




作者:中国—东盟信息港股份有限公司 高级研发 陈奎霖
编辑整理:白鲸开源 曾辉
本文主要给大家介绍JDBC Source批处理任务动态切分优化,希望大家批评指正

JDBC Source 如果配置了table_path
和 partition_column
,引擎会对数据进行动态切分,可以通过分析样本数据优化切分区间,规避数据倾斜问题。
目前发现任务即使配置了where_condition
,动态切分算法仍然会把数据进行全表切分,在从大表中读取少量数据的场景下,任务切分阶段会耗费大量的时间,需要修改下面相关的流程进行优化。
下面所有出现SQL语句的地方均以MySQL为例子进行说明,具体不同的数据源有不同的子类方法overwrite
实现。
数据切分主流程
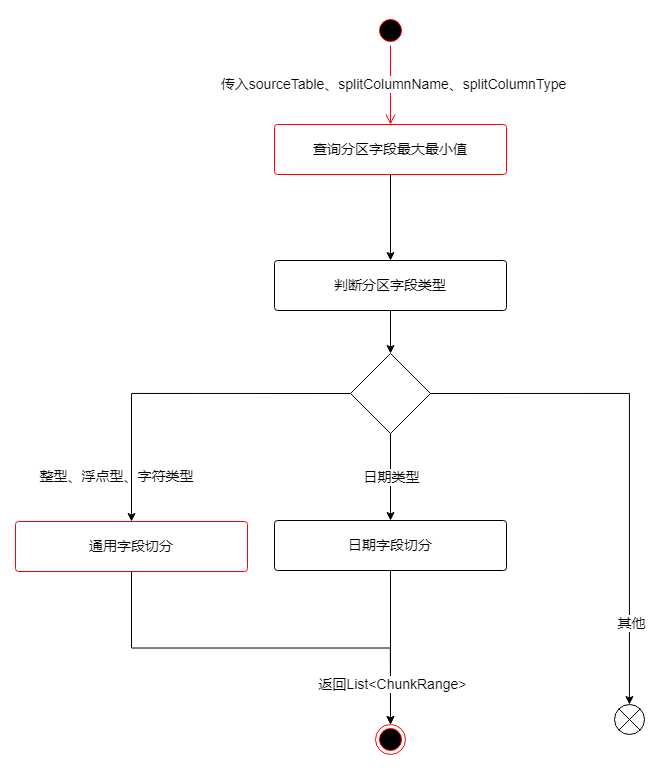
数据动态切分的代码入口位于DynamicChunkSplitter
类中的splitTableIntoChunks
