




分享:阿里云数据库高级产品专家 陈茏久
整理:墨天轮
导读
在数据驱动的时代,非结构化数据如图像、视频和文本的爆炸性增长,对传统数据库提出了巨大挑战。向量数据库的重要性日益凸显,它能够高效地处理和分析这些数据,通过将它们转换为特征向量,实现快速检索和深入洞察。在这样的技术革新浪潮中,AnalyticDB PostgreSQL作为向量数据库的代表之一,如何帮助企业在数据驱动的决策中获得先机?
【墨天轮数据库沙龙】邀请到 阿里云数据库高级产品专家陈茏久,为大家带来《AnalyticDB PostgreSQL及RAG服务实践》的主题分享。以下为演讲实录。

陈茏久
阿里云数据库高级产品专家
去年,我们目睹了向量数据库领域的飞速发展。GPT的横空出世,不仅标志着向量技术正式与RAG方法论结合,更为企业打开了一扇利用大数据实现创新服务的大门。随着技术的不断演进,我们看到了阿里通义模型、百模大战等多模型的共同繁荣,这些进步不仅推动了RAG方法论的创新,还催生了一些框架型产品。今年6月,Open对Rockset的收购进一步证实了大模型与数据整合的趋势。这种整合为Rap场景注入了新的活力,也展示了数据与大模型相互支持的巨大潜力。
AIGC模型的分层结构,将服务分为企业层和模型服务两个核心部分。企业层服务专注于构建企业的核心知识库,并结合企业知识与大模型进行优化,以满足特定的业务需求。而模型服务则以大模型为基础,不断涌现针对不同垂直行业的定制模型,这些模型能够更精准地满足行业需求。
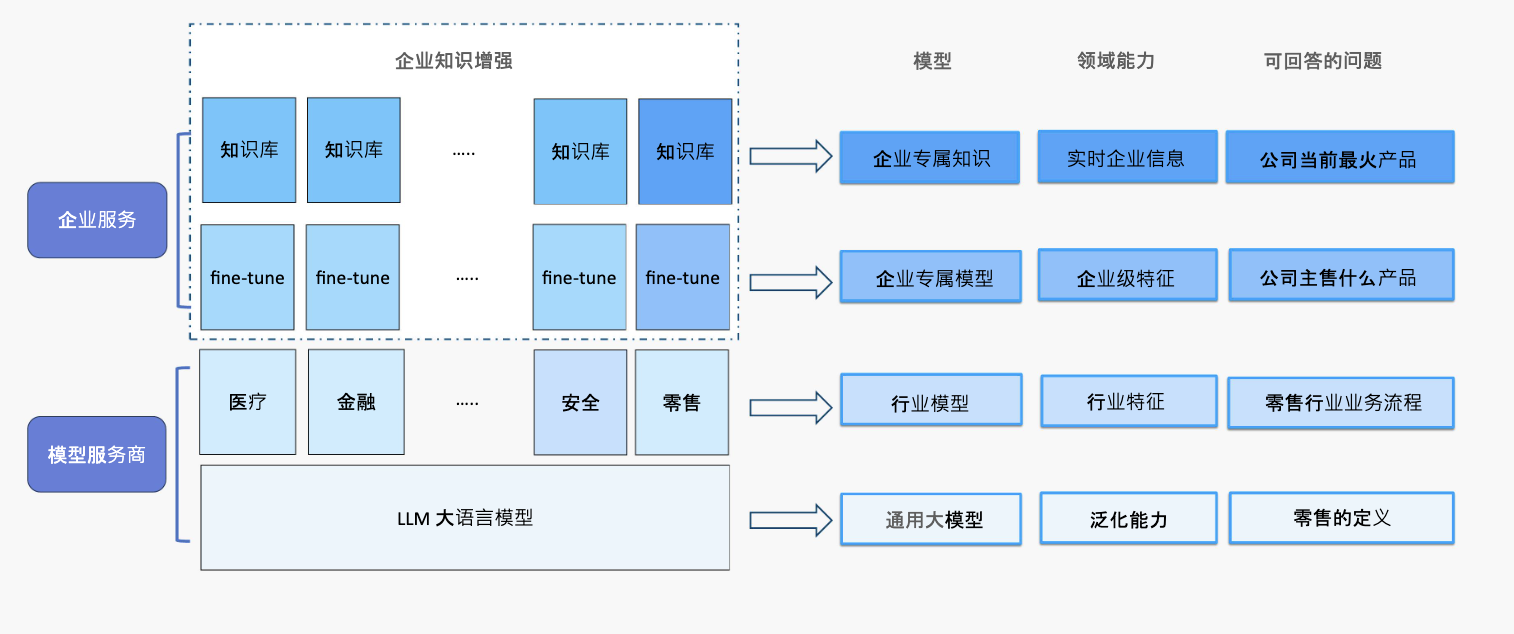
图1 AIGC分层能力一览
