





 第 25 篇 | LINSHIYI
第 25 篇 | LINSHIYI 
3.3 include/, x64/,bin/

include/, x64/, bin/
(1)include
include下存放的是C++的头文件(Header Files),头文件的后缀一般为.h或.hpp,文件中通常包含函数和变量的声明,我们在编写源代码时可以通过#include命令导入相应的头文件。
有关头文件的更多内容推荐看这一篇教程https://www.learncpp.com/cpp-tutorial/header-files/
(2)bin、lib 和 static 的位置
bin和lib文件夹都存放在x64(或x86)中的vc文件夹下,x64和vc文件夹的具体内容见 OpenCV配置攻略(一):OpenCV, VC++和VS,这里不做过多解释了。
OpenCV配置攻略(一):OpenCV, VC++和VS,这里不做过多解释了。
直接拿OpenCV3.4.10->x64->vc15举例,该文件夹下有bin和lib两个文件夹,在2.x版本中,还会存在名叫staticlib的文件夹。
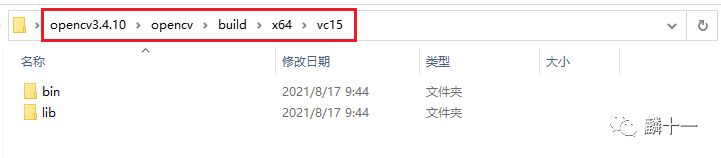
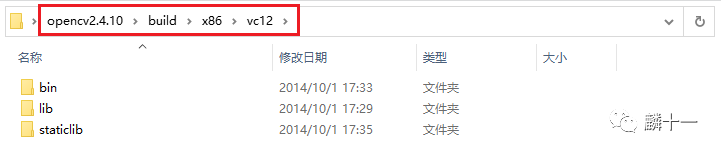
OpenCV2.4.10->bin, lib和staticlib
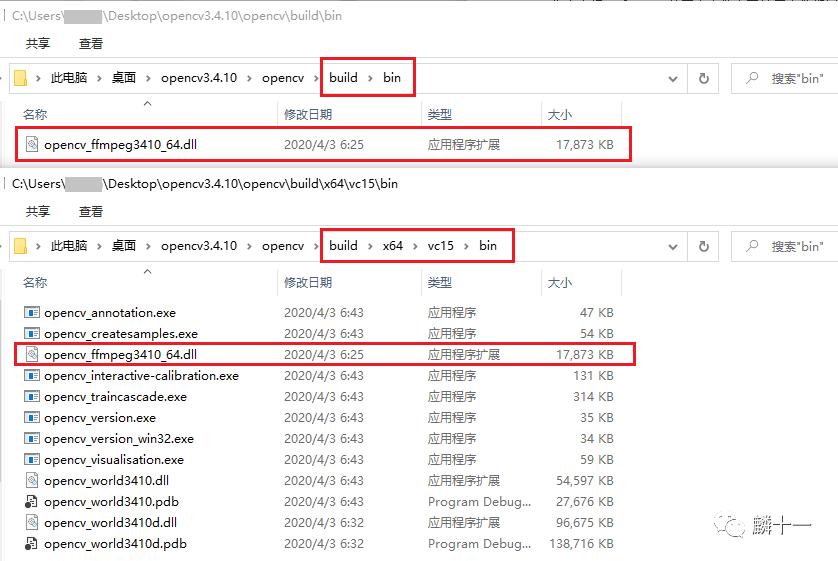
两个opencv_ffmpeg3410_64.dll
(3)C++编译的4个步骤

为什么说Python是一门动态语言?
“链接”过程示例
最后说一说跨文件的依赖关系,在一些复杂的项目中,源文件往往不是孤立存在的,比如A.cpp调用了B.cpp中定义的函数、B.cpp调用了其他的库文件等等。链接器在这里的作用就是保证这些函数、变量、文件等都可以被正确地调用,即拥有跨文件依赖关系的文件都被正确地“链接”在一起。
(4)库文件
A library is a collection of pre-compiled object files that can be linked into your programs via the linker.
