




本文接前文继续分享真实业务迁移到 OB 4.2 后性能抖动诊断案例。问题属于特殊场景特定版本下,文中观点是个人理解,切勿断章取义。欢迎留言交流。
问题概述
国企非金融客户,两个 MySQL 业务试点迁移到 OB 。一个是外部对公业务,数据量和访问量都不大;一个是内部综合业务,数据量约 500G+,访问量 QPS 约几百。由于涉及到销售、仓储、物流、财务等业务,所以也是比较重要的业务。两个业务原跑在专有云 RDS MySQL 数据库上,后面这个业务大部分时候性能还可以,部分复杂报表查询比较慢。
业务 OB 集群部署在专有云 ECS 上,单台 ECS 规格为 32C256G ,磁盘总容量 3.8TB,一共 3 台。OB 版本为企业版 4.2.1.8
,两个 MySQL 租户,规格分别为 4C16G
、20C100G
。数据同步使用 OMS 。全量迁移、增量同步、同步切换和反向同步都比较顺利。
数据同步做了两次,第一次不开增量,同步数据主要用于业务功能和性能验证,这个耗时 2 周左右。第二次同步是切换前三天开始,开启增量同步,晚上业务停 1 小时切换验证数据,随后正式上线,此后是一周的性能诊断优化。OB MySQL 租户的兼容性高,OMS 对 MySQL 数据同步也很成熟。主要精力都在性能诊断优化上。初期是很多自动化接口测试性能都比 MySQL 慢,后期是部分业务场景时快时慢。
客户业务原本也有一些业务场景耗时在十几秒到十几分钟,所以对迁移到 OB 后的性能期望也比较理性,这就给了 OB 性能优化充分的时间。不过试点业务表现也不能太差,优化的压力也还是有的。
诊断优化
性能诊断优化也分两个阶段。一是硬件性能诊断优化,主要是 IO 优化。二是数据库 SQL 性能诊断优化,主要是执行计划优化。
IO 诊断优化
专有云的 RDS MySQL 是运行在高配物理服务器上,磁盘是本地 NVMe SSD 。专有云的 ECS 是虚拟机。磁盘是 4T 云盘,吞吐峰值 300MB。网卡是单网卡,流量上限 4.5Gb 。OB 跑在 ECS 虚拟机上并不被原厂推荐,几经讨论后客户根据实际现有条件坚持如此部署。
OB 的数据文件和事务日志(clog
)分别使用独立的文件系统(/data/1
和/data/log1
)。第一轮数据迁移的时候, OB 合并的时候磁盘 IO 服务时间在 1ms
左右,但是 IO 等待耗时高达 120ms
左右 。OB 合并导致业务 SQL 性能进一步恶化。
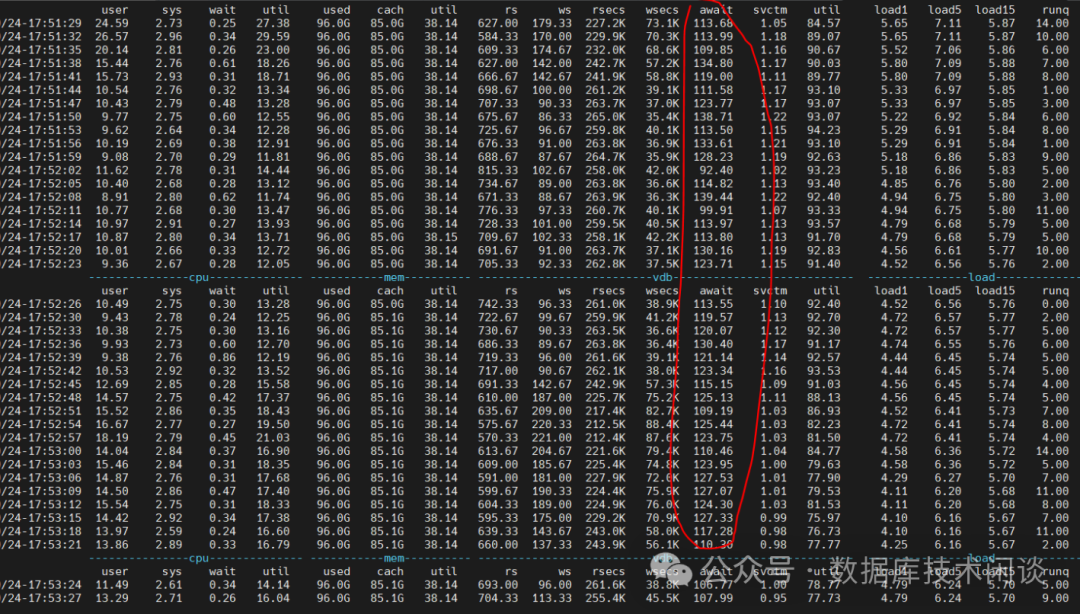
显然在这个 IO 上跑 OB ,性能肯定不会太好。后经讨论不要 4T 单盘,改为 12块 300G 的小盘,然后使用 LVM 创建一个 VG 并划分两个 LV(OB 数据盘和日志盘分别使用)。注意建 LV 的时候使用条带卷(strip volume
)。lsblk
命令最终结果如下:

尽管专有云的云盘说是底层也打散到多块物理盘,但是多块盘总体的IO 吞吐比单盘 IO 吞吐肯定要高,加上 IO 也分散到多块云盘,整体的 IO 延时预计比单盘要低。为了确认这个,特地使用 FIO 对 4T 单盘和 300G 12 盘做了读写测试对比。实际结论也确实如此。
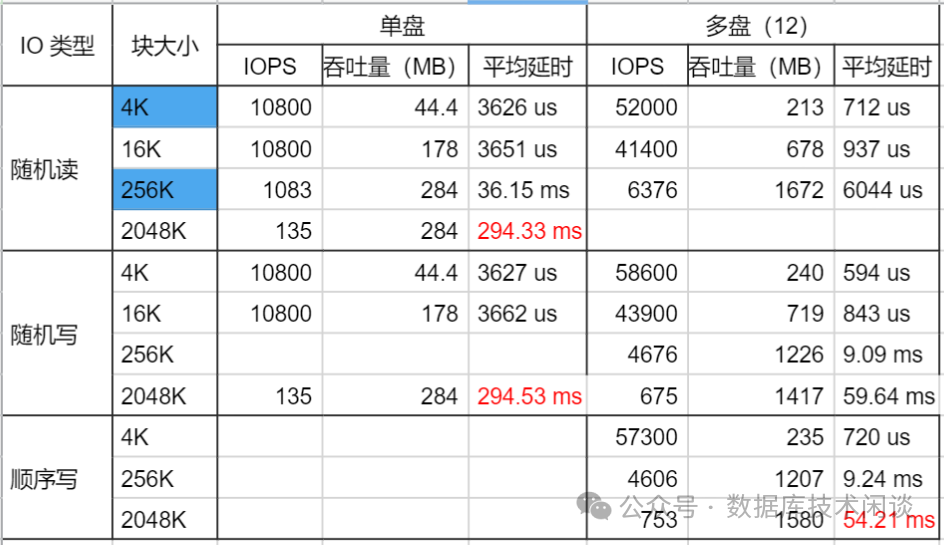
从上图看多盘下,小IO 的平均延时是单盘的 1/5 。
确认方案有效后,就开始 IO 调整。由于 OB 是生产环境部署的,已经通知业务测试了,此时不好再重建集群并重新迁移数据,所以要采用 OB 在线更换磁盘方案。方案的原理跟我以前文章《OB 数据文件缩容技巧》里介绍的节点重建方法类似,利用了 OB 的多副本自动数据补齐功能。
SQL 诊断优化
IO 问题只要找到源头,优化结果就是做到或做不到,因此比较简单。SQL 性能问题就比较麻烦,解决了一个还有一个。业务应用使用了一个开发框架,有很多业务 SQL 是框架生成的。加上业务层面大量的查询组合,所以很多表上的索引也非常多。其中很多还是单列索引。这是绝大部分客户业务的数据库特点。
所以在 MySQL 上业务性能有快有慢,在 OB 上也并不会例外。不过 OB 在应对这种业务 SQL 还是相比 MySQL 更有优势一些。
首先是 OB 有更好的可观测能力,有 SQL 审计视图能够记录所有运行过的业务 SQL,能够精确命中执行慢的 SQL 并且对这个 SQL 运行时很多指标都有记录。第二是 OB 有更强大的 SQL 引擎,有 SQL 执行计划缓存机制以及 OUTLINE 技术在线干预执行计划。这两个在前文《OB SQL 性能抖动问题分析和应对》里有详细阐述。
业务表的数据量最大的约 1800 w,几个业务大表数据量在百万级别,其他的就更小一些。业务迁移到 OB 后的 SQL 性能问题主要表现就是很多 SQL 执行很慢(超过 10s)。这些慢 SQL 特点如下:
有多表连接,大部分连接的表数在 5 个以上,少数几个是三表连接 查询条件组合很多,有范围查询、子查询 或 IN 查询 或者三者叠加。 IN 查询的列表数量不固定,短的几个,长的几十个。 有模糊查询,且还有左匹配的那种。 大量误用外连接( LEFT JOIN
)。
SQL 很慢的原因不完全一致,很难总结出一个适用所有的解释来。但观察大部分慢 SQL 的执行计划发现有很多层的嵌套循环连接算子(NESTED-LOOP JOIN
)。下面是一个慢 SQL 的解析执行计划示例。
========================================================================================================
|ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)|
--------------------------------------------------------------------------------------------------------
|0 |SORT | |3 |10537 |
|1 |└─NESTED-LOOP OUTER JOIN | |3 |10535 |
|2 | ├─NESTED-LOOP OUTER JOIN | |2 |10509 |
|3 | │ ├─NESTED-LOOP JOIN | |1 |10491 |
|4 | │ │ ├─NESTED-LOOP JOIN | |1 |10473 |
|5 | │ │ │ ├─NESTED-LOOP JOIN | |1 |10445 |
|6 | │ │ │ │ ├─NESTED-LOOP JOIN | |1 |10427 |
|7 | │ │ │ │ │ ├─TABLE RANGE SCAN |pp(prj_project_ind1) |6 |114 |
|8 | │ │ │ │ │ └─DISTRIBUTED TABLE RANGE SCAN|tsrd(idx_s_project_code) |1 |2046 |
