




距离上一次写文章已经有好几个月了,在这个跨度时间经历了很多东西,最近一段时间都在忙于新项目的开发,熟悉相关业务,一直都没有写相关文章,废话不多说了,开始今天的正题,继续来熟悉我们的kafka
本文主要按照两个方面来写,第一介绍网络相关模型,第二说明下kafka的producer和cosumer是怎么管理TCP链接的
1.kafka网络模型
kafka具备高性能和高吞吐量的原因有一部分就在于其优秀的网络通信,它的底层主要是基于java nio的,下面我们整体来看下整个网络通信架构图,图片来自极客时间
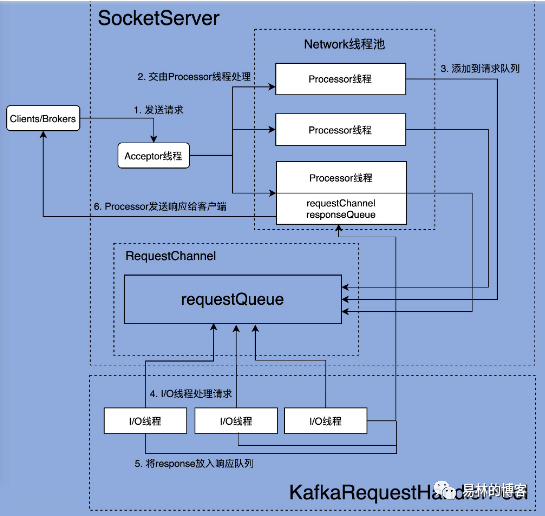
从上面的图我们大概可以知道整个网络架构是由SocketServer和KafkaRequestHandlerProcess两部分组成的
1.1.SocketServer
它实现了Reactor模式,用来处理多个client的并发请求(这个地方的client包括了producer,cosumer或者是其它Broker),并将结果封装入Response中,返回给client
1.2.KafkaRequestHandlerProcess
是用来真正处理请求的地方,里面定义了多个io线程
1.3.Acceptor线程
每个SocketServer线程只会创建一个Acceptor线程,Acceptor线程使用的是JAVA的 Selector+SocketChannel的方式不对的轮询准备好的io事件,这个地方主要就是指SelectionKey.OP_ACCEPT,一旦有对应的事件发生后,Acceptor就会指定一个Process线程,把请求转交给它,由它来创建真正的网络连接,其实Acceptor线程就是一个转发的功能
1.4.Process线程
每个SocketServer线程创建(num.network.thread)的Process线程,process线程负责将收到的Reques添加到RequestChannel的Request队列上,还负责将Response返回给Request方,它的内部有三个数据结构我们需要知道
1.4.1.newConnections
保持的是那些新连接信息,即由Acceptor在接收到ACCEPT请求后,该请求被发送到Proces线程暂存的地方,后面创建连接的时候即调用configureNewConnection时,从该队列取出SocketChannel,创建新的连接,它的大小是固定的20
1.4.2.inflightResponse
一个临时队列,当Processor线程将Response返回给Request发送方后,对于一些特殊的response需要将response返回给发送方后才能处理回调
1.4.3.responseQueue
Response队列,保存着需要返回给发送方的所有Response对象
1.5.全处理流程文字说明
Acceptor线程通过调用accept方法,创建对应的SocketChannel,然后该channle对象通过调用方法assignNewConnection方法
assignNewConnection方法将创建的SocketChannel对象放入Processor线程的newConnections队列中
Processor线程会不断的轮询这个队列中的数据,取出SocketChannel对象,注册到自己的Selector中(每个Processor线程都维护了自己的Selector)
连接建立好后,client发送请求数据
请求数据会被Processor线程的SocketChannel线程获取到,会调用processCompleteReceives,把我们的请求封装成Request对象,最终会借助于client.poll方法把请求发送到请求队列中
io线程处理请求,即KafkaRequestHandler线程(run方法)底层会轮询的从请求队列中获取请求Request,然后交给KafkaApis的handler方法,执行真正的逻辑处理
返回response,其实也是有KafkaApis执行的,当然也是由KafkaRequestHandler线程执行的,调用KafkaApis的sendReponse方法,将Request的处理结果Response发送出去,本质是通过调用RequestChannel的sendResponse
