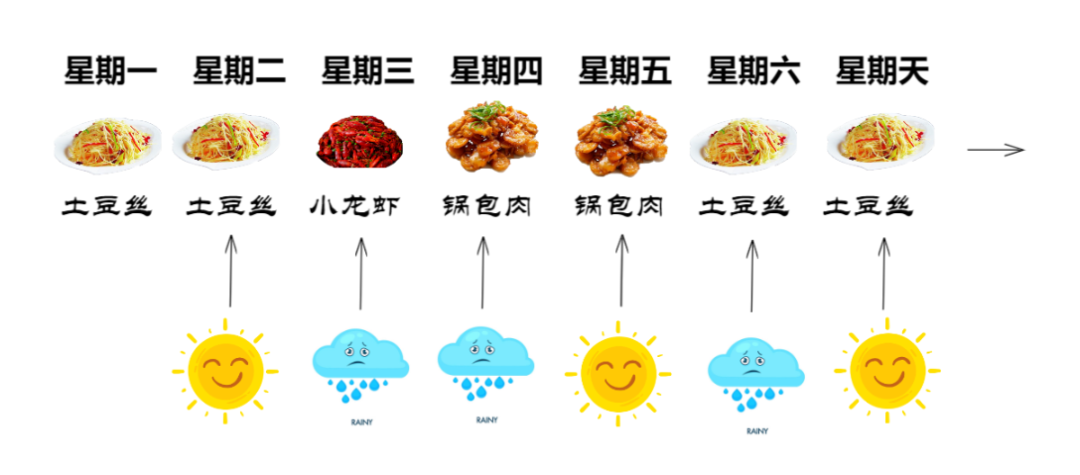
这么看下来这是一个非常简单的线性神经网络,并没有做考虑其它的问题。但是因为经常是晴天,每天吃土豆丝都要吐了,所以小明改为按 时间顺序 来做菜, 第一天做土豆丝,第二天小龙虾,第三天锅包肉. ..,以此循环做这三个菜,假设今天是周一,这一周的菜谱如下
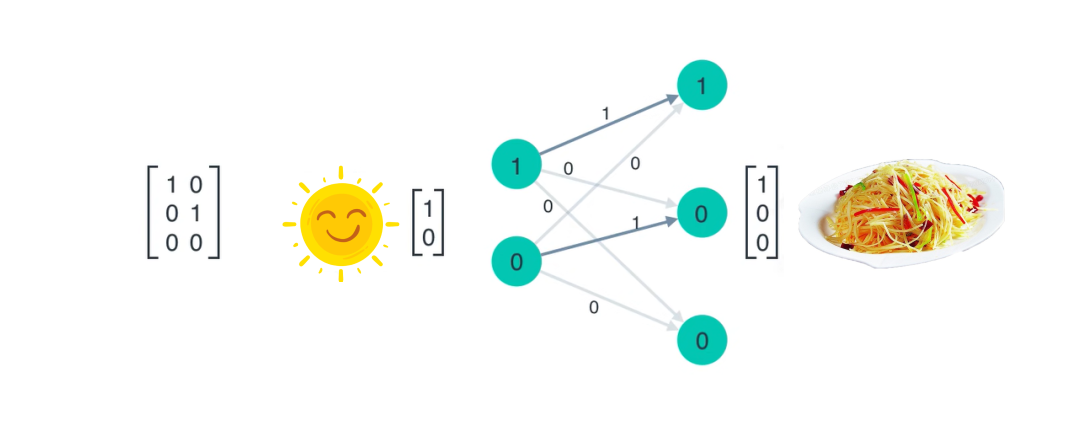
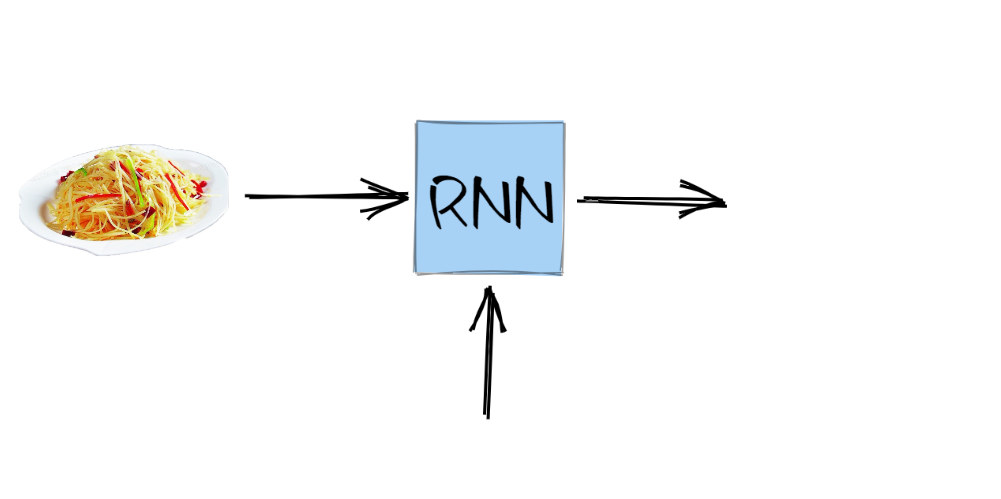
有了这个顺序之后,做什么菜就与 时间步 相关了,这就不再是简单的线性神经网络,而是循环神经网络RNN,因为并不考虑天气,所以其下面箭头的输入暂时为空
第一天小明做完土豆丝之后,第二天需要做什么菜要根据前一天的菜来判断,即第二天将前一天做的菜作为输入
将前一天的菜输入到循环神经网络中,然后输出今天要做什么,即为
这就简单实现了一个根据前一天的菜来判断今天做什么菜的功能,在其网络内部也是做了一个简单的线性映射,只不过其权重矩阵变成了3x3的矩阵,并且输出会作为输入重新导入神经网络中,因此被称为循环神经网络。
过了一段时间,室友小明谈恋爱了💕,做菜顺序还是一样,依次为土豆丝、小龙虾和锅包肉的循环, 但是因为当外面是晴天时,小明要和女朋友一起逛街,所以如果当天是晴天,小明不会做饭,而是将昨天剩下的菜给我们吃😭 , 如果当天是雨天,小明就不会出去,而是在家里,那么他就会做下一个菜。 ok,举个例子,假设今天周一,作为开始今天小明做了土豆丝,第二天周二,小明看到外面是晴天,就约了女朋友出去,所以我们周二要吃昨天剩下的土豆丝,然后第三天依然是先检查天气,才知道我们吃新菜还是剩菜
