






本文将介绍如何构建一个实时推荐引擎,利用 RisingWave[1]、Kafka[2] 和 Redis[3] 即时响应用户行为,提供精准推荐,优化购物体验并提升转化率。
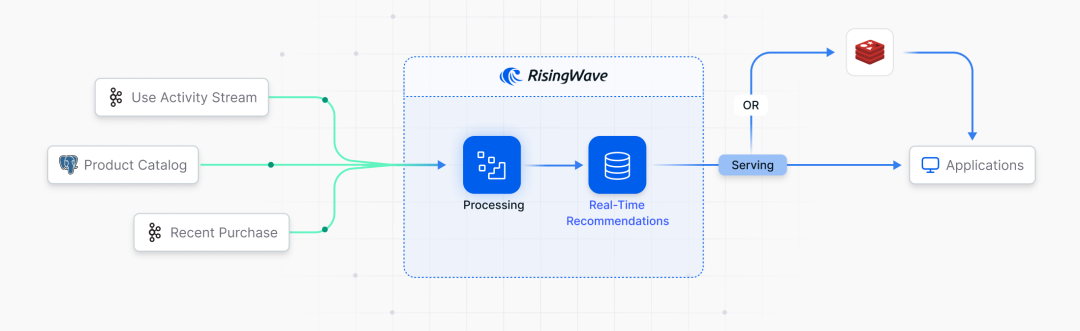

设计思路
数据摄取
用户行为数据(如浏览页面、点击、搜索、加入购物车等)实时流入 Kafka 主题。
产品目录数据(如产品 ID、名称、类别、价格)存储在 PostgreSQL 数据库,并通过 Change Data Capture (CDC) 同步到 RisingWave。当然,如果产品数据更新频率较低,也可以直接存储在 RisingWave 中。
可以选择性地将购买记录数据流用于协同过滤。
流处理
RisingWave 通过定义与 Kafka 主题关联的 Source 来接收数据流,并利用基于 SQL 的物化视图处理推荐逻辑,确保数据随新事件到达时持续更新。
推荐结果存储
RisingWave 计算出的推荐结果会存入 Redis,这是一个针对快速检索优化的内存缓存数据库。
注:在低流量场景或原型阶段,可以直接查询 RisingWave,但在生产环境下,目前 Redis 由于其性能优势仍然是更优的选择。
推荐服务
电商应用可通过用户 ID 从 Redis 获取推荐结果,提供高速、流畅的用户体验。

示例数据
用户行为流(Kafka)
// 页面浏览事件
{
"event_type": "page_view",
"user_id": 123,
"product_id": "product_abc",
"timestamp": "2024-07-27T10:00:00Z"
}
// 搜索事件
{
"event_type": "search",
"user_id": 456,
"query": "running shoes",
"timestamp": "2024-07-27T10:03:00Z"
}
复制
产品目录流(Kafka - 通过 CDC 同步)
{
"product_id": "product_abc",
"name": "Awesome Running Shoes",
"category": "shoes/running",
"price": 99.99,
"description": "...",
"image_url": "..."
}复制

RisingWave 集群:关于如何启动 RisingWave 集群,请参考快速入门指南[4]。 Kafka 实例:用于存储实时用户行为数据流(Kafka 主题)。 PostgreSQL 实例:用于存储 product_catalog(产品目录)表,并启用变更数据捕获(Change Data Capture, CDC) 以实现实时同步。详细配置请参考从 PostgreSQL CDC 导入数据[5]。 Redis 实例:用于缓存推荐结果,加快查询速度。
步骤 1:定义数据源
通过以下 SQL 语句连接 Kafka 主题,定义数据源:
-- 用户行为数据流
CREATE SOURCE user_activity_stream (
event_type VARCHAR,
user_id INT,
product_id VARCHAR,
timestamp TIMESTAMP
) WITH (
connector = 'kafka',
topic = 'user_activity',
brokers = 'kafka-broker1:9092,kafka-broker2:9092',
scan.startup.mode = 'earliest',
format = 'json'
);
-- 产品目录数据流
CREATE SOURCE product_catalog (
product_id VARCHAR,
name VARCHAR,
category VARCHAR,
price DOUBLE PRECISION,
description VARCHAR,
image_url VARCHAR
) WITH (
connector = 'kafka',
topic = 'product_catalog',
brokers = 'kafka-broker1:9092,kafka-broker2:9092',
scan.startup.mode = 'earliest',
format = 'json'
);复制
步骤 2:创建物化视图以跟踪热门商品
以下 SQL 语句用于计算最近 1 小时内浏览次数最多的前 10 个商品:
CREATE MATERIALIZED VIEW trending_products AS
WITH windowed_views AS (
SELECT
window_start,
product_id,
COUNT(*) AS view_count
FROM
TUMBLE(user_activity_stream, timestamp, INTERVAL '1 hour')
WHERE event_type = 'page_view'
GROUP BY window_start, product_id
),
ranked_products AS (
SELECT
window_start,
product_id,
view_count,
RANK() OVER (PARTITION BY window_start ORDER BY view_count DESC) AS rank
FROM windowed_views
)
SELECT
window_start,
product_id,
view_count
FROM ranked_products
WHERE rank <= 10; -- 仅保留前 10 个热门商品复制
该视图的作用:
以 1 小时为窗口,对页面浏览事件进行分组统计。 按照浏览次数对商品进行排名。 随着新数据到达,视图会持续增量更新,确保数据始终保持最新。
步骤 3:创建个性化推荐的物化视图
基于用户最近浏览的商品类别,生成个性化推荐:
CREATE MATERIALIZED VIEW user_recommendations AS
WITH recent_user_activity AS (
SELECT user_id, product_id, timestamp
FROM user_activity_stream
WHERE event_type = 'page_view'
AND timestamp > NOW() - INTERVAL '24 hours'
),
user_category_views AS (
SELECT
r.user_id,
p.category,
COUNT(*) AS category_views
FROM recent_user_activity r
JOIN product_catalog p ON r.product_id = p.product_id
GROUP BY r.user_id, p.category
),
ranked_categories AS (
SELECT
user_id,
category,
category_views,
RANK() OVER (PARTITION BY user_id ORDER BY category_views DESC) AS rank
FROM user_category_views
),
recommendations AS (
SELECT
rc.user_id,
p.product_id AS recommended_product_id
FROM ranked_categories rc
JOIN product_catalog p ON rc.category = p.category
WHERE rc.rank <= 3
AND p.product_id NOT IN (
SELECT product_id FROM recent_user_activity WHERE user_id = rc.user_id
)
)
SELECT
user_id,
array_agg(recommended_product_id) AS recommended_products
FROM recommendations
GROUP BY user_id;复制
该视图的作用:
分析用户最近 24 小时的浏览记录。 计算用户最常浏览的 3 个商品类别。 在这些类别中挑选用户未浏览过的热门商品进行推荐。
步骤 4:将推荐结果写入 Redis
-- 个性化推荐结果存入 Redis
CREATE SINK user_recommendations_sink
FROM user_recommendations WITH (
connector = 'redis',
primary_key = 'user_id',
redis.url = 'redis://127.0.0.1:6379/'
) FORMAT PLAIN ENCODE JSON (
force_append_only = 'true'
);
-- 热门商品数据存入 Redis
CREATE SINK trending_products_sink
FROM trending_products WITH (
connector = 'redis',
primary_key = 'window_start,product_id',
redis.url = 'redis://127.0.0.1:6379/'
) FORMAT PLAIN ENCODE TEMPLATE (
force_append_only = 'true',
key_format = 'trending:{window_start}',
value_format = '{product_id}:{view_count}'
);复制
Redis 数据结构示例:
个性化推荐: user_id → {"user_id": 123, "recommended_products": ["prod1", "prod2"]}热门商品:
trending:2024-03-21T10:00:00 → product_abc:42

