




写在前面
 。
。
Bloom 原理
数据存储原理
布隆过滤器的原理要说还是比较简单的,下面我就结合图片进行一下简单说明。
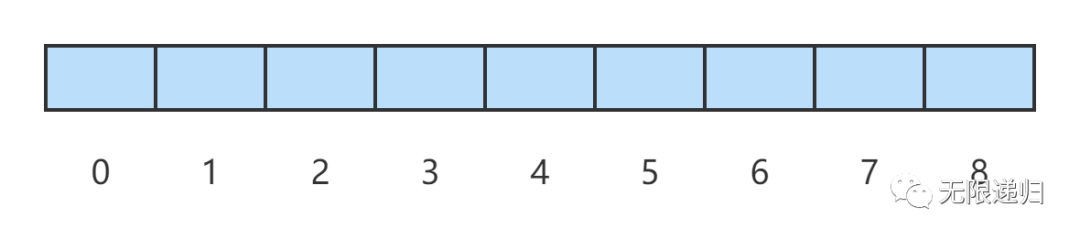
首先看下图:这个图片中有一个位数组,数组的每一位都可以表示0或者1(为了演示,这里位数组的长度我就画的短了些,实际不止哈)
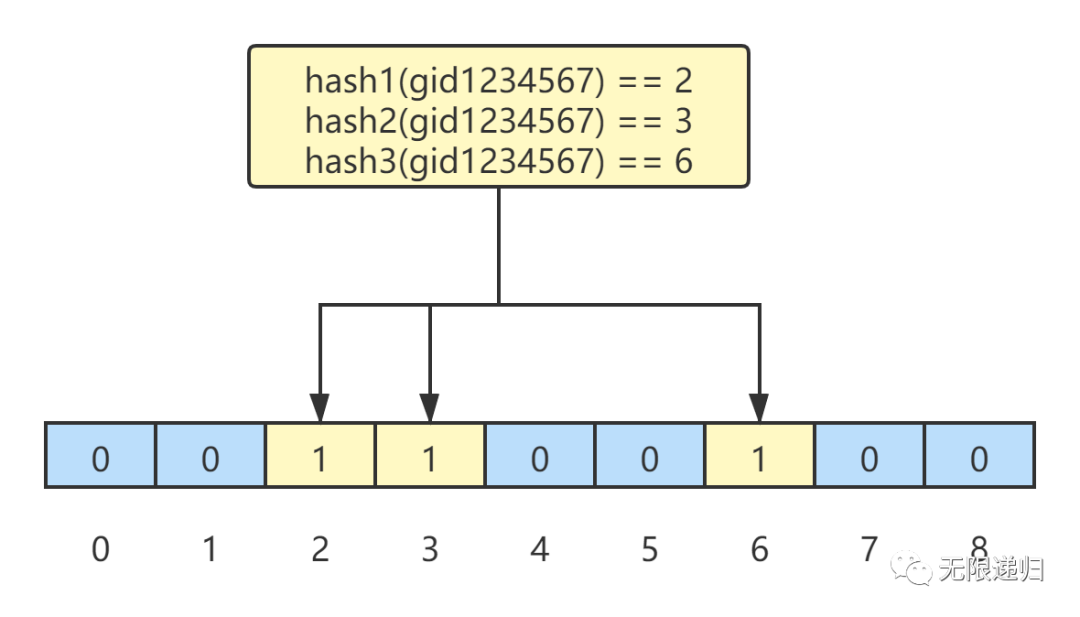
然后使用三个hash函数对指定value(gid1234567)求值,然后把hash求值所对应的位数组中的位存为1
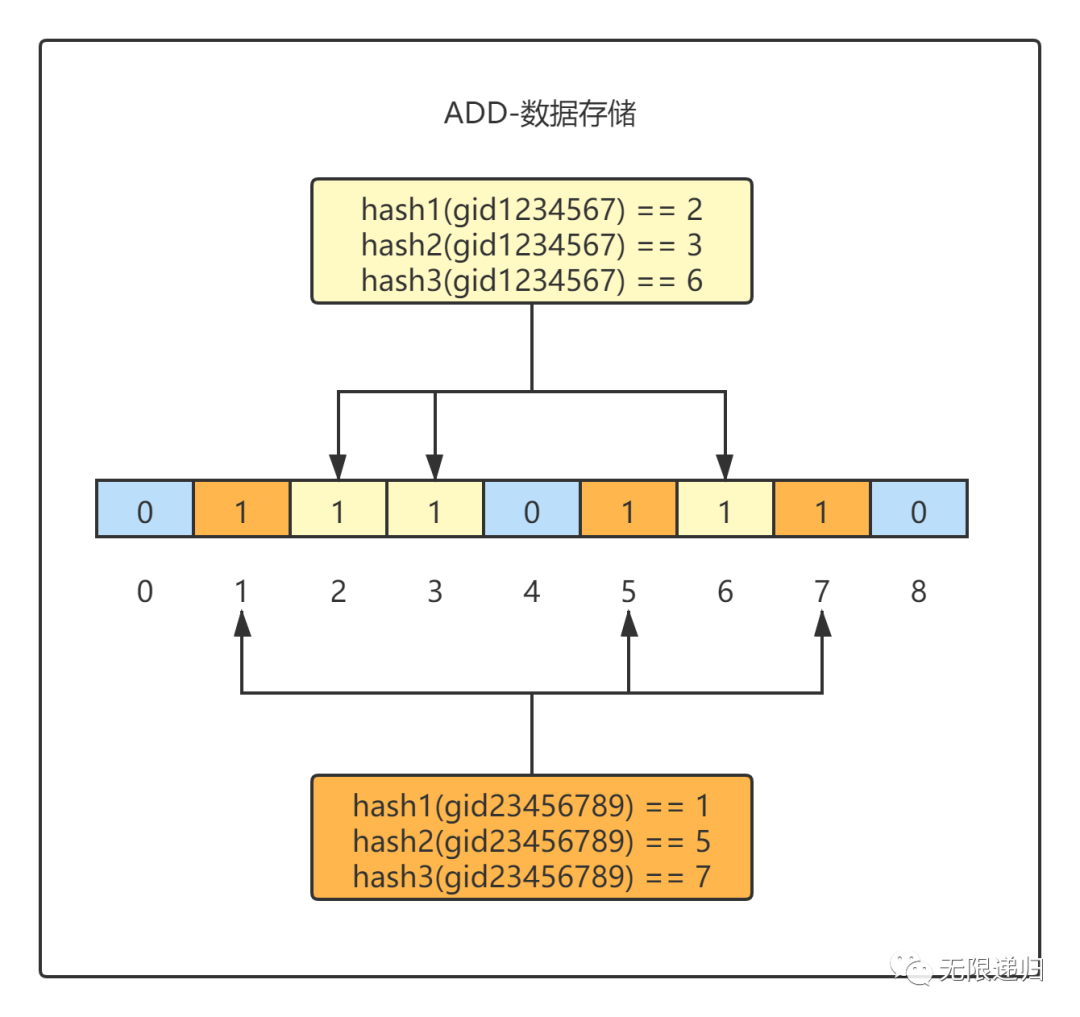
再使用hash函数对指定value(gid23456789)求值,然后把hash求值所对应的位数组中的位存为1
假如我们有1亿个商品ID,那我们就反复通过上面的步骤将商品ID经hash求值后对应的位数组的位置为1,这里我就不以图真正演示了哈,画不过来,哈哈哈!
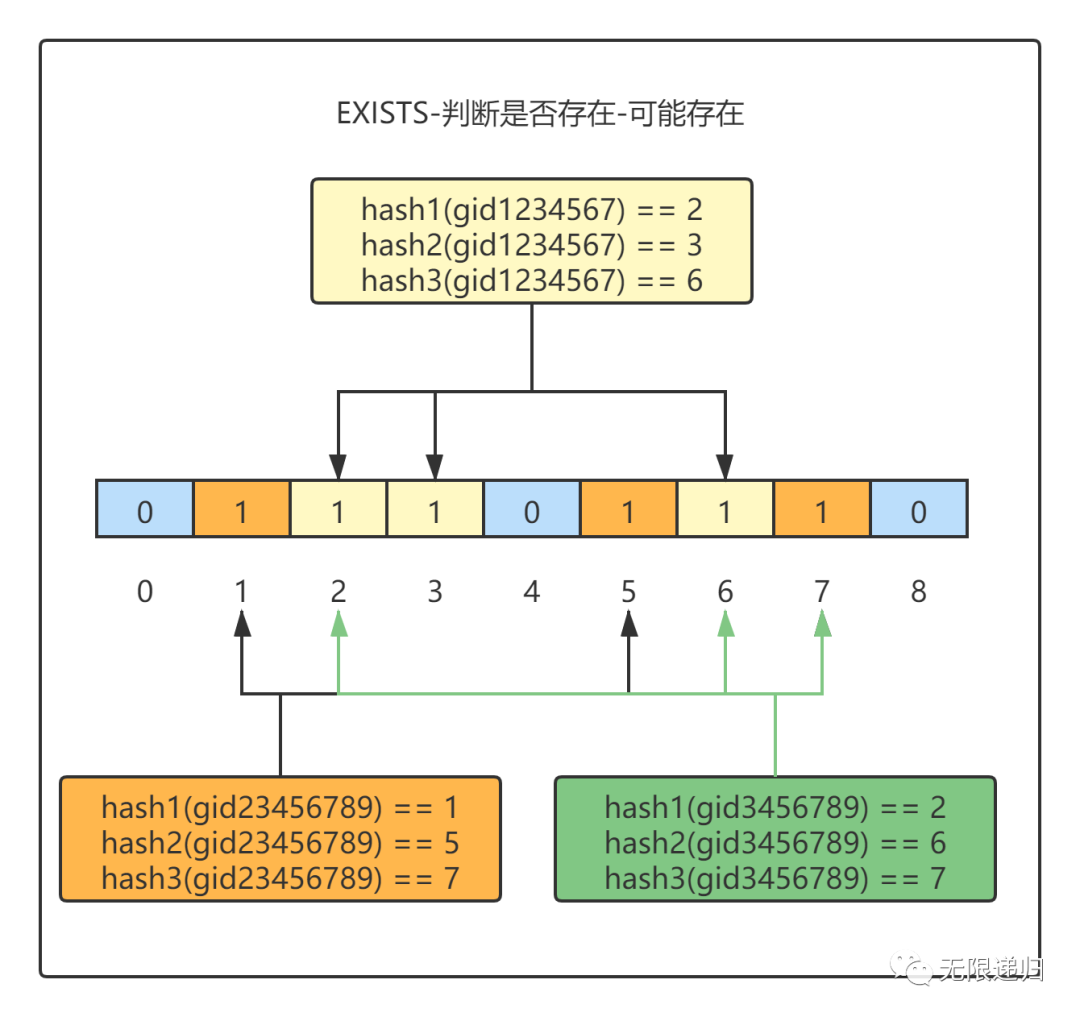
判断存在原理
存储好后,我们就可以使用同样的方式来对一个商品ID进行判断,看看这个商品ID是否存在了。同样是使用同样的hash函数对要判断的商品ID进行求值,然后看对应的位数组中的位上是否为0,如果出现任意一位为0了,那么说明这个商品ID一定不存在。但是如果每一位上存的都是1,那么这个商品可能存在。
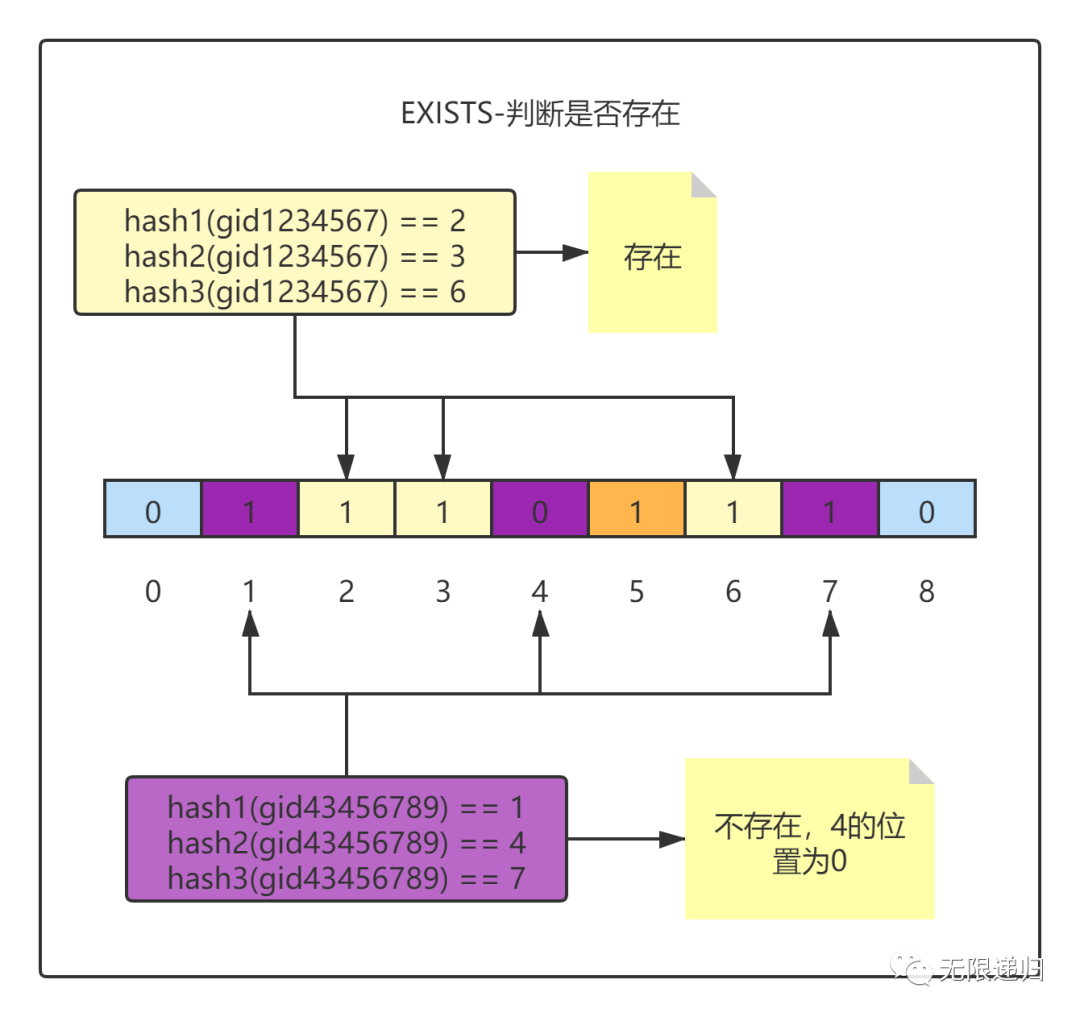