|9 | │ │ │ │ └─DISTRIBUTED TABLE GET |tsr |1 |18 |
|10| │ │ │ └─DISTRIBUTED TABLE RANGE SCAN |esrc(esc_stock_receipt_count_ind6)|1 |27 |
|11| │ │ └─DISTRIBUTED TABLE GET |ba |1 |18 |
|12| │ └─DISTRIBUTED TABLE RANGE SCAN |aav2(bda_artno_attr_value_ind1) |2 |18 |
|13| └─DISTRIBUTED TABLE RANGE SCAN |aav1(bda_artno_attr_value_ind1) |2 |18 |
========================================================================================================复制
从执行计划上看记录数不多,应该跑的很快,实际上执行时间却要十几秒以上。难道是物理执行计划跟解析执行计划不一致?通过 SQL 审计视图找到 SQL 的 plan_id
和trace_id
,进而找到可以找到物理执行计划。或者在 ODC 里运行一次这个业务 SQL,也可以很方便的查看物理执行计划。
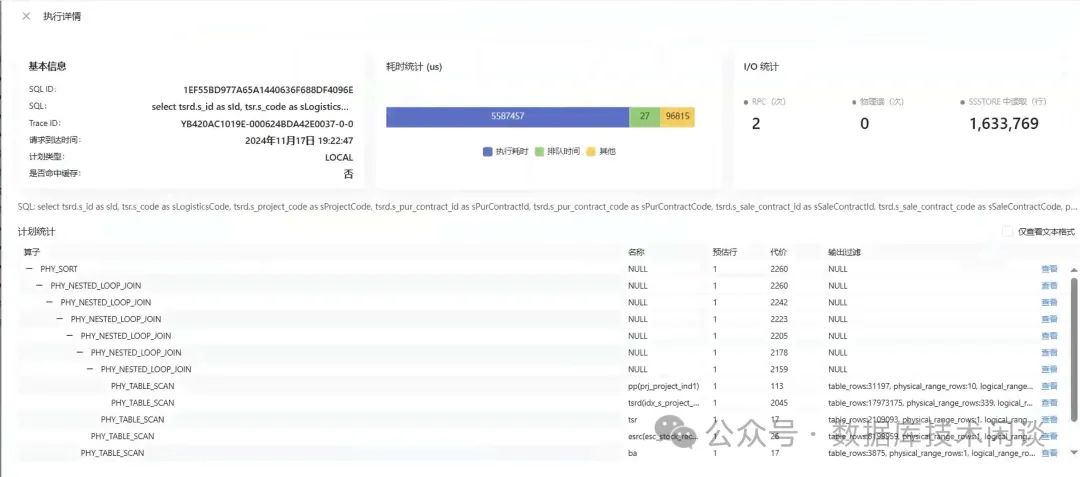
从上图看物理执行计划跟解析执行计划是一样的,算子的估行也基本一致。同时上面还显示 SQL 的执行耗时约 5.5s 左右以及trace_id
信息(后面分析用)。
有类似执行计划的慢 SQL 很多,虽然不能都给出慢的解释,但却找到了一个能大幅提升大部分 SQL 的性能的办法,就是用 outline
给 SQL 绑定一个并行执行的计划 /*+ parallel(4) */
。很多十几秒的 SQL 性能也能下降到一秒内。不过也有一些只是下降到 5 秒以内。SQL 示例如下:
create outline otl_E54A1BDAC7C1B7669D0E0B19C3EF28FF on 'E54A1BDAC7C1B7669D0E0B19C3EF28FF' using hint /*+ use_hash(t1 t2 t3 t4) parallel(4) */;
create outline otl_CBA31F1348B99471372AF51AB26081BA on 'CBA31F1348B99471372AF51AB26081BA' using hint /*+ use_hash(t5 t6) parallel(4) */;
create outline otl_1B91BC1E5952072F8BE51C762C8483D8 on '1B91BC1E5952072F8BE51C762C8483D8' using hint /*+ parallel(8) */;复制
并行能让 SQL 引擎重新评估某些执行计划路径的成本,从而不走嵌套循环连接而改用了 HASH 连接,而对应的表使用了全表扫描(对表或者其索引),而这个叠加 HINT ,就大大缩短了 SQL 执行时间。但是并行也会执行计划更复杂,有很多多对多的数据交换(算子 EXCHANGE OUT DISTR
和 EXCHANGE IN DISTR
),所以也出现个别 SQL 用了并行反而会更慢的情形。
从上面分析看出 HASH 连接也是提升性能的一个关键,有些 SQL 走嵌套循环连接很慢,用 HINT *+ use_hash(t1 t2) */
改成 HASH 连接后就会变快了,此时再叠加并行,还能进一步变快。
上面的优化方法说不上高明,但确实很实用。业务 SQL 里普遍存在一些不规范的写法,对 SQL 引擎并不友好。但是业务新换数据库,并不能立即修改 SQL ,所以解决性能问题的重担最终还是落到 DBA 身上。为了这个业务,DBA 创建了 100+ 条 outline
。这是一种数据库 SQL 优化的“补丁”技术。不好看,但实用。之所以会有这么多的 outline
,其原因是业务场景动态查询组合很多,此外就是 in list
条件。这个 list
长短不一,导致 SQL 的 sql_id
不一致,所以需要为每个 sql_id
创建 outline
。
到此应用性能问题基本解决,业务整体感受要比原来跑在 RDS MySQL
上要好很多。还要补充的一点是尽管很多 SQL
用了并行,但是租户的 CPU
平均利用率 25%
左右,这个是很低的水平了。
上面举例的那个执行计划里全是嵌套循环连接,实际上是有问题的。其原因是算子估算错误。下面就再尝试简单的探索一下 SQL 执行计划中算子估行特点分析。
执行计划分析
算子估行验证
要验证执行计划里算子估行是否正确,有两个方法。
方法一:根据 SQL 运行时的 trace_id
去反查视图 gV$SQL_PLAN_MONITOR
,查出执行计划每一步算子实际的返回行数。
select trace_id, svr_ip, plan_line_id, plan_depth, plan_operation, db_time, first_refresh_time, last_refresh_time, output_rows
from oceanbase.gV$SQL_PLAN_MONITOR where trace_id='YB420AC1019E-000624BDA42E0037-0-0'
order by plan_line_id;复制
输出结果如下:
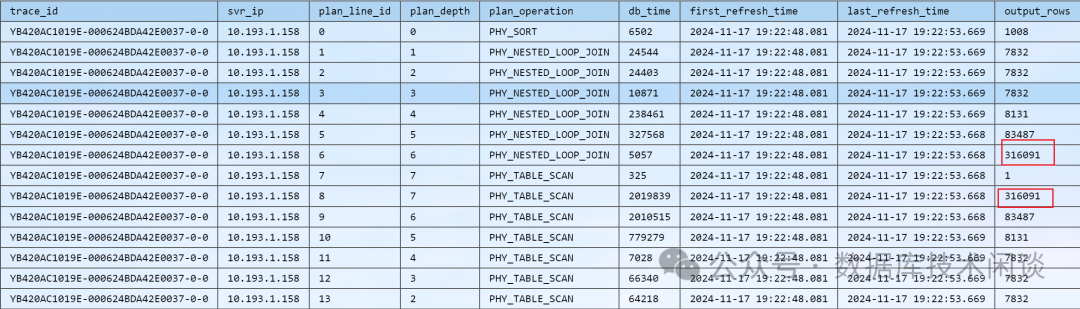
这个输出结果跟物理执行计划对照着看,第8
行算子的实际输出结果是316091
,而解析执行计划和物理执行计划实际输出是1
。一步错,步步错。SQL 引擎后续对连接算法的选择就都错选了NESTED-LOOP JOIN
,导致整体耗时非常高。
方法二:拆解 SQL 针对相应表带上相应的过滤条件做 count(*)
统计。这个方法有点复杂,后面分析为什么算子估算错误会用到这个方法。
统计信息
算子估行信息跟统计信息也密切相关。
首先是确认相关表是否有收集统计信息。
select table_name, partition_name,num_rows, blocks,avg_row_len,sample_size,last_analyzed
from OCEANBASE.DBA_TAB_STATISTICS
where owner ='tpccdb' and table_name = 'bmsql_oorder'
;
select table_name, column_name, num_distinct ,low_value,high_value,density,num_nulls, num_buckets,last_analyzed,sample_size,histogram
