




作者:王润基 RisingWave Labs 内核开发工程师
本文整理自 RisingWave 数据库内核开发工程师 王润基 在 Rust China Conf 2023「数据库与大数据专场」分论坛的分享。感兴趣的读者可以在 B 站上观看本次 talk 的完整录像[1],或是阅读相关文章[2]了解更多技术细节。
egg 是一个 Rust 编写的程序优化器库。它基于 e-graph 和 equality saturation 技术,能够高效、灵活地构造自己的语言并对其进行优化。本次分享将带领大家基于 egg 实现年轻人的第一个 SQL 语言优化器。用 1000 行左右代码实现各种经典的优化规则,并对真实的 TPC-H 查询进行优化。
本次分享主要包含以下内容:
项目背景和应用 egg 的动机 egg 的基本原理和使用方式 用 egg 实现 SQL 优化器的主要过程 效果展示和对 egg 好处与不足的分析
1我们为什么要使用 egg
故事开始于 RisingLight 项目。这是一个 Rust 语言编写的 OLAP 教学数据库,由几位学生在 RisingWave 实习期间发起并维护。创建 RisingLight 的主要目的是为了让感兴趣的学生、工程师和社区开发者能够深入了解数据库的基本原理和实现。因此 RisingLight 的设计目标是简单、全面且易于理解。
作为 OLAP 数据库,查询引擎是其中核心组成部分。下图展示了它的整体结构:
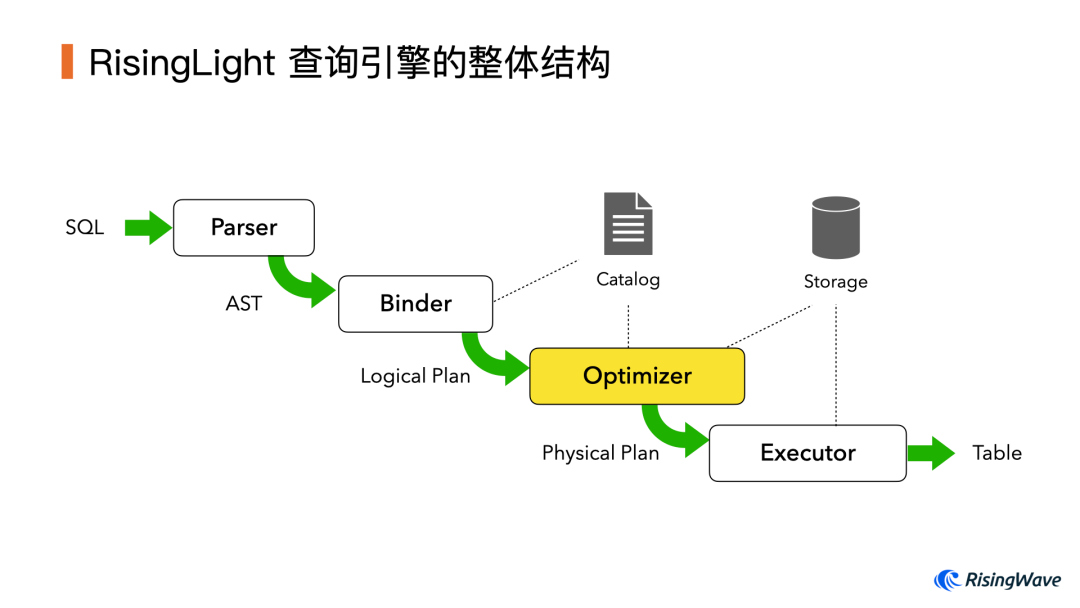
用户输入 SQL 语句后,分别经过 Parser、Binder 的处理生成逻辑查询计划(Logical Plan),然后喂给优化器,生成物理查询计划(Physical Plan),最后交给执行器(Executor)运行。
这里我们通过一个例子来具体展示 SQL 语句、查询计划 和 经过优化的查询计划 之间的关系:
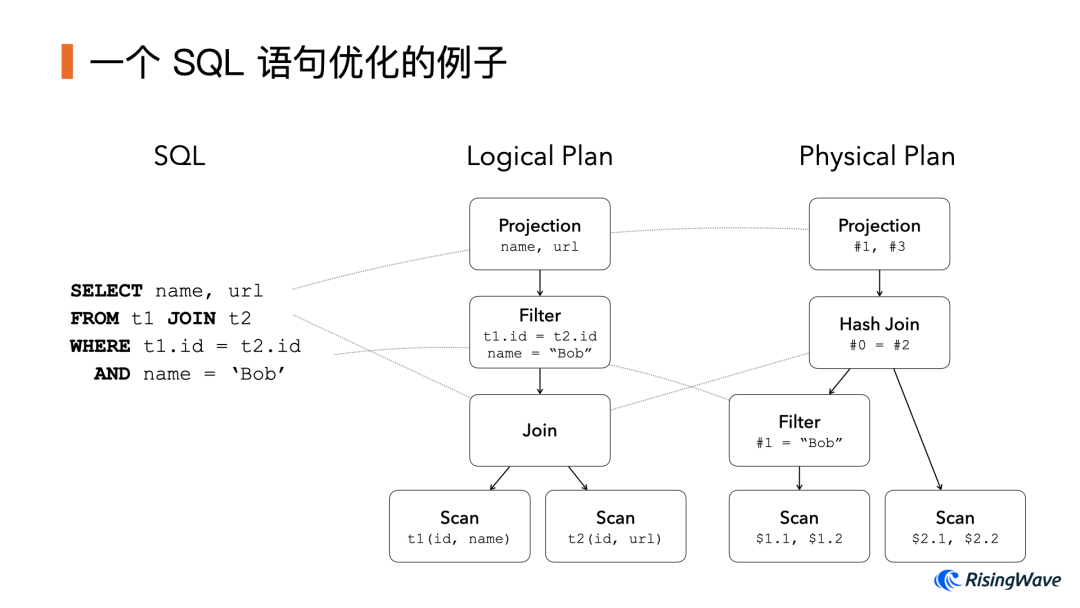
