




1. 问题背景
一线反馈某电力客户业务接口超时,缴费受影响。
故障时一线同事进行了初步的分析,反馈有个gc延迟偶发性增高问题,3节点收到swap告警,cpu使用率在30%+,无明显异常sql,心跳延迟监测也没发现问题。
2. 问题分析
(1)AWR分析
通过一线反馈的信息,还无法判断问题大概的方向,首先还是得先从整体上看看,要了一份rac awr
这是一个6节点的RAC,11.2.0.4版本,主机CPUs为96,从AAS来看,1-4节点的负载不算低

继续往下看等待事件(太长省略部分节点),3节点有个gc cr block lost等待平均时间较长,且其它节点都没有,这个是异常的点需要关注。
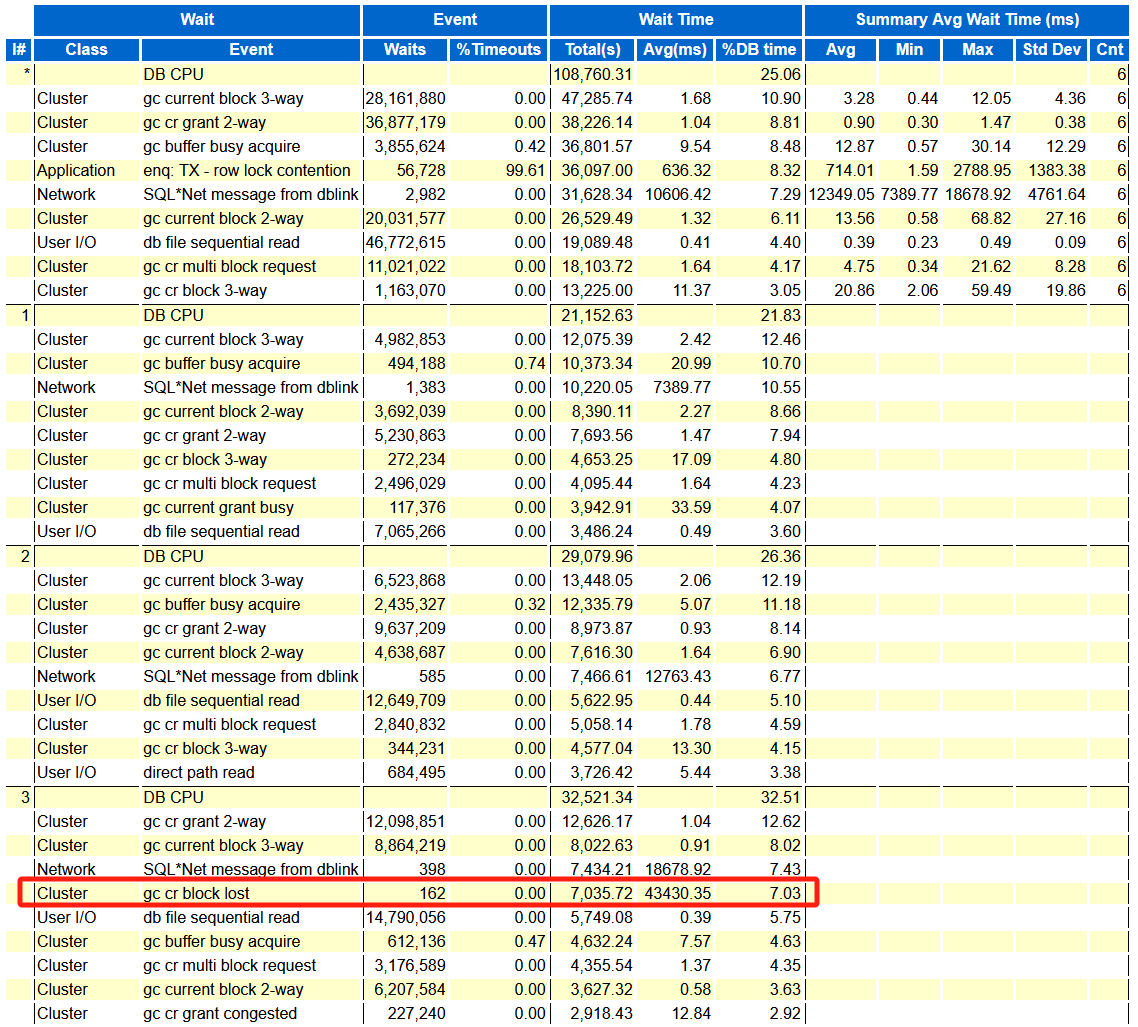
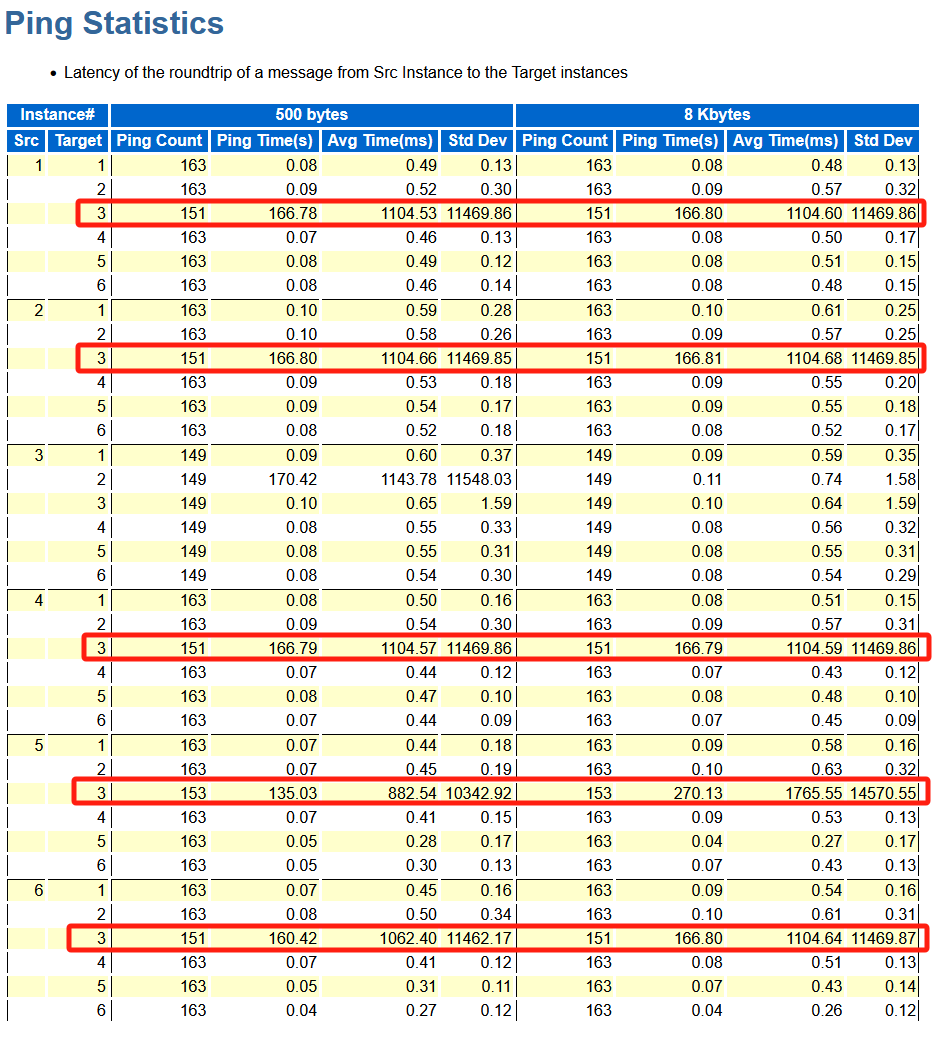
再往下看到Ping Statistics部分的时候,发现其它所有节点都到3节点的ping延时都异常的高,再结合上面3节点的有gc cr block lost等待,那么很可能问题出现在3节点上,且可能跟网络或者主机有关。
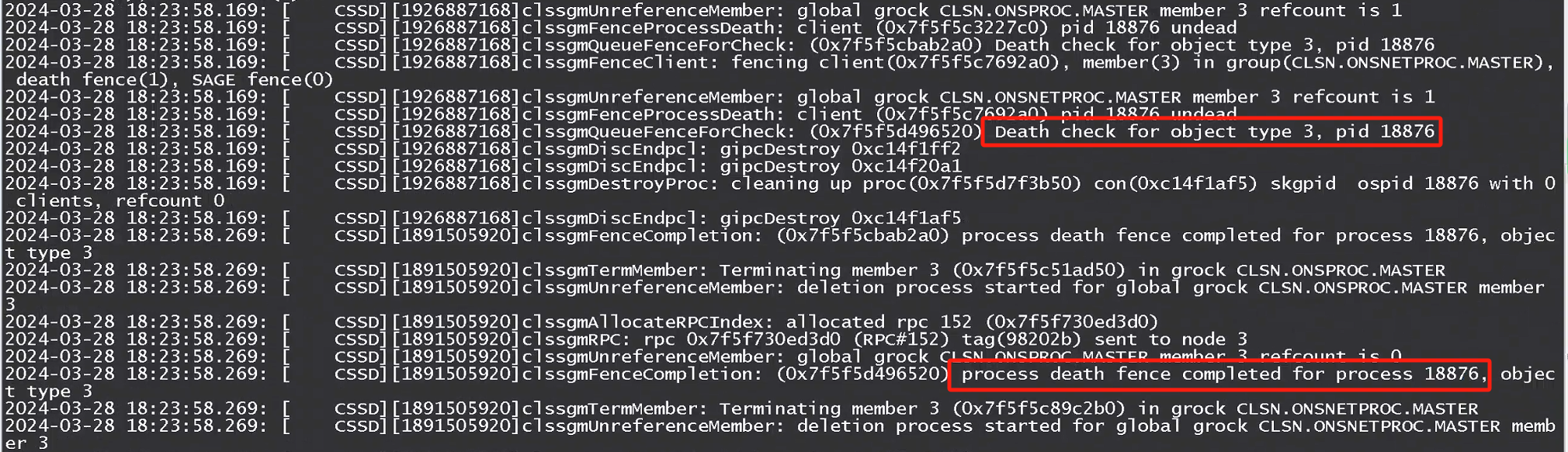
(2)集群日志分析