from OCEANBASE.DBA_TAB_COL_STATISTICS
where owner = 'tpccdb' and table_name = 'bmsql_oorder'
;
select table_name, column_name, endpoint_number, endpoint_value, endpoint_actual_value,endpoint_actual_value_raw,endpoint_repeat_count
from oceanbase.DBA_TAB_HISTOGRAMS
where owner = 'tpccdb' and table_name = 'bmsql_oorder'
;复制
如果没有手动收集过统计信息,刚初始化数据的时候上面返回结果里的一些字段和记录应该是空的。不过只要经过一天,OB 会自动收集库表统计信息。下面 SQL 显示 OB 统计信息自动收集设置。
select owner, job_name, program_owner, job_type, job_action, repeat_interval, end_date, enabled, state, last_start_date, last_run_duration, next_run_date, max_run_duration, comments
from OCEANBASE.DBA_SCHEDULER_JOBS
order by last_start_date desc ;
select owner, window_name, repeat_interval, end_date, duration, next_run_date, last_start_date, enabled, comments
from OCEANBASE.DBA_SCHEDULER_WINDOWS
order by last_start_date desc ;复制
| job_name | job_action | repeat_interval | end_date | enabled | state | last_start_date | last_run_duration | next_run_date | max_run_duration | comments |
|---|---|---|---|---|---|---|---|---|---|---|
| WEDNESDAY_WINDOW | DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC(14400000000) | FREQ=WEEKLY; INTERVAL=1 | 4000-01-01 00:00:00.000 | 1 | SCHEDULED | 2024-11-20 22:00:00.012 | 2024-11-27 22:00:00.000 | 14400 | used to auto gather table stats | |
| FRIDAY_WINDOW | DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC(14400000000) | FREQ=WEEKLY; INTERVAL=1 | 4000-01-01 00:00:00.000 | 1 | 2024-11-22 22:00:00.000 | 14400 | used to auto gather table stats | |||
| MONDAY_WINDOW | DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC(14400000000) | FREQ=WEEKLY; INTERVAL=1 | 4000-01-01 00:00:00.000 | 1 | 2024-11-25 22:00:00.000 | 14400 | used to auto gather table stats | |||
| OPT_STATS_HISTORY_MANAGER | DBMS_STATS.PURGE_STATS(NULL) | FREQ=DAYLY; INTERVAL=1 | 4000-01-01 00:00:00.000 | 1 | 2024-11-21 18:05:20.888 | 43200 | used to stats history manager | |||
| SATURDAY_WINDOW | DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC(72000000000) | FREQ=WEEKLY; INTERVAL=1 | 4000-01-01 00:00:00.000 | 1 | 2024-11-23 06:00:00.000 | 72000 | used to auto gather table stats | |||
| SUNDAY_WINDOW | DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC(72000000000) | FREQ=WEEKLY; INTERVAL=1 | 4000-01-01 00:00:00.000 | 1 | 2024-11-24 06:00:00.000 | 72000 | used to auto gather table stats | |||
| THURSDAY_WINDOW | DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC(14400000000) | FREQ=WEEKLY; INTERVAL=1 | 4000-01-01 00:00:00.000 | 1 | 2024-11-21 22:00:00.000 | 14400 | used to auto gather table stats | |||
| TUESDAY_WINDOW | DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC(14400000000) | FREQ=WEEKLY; INTERVAL=1 | 4000-01-01 00:00:00.000 | 1 | 2024-11-26 22:00:00.000 | 14400 | used to auto gather table stats |
OB 默认每天都会收集一次全库的统计信息。
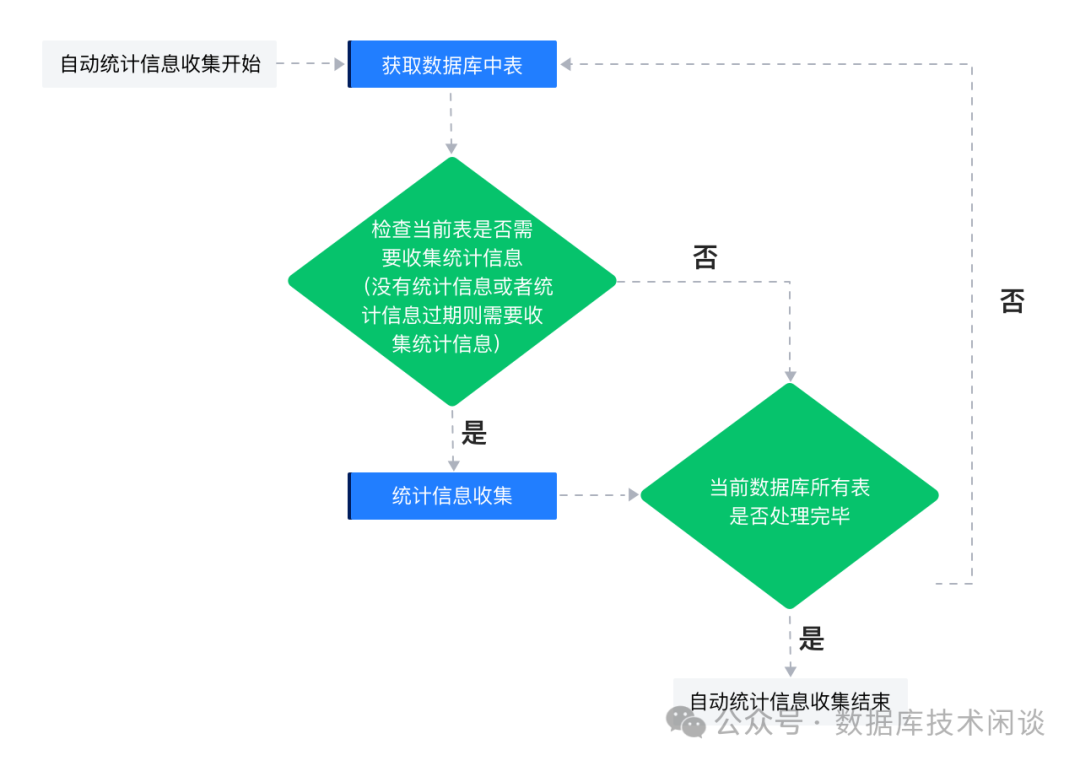