向量数据库已成为一个热门概念。厂商如Milvus、Chroma等,凭借在向量领域的深耕,迅速响应市场的需求变化,展现出了强大的技术实力和市场适应性。在RAG体系的构建过程中,我们面临的挑战不仅是向量的检索,更在于企业级知识库的搭建。数据库厂商已经开始将自身能力向向量领域延展,支持结构化和非结构化数据的向量相关性支持。
AnalyticDB for PostgreSQL作为一款强大的数据分析引擎,自2019年起它便集成了自研向量引擎,以满足图像检索、人脸识别等场景下的需求,不仅具备完备的企业级能力,更展现出其独特的竞争优势。AnalyticDB for PostgreSQL非常适合在RAG时代构建语义检索和数据处理能力。
在接下来的内容中,我们将详细介绍AnalyticDB的相关能力,一探它如何利用向量数据库技术,为企业提供深度的数据洞察和决策支持。
AnalyticDB for PostgreSQL 产品介绍
AnalyticDB 是阿里云自研的一款原生数据仓库,它在性能上对标国际头部友商,如Amazon Redshift,展现出卓越的分析能力。自2019年起,我们开发了自研的向量引擎,该引擎完全适配了AnalyticDB的产品架构。在性能测试中,我们发现它相较于一些开源产品具有明显的优势。
无论是单一场景还是企业AI中台,越来越多的用户基于开源社区构建自己的RAG体系。AnalyticDB紧密跟随社区的步伐,支持开源。对于如Langchain、LlamaIndex等快速增长的社区,也已经适配了相应的引擎。在一些核心场景,例如长短时记忆、整体召回策略、以及声誉召回优化等方面,AnalyticDB进行了深入的适配和优化。
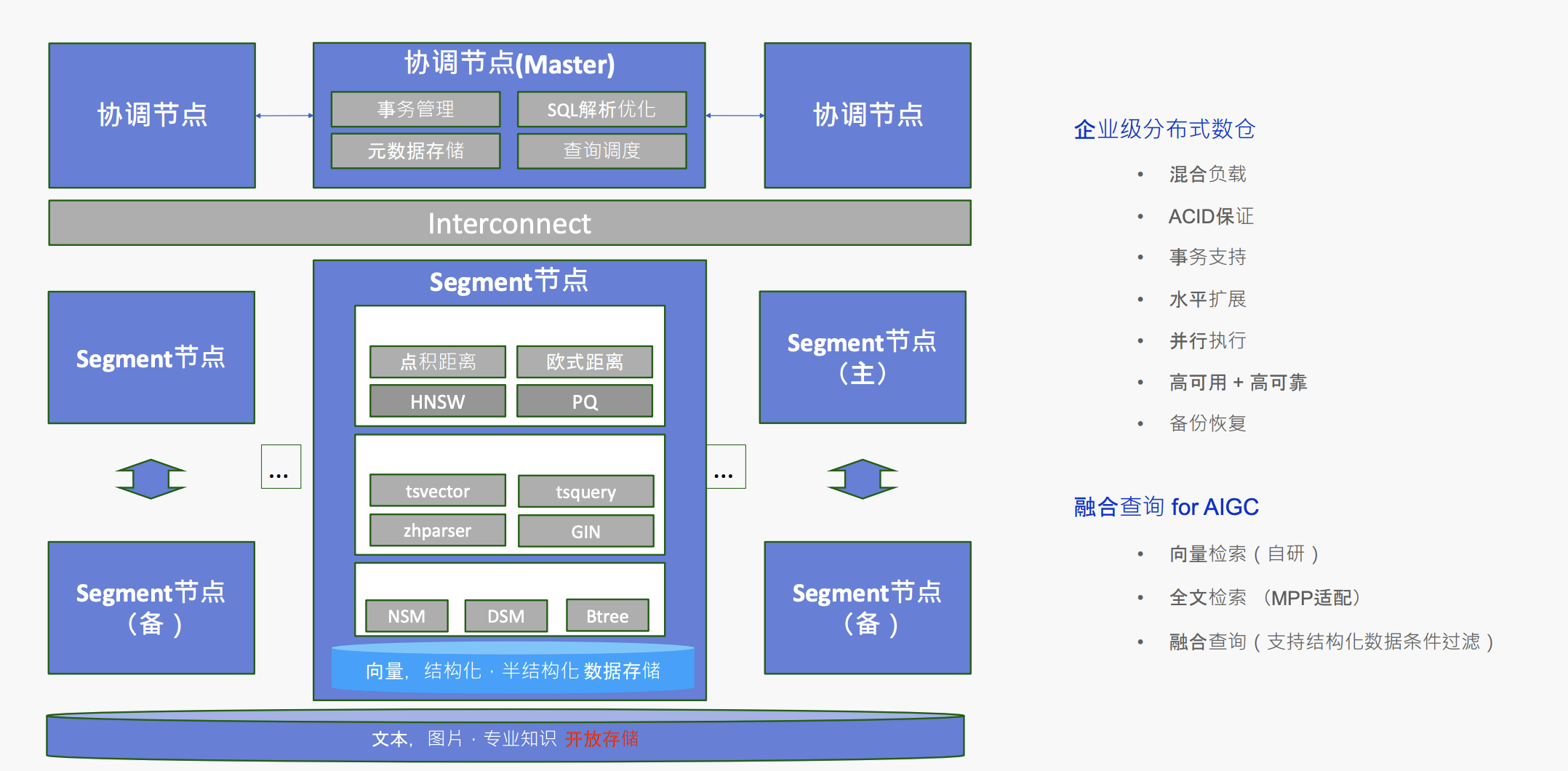
图2 AnalyticDB for PostgreSQL 架构