这里提到的库(Library)可以被看作一些目标文件(Object
File)的集合,还记得吗?目标文件是“汇编”这一步输出的二进制文件,后缀是.o或.obj (定义来自 https://www3.ntu.edu.sg/home/ehchua/programming/cpp/gcc_make.html)
(定义来自 https://www3.ntu.edu.sg/home/ehchua/programming/cpp/gcc_make.html)
库的存在可以让我们在使用一些算法模块时省去重新编译的麻烦,而且库是二进制文件,我们打开它只能看到一堆0和1,所以库也可以起到保护程序源代码的作用。
在OpenCV2.4.10安装包中,我们可以看到staticlib文件夹下保存了很多后缀为lib的静态库,例如opencv_calib3d2410d.lib、opencv_core2410.lib等。这里的calib3d、contrib、core都是OpenCV的算法模块,例如calib3d可以实现相机校准,contrib可以实现人脸识别等等。
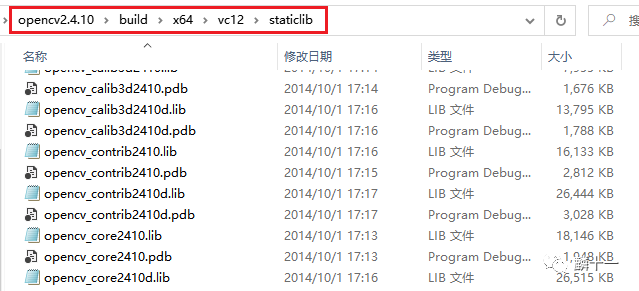
OpenCV2.4.10->staticlib文件夹(部分)
在OpenCV2.x中各个模块的库文件还是分开的,在3.x和4.x中,所有模块都被打包成了一个库文件,并统一命名为“opencv_worldxxxx.dll”。下图是OpenCV3.4.10的动态库:opencv_world3410.dll和opencv_world3410d.dll。
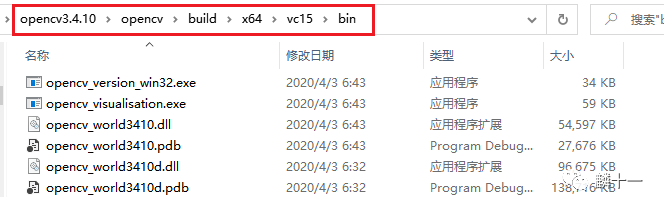
OpenCV3.4.10->bin文件夹
刚刚说到了静态库和动态库,在OpenCV2.x安装包中的staticlib文件夹中存储的是静态库(Static Library),这个文件夹在OpenCV3.x和4.x中都已经没有了,如果需要的话只能自己通过源代码编译。
OpenCV2.x,3.x和4.x中都存在bin和lib文件夹,其中bin文件夹下存放的是动态库(Dynamic Library),lib文件夹下存放的是导入库(Import Library)。
前文讲述C++执行过程的时候提到第四步是“链接”,即将所有的目标文件合并生成一个可执行程序的过程,链接有两种方式:静态链接和动态链接。静态链接需要用到静态库,动态链接需要用到动态库和导入库。
(5)静态链接和静态库
(5)和(6)中引用的3段定义都来自https://www.learncpp.com/cpp-tutorial/a1-static-and-dynamic-libraries/ 这篇教程中详细介绍了静态库、动态库和导入库的概念,有兴趣的同学可以看全文。
静态库可以被看作许多目标文件(汇编器生成的.o或.obj文件)的集合,它包含了所有函数的声明和具体实现。在Windows下静态链接库的扩展名是.lib,在Linux下一般是.a。
静态链接就是在“链接”这一步将“程序调用的”、“静态库中的”机器代码复制进可执行程序中。这样做的好处在于链接器生成的可执行程序已经具备了执行该程序所需要的所有内容,该程序可以独立运行,不再依赖库文件,而且由于少了查找、调用库文件和函数等步骤,程序的运行速度会比较快。
当然,静态链接也存在缺点,首先由于可执行程序中包含了库文件中的代码,所以文件体积会很大;其次,假如我们有多个项目,生成了多个可执行文件,每一个可执行文件都调用了库文件example.lib中的内容,那么库文件的代码就会被复制进每一个可执行文件中,造成无意义的空间浪费;还有一点就是扩展性问题,当某个库文件发生了变化,必须对所有文件进行重新编译,生成新的可执行文件,如果我们开发的是一款产品的话,在每一次更新之后,开发者都需要重新编译整个项目,再进行部署和发布,而用户都需要重新下载整个应用程序,费时费力。
(6)动态链接、动态库和导入库
An import library is a library that automates the process of loading and using a dynamic library.