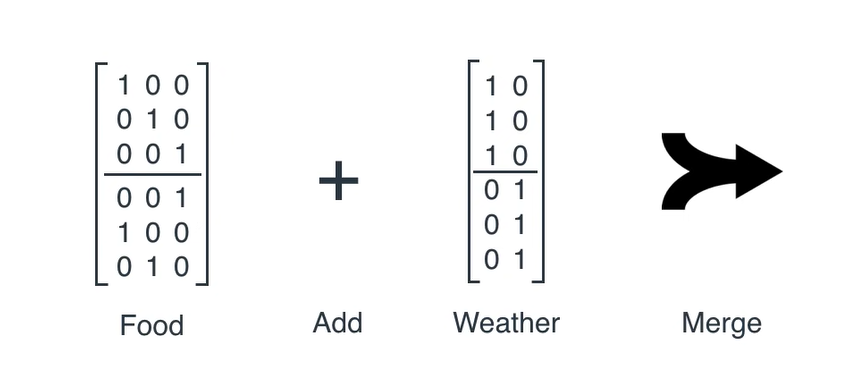
这个过程中,我们每一次都要考虑昨天的菜和今天的天气,将这两个变量输入到神经网络中,才能输出当天吃什么。那这个神经网络的计算过程就比较复杂了,其含有一个Food矩阵和一个Weather矩阵,将这两个矩阵合并
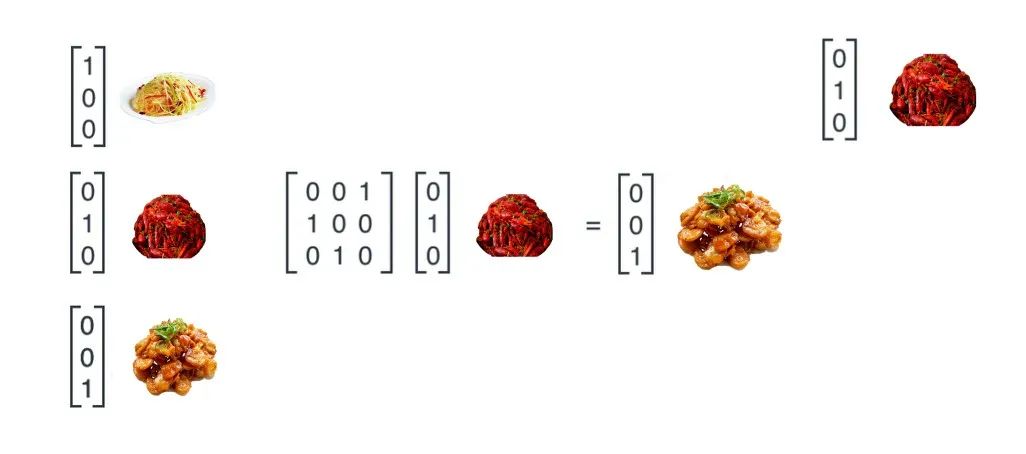
首先来看这个维度为6x3的Food矩阵,前三行为单位矩阵,与任何向量相乘都为向量本身,后三行是刚才我们用到的计算下一个该做什么菜的矩阵,如此一来,当我们用当天的菜的向量表示去与Food矩阵相乘,得到的前三行就是当天做的这个菜本身,后三行则为按顺序的下一个要做的菜
这个 Food矩阵便可以让RNN知道今天做了什么菜,按顺序的下一个该做什么菜 ,实现了做菜的顺序,笔者建议用小龙虾和锅包肉按照上面的方式再算一下,增加理解。那么有了做菜的顺序还要知道当天的天气才能确定当天是做新菜还是吃剩菜,我们再来看Weather矩阵,类比于Food矩阵, Weather矩阵的含义是让我们知道在今天的天气条件下,是吃小明做的新菜还是吃昨天的剩菜。 同样的Weather的前三行为一列1和一列0,与晴天的
现在我们可以得到做菜的顺序和是否做菜,矩阵的维度都是相同的,合并之后会得到一个有意义的结果。举个例子来看这个过程。