AnalyticDB作为一款MPP(大规模并行处理)数据库,在处理日益增长的数据量方面具有其独特的优势。然而,在服务客户的过程中,我们经常面对的一个问题是:随着业务规模的扩大,数据量的膨胀可能会给内存管理带来挑战。内存开销的增加不仅可能导致运维难度提高,还可能影响到系统性能,并导致使用成本的上升。
正是为了解决这一问题,AnalyticDB特别设计了内存和磁盘的融合查询功能。这一特性意味着索引查询不必全部在内存中进行,从而可以在不牺牲性能的前提下,有效控制成本。此外,AnalyticDB采用的分布式执行策略,让数据库即使在面对复杂的向量检索和语义查询检索任务时,也能够通过分布式计算提升效率。随着系统中节点数量的增加,整体的查询能力也会相应得到显著提升。
AnalyticDB的设计理念是提供一个全面的解决方案,它不仅支持向量查询、全文检索以及结构化查询的融合,还允许客户通过一站式服务进行混合查询逻辑。这种集成方法不仅提升了查询性能和数据召回的准确率,也体现了AnalyticDB对企业级需求的深刻理解。它包含了负载隔离、事务性保证、高可用和高可靠性架构,以及备份和恢复功能,这些都是构建一个可扩展知识库的关键要素。目前,许多企业正寻求这种高可靠性和低运维成本的解决方案,以实现其知识库的长期发展。
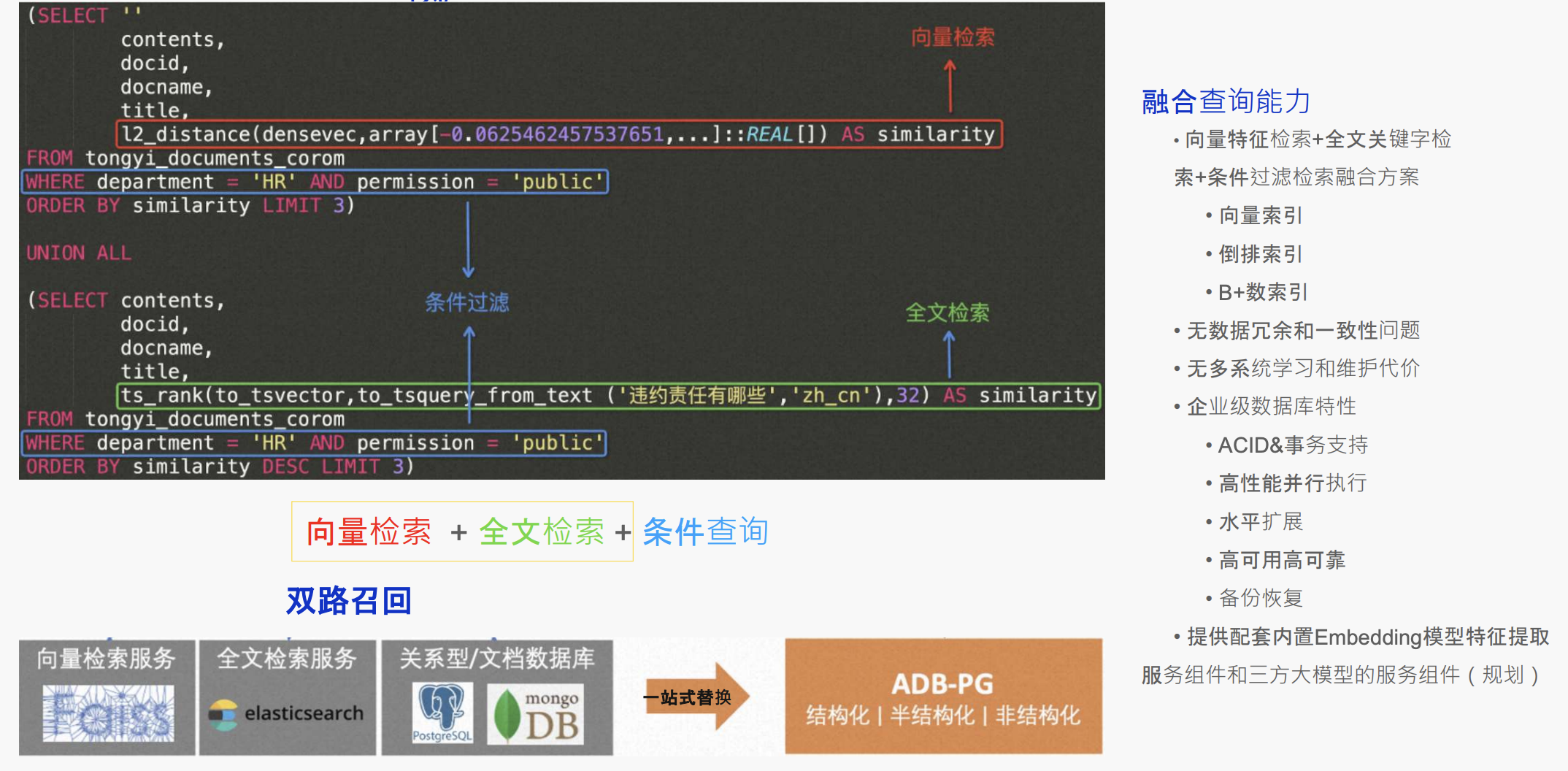
图3 AnalyticDB 融合查询案例
在ADB的融合查询案例中,我们看到了一条SQL语句如何巧妙地结合全文检索和向量检索,满足不断增长的市场需求。客户现在可以利用稠密向量与全文检索的结合,甚至结合稠密向量和稀疏向量,辅以结构化查询,以实现基于业务语义的高质量数据召回。这种高质量的数据召回对于企业来说至关重要,因为它在大模型推理过程中提供了更完整、更相关的语义信息,显著提高了推理的准确性和全面性。