针对上述自动统计信息收集中,判断一个表的统计信息是否过期,主要依据上一次统计信息收集时间到本次收集期间该表的做增/删/改的比例,默认值是 10%;需要注意的是这个变化比例是分区级别的,比如一个分区表的某些分区的增/删/改的比例超过了 10%,那么也会重新收集这些分区的统计信息,当然默认的变化比例是可以配置的,业务可以根据实际情况通过设置 perfs
进行调整。
看到这里就要查看一下统计信息自动收集的一些默认设置。
select dbms_stats.GET_PREFS('APPROXIMATE_NDV') 'APPROXIMATE_NDV'
, dbms_stats.GET_PREFS('CASCADE') 'CASCADE'
, dbms_stats.GET_PREFS('DEGREE') 'DEGREE'
, dbms_stats.GET_PREFS('ESTIMATE_PERCENT') 'ESTIMATE_PERCENT'
, dbms_stats.GET_PREFS('GRANULARITY') 'GRANULARITY'
, dbms_stats.GET_PREFS('INCREMENTAL') 'INCREMENTAL'
, dbms_stats.GET_PREFS('INCREMENTAL_LEVEL') 'INCREMENTAL_LEVEL'
, dbms_stats.GET_PREFS('METHOD_OPT') 'METHOD_OPT'
, dbms_stats.GET_PREFS('STALE_PERCENT') 'STALE_PERCENT'
, dbms_stats.GET_PREFS('NO_INVALIDATE') 'NO_INVALIDATE '
from dual;复制
| APPROXIMATE_NDV | CASCADE | DEGREE | ESTIMATE_PERCENT | GRANULARITY | INCREMENTAL | INCREMENTAL_LEVEL | METHOD_OPT | STALE_PERCENT | NO_INVALIDATE |
|---|---|---|---|---|---|---|---|---|---|
| TRUE | DBMS_STATS.AUTO_CASCADE | DBMS_STATS.AUTO_SAMPLE_SIZE | AUTO | FALSE | PARTITION | FOR ALL COLUMNS SIZE AUTO | 10 | DBMS_STATS.AUTO_INVALIDATE |
所以收集表的统计信息时,如果不指定选项,那默认就收集所有列的统计信息FOR ALL COLUMNS SIZE AUTO
。
统计信息对算子估行的影响
为了观察统计信息对算子估行的影响,这里使用 TPCC 的表 bmsql_oorder
为例进行研究。
首先是没有收集任何统计信息的情况。
顺便提一下, OB 还有个统计信息动态采样的设置,在前文《OB 4.2 SQL 性能抖动诊断案例分享》里我提到过这个影响性能,所以这次我就关闭了这个统计信息动态采样功能。因此可以排除动态采样对这里算子估行分析的影响。
set global optimizer_dynamic_sampling = 0;复制
重新登录会话。
select count(*) from tpccdb.bmsql_oorder ;复制
300000记录,就算表有几百万几千万,这个查询也能快速返回。这是因为 OB 在数据转储生成
sstable的时候就已经在每个宏块里记录当前宏块内的数据记录数,这个信息也是 OB 存储层估行技术,估算的准确度非常高。
紧接着给 SQL 增加一个时间列的范围查询。
mysql> select count(*),min(o_entry_d), max(o_entry_d) from tpccdb.bmsql_oorder where o_entry_d between '2024-11-22 00:00:12.000' and '2024-11-22 14:43:12.000';
+----------+---------------------+---------------------+
| count(*) | min(o_entry_d) | max(o_entry_d) |
+----------+---------------------+---------------------+
| 217988 | 2024-11-22 07:25:27 | 2024-11-22 14:25:27 |
+----------+---------------------+---------------------+
1 row in set (0.52 sec)复制
显然这个范围包含了表的绝大部分记录数。然后查看下面 SQL 的执行计划看看 OB 的估行。
mysql> explain extended_noaddr select * from tpccdb.bmsql_oorder where o_entry_d between '2024-11-22 00:00:12.000' and '2024-11-22 14:43:12.000';
=======================================================
|ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)|
-------------------------------------------------------
|0 |TABLE FULL SCAN|bmsql_oorder|15000 |13872 |
=======================================================
Outputs & filters:
-------------------------------------
0 - output([bmsql_oorder.o_w_id], [bmsql_oorder.o_d_id], [bmsql_oorder.o_id], [bmsql_oorder.o_c_id], [bmsql_oorder.o_carrier_id], [bmsql_oorder.o_cnt],
[bmsql_oorder.o_all_local], [bmsql_oorder.o_ol_cnt], [bmsql_oorder.o_entry_d]), filter([bmsql_oorder.o_entry_d >= cast('2024-11-22 00:00:12.000', TIMESTAMP(-1,
-1))], [bmsql_oorder.o_entry_d <= cast('2024-11-22 14:43:12.000', TIMESTAMP(-1, -1))]), rowset=256
