




本文是 分析 OceanBase 的一种假想的网络异常场景,观察 OceanBase 数据库的表现,加深对 OceanBase V3 的主机高可用和分区多副本选举机制有更深刻的理解。文中观点是个人观点,可能有误,欢迎交流。场景是假想的,请勿错误的使用。
OceanBase V3 在生产环境部署通常是三副本,最佳环境是同城三机房部署。也有的为了加强抗风险能力用了五副本。这里为了说明问题就用三副本。
下面是一个三机房部署的三副本 OceanBase 集群,它能应对的最大风险就是一个机房级别的故障。这个原理已经不需要赘述了。
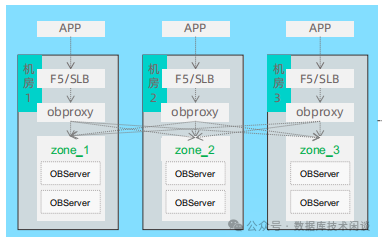
当我们说一个机房故障的时候(比如说机房2),实际发生的事件是机房 2 跟机房 1 之间网络断开了,机房 2 跟机房 3 之间网络断开了。假想的故障场景是只有机房 1 跟 机房 2 之间网络断开,但是机房 2 跟机房 3 之间网络故障没有断开,这个时候 OB 会怎么样?
当然这个假想场景实际上不大可能发生,机房之间的光纤链路都至少有 2 条不同物理线路做高可用,且机房 1 和 2 中断时,机房 1 通过 3 再到 2 也是可以的。所以这里是假设发生了(可以模拟),然后 OB 的答案不是确定的,它取决于多项因素。如果要做实验,我们就需要构造一些前提条件。
实验模拟环境说明
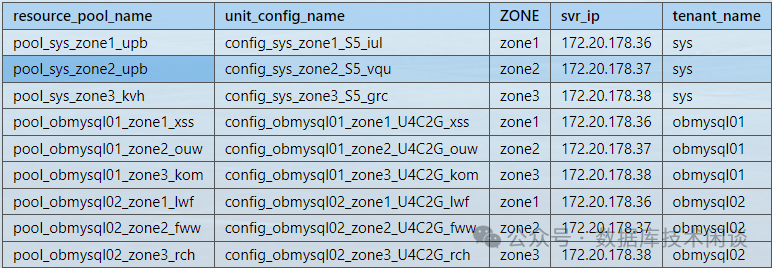
我们构造一个集群环境,集群有三个机房(Zone1,Zone2,Zone3)。租户:SYS 租户、obmysql01、obmysql02 。三个租户的 PRIMARY_ZONE 分别是机房 1(Zone1)、机房 1(Zone1)、机房 2(Zone2)。所以集群的 ROOT_SERVER(后简称 RS)在 Zone1 。
select zone,concat(svr_ip,':',svr_port) ,status, usec_to_time(b.last_offline_time) last_offline_time, usec_to_time(b.start_service_time) start_service_time, b.with_rootserverfrom __all_server border by zone, svr_ip;复制

select t1.name resource_pool_name, t2.`name` unit_config_name, t3.ZONE, t3.svr_ip, t4.tenant_namefrom __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)order by t4.tenant_id, t3.zone;复制
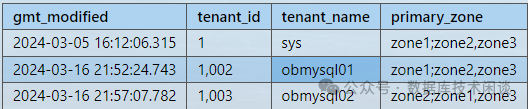
SELECT gmt_modified, tenant_id,tenant_name,primary_zone FROM __all_tenant;复制
实验模拟网络单边故障的方法是通过防火墙 IPTABLES 阻断对应节点对本节点 2881 和 2882 端口的访问( 2 个端口各有分工,这里一并阻断)。网络的互通是双向的,防火墙连接的配置是每个方向都要配置。所以实验里阻断的时候先单向阻断然后做双向阻断。此外,实验时只针对 INPUT 规则进行配置,不针对 OUTPUT规则配置,所以留意阻断命令运行所在的节点。
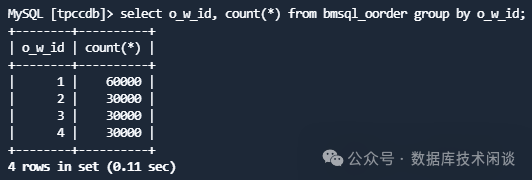
实验还模拟了业务场景。这里两个租户 obmysql01 和 obmysql02 的数据库结构是一样的,只是数据不一样。这里我在 OceanBase的 MySQL 租户基础上使用了分库分表技术,使用的是 ODP(OBSharding)产品构造了一个逻辑实例和逻辑库(tpccdb)以及一组逻辑表。下面是其中一个逻辑表 bmsql_oorder 在各个物理分库下的位置。
SELECT t5.tenant_name, t5.primary_zone tnt_primary_zone, t4.database_name, t1.table_id,t1.table_name, t2.partition_id, t2.role, t2.zone, concat(t2.svr_ip, ':', t2.svr_port) observerFROMgv$table t1JOIN gv$partition t2 ON (t1.tenant_id = t2.tenant_id AND t1.table_id = t2.table_id)LEFT JOIN __all_virtual_tablegroup t3 ON (t1.tenant_id = t3.tenant_id AND t1.tablegroup_id = t3.tablegroup_id)JOIN gv$database t4 ON (t1.tenant_Id = t4.tenant_id AND t1.database_id = t4.database_id)JOIN gv$tenant t5 ON (t1.tenant_id = t5.tenant_id)WHERE 1=1-- t5.tenant_id IN (1001)AND t2.role = 1 AND t4.database_name like 'TPCC%' AND t1.table_name like 'bmsql_oorder%'ORDER BYt5.tenant_name, t4.database_name, t3.tablegroup_name, t1.table_name, t2.partition_id ;复制