查看3节点的GI alert log,没有发生私网中断的日志,但是有部分agent重启,从cssd log里可以看到pid 18876僵死
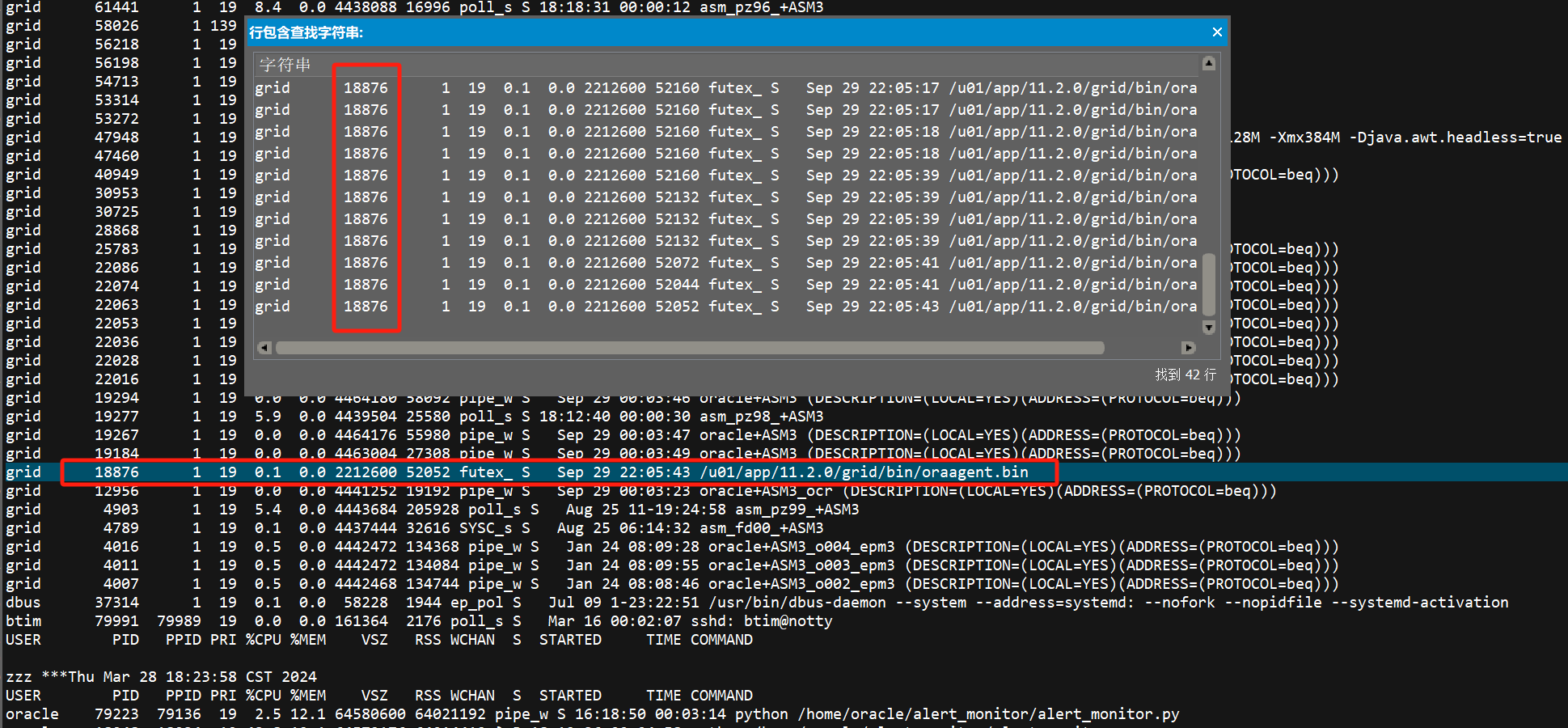
(3)OSWatcher日志分析
从oswps日志里搜索18876为oraagent进程,且从18:23:58开始18876就不存在了,原因是进程重启后pid发生了变化
另外通过OSWatcher数据看,采样间隔是30s,但能发现在18:21:04到18:23:58有个明显的断点
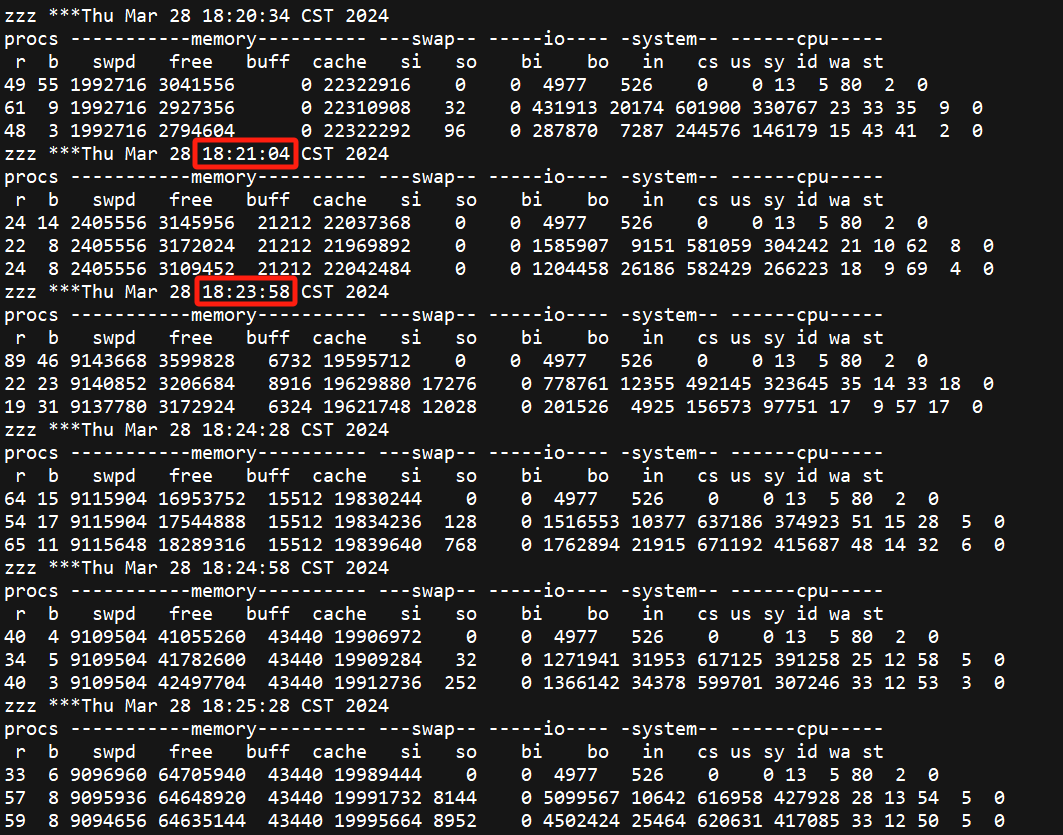
