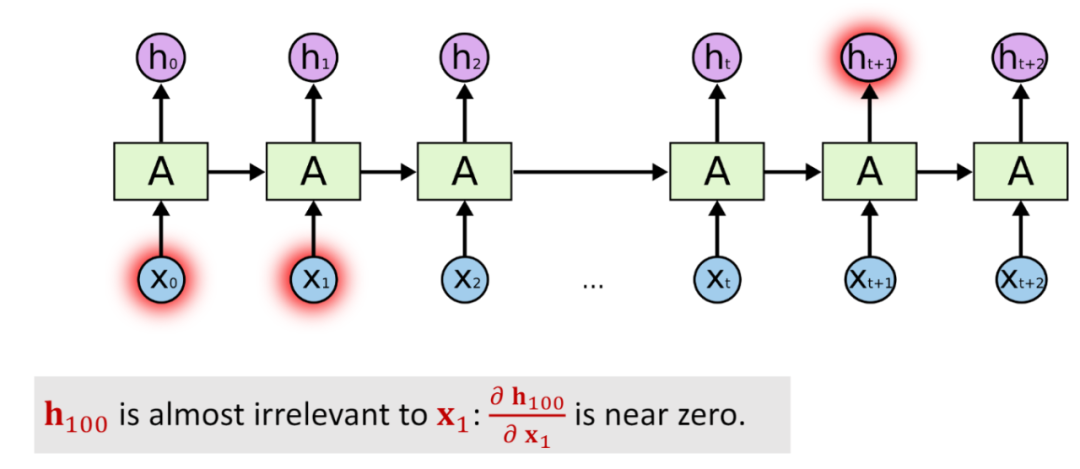
大家好,上篇文章和大家一起学习了RNN,最后提到了RNN的一些不可避免的缺点,那么LSTM(长短期记忆,Long short-term memory)如何改进这些缺陷,一起来学习下吧。
推荐阅读,以便新老朋友丝滑入戏
庖丁解牛看循环,图文并茂学原理,万字解析RNN——循环神经网络
文章大纲
关于循环神经网络RNN的一些缺陷,一个就是共享参数矩阵,导致在进行反向传播计算梯度的时候,很容易会得到一个指数形式的式子,一旦参数矩阵的值或大或小的时候,在指数的作用下就轻轻松松的产生梯度消失或者梯度爆炸的问题。因此,LSTM就是来改善RNN的这个缺陷。同时,RNN还有长期依赖问题,简而言之就是对于长序列会产生“遗忘”的问题,处理过程中可能忘记距离较远的词,比如一段文本,刚开始的有一句话,“我是一个中国人”,中间间隔了很多的词,到一定距离之后,RNN对一句话进行预测,比如“我会说__”,这时我们人类在阅读的时候,一定会记得前边的中国人的背景,所以会自然的想到这个词应该预测为中文。但是对于RNN来讲,它只会根据距离较近的一些词来做预测,因此可能预测为某一种语言,如此就使得模型的效果不好,这便是LSTM改善RNN的另外一个地方。
接下来就一起来看看LSTM的具体内容吧。
