





 第 26 篇 | LINSHIYI
第 26 篇 | LINSHIYI 
这是Ubuntu下安装OpenCV系列的第四篇:make编译。全文共2个部分,分别对应OpenCV安装步骤的第5步和第6步。
第一部分(第5步)会执行make多线程编译,生成算法的目标文件(.o)。第二部分(第6步)使用make install命令,安装OpenCV算法的头文件、库文件、可执行程序等内容,这一部分还会展示debug版本和release版本库文件的区别。
本文以OpenCV3.4.10+contrib为例,在Ubuntu18.04下使用Debug模式进行源代码编译,所述方法同样适用于Ubuntu16.04系统。
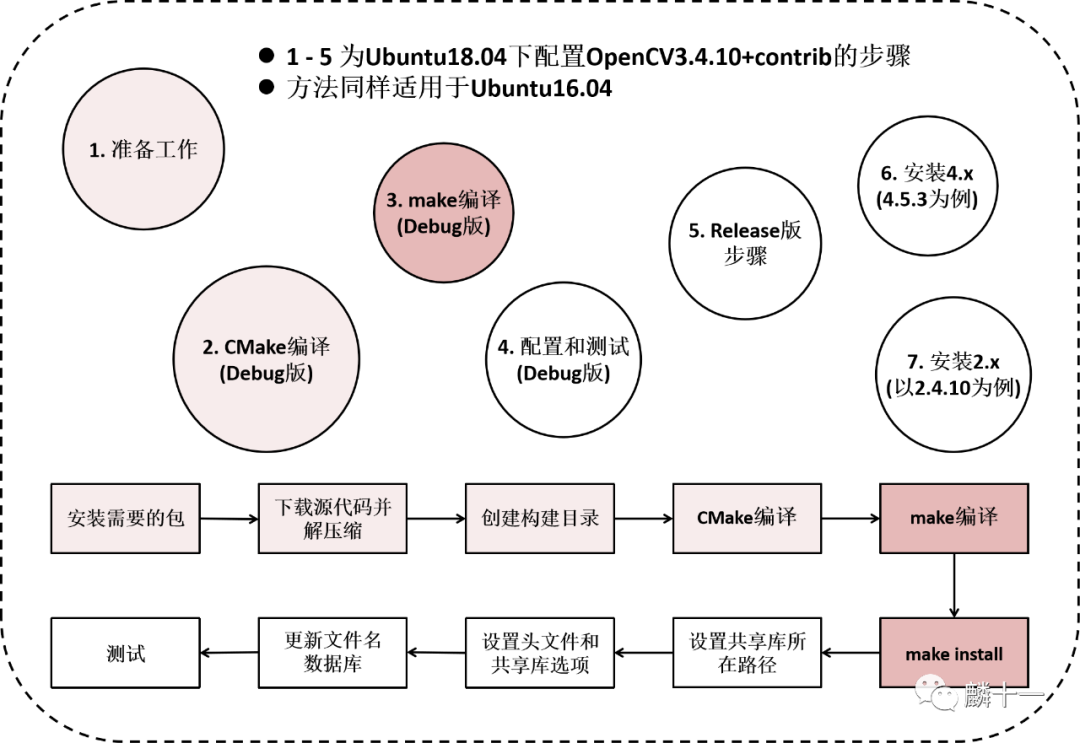
 OpenCV配置攻略(一):OpenCV, VC++和VS OpenCV配置攻略(二): 安装包里都有什么(上) 本文主要介绍make编译这一步,推荐阅读2.4节(3)-(4)中有关CMake和make的部分 OpenCV配置攻略(二): 安装包里都有什么(下) make编译会生成一系列库文件,推荐阅读3.3节(3)-(6)中静态库和动态库的部分 Ubuntu下安装OpenCV(一): 准备工作 Ubuntu下安装OpenCV(二): CMake编译(上)
OpenCV配置攻略(一):OpenCV, VC++和VS OpenCV配置攻略(二): 安装包里都有什么(上) 本文主要介绍make编译这一步,推荐阅读2.4节(3)-(4)中有关CMake和make的部分 