access([bmsql_oorder.o_entry_d], [bmsql_oorder.o_w_id], [bmsql_oorder.o_d_id], [bmsql_oorder.o_id], [bmsql_oorder.o_c_id], [bmsql_oorder.o_carrier_id],
[bmsql_oorder.o_cnt], [bmsql_oorder.o_all_local], [bmsql_oorder.o_ol_cnt]), partitions(p0)
is_index_back=false, is_global_index=false, filter_before_indexback[false,false],
range_key([bmsql_oorder.__pk_increment]), range(MIN ; MAX)always true
Optimization Info:
-------------------------------------
bmsql_oorder:
table_rows:300000
physical_range_rows:300000
logical_range_rows:300000
index_back_rows:0
output_rows:15000
table_dop:1
dop_method:Table DOP
avaiable_index_name:[bmsql_oorder]
stats version:0
dynamic sampling level:0
Plan Type:
LOCAL
Note:
Degree of Parallelisim is 1 because of table property |复制
在没有统计信息的情况下,优化起对这个范围查询估行返回是表记录数的5%
。显然这个误差就很大了。
接下来收集表的统计信息。
analyze table tpccdb.bmsql_oorder compute statistics;复制
查看表的统计信息如下(删除无关的部分)。
mysql> select table_name, partition_name,num_rows, blocks,avg_row_len,sample_size,last_analyzed
-> from OCEANBASE.DBA_TAB_STATISTICS
-> where owner ='tpccdb' and table_name = 'bmsql_oorder'
-> ;
+--------------+----------------+----------+--------+-------------+-------------+----------------------------+
| table_name | partition_name | num_rows | blocks | avg_row_len | sample_size | last_analyzed |
+--------------+----------------+----------+--------+-------------+-------------+----------------------------+
| bmsql_oorder | NULL | 300000 | NULL | 178 | NULL | 2024-11-22 22:33:20.048110 |
+--------------+----------------+----------+--------+-------------+-------------+----------------------------+
1 row in set (0.04 sec)
mysql> select table_name, column_name, num_distinct ,low_value,high_value,density,num_nulls, num_buckets,last_analyzed,sample_size,histogram
-> from OCEANBASE.DBA_TAB_COL_STATISTICS
-> where owner = 'tpccdb' and table_name = 'bmsql_oorder'
-> ;
+--------------+--------------+--------------+-----------------------+-----------------------+---------+-----------+-------------+----------------------------+-------------+-----------+
| table_name | column_name | num_distinct | low_value | high_value | density | num_nulls | num_buckets | last_analyzed | sample_size | histogram |
+--------------+--------------+--------------+-----------------------+-----------------------+---------+-----------+-------------+----------------------------+-------------+-----------+
| bmsql_oorder | o_w_id | 10 | 1 | 10 | 0 | 0 | 0 | 2024-11-22 22:33:20.048110 | 300000 | NULL |
| bmsql_oorder | o_d_id | 10 | 1 | 10 | 0 | 0 | 0 | 2024-11-22 22:33:20.048110 | 300000 | NULL |
| bmsql_oorder | o_id | 3062 | 1 | 3000 | 0 | 0 | 0 | 2024-11-22 22:33:20.048110 | 300000 | NULL |
| bmsql_oorder | o_c_id | 3062 | 1 | 3000 | 0 | 0 | 0 | 2024-11-22 22:33:20.048110 | 300000 | NULL |
| bmsql_oorder | o_carrier_id | 10 | 1 | 10 | 0 | 90000 | 0 | 2024-11-22 22:33:20.048110 | 210000 | NULL |
| bmsql_oorder | o_cnt | 11 | 5 | 15 | 0 | 0 | 0 | 2024-11-22 22:33:20.048110 | 300000 | NULL |