之前提到过,RNN并不是指特定的某一个模型,而是指一类模型,可以理解为一种结构,凡是使用了这种特定的结构的模型都称为RNN,LSTM就是使用了这种RNN结构的一种模型。其实早在1997年LSTM的论文就发表出来了。
https://ieeexplore.ieee.org/abstract/document/6795963
发明LSTM就是这位大佬 Juergen Schmidhuber

这里边还有一些很有意思的故事,就是这个大佬与主流的学术圈分道扬镳,而且和Hinton老爷子他们那一派一直有些恩怨,在学术界公开撕了好多年,从深度学习圣经——花书中也可以看出端倪,LSTM对应的章节仅仅只有两页😂,大家感兴趣也可以在网上搜一下。(人类的本质就是“八卦精”😬)
不管作者如何,毋庸置疑的是LSTM对SimpleRNN的改进还是非常明显的,在transformer没有出现之前,基于LSTM的模型一直是NLP领域的SOTA。
作为比较先来看下SimpleRNN的结构图
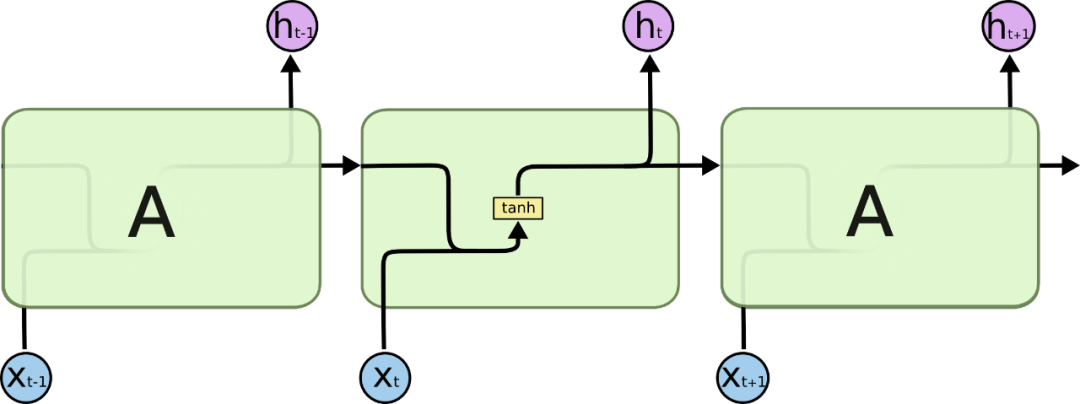
像上一篇文章中讲的那样,SimpleRNN循环单元内部的计算比较简单,仅是将上一个状态和当前的输入一起和参数矩阵做一个计算,现在来看下LSTM的结构图
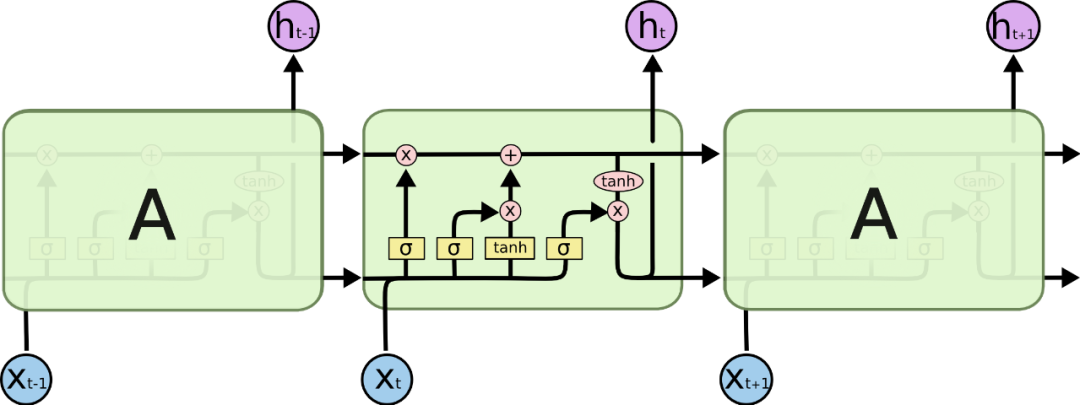