Processor线程将返回结果,从Response队列中取出,返回给对应的Request发送方
一些特殊请求的回调处理,即处理我们的inflightResponse队列,比如说Fetch请求在发送response后需要更新相关统计指标
2.TCP连接的管理
为什么Kafka的底层通讯协议是TCP和不是其它,比如说HTTP,这个问题通过上面的分析我们大概能有个答案
比如说基于TCP我们可以实现IO多路复用,社区还发现,目前已知的 HTTP 库在很多编程语言中都略显简陋,基于以上两个原因所以选择了TCP
2.1.Producer管理TCP
KafkaProducer 是线程安全的
2.1.1.何时创建TCP连接
1.创建KafkaProducer 实例时
在创建 KafkaProducer 实例时,生产者应用会在后台创建并启动一个名为 Sender 的线程,该 Sender 线程开始运行时首先会创建与 Broker 的连接
这个地方就会存在一个问题,此时我们都不知道是要给哪个主题发送消息,它是怎么知道要连接哪个的呢,其实它连接的是bootstrap.servers 参数指定的所有 Broker
bootstrap.servers 参指定了这个 Producer 启动时要连接的 Broker 地址。请注意,这里的“启动时”,代表的是 Producer 启动时会发起与这些 Broker 的连接。因此,如果你为这个参数指定了 1000 个 Broker 连接信息,那么很遗憾,你的 Producer 启动时会首先创建与这 1000 个 Broker 的 TCP 连接
在实际使用过程中,并不建议把集群中所有的 Broker 信息都配置到 bootstrap.servers 中,通常你指定 3~4 台就足以了。因为 Producer 一旦连接到集群中的任一台 Broker,就能拿到整个集群的 Broker 信息,故没必要为 bootstrap.servers 指定所有的 Broker
2.更新元数据后
Producer 更新了集群的元数据信息之后,如果发现与某些 Broker 当前没有连接
3.消息发送时
当要发送消息时,Producer 发现尚不存在与目标 Broker 的连接
2.1.2.何时关闭TCP连接
Producer 端关闭 TCP 连接的方式有两种:一种是用户主动关闭;一种是 Kafka 自动关闭
主动关闭:用户调用 kill -9 主动“杀掉”Producer 应用,或者调用 producer.close() 方法来关闭
自动关闭:Producer 端参数 connections.max.idle.ms 的值有关。默认情况下该参数值是 9 分钟,即如果在 9 分钟内没有任何请求“流过”某个 TCP 连接,那么 Kafka 会主动帮你把该 TCP 连接关闭。用户可以在 Producer 端设置 connections.max.idle.ms=-1 禁掉这种机制。一旦被设置成 -1,TCP 连接将成为永久长连接
在自动关闭中:TCP 连接是在 Broker 端被关闭的,但其实这个 TCP 连接的发起方是客户端,因此在 TCP 看来,这属于被动关闭的场景。被动关闭的后果就是会产生大量的 CLOSE_WAIT 连接
2.2.Consumer管理TCP
KafkaConsumer 是线程不安全的
2.2.1.何时创建TCP连接
TCP 连接是在调用 KafkaConsumer.poll 方法时被创建的
2.2.2.何时关闭TCP连接
消费者关闭 Socket 也分为主动关闭和 Kafka 自动关闭
主动关闭:手动调用 KafkaConsumer.close() 方法,或者是执行 Kill 命令
自动关闭:消费者端参数 connection.max.idle.ms控制的,该参数现在的默认值是 9 分钟,即如果某个 Socket 连接上连续 9 分钟都没有任何请求“过境”的话,那么消费者会强行“杀掉”这个 Socket 连接
当然在生产环境我们一般都会以一个循环的方式不断的调用poll方法拉取消息,那么上面提到的所有请求都会被定期发送到 Broker,因此这些 Socket 连接上总是能保证有请求在发送,从而也就实现了“长连接”的效果
3.总结
本文介绍了Kafka的网络通信模型和Producer,Consumer的TCP连接管理,这块的内容远远不止说的这么简单,具体的详细地方需要大家自己去摸索,最后谢谢大家
