




高效的数据库管理对于处理大型数据集并保持最佳性能和易于维护至关重要。PostgreSQL 中的表分区是一种可靠的方法,用于将大型表逻辑地划分为较小的、可管理的部分(称为分区)。此技术有助于提高查询性能、简化维护任务并降低存储成本。

本文深入探讨了如何在PostgreSQL中创建和管理表分区,重点介绍了pg_partman基于时间和基于序列的分区扩展。详细讨论了 PostgreSQL 中支持的分区类型,并提供了实际用例和实际示例来说明其实现。
介绍
现代应用程序会生成大量数据,需要高效的数据库管理策略来处理这些数据。表分区是一种将大表划分为逻辑上相关的较小段的技术。PostgreSQL 提供了一个强大的分区框架来有效地管理此类数据集。
为什么要分区?
提高查询性能。查询可以使用约束排除或查询修剪快速跳过不相关的分区。
简化维护。可以在较小的数据集上执行特定于分区的操作,例如清理或重新索引。
高效归档。可以删除或归档较旧的分区,而不会影响活动数据集。
可扩展性。分区可以实现水平扩展,特别是在分布式环境中。
本机分区与基于扩展的分区
PostgreSQL 原生的声明式分区简化了分区的许多方面,而诸如此类的扩展pg_partman提供了额外的自动化和管理功能,特别是对于动态用例。
本机分区与 pg_partman
PostgreSQL 中的表分区类型
PostgreSQL 支持三种主要的分区策略:Range、List 和 Hash。每种策略都有适合不同用例的独特特性。
范围分区
范围分区根据特定列(通常是日期或数字列)中的值范围将表划分为多个分区。
例如:月度销售数据
例如:月度销售数据
SQL
创建 表销售( sale_id 序列号, sale_date日期 不为 空, 数量数字 )按范围分区(sale_date); 创建 表sales_2023_01 销售分区 对于值 从( '2023-01-01' ) 到 ( '2023-02-01' );复制
- 优点
适用于日志或交易等时间序列数据
支持顺序查询,例如检索特定月份的数据 - 缺点
需要预定义范围,这可能会导致频繁的架构更新
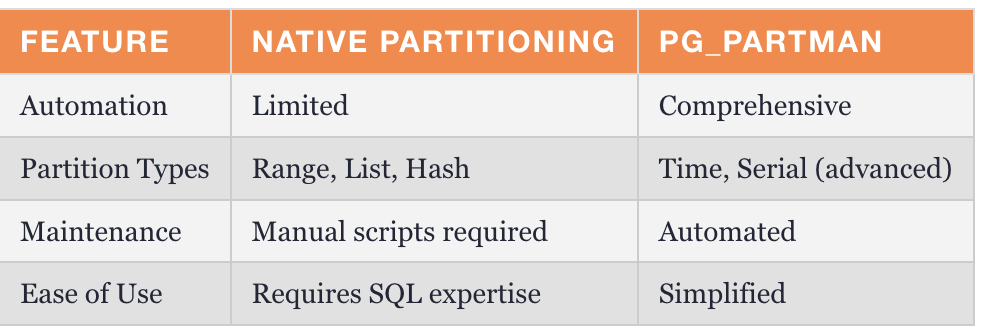
列表分区
列表分区根据一组离散的值(例如区域或类别)来划分数据。
例:区域订单
创建 表订单( order_id 序列号, 区域文本 不为 空, 数量数字 )按列表分区(区域); 创建 表orders_us 对订单进行分区,以获得('US' )中的值 ; 创建 表orders_eu 对订单进行分区,以获得('EU' )中的值 ;复制
- 优点
适合具有有限数量类别(例如地区、部门)的数据集
易于管理一组固定的分区 - 缺点
不适合动态或扩展类别
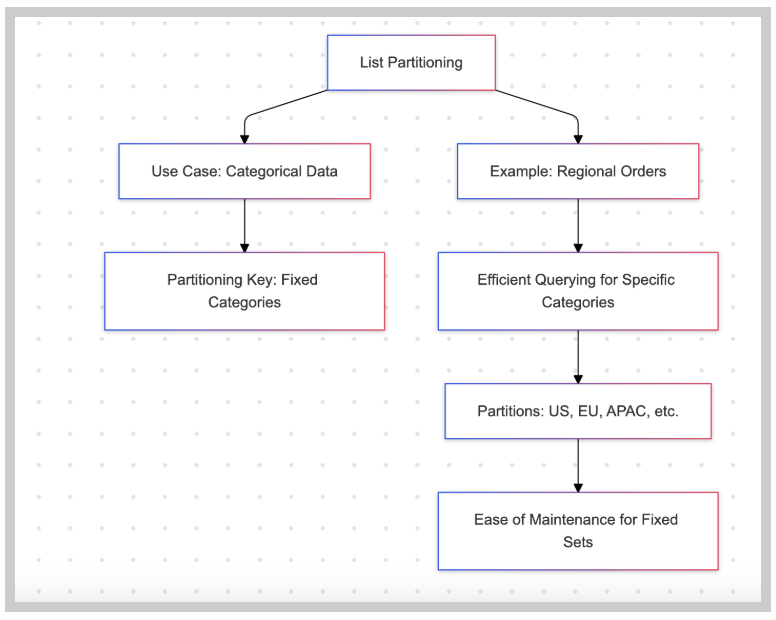
哈希分区
哈希分区使用哈希函数将行分布到一组分区中。这可确保数据均匀分布。
示例:用户帐户
创建 表用户( 用户 ID 序列号, 用户名TEXT NOT NULL )按哈希(user_id)分区; 创建 表users_partition_0 用户分区 对于值(模数4,余数0);复制
- 优点
确保跨分区均衡分布,防止热点
适合均匀分布的工作负载 - 缺点
不易于人类阅读;无法直观地识别分区
pg_partman:综合指南
pg_partman是 PostgreSQL 扩展,可简化分区管理,特别是针对基于时间和基于序列的数据集。
安装和设置
pg_partman需要作为 PostgreSQL 中的扩展进行安装。它提供了一套函数来动态创建和管理分区表。