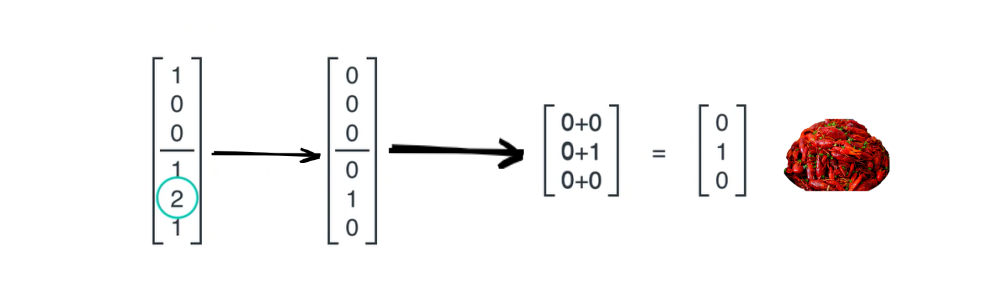
假设昨天小明同学做了土豆丝,但是今天下雨了,那么今天小明同学应该做新的菜即小龙虾
可以看到最后得到的向量最大值为2,那么如何得到做新菜小龙虾的信息呢?既然是神经网络做非线性映射,那怎么能少的了非线性激活函数 呢,这里通过激活函数,将最大的数值映射为1,其余数值映射为0,得到输出的向量,然后将输出的向量前三行和后三行作加和操作,得到接下来的菜——小龙虾
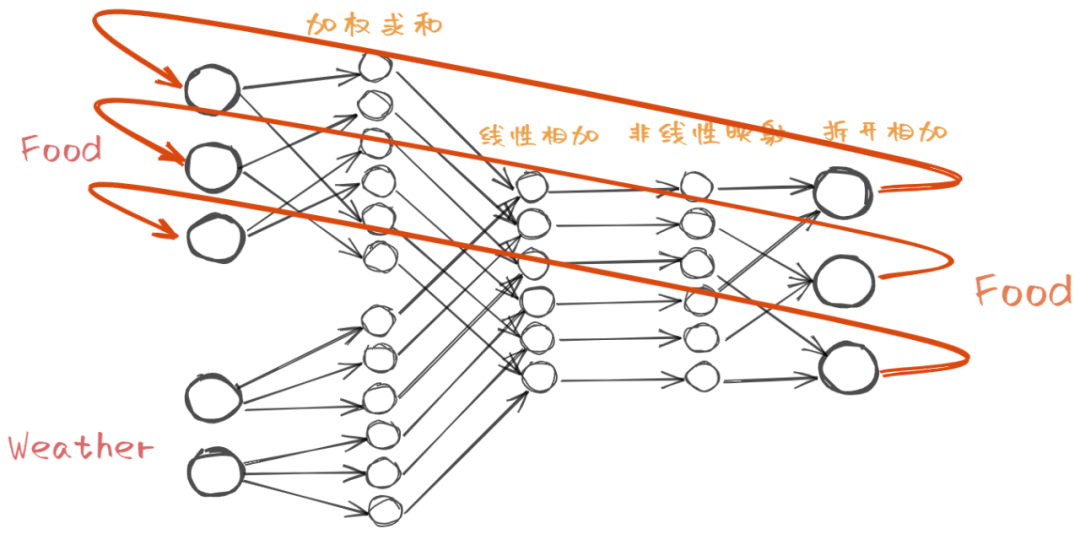
现在整个过程都已经推导完毕,一起来看下如何画出它的神经网络结构图,按照上述步骤, 首先输入的是菜和天气的向量表示,经过与权重矩阵(即Food矩阵和Weather矩阵)加权求和得到两个6x1的向量,将其作加和运算,得到一个含有最大值的向量,对该向量作非线性映射就可以算出一个含有一个1其余全为0的向量,将该向量前三行和后三行相加得到我们的输出,即下一个菜的向量表示 ,结构图如下
这个神经网络的推理依赖于天气和上一个菜,典型的序列问题,相似的还有文本,一个词的含义依赖于前面的词的含义,对于序列这类的数据, 神经网络运行一次得到的输出会作为下一次的输入,这样才叫循环 ,在结构图上表示为
通过这个例子你应该对RNN有了一个大概的理解,下文中提到的都可以与例子中的菜或者天气或者运算过程对应上,建议在继续阅读的过程中,常作对比。
