




一.Placement Rules in SQL主要解决什么问题?
假如数据库集群部署在不同的数据中心,如下图所示,将可能出现以下几种类型的问题:
|
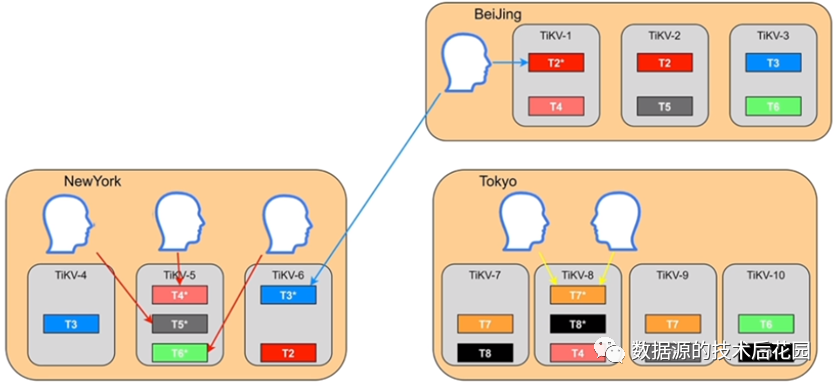
(1)无法进行本地访问。比如BeiJing的客户端需要访问T2和T3表,怎么能够将T2和T3表的Leader及所有副本都固定在BeiJing这个数据中心,以达到本地数据中心访问的需要,避免跨数据中心的访问延时。
(2)无法根据业务隔离资源。比如NewYork有三个客户端,分别需要访问T4、T5和T6表,怎么能够将这三个不同的业务表分布在不同的服务器上,以达到业务隔离资源的效果,而不是像下图那样可能几个表的Leader都在同一个节点从而造成负载不均衡。
(3)难以按照业务等级配置资源和副本数。比如Tokyo中有一个非常重要的业务表T7,为了保证数据不丢失,怎么能够将这张表的副本数据设置多一点。为了保证T7表的访问性能,怎么能够将它分配到性能较好的机器上,而T8表是一个历史归档表,怎么能将它与T7表隔离开来。
以下几类情况在TiDB 6.0之前的版本都不容易实现,为了解决这些问题,TiDB 6.0版本中增加了Placement Rules in SQL功能。使用Placement Rules in
SQL的功能,可以实现下图所示的效果:
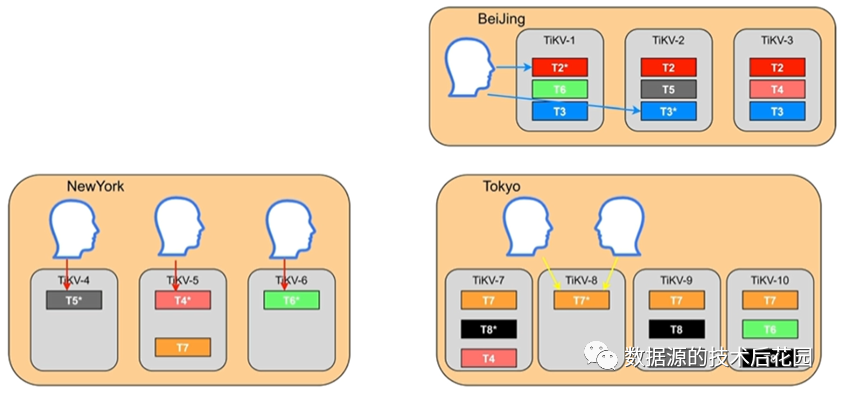
(1)支持本地访问。如下图所示,可以将T2和T3表的所有Region副本放置在BeiJing数据中心,这样所有北京的客户端都只需要访问本地数据。
(2)支持业务隔离资源。如下图所示,可以将T4、T5、T6表的Leader分布在不同的数据节点,这样对这些业务的访问压力将被分摊到不同的数据节点。
(3)按照业务等级分配资源和副本数。如下图所示,设置T7表一共有5个副本,并将T8表的Leader分配在与T7表的Leader不同的节点。
|
二. Placement
Rules in SQL怎么使用?
在TiDB
6.0中使用Placement Rules in SQL,主要包含三个步骤:
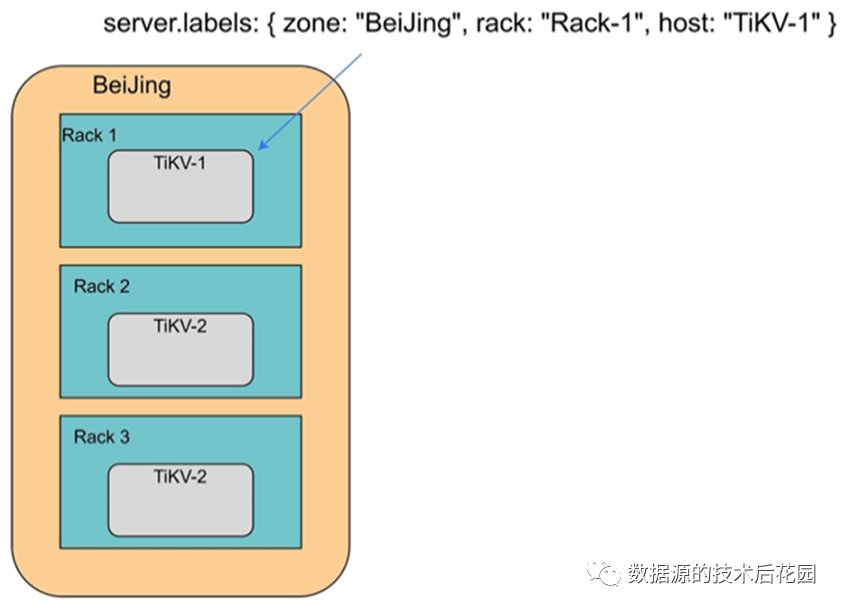
(1)设计业务拓扑,为不同的TiKV实例设置标签。
由于集群的拓扑结构主要由Placement Driver模块负责,因此配置在PD中实现。
|
(2)创建PLACEMENT POLICY。
以下示例列出三个主要的参数,其它参数请参考官网介绍。PRIMARY_REGION代表Leader region位置,REGIONS代表follower region位置,FOLLOWERS代表followers副本数量。
|

(3)设定数据对象的PLACEMENT POLICY。
可以指定schema、表和分区不同粒度的策略。
|