过去,企业在使用数据库引擎时可能需要依赖多款引擎的组合,这无疑增加了操作的复杂性和成本。然而,ADB的一站式查询策略从根本上减少了这种复杂性,帮助用户降低了服务成本,简化了管理流程。AnalyticDB的性能优化不仅限于查询策略。我们在底层指令层也进行了大量的优化工作,与阿里云的多元芯片服务,包括AMD和英特尔芯片,进行了深度合作,确保了整体性能的显著提升。在算法层面,我们通过分区并行改造,全面支持向量处理,并确保了在分布式环境下性能的线性增长。我们的执行计划也经过了细致的相关性优化,以支持用户根据自定义的性能需求进行调整。此外,AnalyticDB还向高阶客户开放了增强功能,赋予他们更大的自主管理能力。
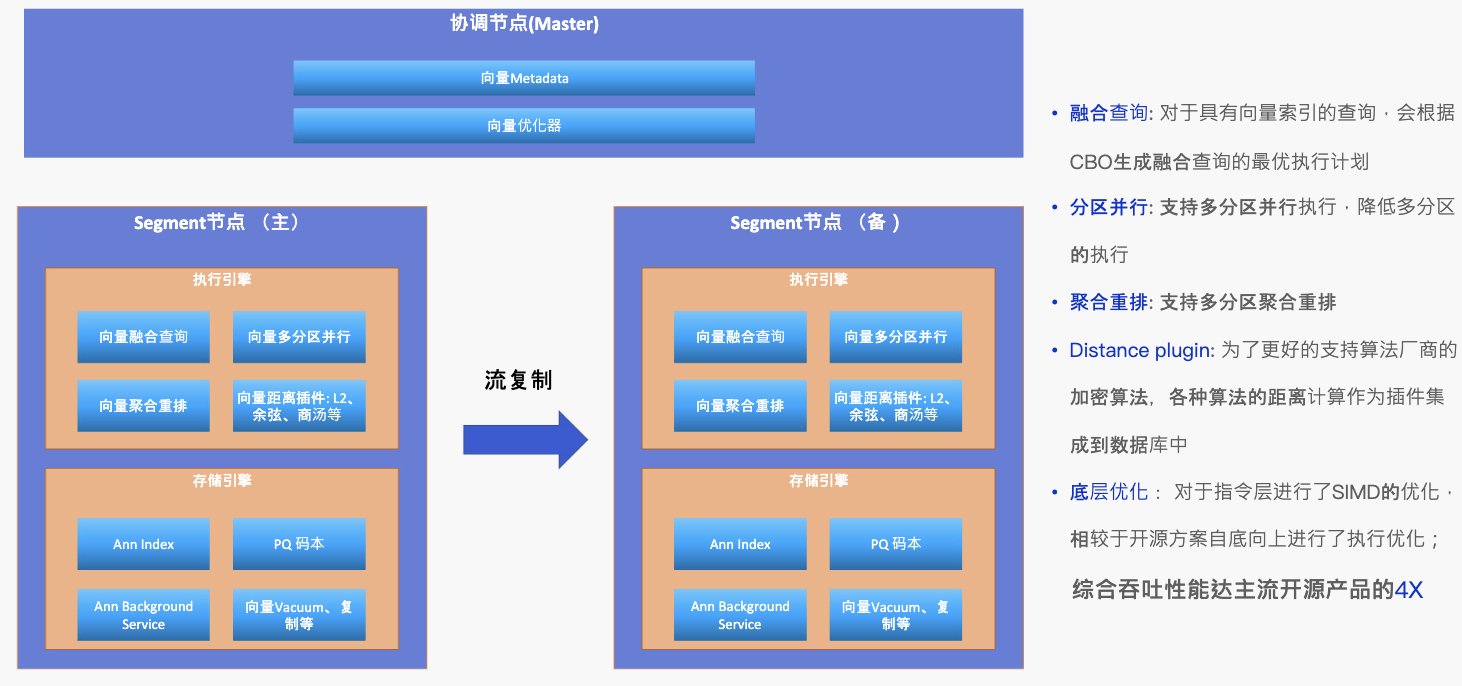
图4 AnalyticDB 向量能力架构及优势
去年,我们参与了信通院的相关评审活动。在这些评审中,我们观察到几乎所有的MPP数据库引擎都能够实现较高的召回精准度。然而,在企业级能力的完备性方面,不同厂商所提供的服务水平存在差异。在ADB方面,我们的企业级能力之所以完备,很大程度上依赖于我们多年来在数据仓库领域多场景经验的积累。我们的产品能够支持实时与离线一体的数据处理、事务型更新管理、融合查询、分区高可用性,以及对超存多个向量的支持。这些能力使我们能够为用户提供更丰富的功能,使他们能够构建更加多样化的应用场景。ADB的这些企业级能力,不仅提高了数据处理的灵活性和可靠性,也为用户提供了更加全面和强大的工具,以满足他们复杂的业务需求。

图5 AnalyticDB for PostgreSQL 向量能力竞品分析
RAG 行业探索
对于RAG的逻辑,我想大家已经相当熟悉,因此我不会在这里赘述。相反,我将重点介绍我们在构建RAG时所采用的方法论和流程。