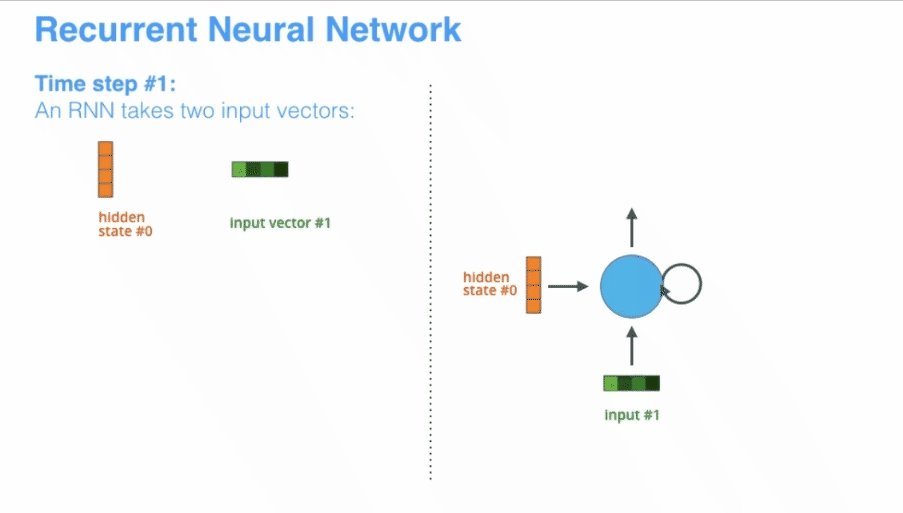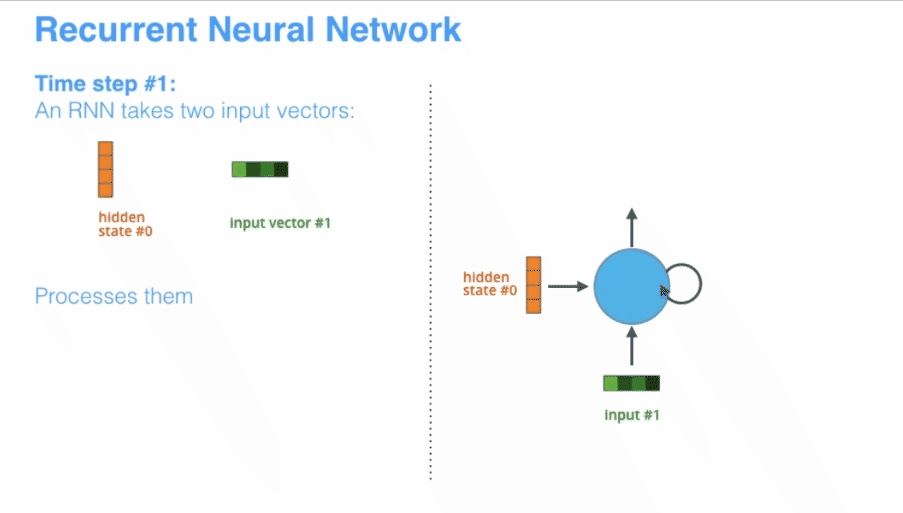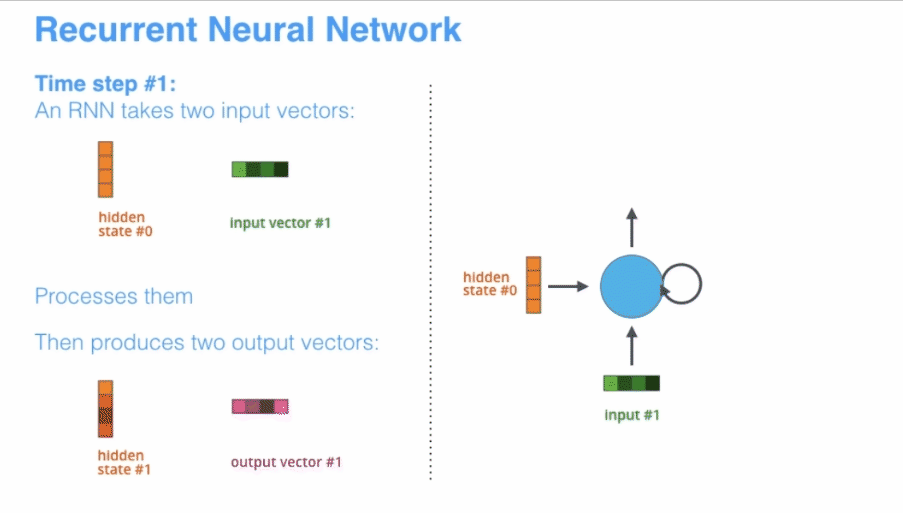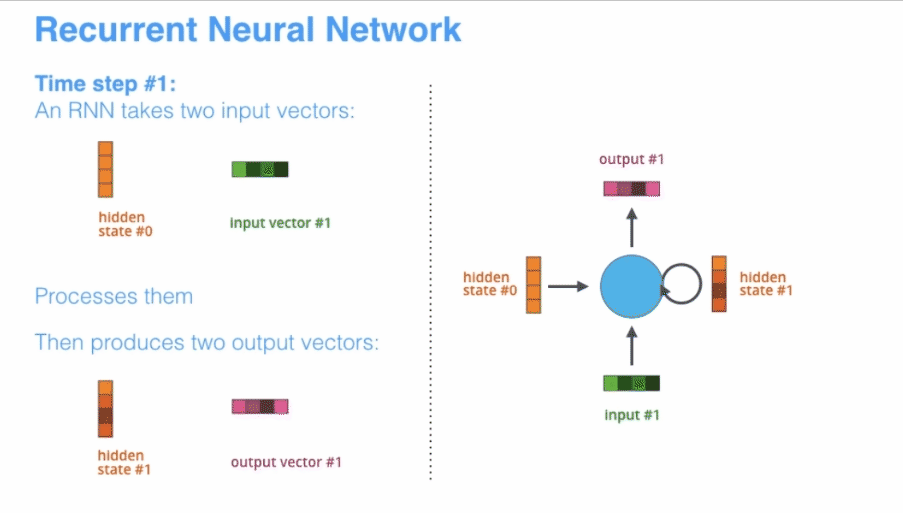
目前在NLP领域,RNN已经过时了,RNN有许多的缺点,在很多问题的表现上不如Transformer模型,但是这并不代表不用学习RNN,技术就是不断的改进而变得强大,作为NLPer学习RNN还是非常必要的。 正所谓春生夏长,秋收冬藏,对于现在的新事物我们不光要知其然,更重要的是知其所以然。 普通的RNN一般也称为Simple RNN ,其输入的是时序型的数据,输入和输出的长度都不是固定的,这就非常适合处理文本、语音和时序类的数据,RNN可以“记住”前面的输入,这就为“理解”文本打下了基础,首先来看一下RNN的基本表示
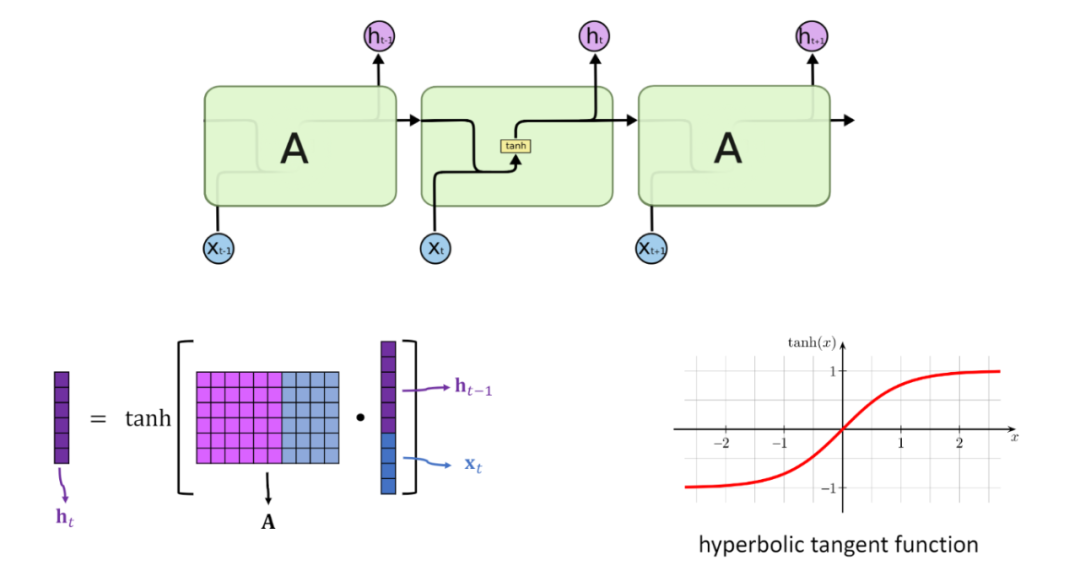
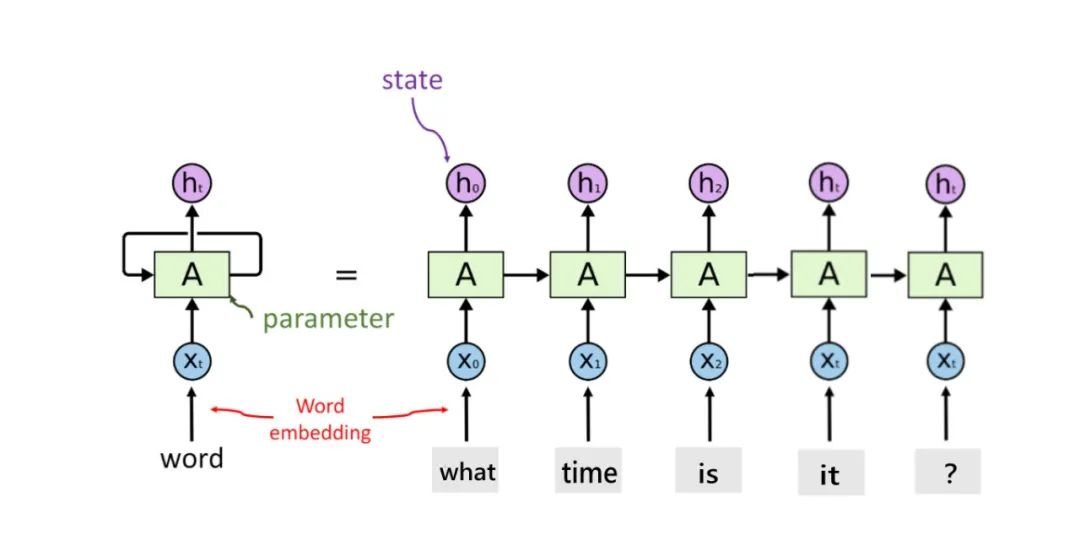
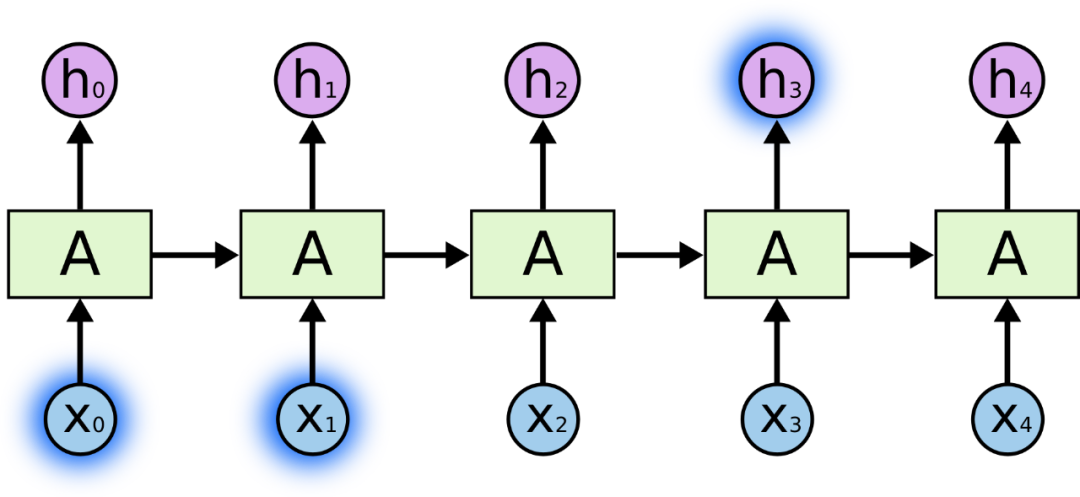
单个的RNN就是这么一个带有循环的结构,前文中的网络结构的严肃表示,这个循环的结构天生适合处理有顺序的数据。其展开结构如下
展开后的RNN看起来复杂,但是其实与普通的前馈神经网络相比并没有特别大的改变,可以认为是神经网络的叠加,网络与网络之间传递数据。x作为RNN的输入,输入到RNN以后会更新状态向量h,总的来说,RNN就是将输入向量x和状态向量h结合后,经过激活函数,然后产生新的状态向量 。公式为 其中A是RNN的参数矩阵