通过生成的图片看更明显,两次的采样间隔超过了150s。OSWatcher是采集OS性能数据的轻量级工具,如果发生采集中断,表示主机当时很可能HANG住了,原因可能是CPU、内存资源不足等等。
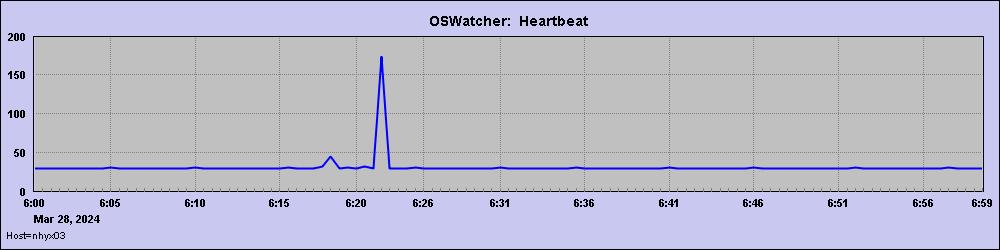
继续看OSW,CPU较正常
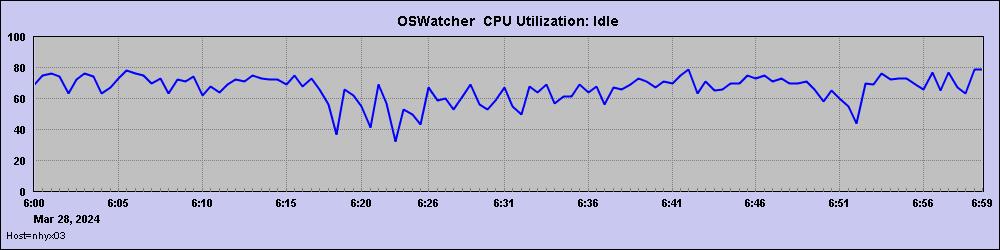
但是内存指标比较怪异,除了故障前Free一直很低外,剩余内存有2次明显的上升,每次上升了60G左右。
这也是个非常异常的点,通常这么大的内存释放,一般都是实例关闭/重启导致,但是经过查询实例并没有发生重启或者关闭。