| bmsql_oorder | o_all_local | 1 | 1 | 1 | 0 | 0 | 0 | 2024-11-22 22:33:20.048110 | 300000 | NULL |
| bmsql_oorder | o_ol_cnt | 11 | 5 | 15 | 0 | 0 | 0 | 2024-11-22 22:33:20.048110 | 300000 | NULL |
| bmsql_oorder | o_entry_d | 11 | '2024-11-22 07:25:27' | '2024-11-22 17:25:27' | 0 | 0 | 11 | 2024-11-22 22:33:20.048110 | 300000 | FREQUENCY |
+--------------+--------------+--------------+-----------------------+-----------------------+---------+-----------+-------------+----------------------------+-------------+-----------+
9 rows in set (0.04 sec)
mysql> select table_name, column_name, endpoint_number, endpoint_value, endpoint_actual_value,endpoint_actual_value_raw,endpoint_repeat_count
-> from oceanbase.DBA_TAB_HISTOGRAMS
-> where owner = 'tpccdb' and table_name = 'bmsql_oorder'
-> ;
+--------------+-------------+-----------------+----------------+-----------------------+---------------------------+-----------------------+
| table_name | column_name | endpoint_number | endpoint_value | endpoint_actual_value | endpoint_actual_value_raw | endpoint_repeat_count |
+--------------+-------------+-----------------+----------------+-----------------------+---------------------------+-----------------------+
| bmsql_oorder | o_entry_d | 27061 | NULL | '2024-11-22 07:25:27' | 12053F00C0CFD7A6C9EE8903 | 27061 |
| bmsql_oorder | o_entry_d | 54001 | NULL | '2024-11-22 08:25:27' | 12053F00C097A6DBD6EE8903 | 26940 |
| bmsql_oorder | o_entry_d | 80928 | NULL | '2024-11-22 09:25:27' | 12053F00C0DFF48FE4EE8903 | 26927 |
| bmsql_oorder | o_entry_d | 108140 | NULL | '2024-11-22 10:25:27' | 12053F00C0A7C3C4F1EE8903 | 27212 |
| bmsql_oorder | o_entry_d | 135825 | NULL | '2024-11-22 11:25:27' | 12053F00C0EF91F9FEEE8903 | 27685 |
| bmsql_oorder | o_entry_d | 163250 | NULL | '2024-11-22 12:25:27' | 12053F00C0B7E0AD8CEF8903 | 27425 |
| bmsql_oorder | o_entry_d | 190571 | NULL | '2024-11-22 13:25:27' | 12053F00C0FFAEE299EF8903 | 27321 |
| bmsql_oorder | o_entry_d | 217988 | NULL | '2024-11-22 14:25:27' | 12053F00C0C7FD96A7EF8903 | 27417 |
| bmsql_oorder | o_entry_d | 245385 | NULL | '2024-11-22 15:25:27' | 12053F00C08FCCCBB4EF8903 | 27397 |
| bmsql_oorder | o_entry_d | 272647 | NULL | '2024-11-22 16:25:27' | 12053F00C0D79A80C2EF8903 | 27262 |
| bmsql_oorder | o_entry_d | 300000 | NULL | '2024-11-22 17:25:27' | 12053F00C09FE9B4CFEF8903 | 27353 |
+--------------+-------------+-----------------+----------------+-----------------------+---------------------------+-----------------------+
11 rows in set (0.03 sec)复制
此时再查看上面范围查询的执行计划信息如下。
explain extended_noaddr select * from tpccdb.bmsql_oorder where o_entry_d between '2024-11-22 00:00:12.000' and '2024-11-22 14:43:12.000';
=======================================================
|ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)|
-------------------------------------------------------
|0 |TABLE FULL SCAN|bmsql_oorder|217988 |54820 |
=======================================================
Optimization Info:
-------------------------------------