其中数据库对 SQL 语句的优化主要分为 基于规则的 RBO 和 基于代价的 CBO 两大类。它们都是要将计划中某种特定的模式(Pattern)转化为另一种模式。不同之处在于,RBO 假设重写之后的模式一定比之前的更优;而在 CBO 中我们需要根据统计信息估算每种模式的代价,最后从若干等价表示中选出代价最小的一种。
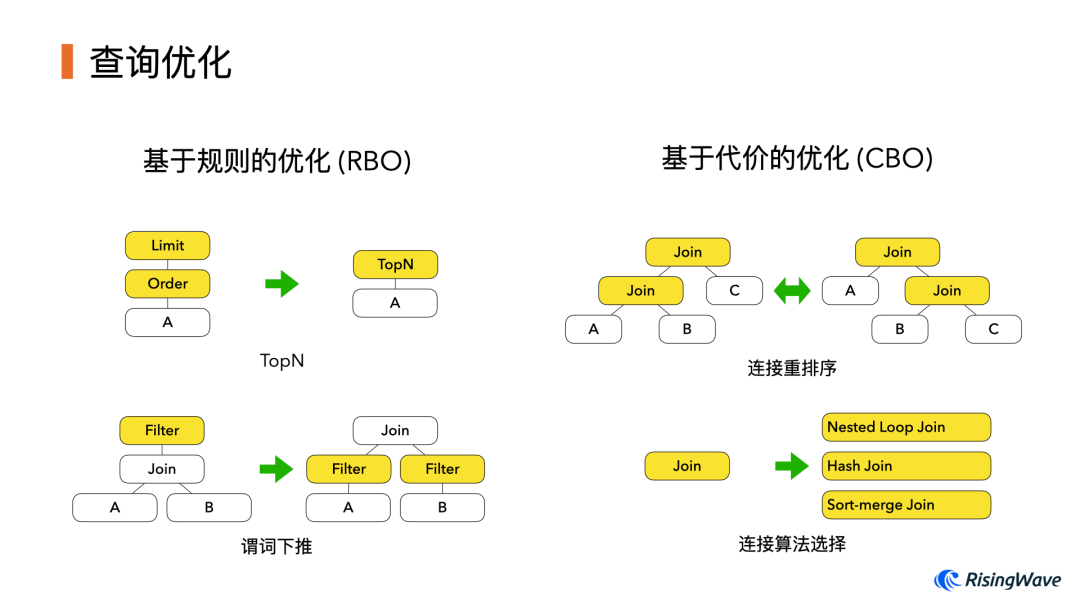
RisingLight 一开始采用了自己从头编写优化器的做法。但是随着时间推移,我们逐渐发现了它存在几个问题。

首先,尽管 Rust 中有模式匹配的 match 语法,但用它描述一个模式并不那么直观和流畅。其次,要对 struct 和 enum 组成的树形结构进行局部重写并不十分方便。最后,我们只实现了 RBO 而没有实现 CBO。因为 CBO 需要相对复杂的搜索策略、数据结构和动态规划算法。这需要一套完整的框架支持,而当时我们并没有足够的精力去实现它。