OpenCV配置攻略(二): 安装包里都有什么(下) make编译会生成一系列库文件,推荐阅读3.3节(3)-(6)中静态库和动态库的部分 Ubuntu下安装OpenCV(一): 准备工作 Ubuntu下安装OpenCV(二): CMake编译(上) Ubuntu下安装OpenCV(三): CMake编译(下)

第五步: make编译, 生成算法模块的目标文件(.o)和其他文件
命令执行位置: 构建目录下, 与CMake编译生成的Makefile处于同一目录下
命令行:
$ sudo make
或
$ sudo make -j* (*指代计算机的线程数)
注意:
1. 可选择多线程或单线程进行编译
完成了CMake编译,相当于生成了适用于不同系统的Makefile或工程文件。我们目前使用的是Ubuntu系统,所以CMake编译之后生成了Makefile文件,接下来就需要使用GNU make工具,通过读取Makefile中的内容实现整个项目的自动化编译。
这一步的命令行很简单,在构建目录下输入sudo make或者sudo make -j*即可执行编译任务(https://www.gnu.org/software/make/manual/make.html#Parallel)
这里的*指的是线程数,程序执行多线程编译时速度会比单线程编译更快。
5.1 查看线程数
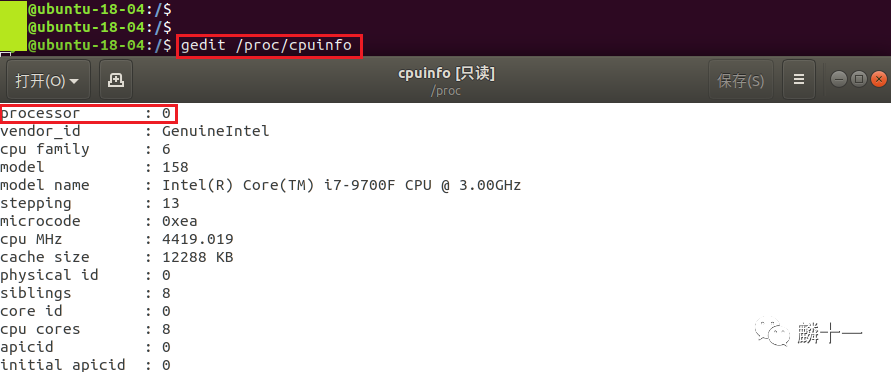
如果不知道自己计算机的线程数,可以在计算机任意位置输入cat /proc/cpuinfo | grep "processor" | wc -l 命令来查看:

简单解读一下上文的命令。cat命令负责输出文件内容;之后的/proc/cpuinfo是一个文件,它记录了例如CPU个数、CPU厂商这类有关计算机CPU的信息,我们可以在计算机中直接打开这个文件查看里面的内容:
接下来的符号"|"代表管道,它会将上一条命令的输出作为下一条命令的输入;grep命令可以查找文件中符合条件的字符串,我们在这里查找的是"processor",这个变量指代计算机的逻辑CPU,从0开始标号;wc命令会输出文件的行数、字数和字节数,选项-l代表只显示行数。
所以,这条语句是由3条子语句和管道"|"连接而成:cat /proc/cpuinfo会输出cpuinfo文件的全部内容:
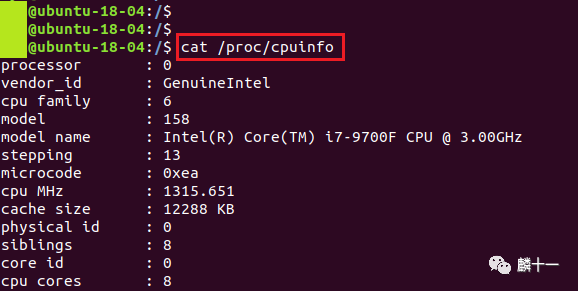
输出/proc/cpuinfo的内容
grep "processor"会从这些内容中提取出所有包含"processor"的语句,从标号可以看出,每一条语句都代表一个逻辑CPU;wc -l会输出这些语句的行数,也就是逻辑CPU的个数。
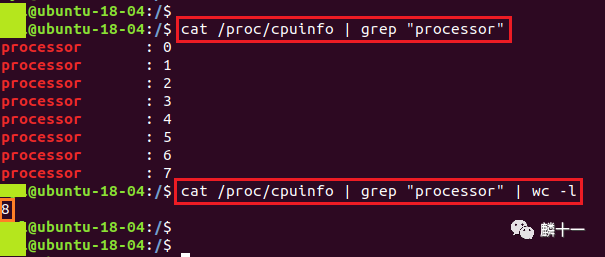
查看线程数的两条语句
从上图的命令行结果可以看出,我们从文件/proc/cpuinfo中提取出了8条包含"processor"的语句,也就是说我的系统中可用的线程数为8。
更详细的内容比如CPU个数、核数、超线程等内容就不再展开了,我们在这里只需要关注如何获取计算机上的线程数即可。
5.2 make编译