bmsql_oorder:
table_rows:300000
physical_range_rows:300000
logical_range_rows:300000
index_back_rows:0
output_rows:217987
table_dop:1
dop_method:Table DOP
avaiable_index_name:[bmsql_oorder]
stats version:1732286000048110
dynamic sampling level:0复制
这个时候估行记录数就跟真实记录数非常接近。
此时如果输入一个范围不存在的记录,执行计划估行最小返回为1
。
mysql> select count(*),min(o_entry_d), max(o_entry_d) from tpccdb.bmsql_oorder where o_entry_d between '2024-11-22 00:00:12.000' and '2024-11-22 00:43:12.000';
+----------+----------------+----------------+
| count(*) | min(o_entry_d) | max(o_entry_d) |
+----------+----------------+----------------+
| 0 | NULL | NULL |
+----------+----------------+----------------+
1 row in set (0.01 sec)
mysql> explain select * from tpccdb.bmsql_oorder where o_entry_d between '2024-11-22 00:00:12.000' and '2024-11-22 00:43:12.000';
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ======================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------- |
| |0 |TABLE FULL SCAN|bmsql_oorder|1 |10970 | |
| ======================================================= |复制
以上是列上没有索引时的SQL执行计划估行非常精准。如果有索引,那情形会复杂一些,这里就不展开了。
回到前面业务 SQL ,虽然表有时间列的范围查询,有其他状态列条件。在有统计信息的前提下,估行不应该差别这么大。应该还是有别的原因。
主键列条件估行
这个时候再回头看看业务 SQL,在 WHERE
条件里有一个非常特别:and tsrd.s_id = tsrd.s_idx
。表 tsrd
的主键就是s_id
,业务上的逻辑有些记录特点是s_id=s_idx
。推测是优化器按普通的主键等值条件去估行,所以估行返回数量是1
。
这一点也很容易验证一下。不过要对上面表 bmsql_oorder
结构要改造一下,将主键设置为单列主键。
mysql> create table t_order as select * from tpccdb.bmsql_oorder;
Query OK, 300000 rows affected (3.94 sec)
mysql> alter table t_order add column id bigint not null auto_increment;
Query OK, 0 rows affected (2.56 sec)
mysql> alter table t_order add primary key (id);
Query OK, 0 rows affected (1.91 sec)
mysql> analyze table t_order compute statistics;
Query OK, 0 rows affected (0.37 sec)复制
然后模拟业务 SQL 看执行计划。
mysql> select count(*) from tpccdb.t_order where o_id=o_id ;
+----------+
| count(*) |
+----------+
| 300000 |
+----------+
1 row in set (0.01 sec)
mysql> explain extended_noaddr select * from tpccdb.t_order where id=o_id ;
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------- |
| |0 |TABLE FULL SCAN|t_order|1 |21571 | |
| ================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t_order.o_w_id], [t_order.o_d_id], [t_order.o_id], [t_order.o_c_id], [t_order.o_carrier_id], [t_order.o_cnt], [t_order.o_all_local], [t_order.o_ol_cnt], |
| [t_order.o_entry_d], [t_order.id]), filter([t_order.id = t_order.o_id]), rowset=16 |
| access([t_order.id], [t_order.o_id], [t_order.o_w_id], [t_order.o_d_id], [t_order.o_c_id], [t_order.o_carrier_id], [t_order.o_cnt], [t_order.o_all_local], |
| [t_order.o_ol_cnt], [t_order.o_entry_d]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t_order.id]), range(MIN ; MAX)always true |
| Optimization Info: |
| ------------------------------------- |
| t_order: |
| table_rows:300000 |
| physical_range_rows:300000 |
| logical_range_rows:300000 |
| index_back_rows:0 |
| output_rows:1 |
| table_dop:1 |