A是一个参数矩阵,在更新状态h的时候会用到参数矩阵A,整个RNN中只有一个参数矩阵A。A在模型建立的时候随机初始化,根据读入的数据不断进行训练,慢慢进化到一个合适的参数矩阵。如何更新状态呢?首先一个状态的更新是根据前一个状态和当前的输入共同决定的(也就是之前故事里的前一天的菜和当天的天气),有了这两个数据还要做一个非线性映射,也就是激活函数,具体过程如下
这样再来看下前文提到的公式就很清楚了
假设我们将一个词用word embedding表示为词向量,(这部分是关于语言模型的知识,像上文中提到的表示用向量表示菜和天气一样,里边涉及到挺多内容,挖个坑,有时间会把这部分补上,按理来说语言模型可以说是现代NLP的基础,不过无伤大雅,这里能理解将词用向量表示即可),将表示好的词向量 输入累积到状态h中 ,这也就是所谓的“记住”上文。比如对于一段话”what time is it?",将其按照方才所说输入到RNN中,状态h中就会逐渐累积我们的文本
图源 https://github.com/wangshusen/DeepLearning/blob/master/Slides/9_RNN_2.pdf
里面包含了what的信息,
图源 https://easyai.tech/ai-definition/rnn/
上面图中就是第二个状态向量中也包含上一个词的信息,所谓“记忆”
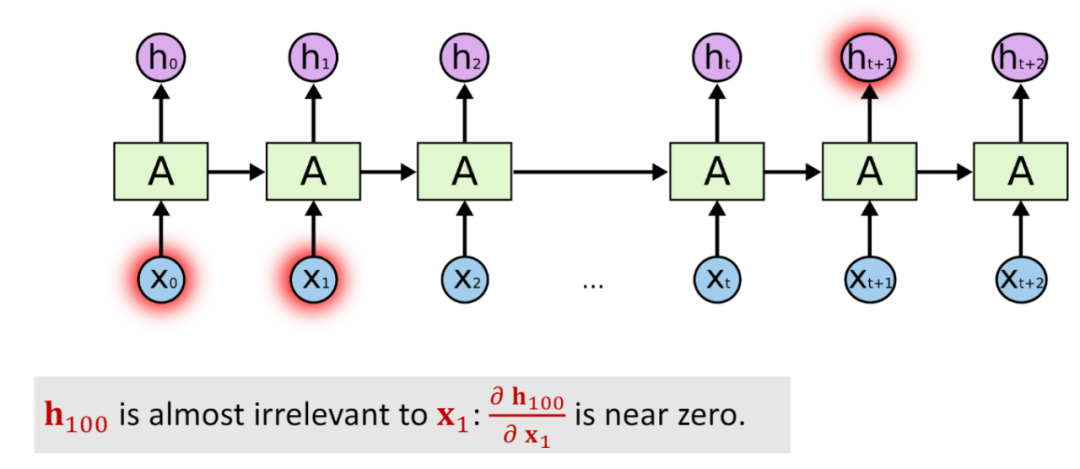