知道了线程数,就可以执行make编译了,我在构建目录debug下使用命令sudo make -j8进行编译。如果电脑性能不佳,也可以直接输入sudo make进行单线程编译。
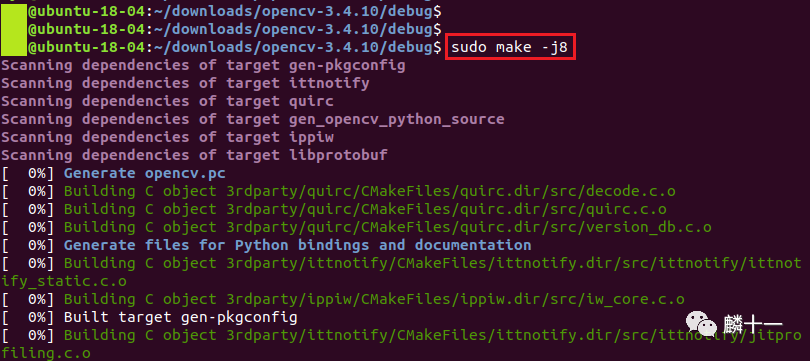
make首次编译的时间会比较长,通过输出的内容可以发现,这一步主要是生成算法的目标文件(.o),为下一步生成库文件做准备。有关目标文件的介绍在 OpenCV配置攻略(二): 安装包里都有什么(下) 3.3节中的第(3)部分。

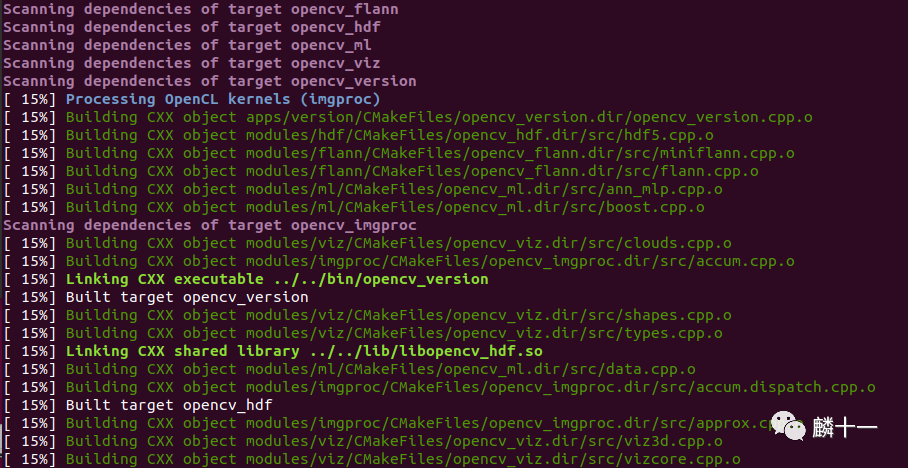
make编译过程
make编译一般也是不会报错的。编译完成后,OpenCV算法的目标文件(.o)就都已经生成了。
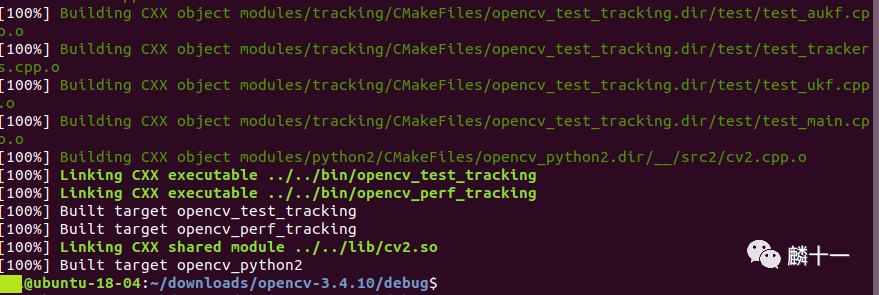
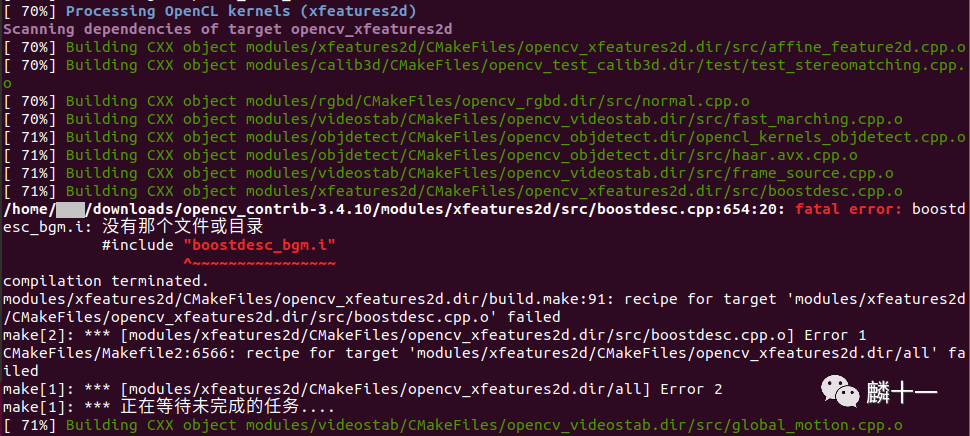

第六步: 将make编译生成的目标文件打包,并安装算法的库文件、头文件、可执行程序等文件
命令执行位置: 构建目录下, 与CMake编译生成的Makefile处于同一目录下
命令行:
$ sudo make install
注意:
1. 库文件、头文件的安装位置是在CMake编译时,通过变量CMAKE_INSTALL_PREFIX进行设置的
2. 区分Debug和Release编译模式下生成的共享库之间的区别
第六步也属于make编译,只不过它在make命令之后添加了一个选项 install,install选项会将执行程序所需的文件复制在目标目录下(https://www.gnu.org/software/make/manual/make.html#Goals)