为什么是可能存在呢?因为存在hash冲突这种情况,当两个值求得的hash值一样后,就会误判为当前值存在,所以当所有hash后的值对应的位存的都是1时,并不一定说明该值一定存在。图中value(gid3456789)经过hash求值后与value(gid1234567)和value(gid23456789)两个值得hash值产生冲突,导致value(gid3456789)求值后对应位上的值为1,进而误判为存在。
Bloom 优缺点
优点:节省空间,判断速度快
缺点:元素删除困难,并且存在一定误判率
Bloom 适用场景
Bloom 过滤器适用于判断某个元素是否出现在某个集合中,但是容许有一定误差的情况。同时比较适合在数据量非常大的情况下使用,数据量小的情况下完全可以直接使用hashtable来做唯一性判断策略。
在业务上可以应用的场景有:
解决缓存穿透问题
对url去重
垃圾邮件过滤
等等...
Redis Bloom 本地内存占用测试
为了方便,我直接使用的docker来进行的测试
docker pull redislabs/rebloom复制
安装好之后,启动一个container,然后在本地使用
redis-cli
进行连接
redis-cli -p 16379复制
然后看下安装后的redis内存信息,可以看到没放数据前,大概有857K
127.0.0.1:16379> info memory
# Memory
used_memory:875280