方法,流程图中标红的方框表示需要修改的部分,详细在下面的子流程中展开说明。
查询最大最小值
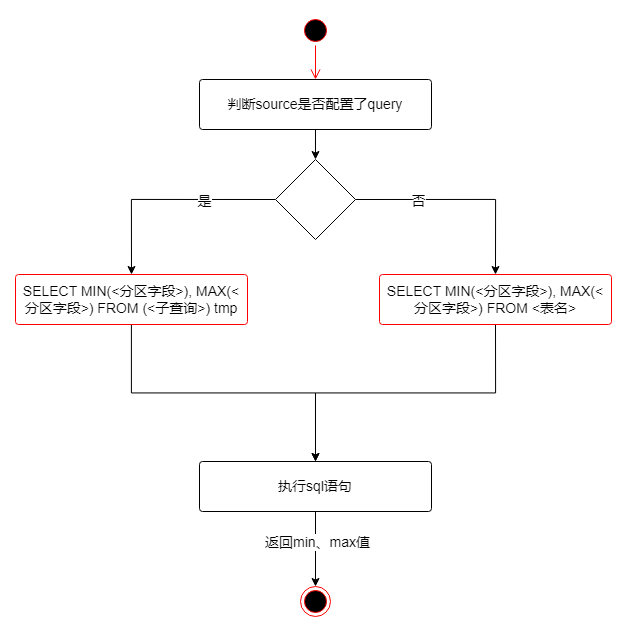
需要加上Source的where_condition
配置的判断和拼接。
通用字段切分

查询数据总条数部分
(1)增加且where_condition
配置为空才走“是”的分支
(2)修改“否”分支,增加where_condition
的判断和对应查询语句的拼接,子查询和表查询的规则如下:
如果配置了Query则查询SQL为
SELECT COUNT(*) FROM (<子查询>) T
否则查询SQL为
SELECT COUNT(*) FROM <表名>
如果配置了
where_condition
则拼接到末尾
切分数据区间部分
详情见子流程
分页查询分片
查询下一个分片的结束边界nextChunkEnd
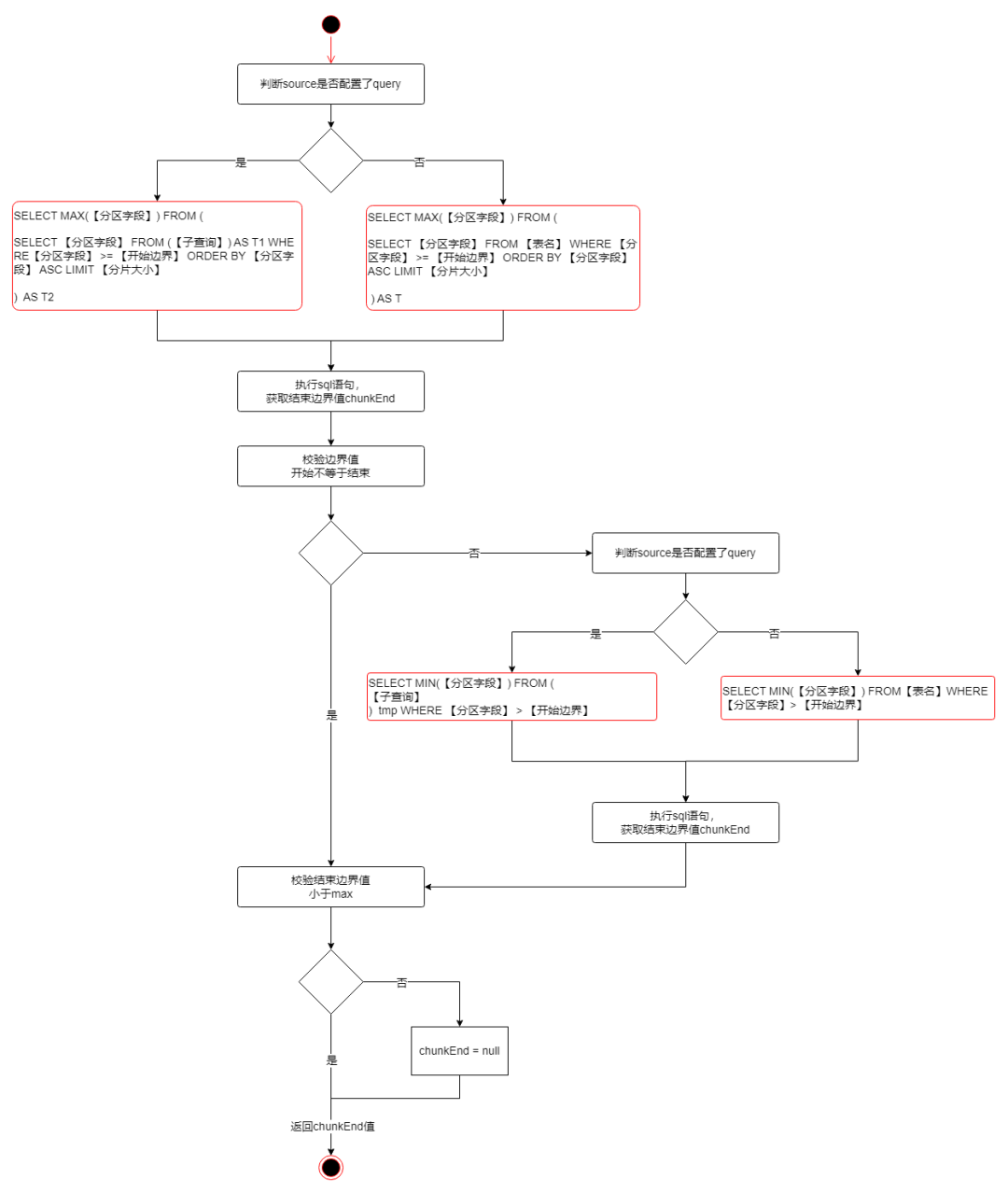
1.max查询部分