可以看到最后一个状态向量包含了整句话的信息,因此我们会着手处理最后一个状态向量。
通过上面的图可以很清楚的看到RNN的缺点,那就是对长序列的数据处理不佳,最后的状态中短期的记忆影响占比太大,因此会出现“遗忘”的情况。
对于短文本的处理,RNN表现良好,能非常清楚的”记住“前文,信息损失小,因此模型拟合的很好。但是对长文本的处理,RNN就有些力不从心了
所以后来为了改善RNN的“遗忘”问题,又出现了长短期记忆网络(LSTM,Long short-term memory)
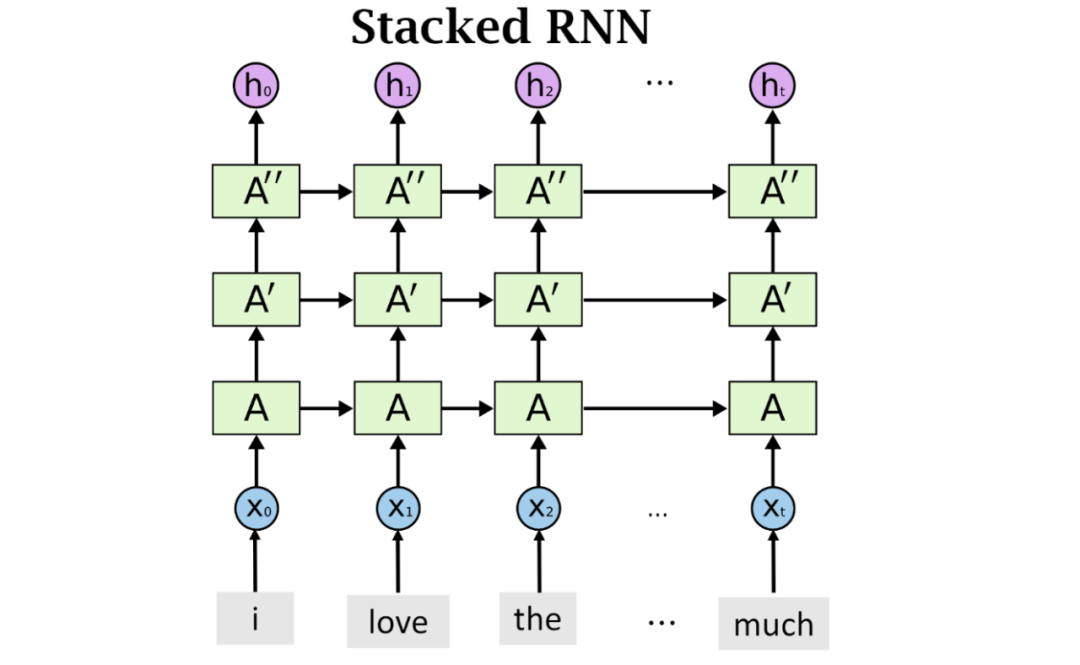
一般当浅层的神经网络效果不好的时候,常想到通过叠加层数来尝试提高模型性能,传统的神经网络叠加就变成了深层神经网络,多个卷积层的叠加变成了深度卷积神经网络,到RNN这里,多个RNN层的堆叠就构成了深层循环神经网络。 原理并不难, 常规RNN每一步输出一个状态向量给下一个时间步,在深层RNN中,将此状态复制一份,一份和之前一样传递给下一个时间步,另外的一份则作为输入传递给堆叠的下一层RNN,这样就在每个时间步实现了多个隐藏层 ,模型学习能力增强
深层RNN的模型效果在数据量比较大的时候会显现出来,因为其模型复杂,参数量大,因此当数据足够多的时候,模型参数能训练的更精准,模型拟合的也更好。
在中学语文课本里我们都学习倒叙和插叙的写作手法,这种写作手法并不是按照顺序来叙述一段故事,但是我们在阅读的时候并不会感觉到太困难。同样的,小说和电影中也有非线性叙事的手法,我最喜欢的诺兰导演就是非线性叙事的高手,其电影情节扑朔迷离,韵味十足。 