所以这一步的目的是将算法生成的库文件、头文件等内容安装到指定目录下。这里的指定目录是我们在第4步CMake编译时通过变量CMAKE_INSTALL_PREFIX设置的参数。
我之前设置的路径为/usr/local/opencv-3-4-10-debug,用户可以根据自己的喜好设置路径和文件名,不设置的话默认安装在/usr/local下。
6.1 make install
直接在构建目录下输入命令sudo make install即可完成这一步:
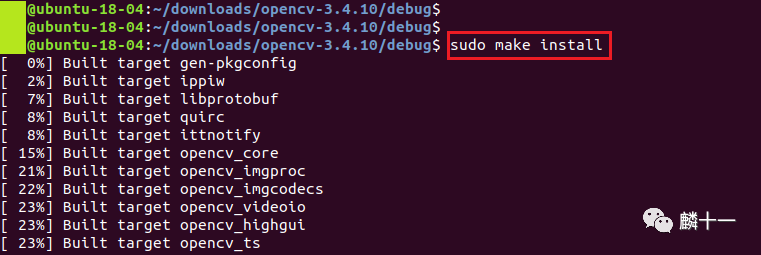
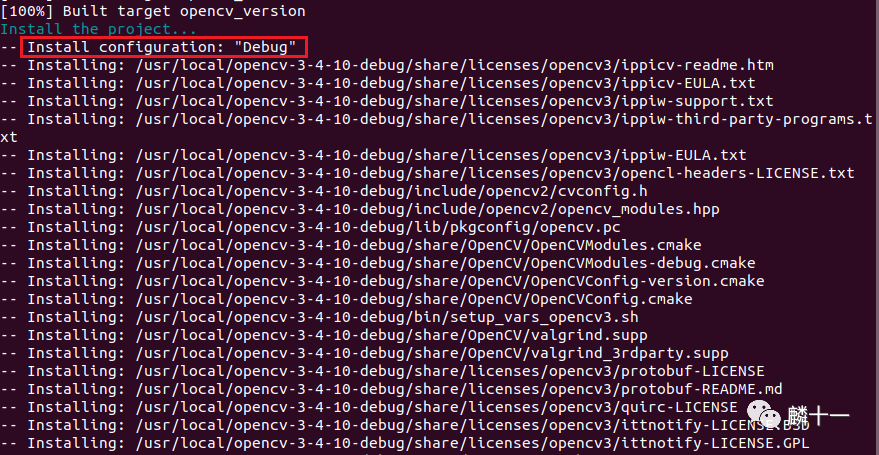
6.2 安装结果
编译完成后我们就可以前往之前设置的路径下查看生成的文件了,使用cd命令进入/usr/local/opencv-3-4-10-debug目录下:
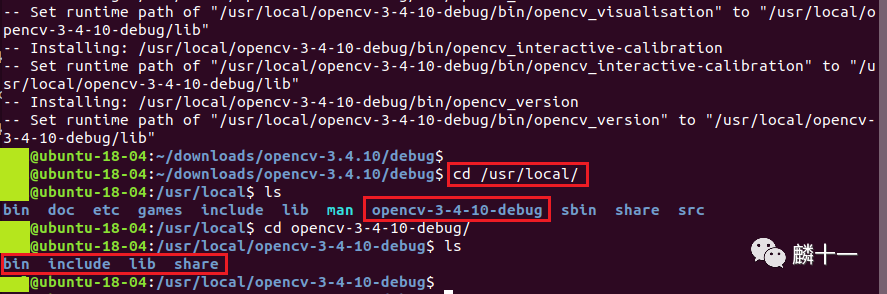
make install这一步一共会生成4个文件夹,分别为bin、lib、include和share。
bin文件夹下存放的都是OpenCV生成的可执行文件,包括级联分类器(opencv_annotation, opencv_traincascade等)、opencv版本(opencv_version)等。
我在这里使用命令./opencv_version运行了一下记录OpenCV版本的可执行文件,输出结果为3.4.10。