应用端查询推荐结果
import redis
import json
# 连接 Redis
redis_client = redis.Redis(host='127.0.0.1', port=6379, decode_responses=True)
def get_user_recommendations(user_id):
data = redis_client.get(str(user_id))
return json.loads(data)['recommended_products'] if data else []
def get_trending_products(window_start):
key = f"trending:{window_start}"
return redis_client.hgetall(key)
# 示例
print(get_user_recommendations(123))
print(get_trending_products('2025-02-25T10:00:00'))复制
对于低流量场景或原型阶段,可以直接查询 RisingWave 物化视图,而无需 Redis:
from risingwave import RisingWave, RisingWaveConnOptions, OutputFormat
import pandas as pd
# 使用官方 SDK 连接到 RisingWave
rw = RisingWave(
RisingWaveConnOptions.from_connection_info(
host='localhost',
port=4566, # 默认的 RisingWave 端口
user='root',
password='root',
database='dev'
)
)
def get_recommendations_direct(user_id: int) -> list:
"""Retrieves recommendations directly from RisingWave."""
query = f"""
SELECT recommended_products
FROM user_recommendations
WHERE user_id = {user_id}
"""
# 使用 fetch 以 DataFrame 形式获取结果
result: pd.DataFrame = rw.fetch(
query,
format=OutputFormat.DATAFRAME
)
if not result.empty:
return result['recommended_products'].iloc[0]
return []
# 示例
def example_usage():
user_recs = get_recommendations_direct(123)
print(f"Recommendations for user 123 (direct): {user_recs}")
# 如有需要,也支持以原始元组的形式获取结果
raw_results = rw.fetch(
"SELECT * FROM trending_products LIMIT 5",
format=OutputFormat.RAW
)
print(f"Trending products (raw): {raw_results}")复制
注意:虽然直接查询方式更简单,但对于高并发环境,仍建议使用 Redis 进行缓存,以提升响应速度。

实时更新:系统能够即时响应用户行为,确保推荐内容始终准确。 低延迟:Redis 提供高速数据检索,RisingWave 负责高效计算,确保整体性能优越。 良好的扩展性:RisingWave 和 Redis 都支持水平扩展,能够灵活应对流量增长。 易于开发:基于 SQL 进行数据处理,使系统的开发和维护更加便捷。 高可靠性:分布式架构增强了系统的容错能力,保障业务的连续性。
优化方向
A/B 测试:针对不同的推荐策略进行实验,以优化效果。 集成机器学习模型:引入更高级的数据分析和预测能力,提高推荐的精准度。 细分趋势分析:根据用户群体特征提供个性化趋势推荐。 数据增强:利用特征存储(Feature Store)丰富用户画像,实现更精细化的个性化推荐。
RisingWave 让实时推荐系统的构建变得前所未有的简单。结合流式数据处理的强大能力与 Redis 的极速响应,可以打造一个动态、精准的推荐引擎,为用户提供更具吸引力的购物体验,并提升转化率。立即查阅 RisingWave 文档[6],开始你的构建之旅吧!
RisingWave: https://risingwave.com/
[2]Kafka: https://kafka.apache.org/
[3]Redis: https://redis.io/
[4]快速入门指南: https://docs.risingwave.com/get-started/quickstart
[5]从 PostgreSQL CDC 导入数据: https://docs.risingwave.com/integrations/sources/postgresql-cdc
[6]RisingWave 文档: https://docs.risingwave.com/get-started/intro
关于 RisingWave


技术内幕
👇 点击阅读原文,立即体验 RisingWave!