直到有一天我在 Rust 社区中了解到 egg 这个项目。看过它的网站介绍后,我立刻意识到这就是我一直在寻找的 Rust 优化器框架。
2egg 进行程序优化的基本原理
egg 项目主页上这张图非常清楚地展示了它的基本原理和优化过程。
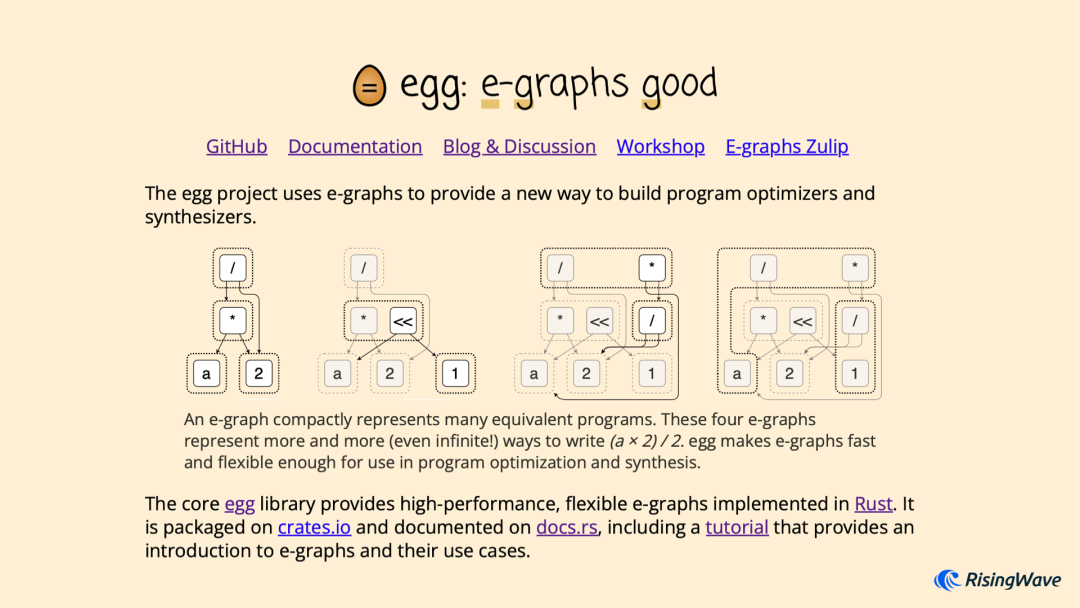
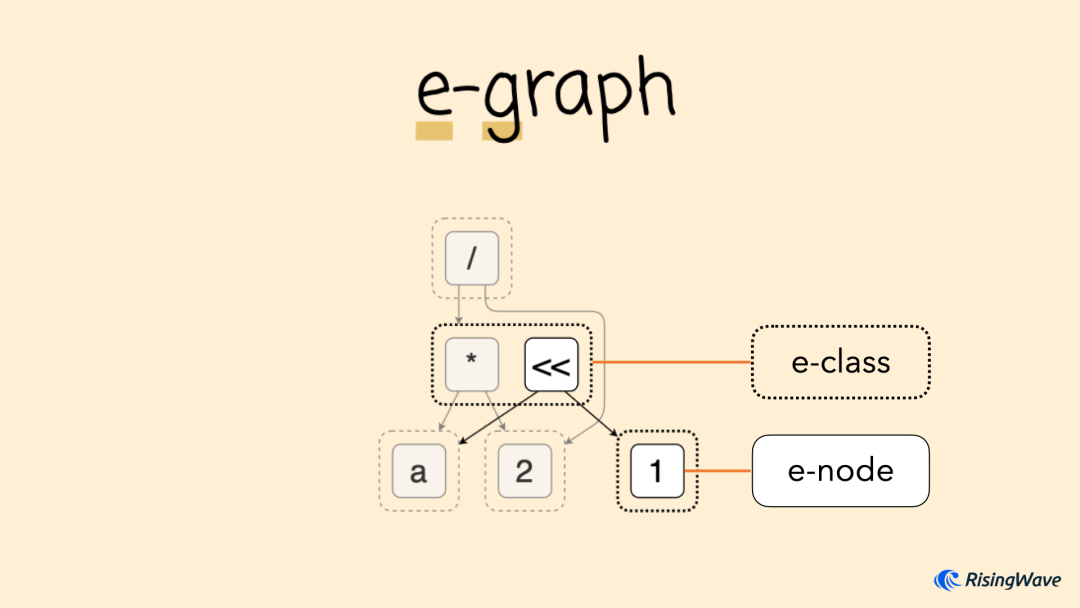
egg 中的核心数据结构叫做 e-graph。其中 e 是 equivalent 的缩写,也就是“等价“的意思。e-graph 在传统图结构的基础上,引入了 e-class 的概念。它是由若干个节点 e-node 组成的集合,表示这些节点在逻辑上是相互等价的。例如下图中的 a * 2
和 a << 1
,假设 a 是整型时这两个表达式等价,因此它们位于同一个 e-class 中。
