




本篇文章是相对于之前来说算是一个比较松散的文章,主要是介绍kafka关于的一些小的特性,包括以下几个方面:其中重平衡下篇文章介绍
kafka精确一次投递
kafka消费者组相关概念
kafka的位移主题
kafka位移提交
kafka提交位移异常
消费者端重平衡
消费进度监控
下面开始本篇的正文
1:kafka的精确一次投递
我们知道kafka作为消息系统的一员,在消息的投递时可以保证最多一次,至少一次和精确一次
kafka的至少一次:
kafka默认是保证的至少一次的语义,即如果我们producer发送消息到broker,如果没有发送成功,比如出现网络抖动,它会默认重试的,通过这种机制来保证你的消息发送成功,可以去看代码
org.apache.kafka.clients.producer.internals.Sender#canRetry
重试次数少于参数retries指定的值,
异常是RetriableException类型或者TransactionManager允许重试
会把数据重新放入队列,等待重新轮询复制
kafka的最多一次:
这个其实很简单了,我们禁止重试即可
kafka的精确一次
kafka怎么样保证精确一次了,既不多也不少,有两种方式:
第一:通过kafkfa的幂等性:
Producer 默认不是幂等性的,但我们可以通过创建幂等性 Producer。它是 0.11.0.0 版本引入的新功能。在此之前,Kafka 向分区发送数据时,可能会出现同一条消息被发送了多次,导致消息重复的情况。在 0.11 之后,指定 Producer 幂等性的方法很简单,仅需要设置一个参数即可,即
props.put(“enable.idempotence”, ture),或
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)复制
,其它的不需要做任何改变.
它是怎么样实现幂等的了,底层原理大概就是它自己会对发过去的消息做去重判断,即典型的空间去换时间的套路
它也有缺点:因为它只能保证当个分区的幂等,还有就是在一个kafka进程中,即如果kafka重启了,那么幂等性就会丢失
第二:通过kafka的事务消息
说道事务,kafka的支持的事务隔离级别是读已提交,我们可以通过下面的方式来实现具有事务性的kafka的producer,
开启 enable.idempotence = true。
设置 Producer 端参数 transctional. id复制
在代码上
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}复制
consumer端做的改变
设置 isolation.level =read_committed,
默认情况下是read_uncommitted
当然这么设置对于普通的非事务消息也是可见的复制
它是怎么样实现的呢:我们可以把它想象成2PC,即会有一个事务协调者帮我们完成整个事务的提交回滚
2.kafka消费者组相关概念
Consumer Group的特点:
Consumer Group 下可以有一个或多个 Consumer 实例。这里的实例可以是一个单独的进程,也可以是同一进程下的线程。在实际场景中,使用进程更为常见一些。
Group ID 是一个字符串,在一个 Kafka 集群中,它标识唯一的一个 Consumer Group。
Consumer Group 下所有实例订阅的主题的单个分区,只能分配给组内的某个 Consumer 实例消费。这个分区当然也可以被其他的 Group 消费
理想情况下,Consumer 实例的数量应该等于该 Group 订阅主题的分区总数
既然说到了了消费者组我们就得说道消费者组的位移,在早期的kafka中,位移是保存在zk中的,但是因为要频繁的读写,发现zk的性能并不是那么友好,在新版本中,kafka的位移是保存在一个__consumer_offsets的位移主题中的,没错,它也是一个topic,就像我们的自己的topic一样,只是它属于kafka内建的,通过这种方式,kafka的位移的高性能就得到了保证
3.kafka的位移主题
位移主题的数据格式:位移主题的 Key 保存 3 部分内容:<Group ID,主题名,分区号 >,value保存的我们可以简单的认为是位移值,当然实际上远远是不止这样的
kafka位移主题是什么时候创建的呢
当kafka集群中的第一个consumer程序启动时,kafka就会自动创建位移主题,既然是主题那么它肯定也有分区数和副本数
offsets.topic.num.partitions=50,分区数,在kafka的日志路径下,我们可以看见很多类似于 __consumer_offsets-xxx的文件
offsets.topic.replication.factor=3 副本数复制
所以说,如果位移主题是 Kafka 自动创建的,那么该主题的分区数是 50,副本数是 3
当然我们也可以手动创建它, 在Kafka 集群尚未启动任何 Consumer 之前,使用 Kafka API 创建它,好处在于,你可以创建满足你实际场景需要的位移主题,当然建议最好是使用自动创建
现在我们有了位移主题了,那么是怎么使用的呢,或者说是怎么提交的
首先kafka提供两种提交方式,一种是自动提交另外一种就是手动提交
Consumer 端有个参数叫 enable.auto.commit,如果值是 true,则 Consumer 在后台默默地为你定期提交位移,提交间隔由一个专属的参数auto.commit.interval.ms 来控制,使用自动提交虽然说方便,但是会存在问题:
自动提交存在的问题
1:消息可能会丢失
2:还有一个问题,如果使用自动提交.假设我们在消息某个数据时,在T1时刻数据消费完了,然后没有任何消息产生,但是由于是自动提交,那么它会kafka会不断的提交这个重复消息,导致的问题就是内存越来越大,最后撑爆整个磁盘,