ADB在我们的全景支撑生态中,从数据源层面支持了结构化和半结构化数据源,如MongoDB等,以及其他多种数据平台,例如Data Lake和开放存储,包括文档、图片、视频和声纹等。ADB提供了丰富的接口和数据加载方法论,确保了数据建仓和知识库构建流程的完备性。在服务过程中,我们在核心数据能力的基础上,进一步构建了一个面向Web全场景应用的API服务层。这包括Web服务的创建流程,从文档的切分、处理到embedding的创建、数据存储、结构化语义召回,以及结果的优化等。我们为这些流程提供了独立的API,使用户能够更加便捷地面向应用进行创建。同时,我们还提供了数据服务的API和资源管理的API,使用户不必依赖SQL来创建RAG服务,而是可以通过API全链路地进行服务。目前,我们发现大约60%的客户都在使用这些API。对于开源框架的支持,如Dify和Streamlit,我们的集成和社区生态支持得到了用户的认可,使得他们更愿意将核心企业知识库托管在ADB上,实现灵活的多租户开发。此外,ADB也是阿里云商业化产品的核心向量基础层,服务于阿里云百炼、阿里云析言等产品。

图6 AnalyticDB for PostgreSQL 生态全景
在整体上,我们将ADB定位为企业级服务的重要组成部分。ADB不仅在服务层和SQL层提供了全面的支持,还通过AI4DB,结合MPP能力和大模型能力,为数据分析场景提供加持。例如,利用通易的大模型进行客户问题质检和情感分析,ADB支持原生调用方式,实现了数据分析与企业级数据仓库的一站式构建体验。ADB在存储层支持多模态存储,帮助客户使用单一引擎更好地管理企业数据资产。我们提到的RAG服务是一站式的,从文本处理到图片和文本结合,再到视频,我们支持独立原子级别的API服务。这些服务可以连续调用,也可以独立调用。我们还持续支持开源算法和阿里云独有的算法,包括通易的高阶embedding算法,以提高召回率。