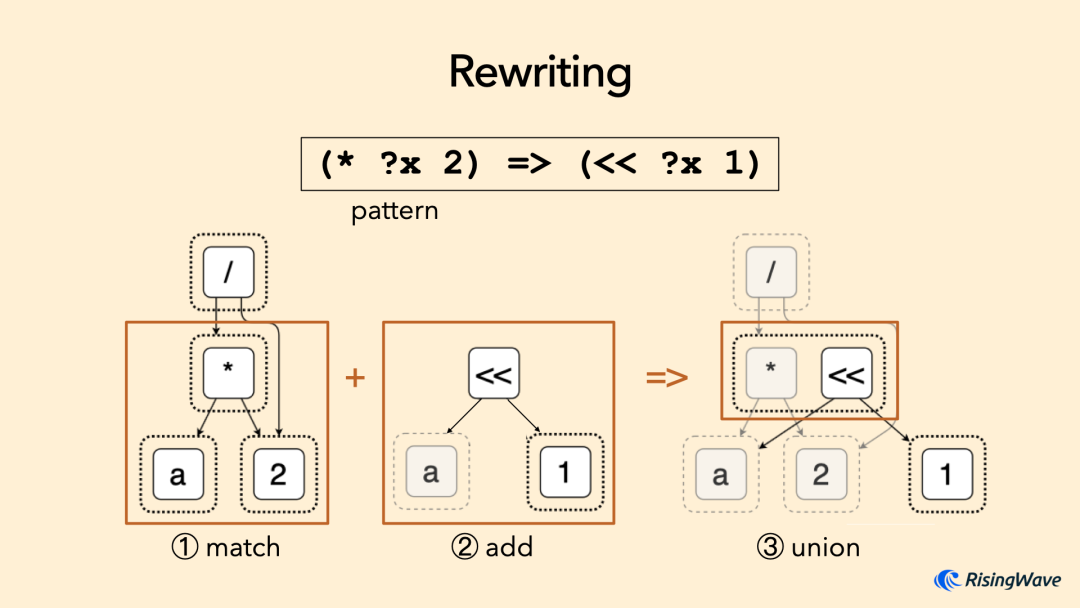
在 e-graph 上重写一个表达式的过程如下图所示。首先我们给定一个重写规则(Rule),它将左边的模式 (* ?x 2)
重写为右边的 (<< ?x 1)
,其中 ?x
表示匹配任意子树。egg 首先在原图中匹配左边的模式 ①,然后根据右边的模式插入新的子图 ②,最后将它们的根节点合并(union)起来 ③。这样就完成了一条规则的重写。
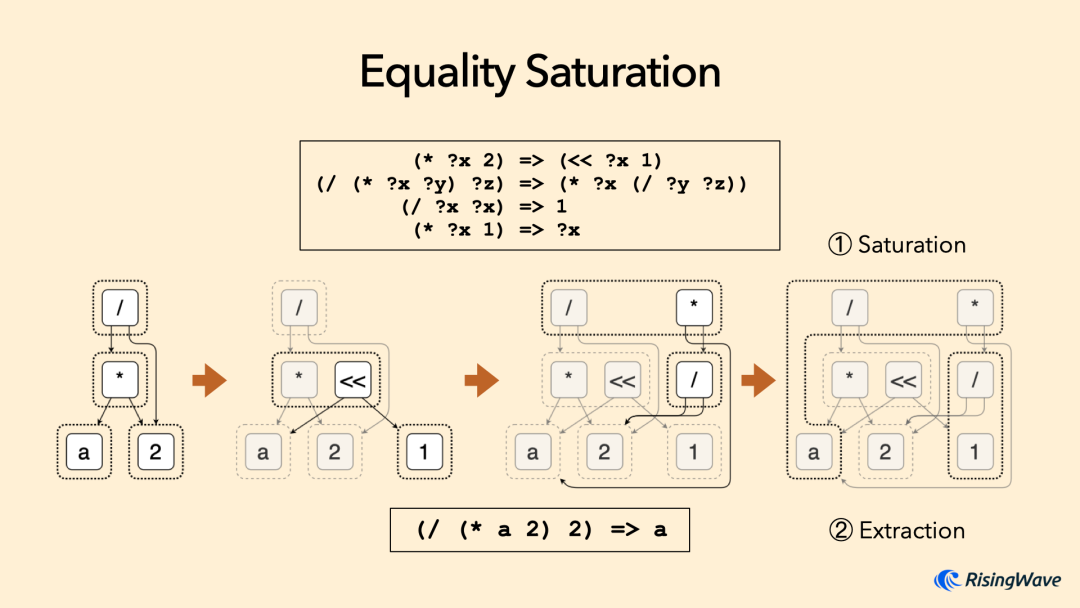
在实际优化中,我们会预先定义一系列的重写规则,并给定一个初始的表达式。egg 的做法就是不停地在图中尝试匹配各种规则并插入新的表达式,直到再也无法扩展出新的节点。我们称此时的状态为 Saturation ①,也就是饱和了。之后,egg 通过用户定义的估价函数(Cost Function)从所有可能的表示中找到代价最小的一种,作为最终的优化结果。这个过程就被成为 Equality Saturation。可以发现,这是一种基于代价的优化,因此天然适合实现 CBO 规则。