判断如果配置了where_condition则在limit那层查询添加条件拼接
2.min查询部分
判断如果配置了where_condition则添加条件拼接
样本查询分片
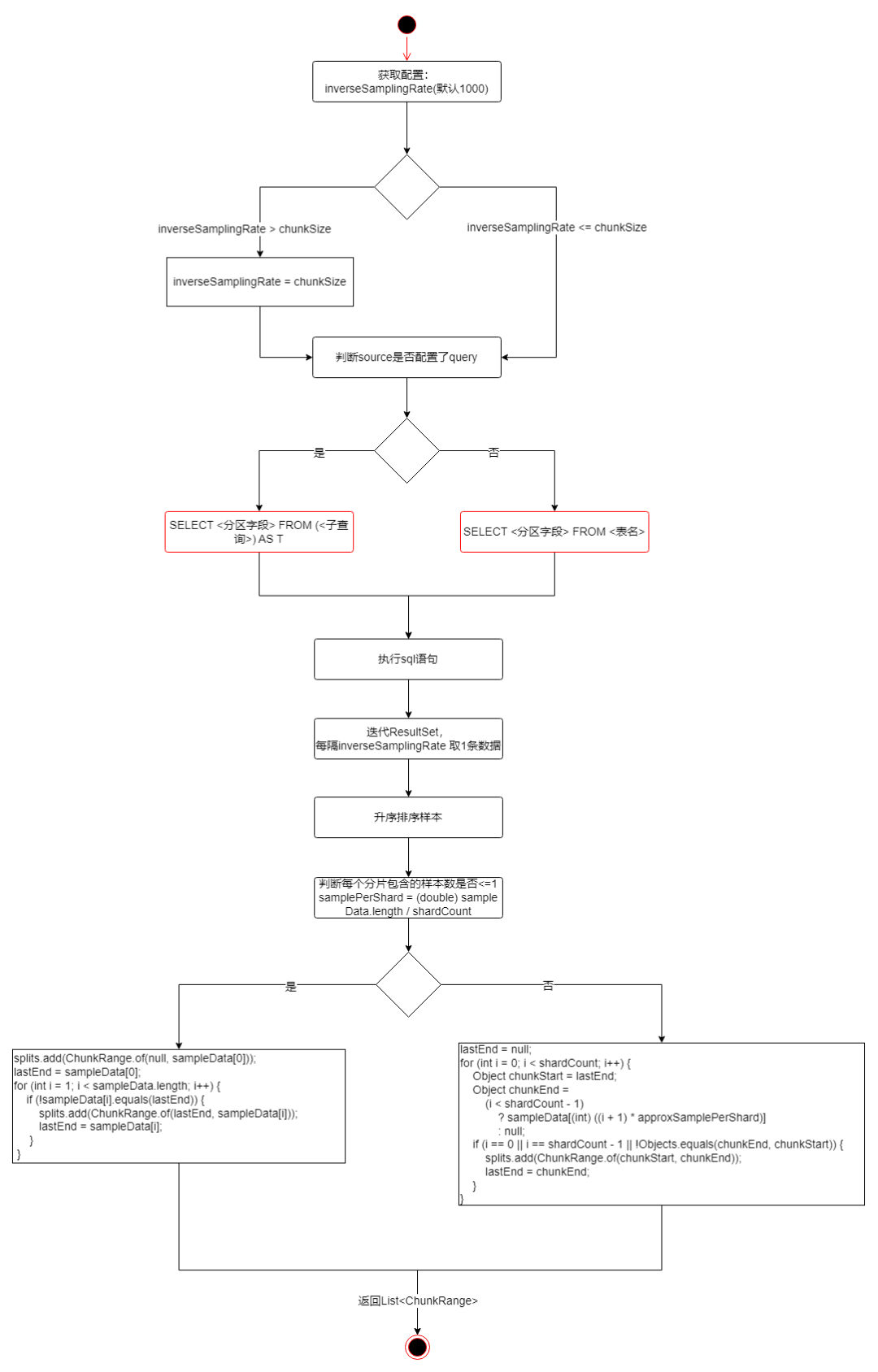
判断如果配置了where_condition
则添加条件拼接
日期字段切分
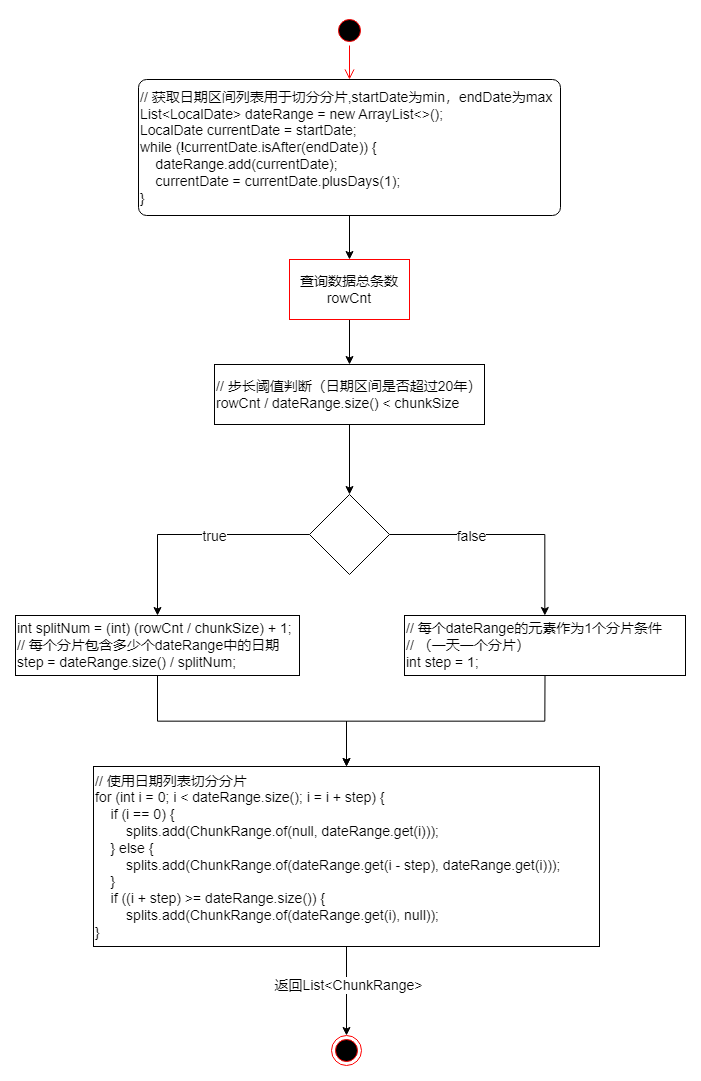
复用了通用字段切分
的1部分,只需修改一次即可。
分片使用流程
这里相关的流程不需要修改,这里分析是为了弄清楚分片是如何被使用的,以评估前面修改的必要性、正确性和风险。
数据被切分为分片后会被分发到Worker的SourceSeaTunnelTask
中,最终在JdbcInputFormat
类的open
方法中被使用,主要流程如下
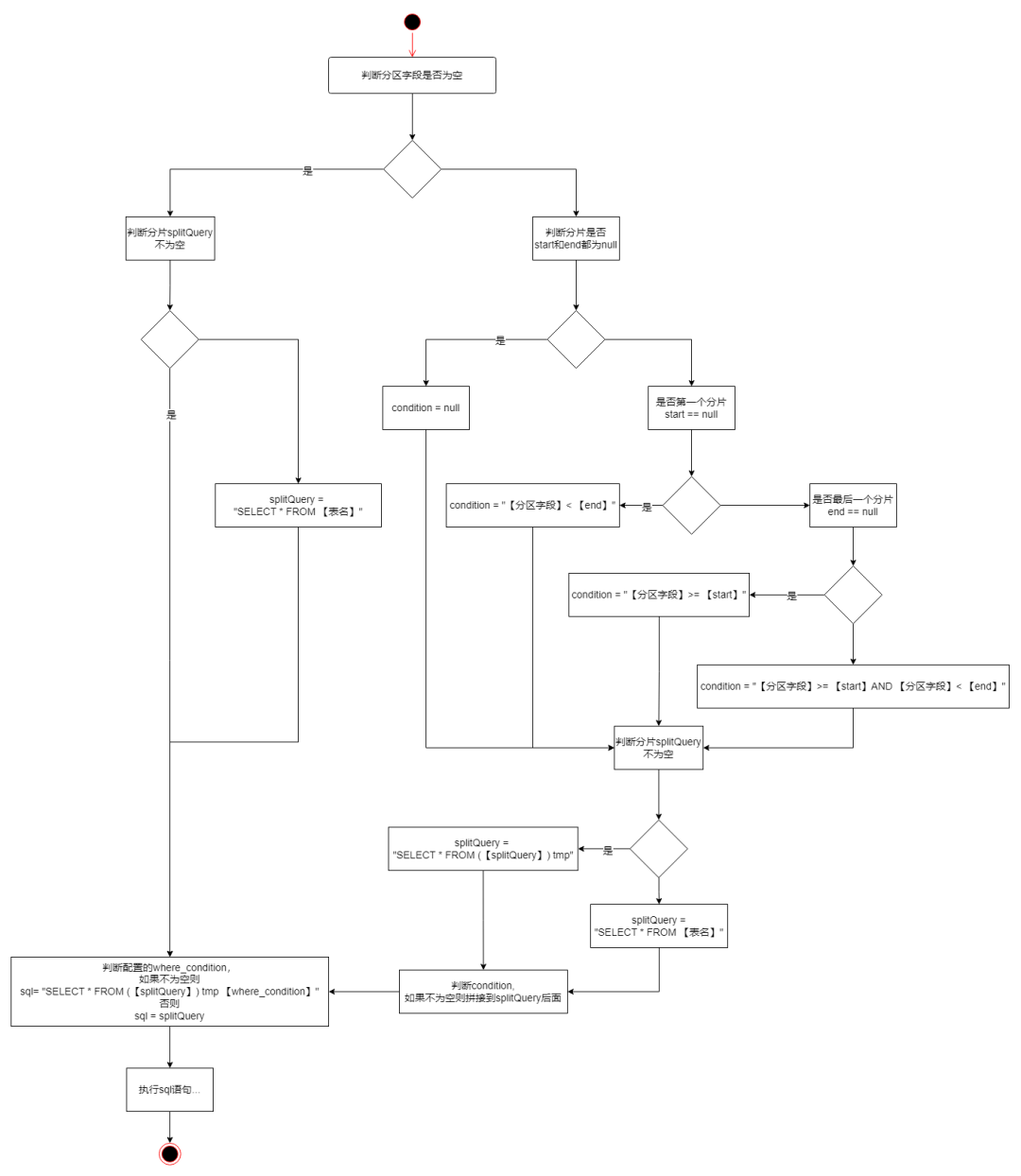
由上面流程可知,由分片生成的SQL在最后会判断拼接where_condition