可以看到,LSTM其实就是在循环单元内部计算上面做了一些复杂的改进,这里面用到了4个参数矩阵,这样来改善共享同一个参数矩阵的情况。LSTM的精髓可以认为就是那一条计算过后的”传送带“,在这条传送带上有一个新的向量C(记忆细胞,Memory Cell),有的还称为一种特殊的隐藏状态,之前模型学习到的信息通过传送带传送到下一个时间步,而传送带控制信息的传送则是使用了“门”结构,接下来就一点点的剖析LSTM的内部结构。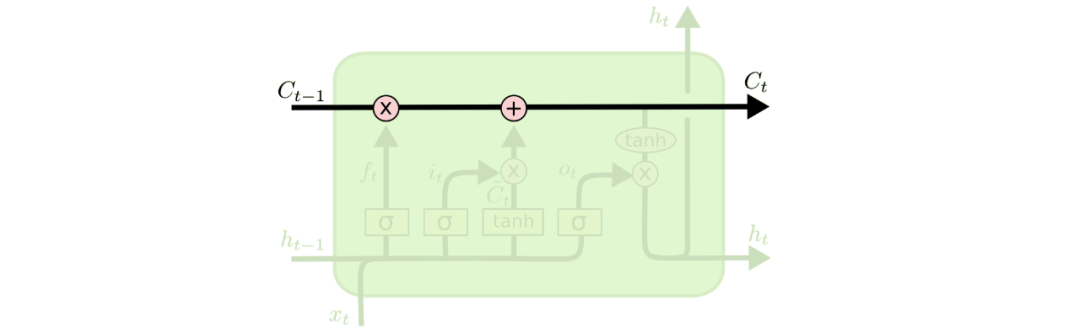
首先循环单元内部的第一个门结构是“遗忘门”
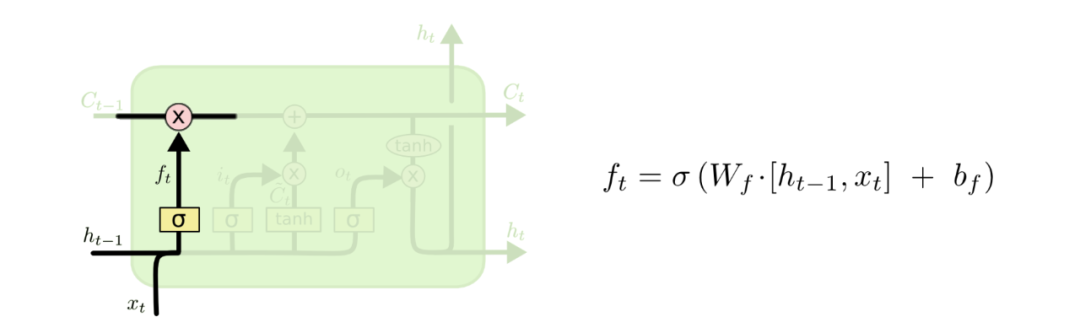
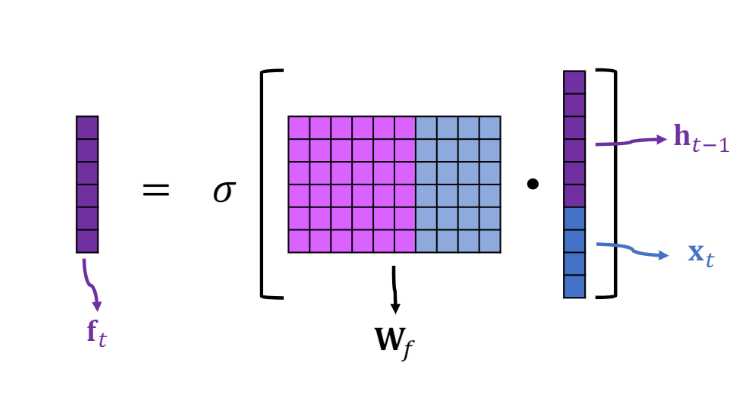
其中σ代表了sigmoid函数,之前的文章都有提到,而红色圈中的×代表了Elementwise multiplication计算,即逐元素相乘。
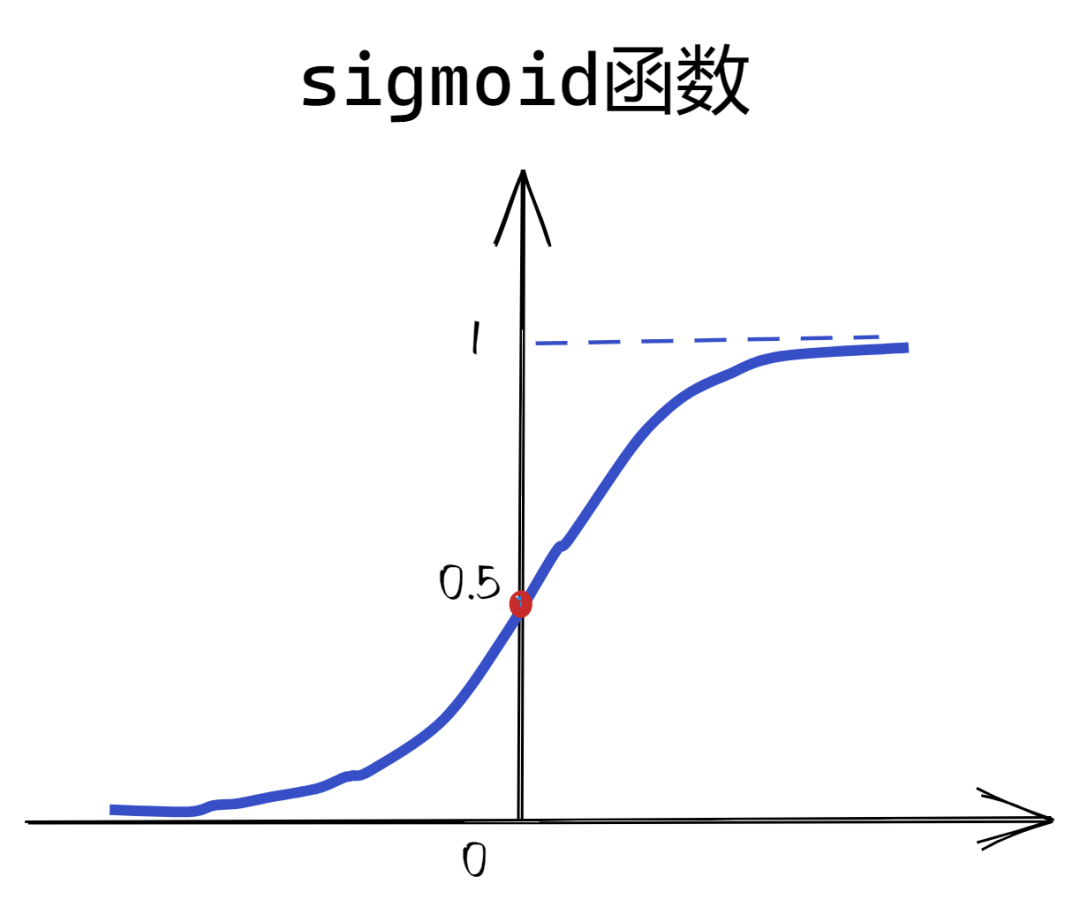
sigmoid函数将向量的值映射到0,1之间,这个数值代表了是否要遗忘该元素,即当值为0时,代表完全忘记该元素,为1时则代表完全记忆这个元素,如此一来就可以控制接收的 的值能否通过。
就是一个值为0,1之间的向量, 是上一个状态, 是当前时间步的输入, 是偏置项, 是遗忘门的参数矩阵,在建模开始会有一个初始值,然后在训练过程中通过反向传播不断调整其值,在不考虑偏置的情况下,计算公式和SimpleRNN中的一样,这部分没什么变化,就是下面这张图
第二个门结构是“输入门”