| dop_method:Table DOP |
| avaiable_index_name:[t_order] |
| stats version:1732287042626877 |
| dynamic sampling level:0 |
| Plan Type: |
| LOCAL |
| Note: |
| Degree of Parallelisim is 1 because of table property |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
47 rows in set (0.01 sec)复制
估算行数是1
,实际返回行数是300000
。误差非常大。
这个是 OB 4.2.1.8
版本已知问题,估计前面的版本也有,这个问题在 4.2.5
后续版本会修复,在4.3.3
版本里也已经修复了。
(root@10.0.0.65:2881) [tpccdb]> status;
--------------
obclient Ver Distrib 10.4.18-MariaDB, for Linux (x86_64) using readline 5.1
Connection id: 3221633037
Current database: tpccdb
Current user: root@10.0.0.65
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server version: OceanBase 4.3.3.0 (r100000412024101200-0701a8319ff6499651ba0f95520709081c751b20) (Built Oct 12 2024 01:29:48)
Protocol version: 10
Connection: 10.0.0.65 via TCP/IP
Server characterset: utf8mb4
Db characterset: utf8mb4
Client characterset: latin1
Conn. characterset: latin1
TCP port: 2881
Protocol: Compressed
Active --------------
(root@10.0.0.65:2881) [tpccdb]> select count(*) from t_order where id=o_id;
+----------+
| count(*) |
+----------+
| 3000 |
+----------+
1 row in set (0.010 sec)
explain extended_noaddr select * from t_order where id=o_id;
Query Plan |
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
================================================== |
|ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
-------------------------------------------------- |
|0 |TABLE FULL SCAN|t_order|3062 |19620 | |
================================================== |
Outputs & filters: |
------------------------------------- |
0 - output([t_order.o_w_id], [t_order.o_d_id], [t_order.o_id], [t_order.o_c_id], [t_order.o_carrier_id], [t_order.o_ol_cnt], [t_order.o_all_local], [t_order.o_entry_d],|
[t_order.id]), filter([t_order.id = t_order.o_id]), rowset=256 |
access([t_order.id], [t_order.o_id], [t_order.o_w_id], [t_order.o_d_id], [t_order.o_c_id], [t_order.o_carrier_id], [t_order.o_ol_cnt], [t_order.o_all_local], |
[t_order.o_entry_d]), partitions(p0) |
is_index_back=false, is_global_index=false, filter_before_indexback[false], |
range_key([t_order.id]), range(MIN ; MAX)always true |
Optimization Info: |
------------------------------------- |
t_order: |
table_rows:300000 |
physical_range_rows:300000 |
logical_range_rows:300000 |
index_back_rows:0 |
output_rows:3062 |
table_dop:1 |
dop_method:Table DOP |
avaiable_index_name:[t_order] |
stats info:[version=1731998963910209, is_locked=0, is_expired=0] |
dynamic sampling level:0 |
estimation method:[OPTIMIZER STATISTICS, STORAGE] |
Plan Type: |
LOCAL |
Note: |
Degree of Parallelisim is 1 because of table property复制
估行返回数量跟实际数量接近,可见该问题已经修复。
总结
OB SQL 引擎的能力在不断的完善。不同客户的业务不同时间迁移到不同的 OB 版本上,都可能重复遇到各种类似问题,问题的修复可能要等待以后的版本,好在 OB SQL 引擎还支持 outline
技术在线干预执行计划。所以本文案例碰到一些算子估行不准导致多表连接算法不是最优问题,即使业务切换到 OB 后出现性能问题,这次也做到了快速应对修复。
更多阅读
最后发一个个人想法:想探索组建一个 OB 运维交流群,成员间能分享讨论各自的 OB 使用问题和经验,共同进步。群采取邀约制。欢迎使用过 OB 且有相同想法的朋友通过公众号留言回复:加好友
。