Compaction机制
Kafka 提供了专门的后台线程定期地巡检待 Compact 的主题,看看是否存在满足条件的可删除数据。这个后台线程叫 Log Cleaner,在很多实际生产环境中都出现过位移主题无限膨胀占用过多磁盘空间的问题,如果你的环境中也有这个问题,我们就可以去检查一下 Log Cleaner 线程的状态,通常都是这个线程挂掉了导致的
它是怎么样判断数据是不是可以删除了的:
对于同一个 Key 的两条消息 M1 和 M2,如果 M1 的发送时间早于 M2,那么 M1 就是过期消息。Compact 的过程就是扫描日志的所有消息,剔除那些过期的消息,然后把剩下的消息整理在一起
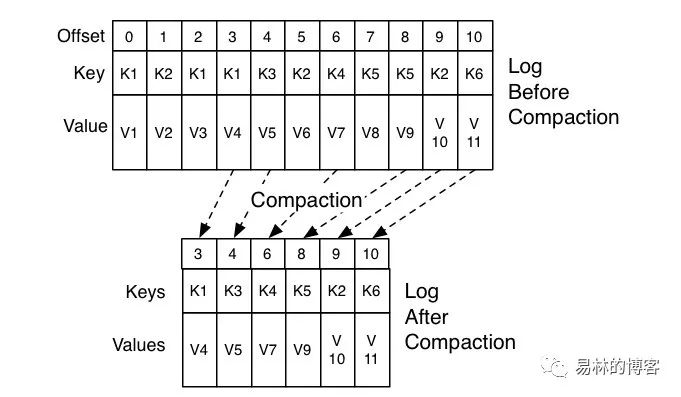
图中位移为 0、2 和 3 的消息的 Key 都是 K1。Compact 之后,分区只需要保存位移为 3 的消息,因为它是最新发送的
4.kafka位移提交
Consumer 需要向 Kafka 汇报自己的位移数据,这个汇报过程被称为提交位移(Committing Offsets),因为 Consumer 能够同时消费多个分区的数据,所以位移的提交实际上是在分区粒度上进行的,即Consumer 需要为分配给它的每个分区提交各自的位移数据。
kafka位移提交的方式:
对于用户来说分为自动提交和手动提交,手动提交又分为同步提交和异步提交
自动提交和手动提交,大家可以看上面3的说明,自动提交会存在一些问题,上面也说过,在生产环境中我们一般也都使用手动提交,下面我们来看下手动提交的两种方式
同步提交
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 处理消息
try {
consumer.commitSync();
} catch (CommitFailedException e) {
handle(e); // 处理提交失败异常
}
}复制
同步提交相对于自动提交来说,由我们自己来控制位移的提交,尽可能的可以避免数据丢失的问题,当然它也存在问题,因为是同步提交,所以需要等待broker的反馈,才会结束,这样就影响整个应用的TPS了,所以我们下面看另外一个方法
异步提交
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 处理消息
consumer.commitAsync((offsets, exception) -> {
if (exception != null)
handle(exception);
});
}复制
调用之后会立即返回,异步会使用函数来获取发送的成功与否
那么我们在生产环境中,就直接用异步提交嘛,并不是这样的,异步提交和同步提交有一个很大的区别就是,异步提交出现问题时它不会重试,因为它是异步操作的,就算让它重试,可能它在想提交时,位移进度可能都不是最新值了,所以异步提交下,重试没有任何意义,基于此,如果我们想又不影响TPS,又可以实现重试功能,我们怎么做呢
try {
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 处理消息
commitAysnc(); // 使用异步提交规避阻塞
}
} catch (Exception e) {
handle(e); // 处理异常
} finally {
try {
consumer.commitSync(); // 最后一次提交使用同步阻塞式提交
} finally {
consumer.close();
}
}复制
这段代码同时使用了 commitSync() 和 commitAsync()。对于常规性、阶段性的手动提交,我们调用 commitAsync() 避免程序阻塞,而在 Consumer 要关闭前,我们调用 commitSync() 方法执行同步阻塞式的位移提交,以确保 Consumer 关闭前能够保存正确的位移数据。将两者结合后,我们既实现了异步无阻塞式的位移管理,也确保了 Consumer 位移的正确性
更加细粒度的提交
Kafka Consumer API 为手动提交提供了这样的方法:commitSync(Map<TopicPartition, OffsetAndMetadata>) 和 commitAsync(Map<TopicPartition, OffsetAndMetadata>)。它们的参数是一个 Map 对象,键就是 TopicPartition,即消费的分区,而值是一个 OffsetAndMetadata 对象,保存的主要是位移数据
我们想实现每处理100条消息就提交一次,可用下面的代码
rivate Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
int count = 0;
……
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record: records) {
process(record); // 处理消息
offsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1);
if(count % 100 == 0)
consumer.commitAsync(offsets, null); // 回调处理逻辑是 null
count++;
}
}复制
5.kafka提交位移异常
CommitFailedException,顾名思义就是 Consumer 客户端在提交位移时出现了错误或异常,而且还是那种不可恢复的严重异常。如果异常是可恢复的瞬时错误,提交位移的 API 自己就能规避它们了,因为很多提交位移的 API 方法是支持自动错误重试的,比如commitSync 方法
可能的原因:
1:max.poll.interval.ms设置不合法