回到RNN上面,我们在理解一段文字的时候一般从左向右顺序阅读,但是有些从后向前看也可以理解,而对于普通RNN而言,其特别依赖自左向右的顺序,这就会产生一些问题,比如一段文字”饿死我了,我想__一个面包。“ 在这段文字中,如果从左向右来判断横线上的词汇,普通RNN可能会预为“哭”,“吐”,“买”...,这就是没有考虑到后面的文字,如果模型也学习到了横线后的”一个面包“,就更有可能预测为“吃”,这样就更符合语义了。 那么如何去让RNN也学习后面的词呢?还是从普通RNN出发,既然当前时间步是考虑上一个时间步的状态和当前的输入,这样就学到了上文的信息 ,那如果在加一个反向的RNN,上一个时间步不就变成了下文的状态了吗。这就是双向循环RNN(Bidirection RNN),
两个RNN互相独立,并不共享参数,有各自的状态,将各自输出的状态拼接起来作为向量y,此时如果还叠加了多层RNN,y就作为下一层RNN的输入向量,如果并没有叠加多层,那么类似的只考虑两层最后的状态向量
看了许多文章感觉还是苏神写的比较清楚,这里参考一下作为这部分的内容。 RNN中存在的一个严重问题就是梯度消失和梯度爆炸,因为RNN通常都比较深,这源于处理的序列类型的数据。在前文提到每一个时间步会考虑上一个时间步的状态 这个求梯度的公式也很有意思,居然也是类似于RNN的一种, 当前时间步的梯度 。而且观察这个公式, 历史的梯度信息 ,那么 当历史梯度衰减时,因为循环的公式结构则会一直衰减下去,所以梯度随着步数的增加,梯度必然消失 。 当 那么当历史梯度增加的时候,梯度值慢慢趋向于NaN,也就是梯度爆炸,比较容易理解。但是对于梯度消失来讲,这并不代表梯度值为0,而是趋向于0,比如当出现梯度消失的问题时,
总之,梯度消失和梯度爆炸的一个根本原因就在于 每个时间步上都使用共享参数矩阵A,那么当偏导数中存在参数矩阵A的指数形式的时候,如果参数矩阵A或大或小,就会导致梯度消失和梯度爆炸 。推荐阅读苏神的文章解释,最后我会给出参考链接。
Reference
https://www.youtube.com/watch?v=UNmqTiOnRfg&ab_channel=LuisSerrano
https://github.com/wangshusen/DeepLearning/blob/master/Slides/9_RNN_2.pdf
https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
苏剑林. (Nov. 13, 2020). 《也来谈谈RNN的梯度消失/爆炸问题 》[Blog post]. Retrieved from https://kexue.fm/archives/7888
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://easyai.tech/ai-definition/rnn/
希望下次再吃小龙虾和锅包肉的时候能想到“做菜看天气,后来按顺序”的小明同学,RNN PTSD🙈
以上便是本文的全部内容了,希望能给到你一点点的帮助🐞。
往期推荐