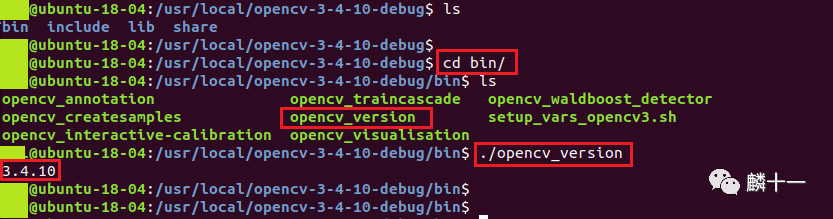
有关级联分类器的用法见https://docs.opencv.org/master/dc/d88/tutorial_traincascade.html
第二个include文件夹下存放的是各个算法的头文件:
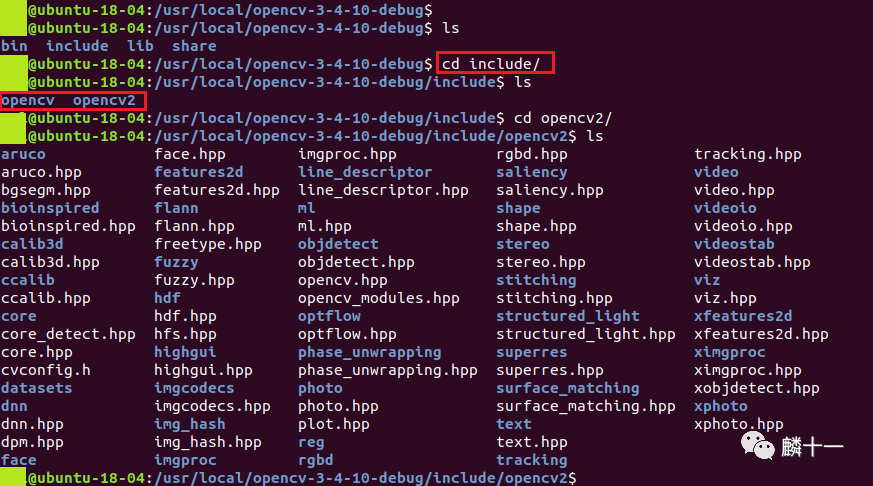
include文件夹
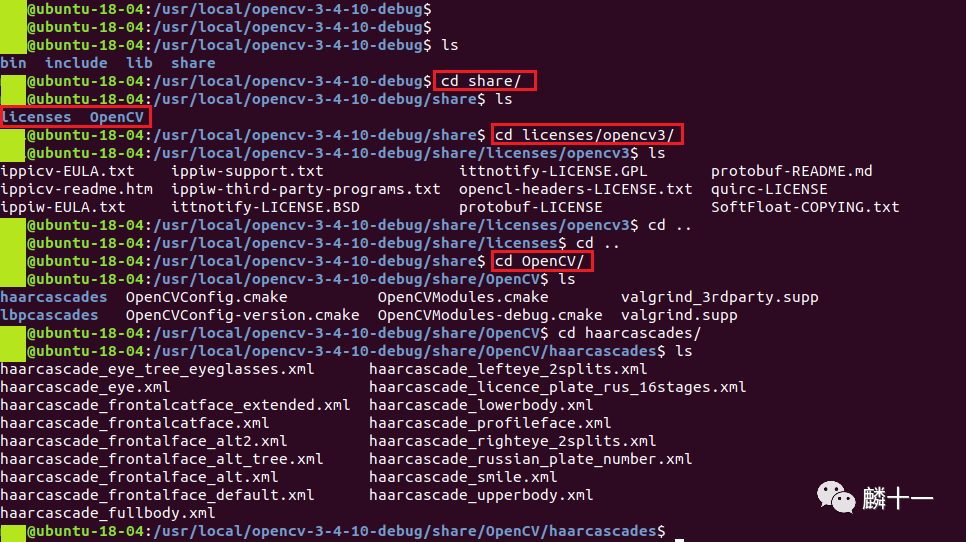
share文件夹下有两个文件夹,licenses中存放的是证书、版权声明、使用指南等文本文件,OpenCV下存放的大多是级联分类器数据,格式为XML。
lib下存放的是库文件,在Linux/Unix下,格式为lib*.so.*的文件既是动态库也是导入库。
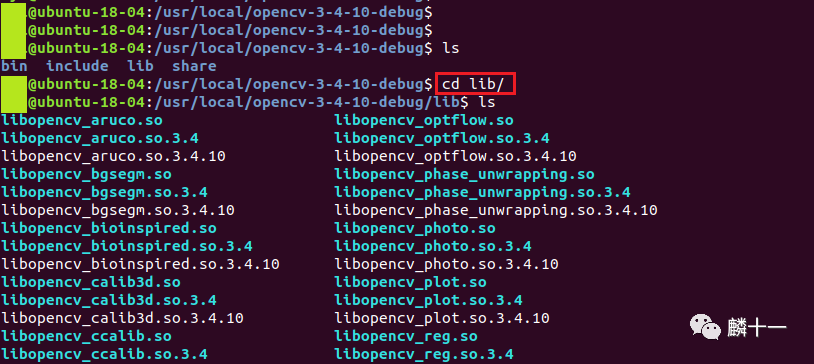
我们在这一步生成的全都是动态链接库,如果想生成静态链接库,可以参考
https://docs.opencv.org/master/db/d05/tutorial_config_reference.html
6.3 debug和release版本库的区别
到目前为止,我们一直在使用Debug模式编译OpenCV源代码,make install这一步生成的也都是debug版本的库文件。如果使用Release模式编译代码,那么会生成release版本的库文件。
不过,Ubuntu下生成的Debug、Release或其他版本的库文件名称相同,单从文件名上很难区分出哪一个是debug版本的库,哪一个是release版本的库。