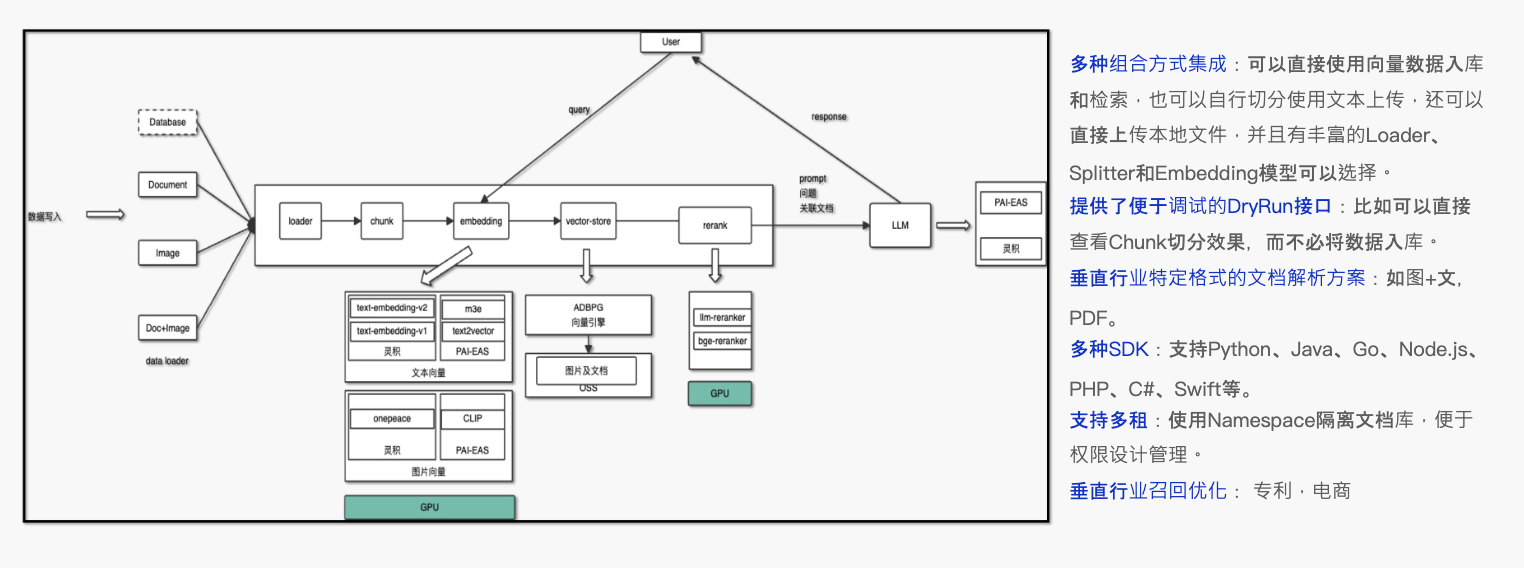
图7 ADB-PG RAG Service 一站式满足业务应用开发
我们还支持基于rerank模型的结果优化,对召回结果和PRI语义进行比对后,进行基于语义的重排,确保提供给大模型的内容具有更高的相关性和语义准确性。对于垂直行业,如专利处理和电商领域,我们也开发了特定的文本处理能力,并欢迎有兴趣的朋友一起交流。
企业级解决方案设计‘
我们为不同企业提供了多套定制化的解决方案。首先推荐的是阿里云的通义千问百炼产品,它提供全面的模型服务,覆盖模型训练、使用到微调的全链路。在百炼应用中,我们支持创建用户智能体,并为企业在需要RAG技术的地方建立独立的专有知识库。

图8 企业级专属RAG解决方案: 通义百炼专属大模型
面对企业对数据安全和合规性的担忧,尤其是对数据投递给百炼平台后可能存在的风险或合规问题,我们提供了一种解决方案:企业可以在本地部署AnalyticDB,并将其与百炼平台连接。这样,所有文本数据处理后都存储在企业私域内的知识库中,只有Skype所需的知识块才会投递到百炼模型平台进行语义生成。这种设置确保了数据的安全,同时AnalyticDB可以对企业的所有数据进行审计。
在服务过程中,我们还提供OCR识别和智能文档处理服务,阿里云的智能文档处理产品在文档提取、段落分析和内容解析方面,提供了比开源产品更优的性能。此外,我们还增强了RAP技术,采用了后公立的长短文本训练模型,提升了查询准确率。我们发现,结合稀疏向量的方法可能比传统的全文加上稠密向量的查询准确率提高约20%。
除了阿里云的方案,我们也支持客户使用开源框架或构建自己的多场景应用。AnalyticDB支持在ECS上快速部署多场景应用服务,并结合销量知识库进行独立租户隔离,实现独立的知识、权限和资源管理。我们还支持调用阿里云的PES服务,部署多种开源大模型,并使用GPU进行管理,帮助企业避免厂商绑定,同时利用开源优势。