其中有两个分库在租户 obmysql02 且主副本在 Zone2 (37 节点上)。逻辑表的查询会根据情况读取一个或多个分库的分表。
使用 ODP(OBSharding)并不是这个实验的必须条件,只是方便说明问题。你也可以通过分区表技术实现,那就是一个租户下,分区表不同分区主副本分散在 zone1 和 zone2 。后面会重点关注故障时对这个业务查询的影响。
iptables -A INPUT -s 172.20.178.37 -p tcp --dport 2881 -j DROPiptables -A INPUT -s 172.20.178.37 -p tcp --dport 2882 -j DROPdate复制
然后观察集群 RS 事件。注意通过 36 上的 OBProxy 连接集群的 SYS 租户,这个连接不受上面阻断影响。
SELECT gmt_create ,module,event,name1,value1,name2,value2,name3,value3,name4,value4FROM oceanbase.`__all_rootservice_event_history`WHERE 1=1-- AND module IN ('server','root_service')AND gmt_create >='2024-03-21 10:27:30'ORDER BY gmt_create DESC LIMIT 10;复制

从结果看大概10s 不到 RS 就检测到节点 37 掉线了,并修改了集群参数 rootservice_list 值(踢掉了 37 节点)。
这里 RS 是可以访问 37 节点,但是 37 节点不能访问 RS 节点。RS 判断 37 掉线,说明节点掉线( lease_time )和上线(server_online ) 是由节点向 RS 节点主动上报的,不是 RS 节点主动去探测的。这个上报间隔由集群参数 决定。
继续观察这个视图看了很久,没有看到有分区切主事件发生。
接着先来看看业务查询是否受影响。
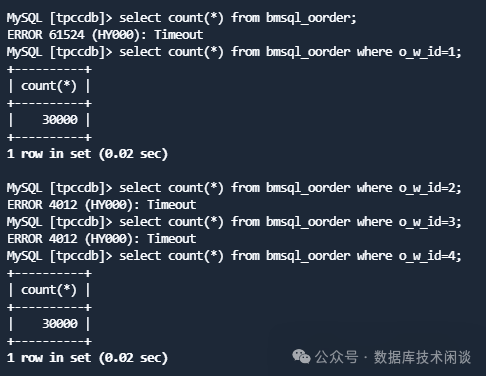
果然针对逻辑表的全表统计出现超时错误(-4012)。但是如果按分库分表字段挨个去查询的时候,能看出一半结果正常,一半结果异常。那个异常的结果就发生在租户 obmysql02 上,并且原因跟刚才网络阻断有关。
等了很久,这个查询也不会恢复,所以这里不会有常说的高可用能力体现。
如果运维做一些查询,比如说直接通过 36 上的OBProxy 登录这个租户 obmysql02 ,可以连接,但是如果获取数据库列表信息(元数据一种),也会出现超时报错。
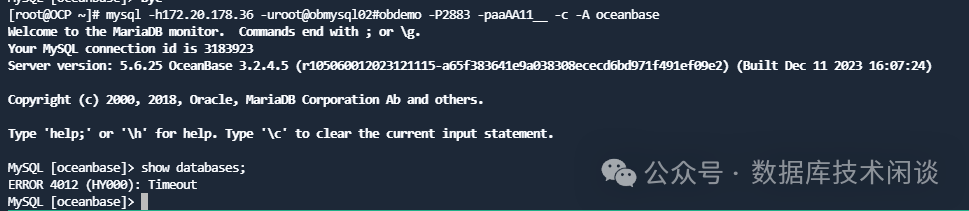
如果通过 37 上的 OBProxy 登录这个租户 obmysql02 会发现连登录都报错。