导入库都存放在名为lib的文件夹下,由于动态链接在“运行”这一步才会调用动态库,所以在“链接”时就需要导入库来告诉可执行文件有关动态库的地址、索引等信息。换句话说,动态链接生成的可执行文件与动态库的交互,就是依靠导入库完成的。
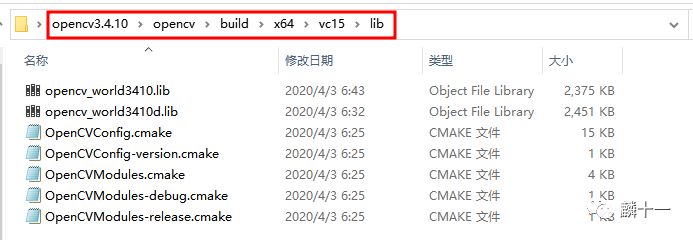
OpenCV3.4.10->导入库(后缀为lib)
A dynamic library (also called a shared library) consists of routines that are loaded into your application at run time. When you compile a program that uses a dynamic library, the library does not become part of your executable -- it remains as a separate unit.
动态库存放在名为bin的文件夹下,在可执行程序“运行”时被调用。与静态链接生成的可执行程序相比,由于不需要复制大量的函数代码,动态链接生成的可执行程序会小很多;而且每一个库文件都是相对独立的存在,当多个应用程序使用同一个库时,内存中只需要一份库文件供所有程序调用就可以了,不必像静态链接那样给每一个应用程序复制一次代码,这大大节省了磁盘的空间;此外,当库文件有更新时,开发者也无需编译整个项目,只需要替换掉库文件,用户也只需更新库即可,这样对于程序的升级和部署都更加友好。
OpenCV3.4.10->动态库(后缀为dll)
动态链接的缺点在于运行可执行程序时,必须依赖相应的动态库,而且查找、定位、调用文件和函数的过程会减慢程序的执行速度。虽然速度会慢一点,但是整体来说,动态链接还是更受欢迎的链接方式。
在Windows下,导入库的后缀是.lib,动态库的后缀是.dll,在Linux下,后缀为.so的文件既是导入库也是动态库。
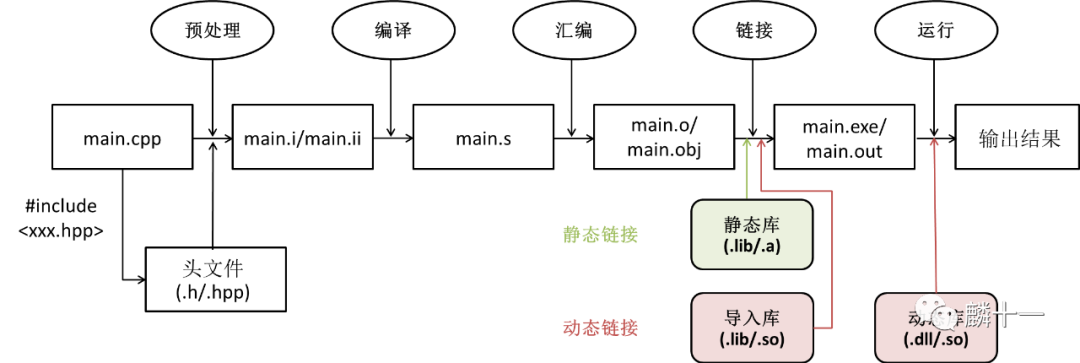
C++编译过程示意图
我把上两节的内容汇总了一下,画了一张示意图,希望能够帮助读者理解,被水印挡住的文字是“动态库”。了解了不同库文件的位置和作用,我们在配置OpenCV环境的时候思路就会很清晰了。
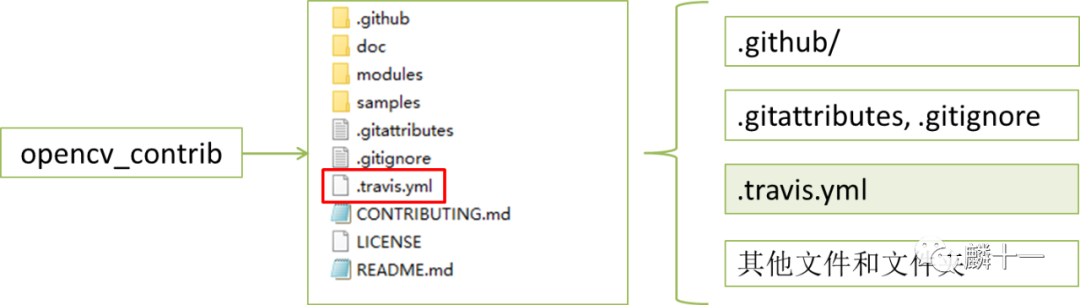
4.1 .github/
.github/
.github文件夹下有ISSUE_TEMPLATE.md和PULL_REQUEST_TEMPLATE.md两个文件,这是两个模版文件。先来说第一个issue_template.md,从文件注释中我们就能理解这个文件主要是用来报告bug的:
当我们发现了源代码中的bug,就可以按照这个模版给出的格式来描述具体的问题,并反馈给项目团队。
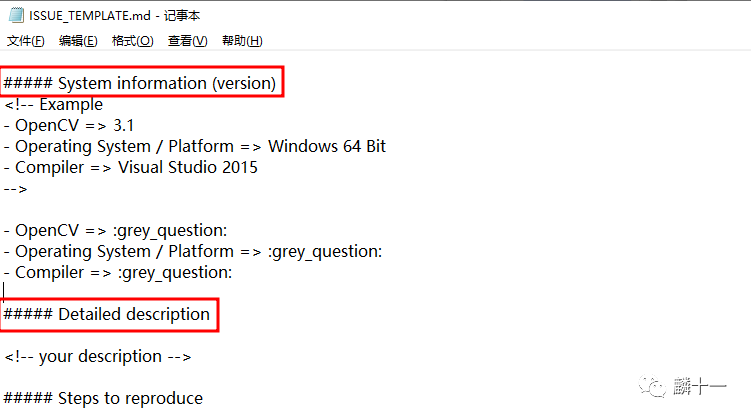