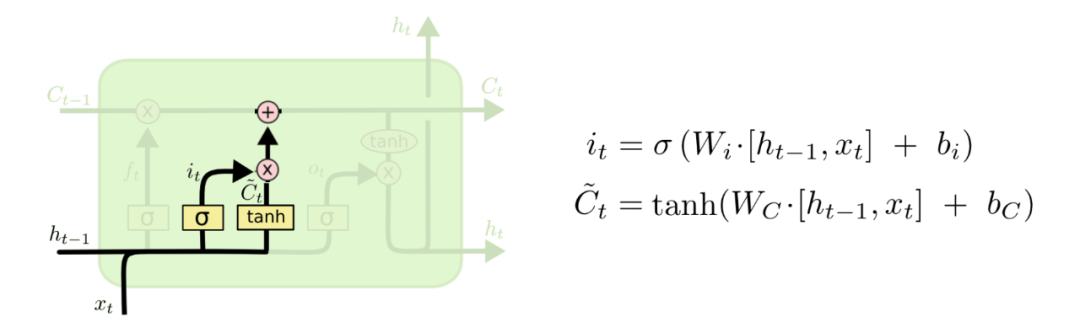
在输入门中有两步计算,第一步是向量 ,将上一个时间步的状态和新的输入做一个拼接,再与新的参数矩阵 相乘,加上偏执项后做一个sigmoid激活。所以向量 的值也都是介于0,1之间,这个向量的作用是控制我们要更新哪些值,也就是说对于之前学习到的信息哪一些需要更新一下。举个例子,比如之前学习到的信息是一个人18岁,在读入新的输入和上一步的状态后,可能要将这个信息更新为19岁,这就是向量 要做的事情。
第二个式子是计算new candidate values ,与上一步不同的只是在于激活函数换成了tanh函数,当然了相对应的参数矩阵和偏置向量都是不同的。
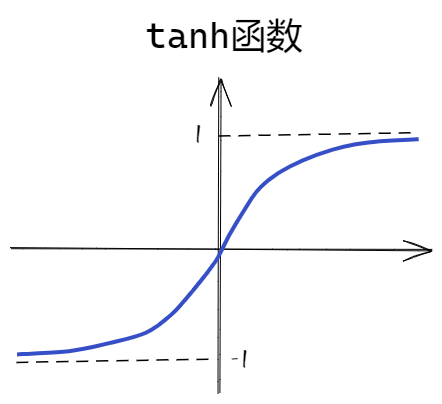
tanh函数会把值映射到-1,1之间, 表示要在传送带上增加什么信息。
有了 和 之后还是将二者做一个Elementwise multiplication计算,计算得到的结果与遗忘门的结果做一个加和
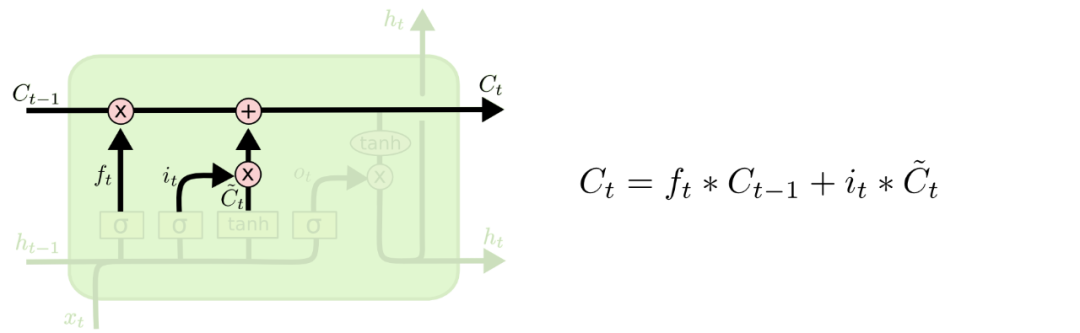
这一步就是在传送带上选择忘记 的哪些信息,还有在新的 更新哪些信息。
最后一个门是”输出门“
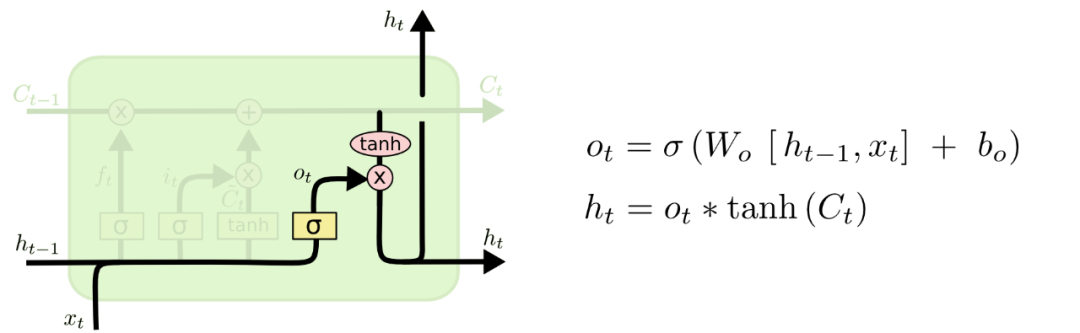
有了前面两个门的理解,再看这个门也就清楚了,公式都是一样的,区别仅在于参数不同, 是输入门的参数矩阵,也是需要在训练数据中学习的。