即使通过 37 直连本地 OB 进程的 2881 端口,能登录,但是获取数据库列表也会报错。
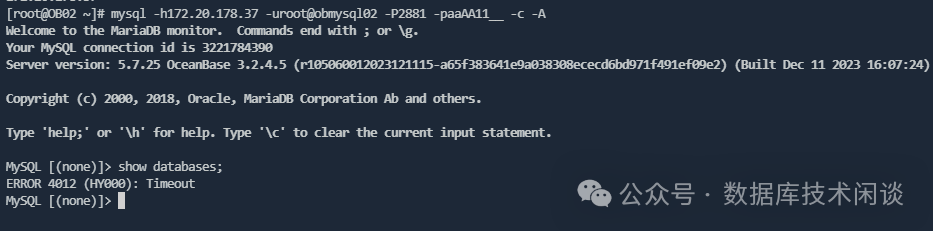
所以,基本可以确定的运维的一些获取元数据库信息的 SQL 有些都会报错。是否报错就取决于那个视图的原理。比如说 SYS 租户的视图 __all_server 就不报错。

此时查看分区主副本位置也是会报错的。从查询 bmsql_oorder 对应数据报错结果看,推测分区是没有发生切换。
既然 OB 没有对分区进行切主,那就尝试一下手动切主。直接将租户 obmysql02 的 PRIMARY_ZONE 切换到 Zone1 或 Zone3 。
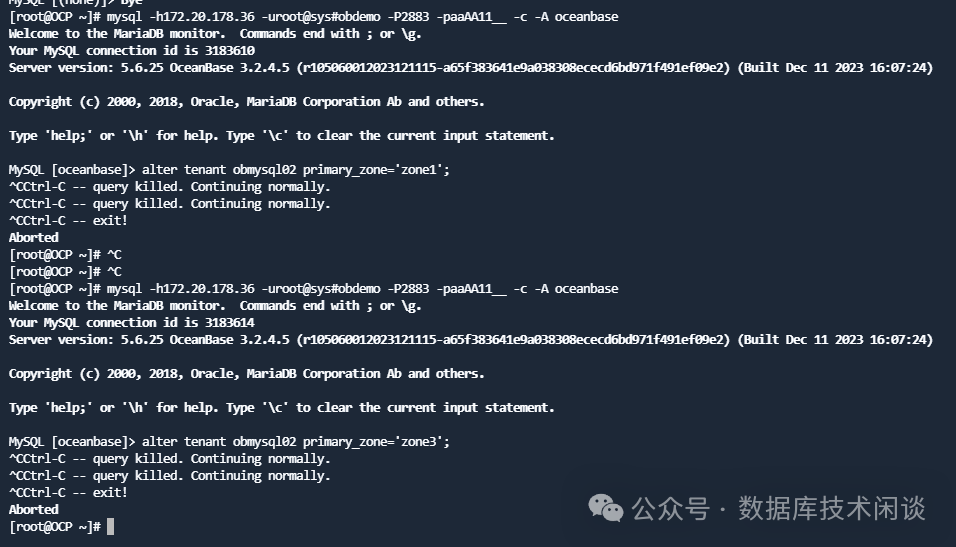
结果手动发起租户 obmysql02 切主也报错。
再尝试将 Zone2 的节点 STOP 掉跨库。
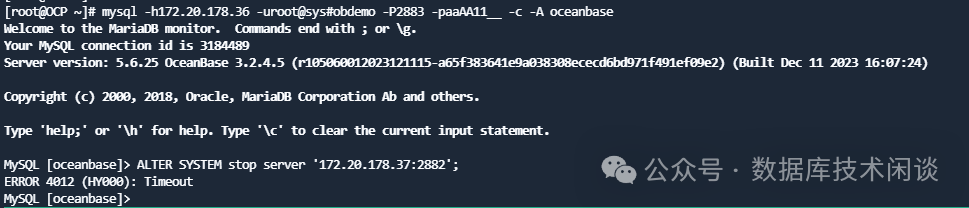

结果也以失败告终。看来想让 OB 切主是不可能的了。
这里分析一下为什么租户 obmysql02 业务表的分区不会自动切主。其原因可能是节点 37 只是跟 36 不通,跟 38 还是通的。这个理由勉强能说的过去,可能还有别的原因就不得而知了。
iptables -A INPUT -s 172.20.178.36 -p tcp --dport 2881 -j DROPiptables -A INPUT -s 172.20.178.36 -p tcp --dport 2882 -j DROPdate复制
实际发现这一步并没有改变什么现状。因为节点 37 掉线是靠 37 主动汇报,不是 RS 节点去主动探测,所以这一步实验是多此一举。不过 RS 事件表里是多了一笔异常记录。
iptables -A INPUT -s 172.20.178.38 -p tcp --dport 2881 -j DROPiptables -A INPUT -s 172.20.178.38 -p tcp --dport 2882 -j DROPdate复制