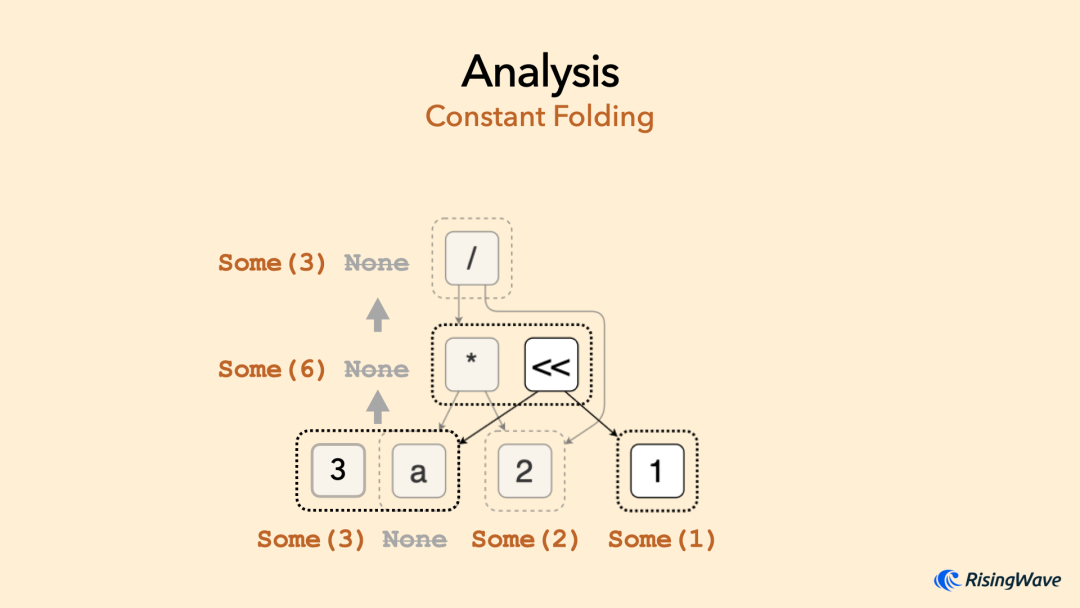
此外,egg 中另一个强大的功能是支持程序分析(Analysis)。它允许我们为每个 e-class 关联任意数据来描述它的某种属性。(可以思考一下为什么是关联 e-class 而不是 e-node。)例如,我们可以定义常量分析(Constant Analysis),为每个 e-class 关联一个 Option<Value>
来描述每个表达式是否是常数。在 e-graph 动态添加和合并节点的过程中,Analysis 也会随之更新。我们可以利用这点实现动态的常量传播和常量折叠优化。
3用 egg 实现 SQL 优化器的主要过程
下面我们来看看具体如何用 egg 来优化 SQL 语句。
使用 egg 的第一步是定义语言。egg 提供了 define_language!