used_memory_human:854.77K
used_memory_rss:7503872
used_memory_rss_human:7.16M
used_memory_peak:919640
used_memory_peak_human:898.09K
used_memory_peak_perc:95.18%
...复制
接着我执行如下lua脚本,向bloom中加入10W条数据
EVAL "for i=1,100000 do redis.call('BF.ADD', 'bloomfilter', i) end" 0复制
查看内存占用情况,可以看到10W数据的布隆过滤器大概用了1M不到内存
127.0.0.1:16379> info memory
# Memory
used_memory:1242368
used_memory_human:1.18M
used_memory_rss:8425472
used_memory_rss_human:8.04M
used_memory_peak:1242432
used_memory_peak_human:1.18M
used_memory_peak_perc:99.99%
...复制
然后我在执行如下lua脚本,向bloom中加入1000W条数据
EVAL "for i=1,10000000 do redis.call('BF.ADD', 'bloomfilter', i) end" 0复制
查看内存占用情况,可以看到1000W数据的布隆过滤器大概用了55M内存
127.0.0.1:16379> info memory
# Memory
used_memory:58456216
used_memory_human:55.75M
used_memory_rss:61702144
used_memory_rss_human:58.84M
used_memory_peak:58497088
used_memory_peak_human:55.79M
used_memory_peak_perc:99.93%
...复制
最后我插入了1亿条数据
EVAL "for i=1,100000000 do redis.call('BF.ADD', 'bloomfilter', i) end" 0复制
查看内存使用情况,1亿条数据大概占用内存470M内存
127.0.0.1:16379> info memory
# Memory
used_memory:519829824
used_memory_human:495.75M
used_memory_rss:493154304
used_memory_rss_human:470.31M
used_memory_peak:519870696
used_memory_peak_human:495.79M
used_memory_peak_perc:99.99%
...复制
关于BF.EXISTS的执行时长,那是相当的快了,这个无需担心。而且1亿条数据的占用内存在470M左右,可以说也是没啥问题的
往期推荐


扫码关注更多精彩