,如果在生成分片的阶段没有考虑where_condition
,则生成的分片中可能有部分分片在追加上where_condition
条件限制后查询不到数据,当这样的分片很多时,不但会影响分片切分的性能,也会影响数据读取的性能,因为过程中产生了大量的无效查询。
优化效果
优化之后本地测试从一个55G的MySQL表使用where_condition
过滤读取多条数据写入Oracle表的耗时从25分钟缩短到23秒。
提交的PR链接:https://github.com/apache/seatunnel/pull/8760
白鲸开源
白鲸开源是一家开源原生的 DataOps 商业公司,由多个 Apache Foundation Member成立,80%员工都是 Apache Committer,运营2 个全球 Apache 开源项目(DolphinScheduler, SeaTunnel),同时根据全球最佳实践发布商业版版本WhaleScheduler和WhaleTunnel。我们致力于打造下一代开源原生的DataOps 平台,助力企业在大数据和云时代,智能化地完成多数据源、多云及信创环境的数据集成、调度开发和治理,以提高企业解决数据问题的效率,提升企业分析洞察能力和决策能力。
社区介绍
Apache SeaTunnel是一个云原生的高性能海量数据集成工具。北京时间 2023 年 6 月1 日,全球最大的开源软件基金会Apache Software Foundation正式宣布Apache SeaTunnel毕业成为Apache顶级项目。目前,SeaTunnel在GitHub上Star数量已达 8k+,社区达到6000+人规模。SeaTunnel支持在云数据库、本地数据源、SaaS、大模型等130多种数据源之间进行数据实时和批量同步,支持CDC、DDL变更、整库同步等功能,更是可以和大模型打通,让大模型链接企业内部的数据。
同步Demo
新手入门

最佳实践

测试报告
源码解析
Apache SeaTunnel