这一小节会通过命令readelf -S <file name>来展示不同版本的库的区别。readelf命令用于查看ELF格式的文件信息,常见的ELF文件就是Linux下的动态库(*.so)和静态库(*.a)。参数-S可以显示指定名称文件的节头(Section Headers)信息。
在命令行中输入readelf -H可以查看readelf命令可用的所有选项:
在之前的编译中,我将Debug模式编译生成的文件存放在了/usr/local/opencv-3-4-10-debug下,同理,我将Release模式编译生成的文件存放在了/usr/local/opencv-3-4-10-release下。Release模式的具体编译步骤在下下篇会详细展示。
先进入opencv-3-4-10-debug文件夹下,随便查看一个debug版本的动态库,我在这里选择的是libopencv_aruco.so:
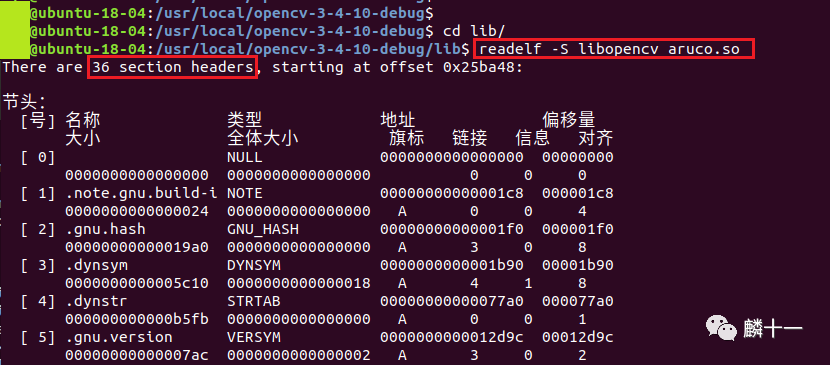
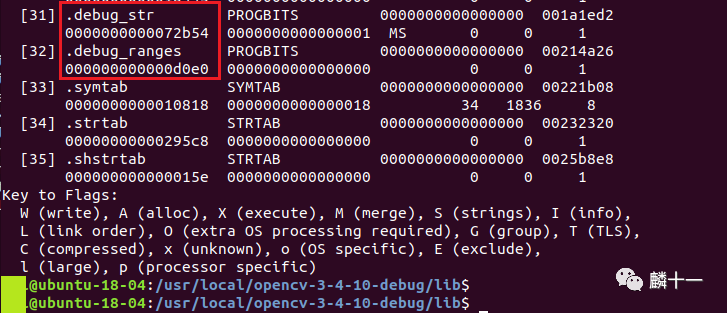
从输出结果可以发现,libopencv_aruco.so共有36个节头,且一些节头带有debug标记(如[31]和[32])
接下来进入Release模式生成的opencv-3-4-10-release文件夹下,查看同名文件的节头信息:
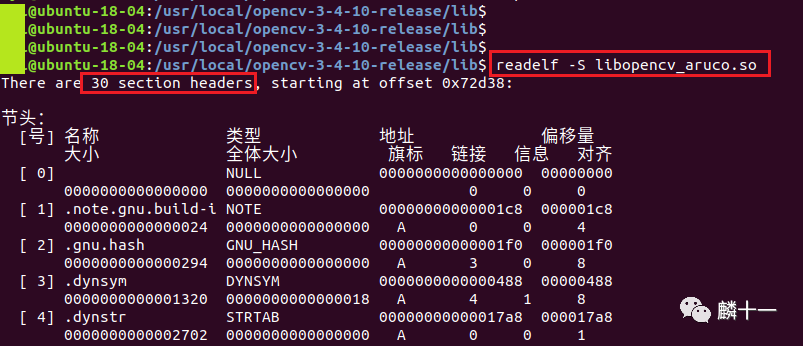
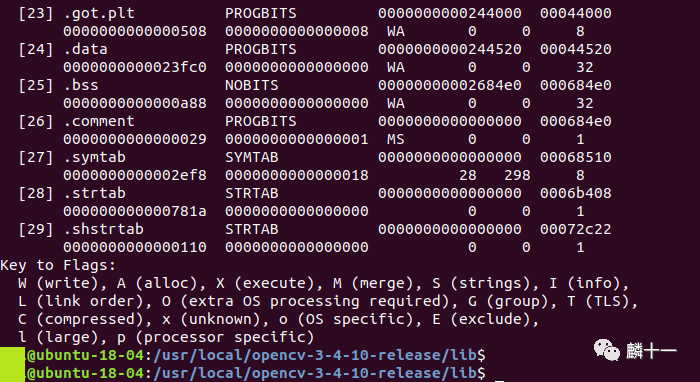
