




Table of Contents
前言
在 SQL 查询中,如果我们需要进行模糊搜索某一列中的内容,通常都会优先考虑使用 like 关键字进行模糊查询,如果表字段的数据量不大,使用该方法影响不大,可以满足需求,但是在查询过程中如果使用了 %搜索内容% 来查询,该字段上的索引会失效,因此在数据量大的表里查询,性能会比较差;还有如果需要查询在不同位置同时出现多次不同的搜索内容,则需要用 OR 连接多个查询条件。最近看到 PostgreSQL 能实现全文检索功能,基于文本搜索配置,它通过词典、停止词等方式来处理文本,能对文本数据进行高效的搜索且是使用内置的功能来实现全文检索,使用起来也方便。
测试数据
创建测试表,并加入测试数据,如下所示:
CREATE TABLE public.test_full_text (
id serial4 NOT NULL,
c_name varchar NULL,
detail text NULL
);
复制
PostgreSQL 内置的全文检索
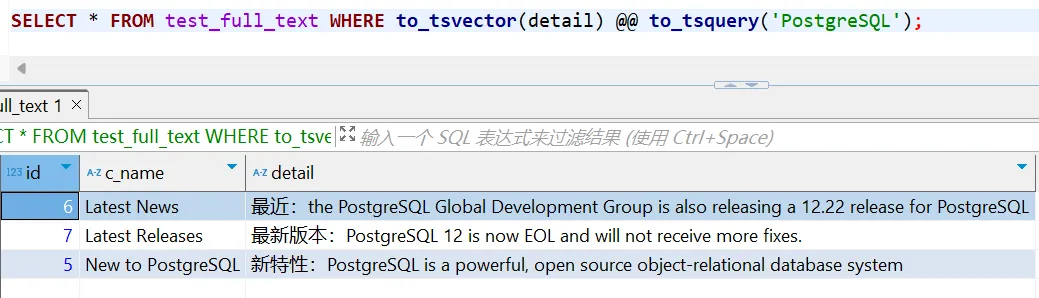
PostgreSQL 内置的全文检索主要使用的是 to_tsvector 与 to_tsquery 函数,两个函数之间通过 @@ 符号连接,以下将介绍这两个函数使用。
创建索引
创建索引:通过 GIN 或 GiST 索引来加速全文检索。
GIN 索引:一种高效的全文索引类型,适用于大多数全文检索操作。
GiST 索引是一种更为灵活的索引类型,适用于较为复杂的查询。
-- 使用 GIN 索引
CREATE INDEX idx_test_full_text_detail ON test_full_text USING GIN (to_tsvector('english', detail));
复制to_tsvector
to_tsvector(language, text) :将文本内容转换成一个格式化的词项列表,这些词项可以用来进行全文搜索,输入的字符串进行向量化之后,便于高效检索。其中 language 有以下选项:
- ’english’:用于英文文本的分析,包括去除英文停用词、词形还原等。
- ’simple’:简单的配置,不做词形还原和停用词过滤。
注:默认是不支持中文。
to_tsquery
to_tsquery (language, text) :用于将文本查询字符串转换为 tsquery 类型的函数。
- text:这是要转换为查询的文本字符串。可以包含搜索的关键词、逻辑操作符(如
&、|和!)以及词组。
pg_trgm
pg_trgm 为 PostgreSQL 内置插件。主要用于模糊搜索和相似度匹配,它基于 trigram(字符三元组)实现,常用于处理 模糊搜索,比如拼写错误、近似匹配等场景。
相似度匹配:利用 similarity 函数可以计算两个字符串的相似度。
postgres=# CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE EXTENSION
postgres=# SELECT similarity('hello', 'helo') AS sim_score;
sim_score
-----------
0.5714286
(1 row)
复制在查询时候,可以用全文检索来匹配包含特定词汇的记录,再用 pg_trgm 来补充模糊匹配,注意:% 操作符要求字段列的数据类型是 文本类型(如 TEXT 或 VARCHAR)。
zhparser
在 PostgreSQL 中,如果需要支持中文的全文检索,则需要安装 zhparser 来实现。注:zhparser支持PostgreSQL 9.2及以上版本。本文使用的插件版本为:scws-1.2.3 、zhparser-2.2
相关插件下载:
安装 scws
- 下载 scws 简易中文分词系统源码包。
- 下载完成后,解压 scws,并使用 ./configure --prefix=/usr/local/scws 进行配置安装目录。
- 使用 make 与 make install 进行编译与安装。
[root@pc001 soft]# wget http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2
--2024-12-31 14:01:01-- http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2
正在解析主机 www.xunsearch.com (www.xunsearch.com)... 202.75.216.233
正在连接 www.xunsearch.com (www.xunsearch.com)|202.75.216.233|:80... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:485903 (475K) [text/plain]
正在保存至: “scws-1.2.3.tar.bz2”
scws-1.2.3.tar.bz2 100%[=================================================>] 474.51K 470KB/s 用时 1.0s
2024-12-31 14:01:04 (470 KB/s) - 已保存 “scws-1.2.3.tar.bz2” [485903/485903])
[root@pc001 soft]# tar xvjf scws-1.2.3.tar.bz2
[root@pc001 scws-1.2.3]# ./configure --prefix=/usr/local/scws
[root@pc001 scws-1.2.3]# make
[root@pc001 scws-1.2.3]# make install
/usr/local/scws 中了,执行下面命令看看文件是否存在
[root@pc001 scws-1.2.3]# ls -al /usr/local/scws/lib/libscws.la
-rwxr-xr-x. 1 root root 916 12月 31 14:09 /usr/local/scws/lib/libscws.la
[root@pc001 scws-1.2.3]# /usr/local/scws/bin/scws -h
scws (scws-cli/1.2.3)
Simple Chinese Word Segmentation - Command line usage.