ISSUE_TEMPLATE.md
pull_request_template.md就是当我们对于源代码有了新改动的时候需要提交的内容模板。先来看看什么是pull request,官方文档中这样解释(https://docs.github.com/en/github/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/about-pull-requests):
一句话总结:pull
request就是发起一个请求,请求将自己的代码加入其他人的项目中去。
 PULL_REQUEST_TEMPLATE.md
PULL_REQUEST_TEMPLATE.md拿OpenCV举例,如果我们对于源代码有了改进(比如修正了bug,写出了新算法),就可以将自己改动后的代码连带改动说明(pull_request_template.md)一同pull request给开发团队,开发人员在看到你的改动之后会进行代码检查和讨论。如果你的代码可行,就会被合并入OpenCV的源代码中,你也会被当作此项目的贡献者(Contributor)之一。
.gitignore是一个文本文件,Git官网中给了(https://git-scm.com/docs/gitignore)这样的定义:
当我们使用Git将本地仓库中的项目上传至GitHub远程仓库时,如果不想上传某个目录或者文件,就可以创建.gitignore并写入不想上传的目录或文件名称,这样Git在上传时就会忽略这些特定的文件。
上述定义中的untracked files专业翻译是“未被纳入版本管理中的文件”,简单理解就是“还没有上传至远程仓库的文件”。换句话说,.gitignore中的内容对还没上传的文件有用,对于已经上传并存在于远程仓库中的文件没有用。简单来看一下.gitignore中的内容:
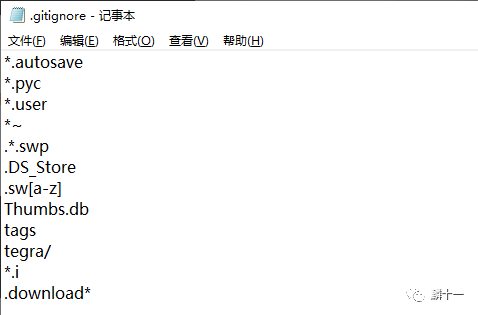
.gitignore的内容
这里的.gitignore文件放在了根目录下,代表着符合上述条件的所有文件都不会被上传。举个例子,*.pyc代表Git会忽略所有后缀为pyc的文件,tegra/代表忽略所有名为tegra的文件夹和该文件夹下的所有内容。如果创建了多个.gitignore文件,还要考虑文件作用范围的问题。一般来说.gitignore对同目录及其子目录下的文件生效。更多介绍可以查看刚刚贴出的官网链接。
.gitattributes也是一个文本文件,具体介绍在这里(https://git-scm.com/docs/gitattributes),官网定义如下:
.gitattributes文件中每一行的格式都是pattern
attr1 attr2 ...,pattern指的是文件模式,attr指的是给文件模式赋予的属性。直接来看OpenCV3.4.10中的文件:
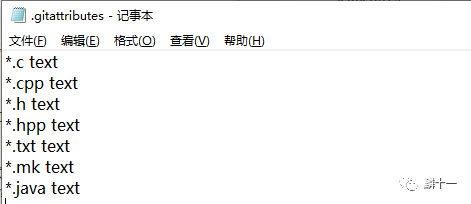