最后的门来计算LSTM的输出,状态向量 。在这里LSTM是自己控制了是否更新隐藏状态h,通过输出门里面的参数矩阵,可以不断地学习到是否更新,而在RNN中是所有的循环单元都输出隐藏状态,因此无法避免梯度消失问题。
首先还是计算输出门,利用sigmoid函数将其映射到0,1之间,然后将传送带上的向量用tanh函数映射到-1,1之间,二者相乘,得到最后的状态向量,这个状态向量就是学习到了所有的信息。这个状态向量进行了一个copy操作,一份输出给下一个时间步,另一份作为LSTM的输出。
上面就是LSTM的三个门介绍,首先计算遗忘门,然后计算输入门和一个待输入的状态 ,再使用输入门和待输入的状态更新LSTM的记忆细胞C,最后使用更新后的C结合输出门得到最后的隐藏状态h。可以观察到,所有的公式计算最后得到的值都是在0,1之间或者-1,1之间,这就使得在计算门结构的时候可以很方便的进行反向传播,便于更新参数矩阵。下面的图是前文的总结 
看到这里可能你还是不理解LSTM只是比SimpleRNN多了一个向量C,为什么能改善遗忘的问题?笔者是这么理解的,C向量可以认为是LSTM在序列中学习到的信息,这些信息可以输出也可以保留,而h是确定要输出的,在循环单元中逐个流通。对于SimpleRNN,只有隐藏状态h和当前的输入,而这些都要与一个参数矩阵A做矩阵乘法,还要经过tanh激活函数,这样一计算,学习到的信息会丢失一些,而整个RNN是循环计算的,那么到更深层以后,前面学习到的信息损失的就太多了。而LSTM引入了向量C后,这里并没有做矩阵乘法计算,而是做的逐元素相乘的计算且与之相乘的是0,1之间的数,这样就使得之前学习到的信息损失较少,信息损失少自然记忆的信息就多,也自然可以改善遗忘的问题,希望这段解释能让你清楚一些。
至于LSTM为什么这么设计,笔者在网上希望能在各大佬的博客或视频中寻找答案,但是很遗憾,没有找到为什么这么做,甚至作者本人也不能给出一个合理的解释,这也是深度学习中的一个常态,很多SOTA的技术都有着不可解释性。
还有很多基于LSTM的改进,其中GRU(Gate Recurrent Unit)是比较流行的一个,大家有兴趣可以自行查找,探索这段发展历程也是一件非常有意思的事情。
Reference
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://github.com/wangshusen/DeepLearning/blob/master/Slides/9_RNN_3.pdf
苏剑林. (Nov. 13, 2020). 《也来谈谈RNN的梯度消失/爆炸问题 》[Blog post]. Retrieved from https://kexue.fm/archives/7888
如果感觉写的还不错的话,求赞求关注。
以上就是本文的全部内容了,希望能给到你一点点的帮助。🐌
分享知识,记录生活,一起进步

往期推荐