Copyright (C)2007 by hightman.
复制安装完成后可使用 ls -al /usr/local/scws/lib/libscws.la 查看文件是否存在,如果安装成功此目录下会有文件,也可使用 /usr/local/scws/bin/scws -h 查看命令输出。
安装 zhparser
- 修改 zhparser-2.2.tar.gz 用户与用户组属性
- 解压 zhparser-2.2.tar.gz 文件
- 使用 make 与 make install 进行编译与安装插件
- 安装成功后可以登录 psql 进行创建 zhparser
[root@pc001 soft]# chown -R postgres:postgres zhparser-2.2.tar.gz
[postgres@pc001 soft]$ tar zxvf zhparser-2.2.tar.gz
[postgres@pc001 soft]$ cd zhparser-2.2/
[postgres@pc001 zhparser-2.2]$ make
[postgres@pc001 zhparser-2.2]$ make install
/usr/bin/mkdir -p '/usr/postgres/16.1/lib'
/usr/bin/mkdir -p '/usr/postgres/16.1/share/extension'
/usr/bin/mkdir -p '/usr/postgres/16.1/share/extension'
/usr/bin/mkdir -p '/usr/postgres/16.1/share/tsearch_data'
/usr/bin/install -c -m 755 zhparser.so '/usr/postgres/16.1/lib/zhparser.so'
/usr/bin/install -c -m 644 .//zhparser.control '/usr/postgres/16.1/share/extension/'
/usr/bin/install -c -m 644 .//zhparser--1.0.sql .//zhparser--unpackaged--1.0.sql .//zhparser--1.0--2.0.sql .//zhparser--2.0.sql .//zhparser--2.0--2.1.sql .//zhparser--2.1.sql .//zhparser--2.1--2.2.sql '/usr/postgres/16.1/share/extension/'
/usr/bin/install -c -m 644 .//dict.utf8.xdb .//rules.utf8.ini '/usr/postgres/16.1/share/tsearch_data/'
postgres=# CREATE EXTENSION zhparser;
CREATE EXTENSION
postgres=# CREATE TEXT SEARCH CONFIGURATION testzhcfg (PARSER = zhparser);
CREATE TEXT SEARCH CONFIGURATION
postgres=# ALTER TEXT SEARCH CONFIGURATION testzhcfg ADD MAPPING FOR n,v,a,i,e,l WITH simple;
ALTER TEXT SEARCH CONFIGURATION
复制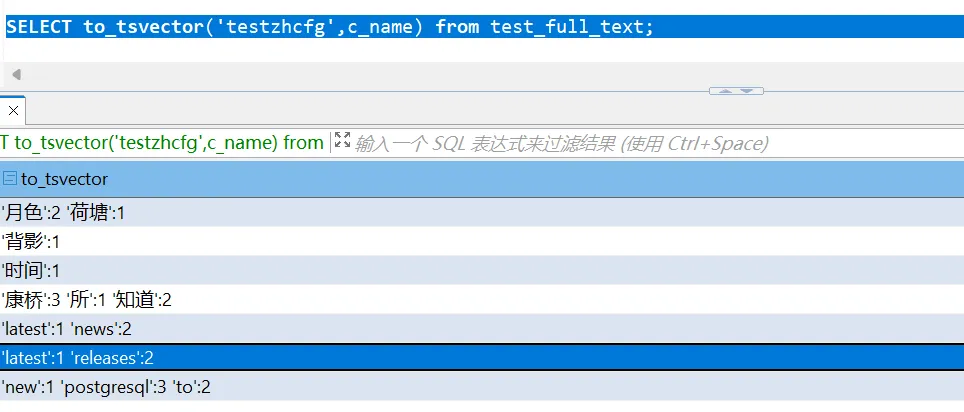
通过以上示例可以看出已经成功安装 zhparser 插件了,也能进行中文分词。
zhparser 与 Jieba 对比
| 特点 | zhparser | Jieba |
|---|---|---|
| 插件性质 | PostgreSQL C语言插件 | Python库,需通过 PL/Python 使用 |
| 分词模式 | 简单分词 | 精确、全模式、搜索引擎模式 |
| 自定义能力 | 较少 | 高,支持自定义词典和词频 |
| 性能 | 较高 | 相对较低 |
| 适用场景 | 简单、标准化文本分词,需高性能的检索场景(电商、知识库检索、新闻站点全文搜索,尤其是标准化文本较多的场景) | 复杂语境、高度定制化分词需求(社交平台、论坛分析、垂直领域文本(如医学、金融等)处理,以及需要动态加载自定义词库的情景) |
总结
在PostgreSQL 中,提供了很多丰富的文本检索功能与第三方插件,如全文检索、pg_trgm、zhparser 和 Jieba 都涉及文本处理和搜索的功能,但它们的用途和实现方式各有不同,我们可以针对适用场景选择更适合的方法或多种方式结合,使 PostgreSQL 的全文检索能力更加灵活和强大。