可以发现,release模式的libopencv_aruco.so文件只有30个节头,且所有节头都没有debug标志。
所以说,不同编译版本的库文件从外表上看没有区别,但实际上各个文件都是不同的,我们在生成、使用这些库的时候要留意,混用这些库很可能造成编译失败或者程序运行失败的问题。
最后贴一张有趣的图,在最开始查看readelf命令的帮助文档时,我习惯性地输入选项-h,然后发现它居然“无事可做”了
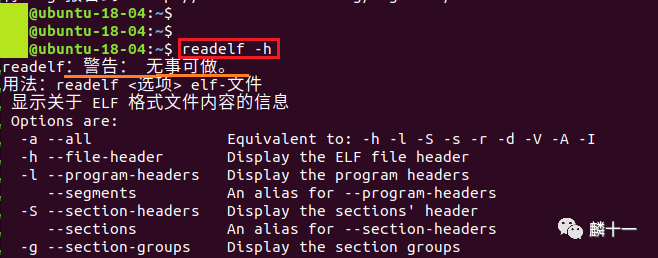
这件事告诉我们:readelf命令除去选项-v和-H之外,其他选项后必须要有一个指定名称的ELF文件才可以成功运行。

 其实就只有2行命令,非常简单。到这里为止,OpenCV的编译的部分就全部结束了,接下来的步骤都是配置操作。
其实就只有2行命令,非常简单。到这里为止,OpenCV的编译的部分就全部结束了,接下来的步骤都是配置操作。 包括4个部分:共享库的路径设置(ldconfig命令)、头文件和共享库的选项设置(pkg-config命令)、文件名数据库的更新(updatedb命令)以及使用OpenCV自带的样例程序进行测试。
包括4个部分:共享库的路径设置(ldconfig命令)、头文件和共享库的选项设置(pkg-config命令)、文件名数据库的更新(updatedb命令)以及使用OpenCV自带的样例程序进行测试。 先这样吧。最近发文速度有点快,还有些不适应,总觉得文章还能再改改
先这样吧。最近发文速度有点快,还有些不适应,总觉得文章还能再改改
 END
END ~
~