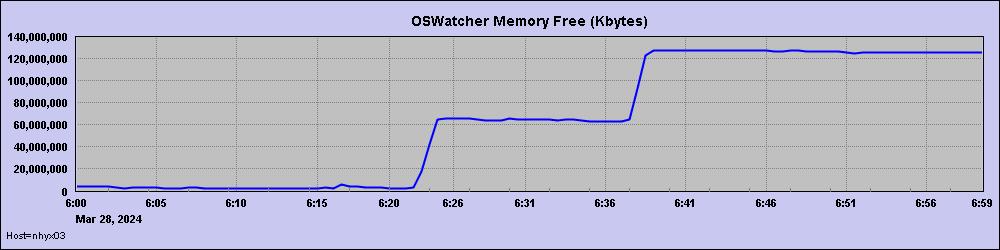
另外还能看到故障时间附件,主机内存有大量的page in和page out,说明当时已出现系统内存不足。
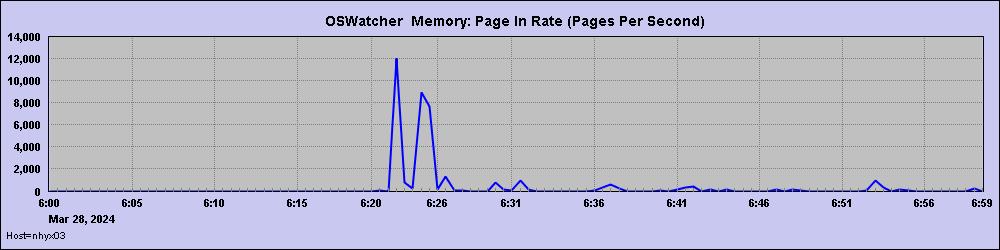
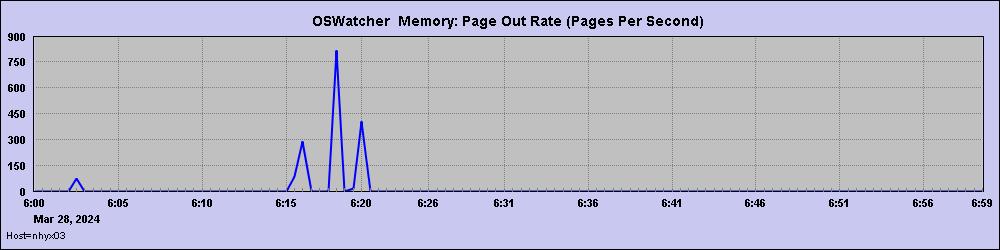
从oswps中找故障时间点占用内存较高的进程,发现是两个python脚本,分别占用了10%和12%的内存,主机的总内存为512G,正好都是60G左右,前面2次60G内存的释放,很可能它们前后退出。