.gitattributes的内容
上图中的*.c,*.cpp,*.h等都是文件模式,*.c指代所有后缀为c的文件,.cpp代表所有后缀为cpp的文件(也就是C++的源文件)等。text是给这些文件赋予的属性:
text只是其中一种属性,我们还可以设置-text,eol等属性。拿上图中的*.c text举例,text属性将所有后缀为.c的文件标记为文本文件,并在用户使用Git命令进行提交、合并等操作时将行尾标志符统一为LF。
在2.2节中我们就提到过行尾标识符,这里再复习一下。不同系统的行尾标志符是不同的,Windows中约定'\r\n'作为一行的结束标志,类Unix系统中是'\n',macOS中是'\r'。也就是说当我们在敲下“Enter”键的时候,系统给我们的代码或文本中添加的符号是不同的,只不过由于这些符号不是可见符号,所以在文本中没有显示出来而已。'\r'代表回车(Carriage
Return, CR),'\n'代表换行(Line
Feed, LF),'\r\n'就是回车换行,即CRLF。
总结来说,.gitattributes可以将不同格式的文件和代码在使用Git提交、合并至GitHub仓库的时候,调整为统一的文件格式。
Continuous Integration is the practice of merging in small code changes frequently - rather than merging in a large change at the end of a development cycle. The goal is to build healthier software by developing and testing in smaller increments. This is where Travis CI comes in.
持续集成简单理解就是代码每一次的小改动都会及时地与主干代码进行集成和测试的过程。持续集成有利于开发者及时发现新代码中的错误,减少将新代码合并至主干代码过程中出现的问题,如果开发人员的新代码没有及时与主干代码进行集成或测试,那么在项目后期合并代码时很容易出现大量代码冲突或系统集成失败等问题,这种问题也被称为“集成地狱”
持续集成的过程其实很简单:配置环境、编译、链接、运行、测试等,我们可以手动完成这些步骤,也可以依靠工具自动完成,Travis CI就是一个可以自动进行持续集成的工具。

Travis CI LOGO
As a continuous integration platform, Travis CI supports your development process by automatically building and testing code changes, providing immediate feedback on the success of the change.