目前,约有10-15%的客户采用此类方案进行平台搭建。对于有特殊需求的客户,我们也支持调用海外开源模型或基于自部署GPU的支持。我们还为AI服务商提供了多租户方法论,支持中长尾客户和大VIP客户的资源综合管理。通过外购服务层,可以实现多租户构建,每个租户的知识库对应一张表,进行逻辑隔离,而对于头部客户,则可以创建专属资源实例,进行物理隔离。
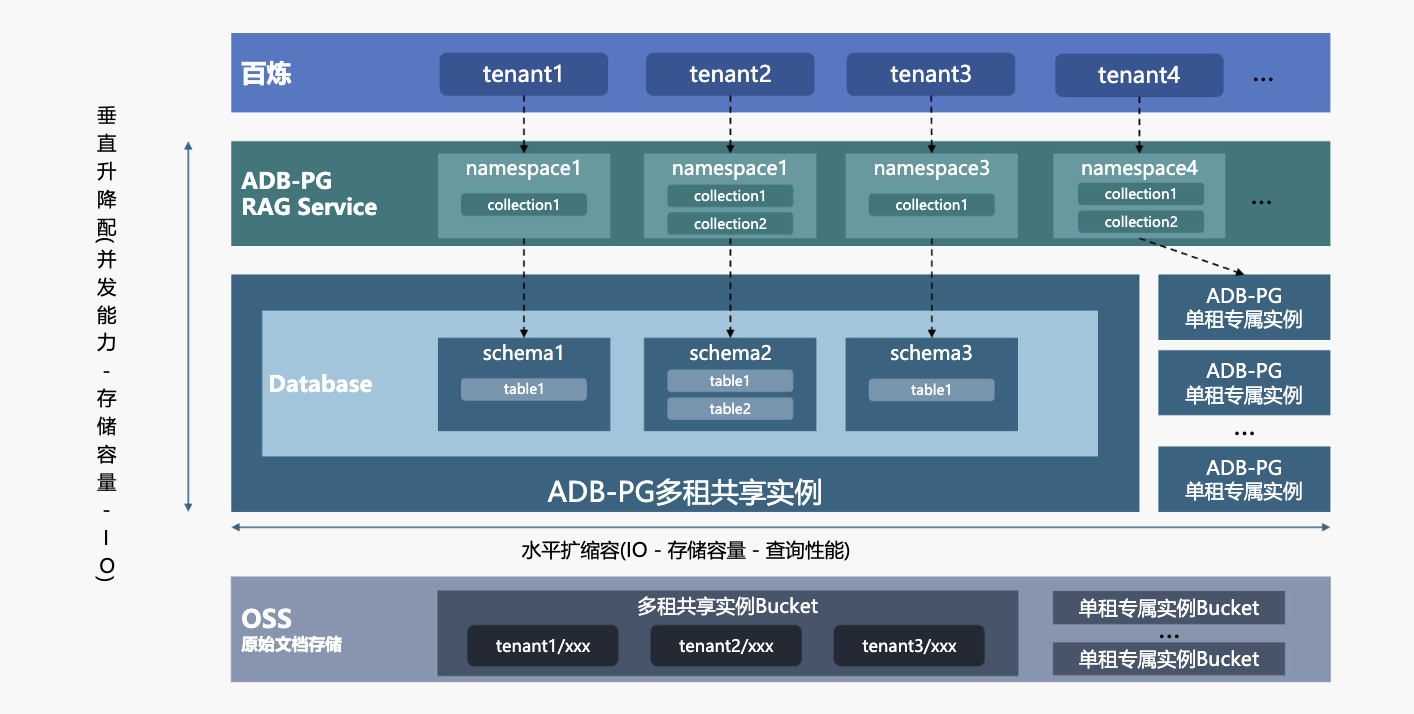
图9 基于ADB-PG 构建的RAG多租户服务
在存储方面,AnalyticDB可以实现水平扩容,满足用户和数据量的增长需求。这为基膜服务厂商或外部SaaS服务厂商提供了架构支持和最佳实践。AnalyticDB也支持私有化部署,我们在国企和央企中通过这种方式进行相关输出,确保了企业数据的安全性和可控性。
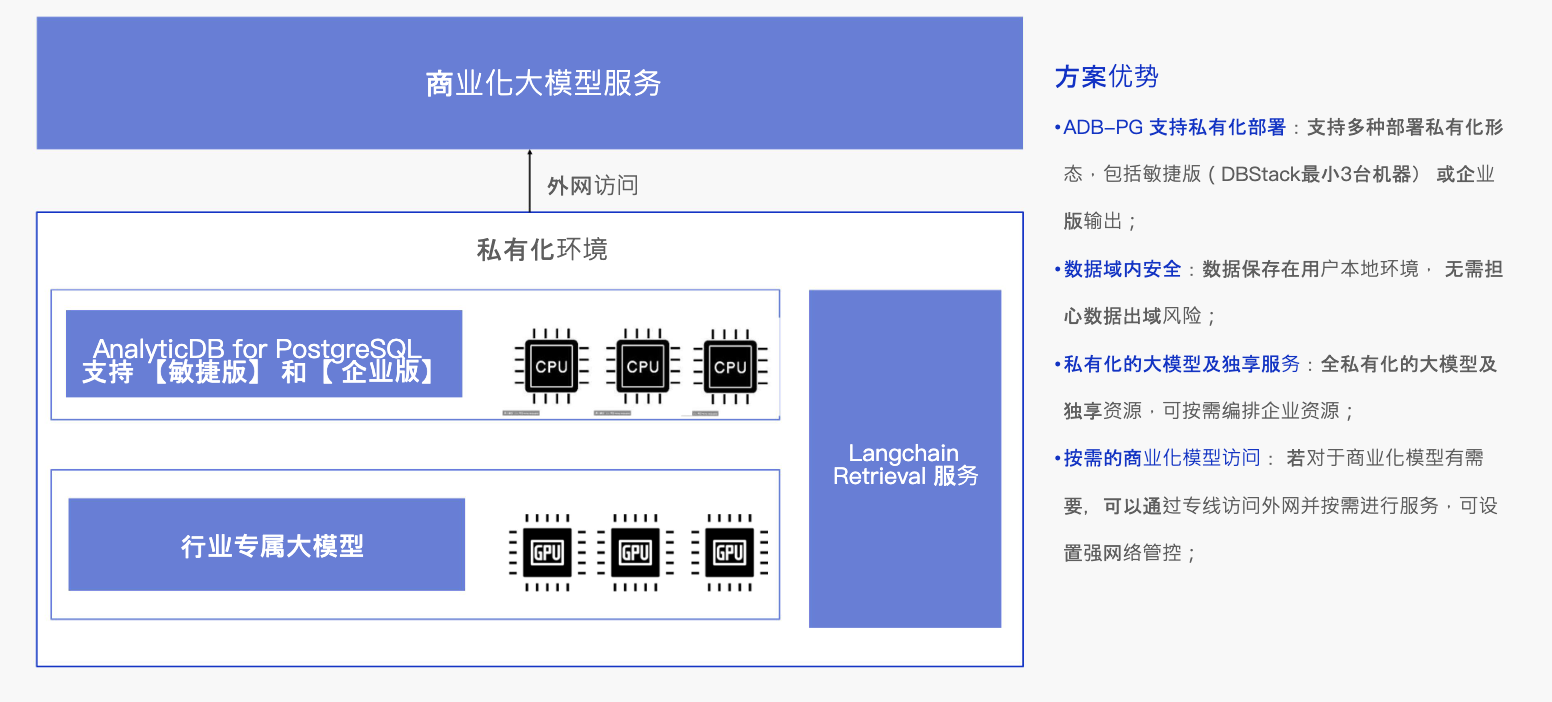
图10 私有化部署解决方案
典型场景案例
接下来,我将分享几个实用的案例,首先是针对游戏行业的客服挑战。游戏行业在新游发布、运维或举办活动期间,常常会面临大量客服客诉的涌入。由于游戏公司通常难以迅速扩充和培训客服团队,这就催生了对自动化客服系统的需求。理想的自动化系统不仅能够提供接近真人的交互体验,还要准确捕捉和理解用户的意图。通过整合大型语言模型和每款游戏独有的世界观知识库,我们能够实现多轮对话式的客户支持,显著提升了服务效率和质量。

图11 ADB在游戏行业中的应用
在实际应用中,这种方法不仅将准确率提高了20%,还大幅度降低了服务成本。对于新游戏的快速接入,我们的框架能够迅速构建起基础信息和体系,并支持持续更新游戏活动,同样的方法论也适用于游戏内NPC的互动支持。