Properties props = new Properties();
…
props.put("max.poll.interval.ms", 5000);
consumer.subscribe(Arrays.asList("test-topic"));
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
// 使用 Thread.sleep 模拟真实的消息处理逻辑
Thread.sleep(6000L);
consumer.commitSync();
}复制
分析上面一段代码,我们设置了max.poll.interval.ms等于5秒(消息拉取的最大频率),但是消息的处理时间需要6秒,这时Kafka Consumer 端会抛出 CommitFailedException 异常
我们怎么样去防止这样的问题呢
下面的也是我们解决此类的优先级排序
缩短单条消息处理的时间
增加 Consumer 端允许下游系统消费一批消息的最大时长,即max.poll.interval.ms的值
减少下游系统一次性消费的消息总数,这取决于 Consumer 端参数 max.poll.records 的值。当前该参数的默认值是 500 条
下游系统使用多线程来加速消费
关于使用多线程来消费程序,这是实现难度最大的一个,我们知道kafkaConsumer是线程不安全的,我们要想用多线程,也有下面的两种方式
使用多线程多consumer实例
单线程单cosumer实例+消息处理worker多线程
两种方法都有各自的优缺点

多线程方法,创建了一个 Runnable 类,在实际应用中,你可以创建多个 KafkaConsumerRunner 实例,并依次执行启动它们,达到多线程的效果
public class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public void run() {
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
ConsumerRecords records =
consumer.poll(Duration.ofMillis(10000));
// 执行消息处理逻辑
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
closed.set(true);
consumer.wakeup();
}复制
方案二的伪代码
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
...
private int workerNum = ...;
executors = new ThreadPoolExecutor(
workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy());
...
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (final ConsumerRecord record : records) {
executors.submit(new Worker(record));
}
}
..复制
2.在同一个kafka集群中设置相同的groupid也会出现上面的问题
6.消费进度监控
对于 Kafka 消费者来说,最重要的事情就是监控它们的消费进度了,或者说是监控它们消费的滞后程度。这个滞后程度有个专门的名称:消费者 Lag 或 Consumer Lag
通常来说,Lag 的单位是消息数,而且我们一般是在主题这个级别上讨论 Lag 的,但实际上,Kafka 监控 Lag 的层级是在分区上的,如果要计算主题级别的,你需要手动汇总所有主题分区的 Lag,将它们累加起来,合并成最终的 Lag 值
正常工作的消费者,它的 Lag 值应该很小,甚至是接近于 0 的,如果一个消费者 Lag 值很大,通常就表明它无法跟上生产者的速度,最终 Lag 会越来越大,从而拖慢下游消息的处理速度,更可怕的是,由于消费者的速度无法匹及生产者的速度,极有可能导致它消费的数据已经不在操作系统的页缓存中了,那么这些数据就会失去享有 Zero Copy 技术的资格。这样的话,消费者就不得不从磁盘上读取它们,这就进一步拉大了与生产者的差距,进而出现马太效应,即那些 Lag 原本就很大的消费者会越来越慢,Lag 也会越来越大
kafka-consumer-groups 脚本是 Kafka 为我们提供的最直接的监控消费者消费进度的工具
bin/kafka-consumer-groups.sh --bootstrap-server <Kafka broker 连接信息 > --describe --group <group 名称 >复制
该命令还会输出一些值,如当前最新生产的消息的位移值(即 LOG-END-OFFSET 列值),该消费者组当前最新消费消息的位移值(即 CURRENT-OFFSET 值)等等
在实际场景中我们一般都会结合Zabbix 或 Grafana,这种情况下我们一般是使用Kafka JMX 监控指标,使用这个时,观察消费进度,一般观察这两个指标records-lag-max 和 records-lead-min,它们分别表示此消费者在测试窗口时间内曾经达到的最大的 Lag 值和最小的 Lead 值
Lead 值是指消费者最新消费消息的位移与分区当前第一条消息位移的差值,一旦你监测到 Lead 越来越小,甚至是快接近于 0 了,你就一定要小心了,这可能预示着消费者端要丢消息了
关于监控暂时说到这里,关于kafka的监控,我们关注的点远不止这些
7.总结
本篇文章到这里结束了,文章中所涉及到的每个点大家其实都可以自己专研进去,本篇文章更多的是一个大纲的作用,最后谢谢大家