宏包在一个 enum 外面,来定义每个节点的不同类型。

这里我们实现了四类节点,分别是:
值节点:表示一个常量或变量 list 节点:表示若干节点组成的有序列表 表达式操作:加减乘除等运算 SQL 算子:查询计划树的主节点
每个节点的具体规范定义在右边的注释中。需要说明的是,我们的语言直接描述查询计划而不是 SQL 语句,因此你会注意到其中的列名已经被 binder 转化为了 Column ID,例如$1.1
表示第一个表的第一个列。
定义好语言后,我们就可以通过类似 Lisp 的 S-expression 来简洁地描述一个表达式。egg 中使用 RecExpr
容器类型来存放表达式。它的内部其实就是节点的数组,后面的节点可以引用前面的节点,而最后一个是根节点。这种连续而紧凑的内存布局其实比递归的 Box 结构要高效不少。

接下来,我们继续使用 egg 特色的模式匹配语言来定义规则。首先是表达式化简,这些是各种语言都要实现的基础规则,egg 官方也给出了很多例子。相信大家一眼就能看懂,非常直观。

类似的,对于 SQL 算子也有这样的简单规则。例如合并两个相邻的相同算子、交换两个算子顺序、消除无效算子等等。这里我们引入了 (empty)
节点来描述一个没有输出的算子。

下面我们来看一个不那么 trivial 的优化。这是一个经典的 RBO,称为谓词下推。如下图所示,我们希望将 Filter 算子推到 Join 算子的下面。这样 Filter 就会被更早执行,从而减少要处理的数据量。
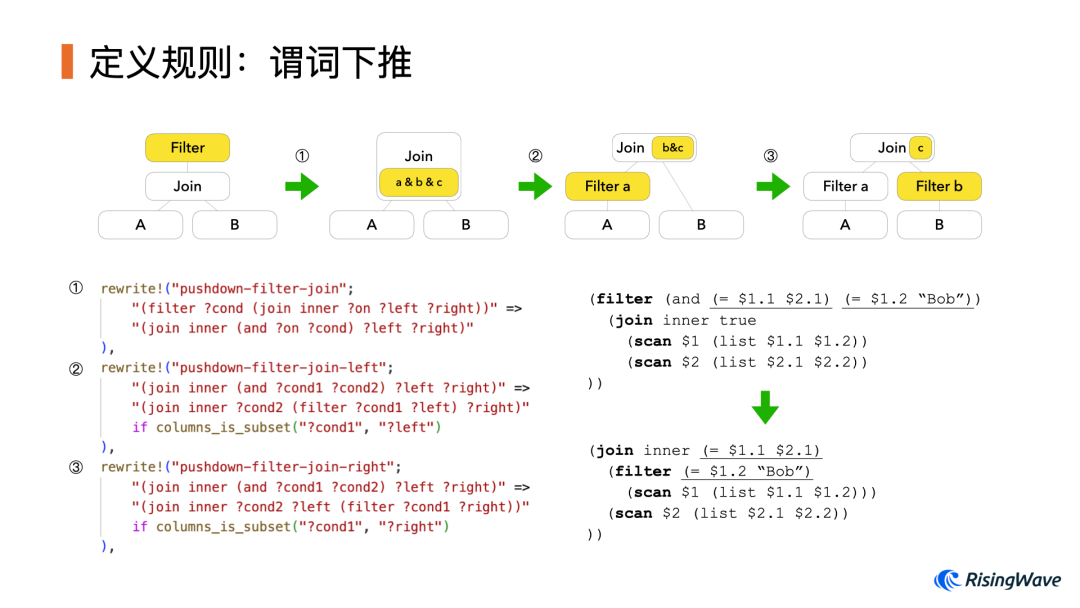
这个优化的难点在于,Filter 上的谓词表达式存在不同的情况:
↙️ 谓词只包含来自左表 A 的列,可以下推到左子树中 ↘️ 谓词只包含来自右表 B 的列,可以下推到右子树中 ⏹️ 谓词同时包含左右两表 A 和 B 的列,因此无法下推
我们定义了三条规则来实现这个优化:① 首先将 Filter 上的谓词下推到 Join 的条件上,然后 ②③ 分别判断每个谓词是否能够下推到左边或右边。
这里我们使用条件重写(if
)功能,并引入了 columns_is_subset