第二部分是关于阿里云自身产品改造,即阿里云产品博士的落地实践。随着业务的扩展,需要一个企业级的知识大脑来支持日益增长的员工数量。通过梳理核心知识,并利用大型模型Web方式来回答关键问题,我们可以高效地传播和应用知识。去年,阿里云进行了深入的探索,目前我们的内部产品模式能力已经服务于内部几千个客户,整体方案融合了阿里云百炼和AnalyticDB的私有化部署。
服务过程分为四个阶段。第一阶段是企业级业务梳理,完成概念验证(POC)和基础能力的搭建,包括网络环境的搭建和使用当前语料的流程支持。第二阶段是基于质量召回内容的持续改进,包括RAP检索体验的升级和创客及隐白点的优化,这些能力已经整合到百链上,实现开箱即用。第三阶段是企业内部质量内容的优化,需要企业持续支持松散格式和产品内部格式的标准化,并引入大型模型以支持对核心准确性要求高的场景,同时对内部内容进行分类覆盖。在检索时,我们前置引入了agent,以指向性地引导不同类别的问题和内容,利用AnalyticDB的融合查询功能,实现对更相关内容的快速收敛。
最后一个阶段是应用侧体验的升级,旨在帮助用户在体验上进行升级,提升用户满意度。许多企业在了解到这款产品后,都表现出了在自身企业内落地服务的强烈愿望。

图12 ADB在阿里云产品博士中的落地实践4个阶段
今天的分享大致是这些内容,我希望能够激发更多的思考和讨论,也期待我们的服务能够覆盖在座各位的企业和场景。
更多精彩内容,欢迎大家观看现场视频回放与会议资料
视频回放:https://www.modb.pro/video/10052
会议资料:https://www.modb.pro/doc/134609
评论

 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