同时再次运行业务查询发现也恢复了。
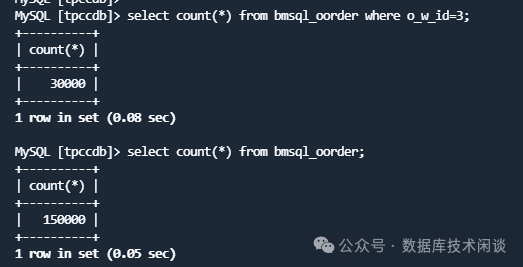
所以此时 OB 集群的高可用机制发生作用了。
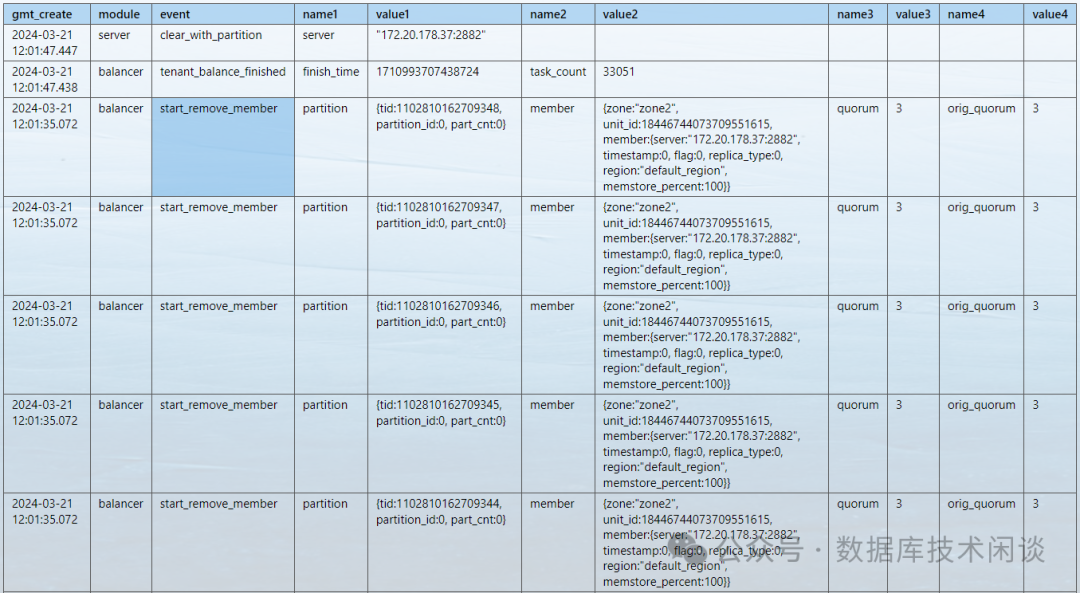
观察此时的 RS 事件日志可以看到 1 个小时后节点 37 的数据都被清空了。不过也有一点可疑的是只看到 start_remove_member 事件,没看到 finish_remove_member 事件。
iptables -F复制
集群开始全部恢复。从 RS 事件看在自动补齐 37 上的数据副本了。
实验场景二
上面实验是从阻断 37 节点访问 RS 节点(36)的访问开始。如果实验从先阻断 RS 节点对 37 的访问开始,这个现象会有一小点变化,就体现在节点 37 在 __all_server 视图中的状态。其他现象还是一样。有兴趣的可以自己研究看看。
总结
所以根据这个实验可以看出 OceanBase V3 的几个高可用特点:
节点在 __all_server 中的状态是由节点自己汇报给 RS 节点的。这个方向的网络访问链路如果断了,节点就掉线了。
分区多副本选举结果发生变化是由每个分区三副本彼此的连通性决定(当然,还有 PRIMARY_ZONE 策略,这里假设策略没有变化)。如果只是某个方向上的网络故障导致分区主副本还能获得多数派的投票,这个主副本它可能不会切换。但是也可能无法提供读写服务。
以上实验现象是确定的,原理都是推测,可能只猜对了部分。严格的说要看 OBServer 日志或者 OBServer 代码,这里没有深入研究。
从经验上来说,如果这种假想的故障场景如果发生了,业务可能出现部分数据访问故障,部分数据访问正常。快速的解决方法就是让故障中某个节点(如这里的节点 37 )彻底“宕机”或者让机房 2 跟 机房 3 的网络也中断掉。直接 KILL 进程或重启主机,这样,OceanBase 的高可用机制还是会自动发生作用的。ORACLE RAC 集群的高可用维护经验里也有一条不怕节点死,就怕节点半死不活。一旦发生直接杀死节点,恢复的还快一些。二者有相同之处。
其他参考