使用你的包管理器安装:
sudo apt-get 安装 postgresql-pg-partman复制
在数据库中创建扩展:
创建扩展 pg_partman;复制
配置分区
pg_partman支持基于时间和基于序列的分区,这对于具有时间数据或序列标识符的数据集特别有用。
基于时间的分区示例
SQL
创建 表日志( 序列号, log_time时间戳 不为 空, 信息文本 (英文): 选择partman.create_parent ( p_parent_table := '公共.日志' , p_control := 'log_time' ,复制代码 p_type := '时间', p_interval := '每日' (英文):复制
此配置:
- 自动创建每日分区
- 简化日志数据的查询和维护
基于串行的分区示例
SQL
创建 表事务( transaction_id BIGSERIAL 主键, 详细信息文本 不为 空 (英文): 选择partman.create_parent ( p_parent_table := '公共.交易' , p_control := '交易ID' , p_type := '串行' , p_间隔 := 100000 (英文):复制
这样每 100,000 行就会创建一次分区,确保父表仍然可管理。
自动化功能
自动维护
用于run_maintenance()确保未来的分区是预先创建的:
SQL
选择partman.run_maintenance ( );复制
保留政策
定义保留期以自动删除旧分区:
更新partman .part_config SET保留期 = ‘12 个月’ 其中parent_table = 'public.logs';复制
pg_partman 的优点
简化动态分区创建
自动清理和维护
减少手动架构更新的需要
表分区的实际用例
- 日志管理。高频日志按天分区,方便归档和查询。
- 多区域数据。电子商务系统按地区划分订单,以提高可扩展性。
- 时间序列数据。具有分区遥测数据的物联网应用程序。
日志管理
按天或按月对日志进行分区,以有效管理高频数据。
选择partman.create_parent ( p_parent_table := '公共.服务器日志' , p_control := '时间戳' , p_type := '时间', p_interval := '每月' (英文):复制
多区域数据
按地区划分销售或库存数据,以获得更好的可扩展性。
创建 表销售( sale_id 序列号, 区域文本 不为 空 )按列表分区(区域);复制
大批量交易
按顺序对事务进行分区ID以避免索引臃肿。
选择partman.create_parent ( p_parent_table := '公共.交易' , p_control := '交易ID' , p_type := '串行' , p_间隔 := 10000 (英文):复制
结论
表分区是管理大型数据集不可或缺的技术。PostgreSQL 的内置功能与pg_partman扩展相结合,使实现动态和自动分区策略变得更加容易。这些工具使数据库管理员能够提高性能、简化维护并有效扩展。
分区是现代数据库管理的基石,尤其是在大容量应用程序中。理解和应用这些概念可确保数据库系统强大且可扩展。
原文地址:https://dzone.com/articles/postgresql-partitioning-pg-partman-data-management
原文作者: arvind toorpu