.travis.yml使用YAML语言编写,这里对YAML不做过多介绍了,想了解详情的读者见下文链接:
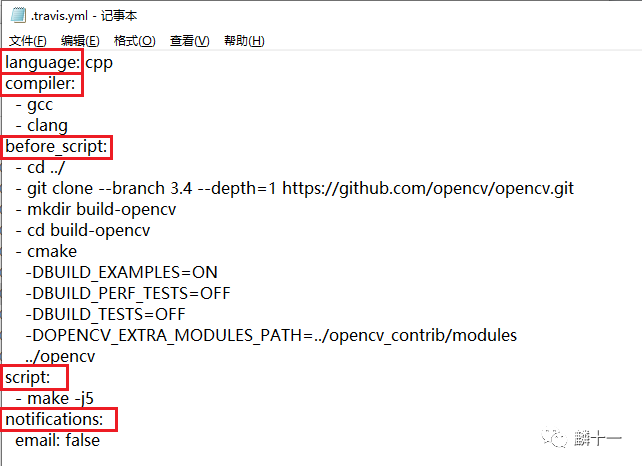
有关Travis CI和.travis.yml的更多内容见官方文档(https://docs.travis-ci.com/)
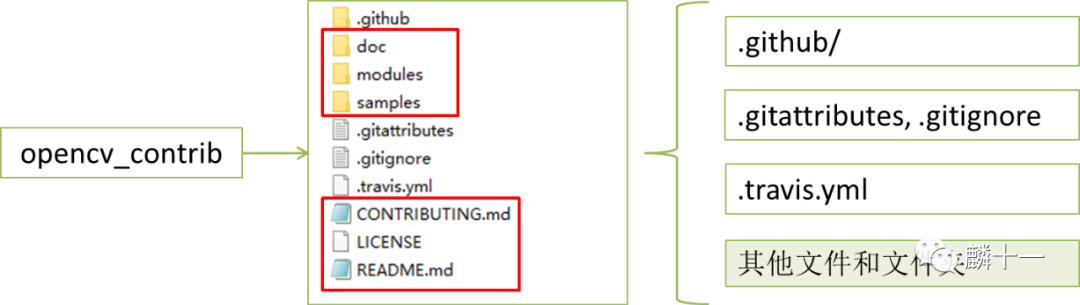
modules文件夹存放了额外算法的源代码,例如face(人脸识别)、bioinspired(生物视觉)、tracking(视觉对象追踪)等等。如果想要使用这些算法模块,需要我们自己对源码进行编译,modules文件夹所在的路径也是编译时需要的参数,有关编译的具体细节在接下来的配置文中会有具体讲解。
doc下存放了某些算法的样例图片和训练好的模型,samples下是一些样例程序和图片文件。
README.md中是项目简介和配置所需的cmake语句,LICENSE是OpenCV的开源许可证->BSD 3-Clause License,CONTRIBUTING.md中是贡献指南的链接。这些文件在前文都有涉及,这里不再解释了。

这篇文依然是改了又改才发出来,从最开始设计介绍顺序的时候我就在纠结,目录画了好几版也不满意;写完初稿又发现自己对于make和cmake的理解有些偏差,所以又重写了第二节中的内容;最后在库文件那里又补上了C++的编译过程,总之是修修补补,现在才差不多满意
这个系列还有2篇,一篇是OpenCV在Ubuntu16.04上的配置攻略,一篇是在Windows10上的配置攻略,两篇文的内容都会包括:
 源代码编译(包括opencv_contrib的编译)
源代码编译(包括opencv_contrib的编译)
OpenCV2.x和3.x的配置过程,没想好要不要写4.x,因为3.x和4.x步骤相同
我曾遇到的bug及处理方式
截图已经做好,只剩下写中间步骤和图片排版,我尽量在9月份完结这个系列
 END
END ~
~