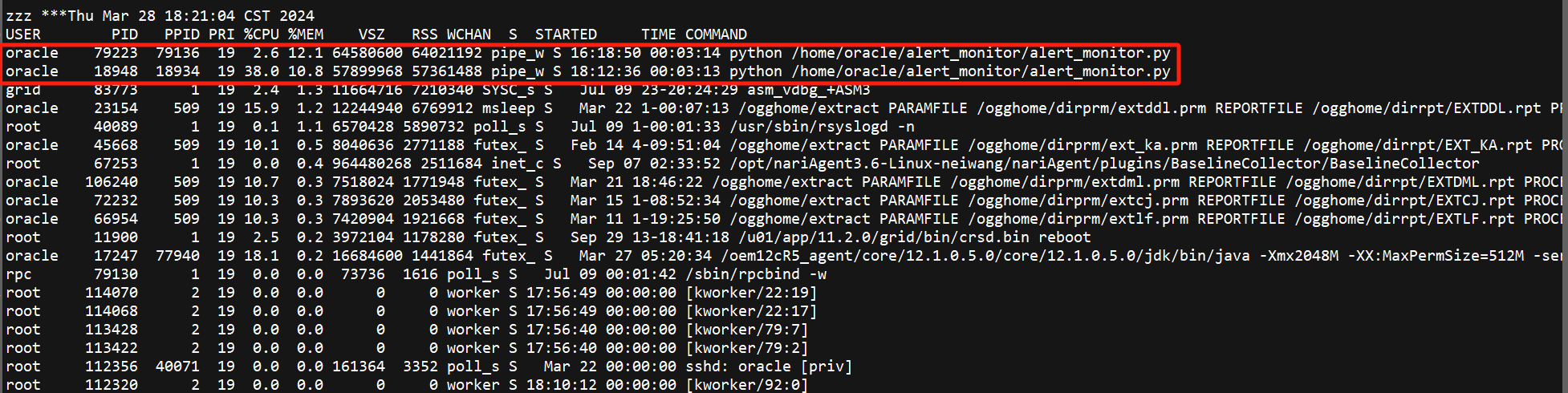
继续查看oswps日志,在18:24:58时最后出现两个python进程79223和18948,随后18948消失只剩下79223
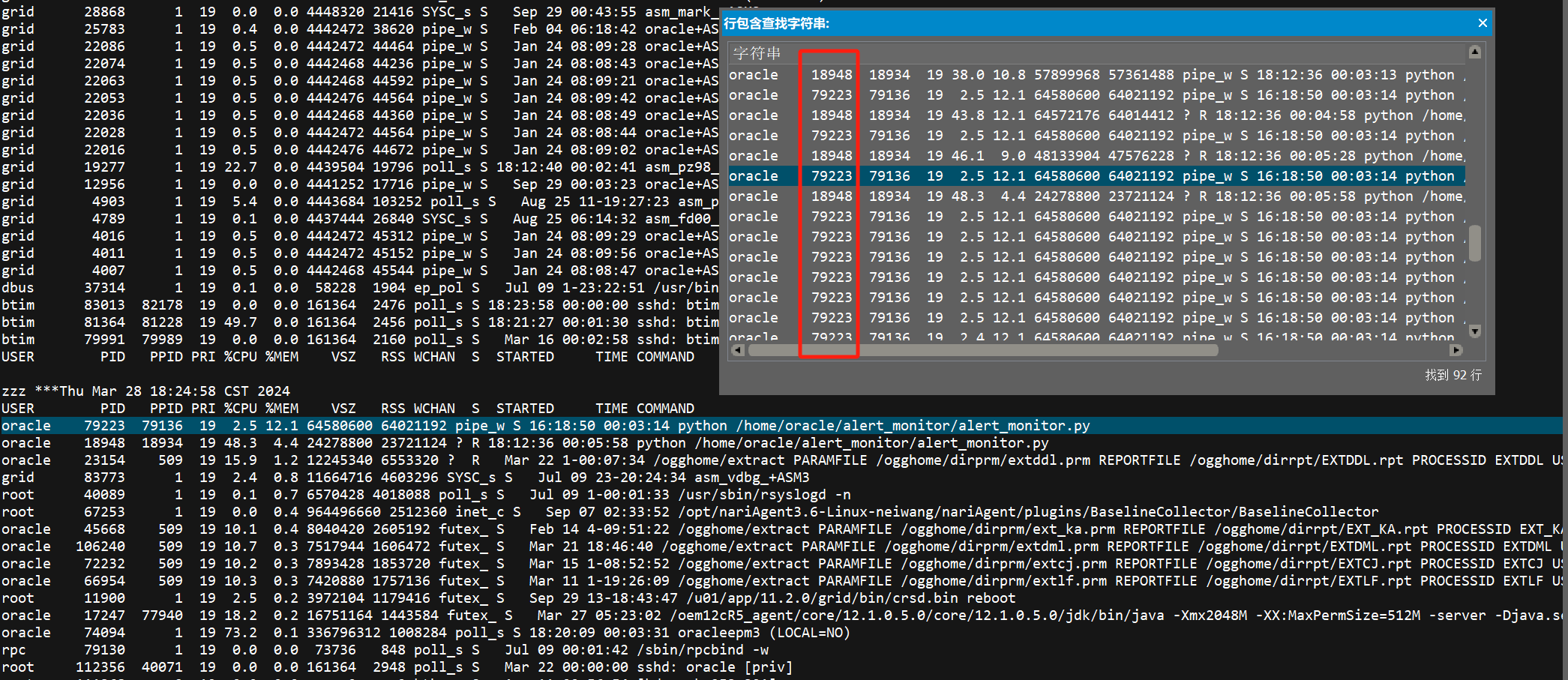
而79223最后出现的时间是18:38:31,两个python进程消失的时间点,与剩余内存增加60G的2个时间点完全吻合。

3. 总结
经过前面的分析,问题是由于3节点的 alert_monitor.py 脚本消耗的大量的内存,将主机内存耗尽,出现了集群部分 agent 重启和主机 HANG,导致部分业务超时。
经与一线沟通,alert_monitor.py 是将各个库的 alert 日志里的报错抽到一台专门的服务器上,每天检查。当前故障节点的alert log过大,有20多G,导致程序在处理时消耗的大量的内存。
后续处理:每次 alert_monitor.py 脚本在读取前,先将 alert 日志中最新的一部分 tail 出来保存,供脚本读取,调整后问题未再出现。
文章被以下合辑收录
评论

 0 点赞
0 点赞 0 点赞
0 点赞 0 点赞
0 点赞