函数来进行判断。
要实现这个函数,我们还需要引入一个分析,称为 Column Analysis。类似经典的活跃变量分析,它会为所有表达式节点关联其中用到的所有列,并为所有算子节点关联它的输出中包含的所有列。这样我们只需判断”表达式的集合是否包含于算子的集合“,就能决定能否下推。

最后我们来看 CBO。一个最为经典的优化是 连接重排序(Join Reordering)。当我们有多个表进行连接的时候,它们的连接顺序就会对性能产生非常大的影响。此外,实际中大部分连接都是作用在主键上的,对于这类等值连接可以使用 HashTable 进行优化,相比原始的嵌套循环连接(Nest Loop Join)在计算复杂度上可以降低一个数量级。因此这两个优化对于多表查询至关重要。
在实现中,我们使用规则 ① 完成对 Join 子树的右旋。它作用于初始的左深树(Left-deep tree)可以遍历所有可能的组合。然后我们定义规则 ②③ 来匹配等值连接的模式,并将这样的 Join 转换为 HashJoin。这些规则共同作用下,对于多表连接就可以产生大量的组合方式。
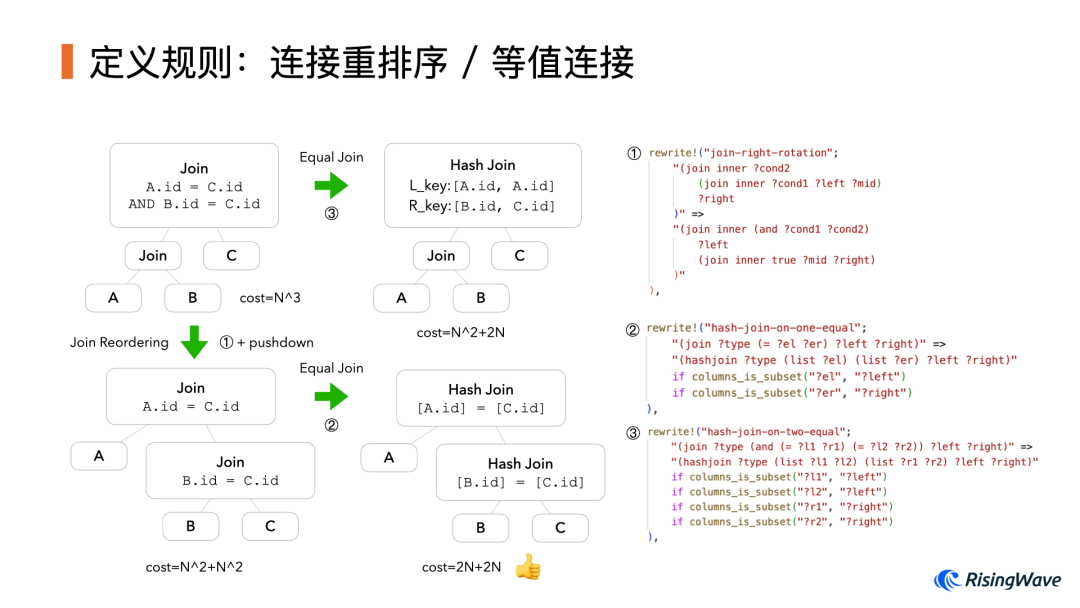
最后我们还要定义估价函数(Cost Function)才能让 egg 在大浪淘沙中找到真正最优的方案。实现起来并不复杂,整个函数的全部代码都已经贴在右边了。但是,实际调试起来还是颇费了一番工夫。因为任何一处疏漏都可能导致 egg 无法找到期望的最优结果,而你却很难知道是哪一步算错了。

这里 egg 最大的问题在于,它并不支持启发式搜索。在应用规则的过程中,它并不会根据估价函数进行剪枝,而是尽可能扩展出全部表示后再一步找到最优解。(还记得 Equality Saturation 的本意么。。)这导致规则多了以后,egg 对于稍微复杂一点的查询都会出现组合爆炸问题,无法在有限时间内给出合理结果。对此,我们采用了手动分阶段优化和多轮迭代的方式来缓解这个问题。

以上就是我们使用 egg 实现 SQL 优化器的主要技术点。使用 egg 重构后的新版查询引擎整体工作流程如下图所示:
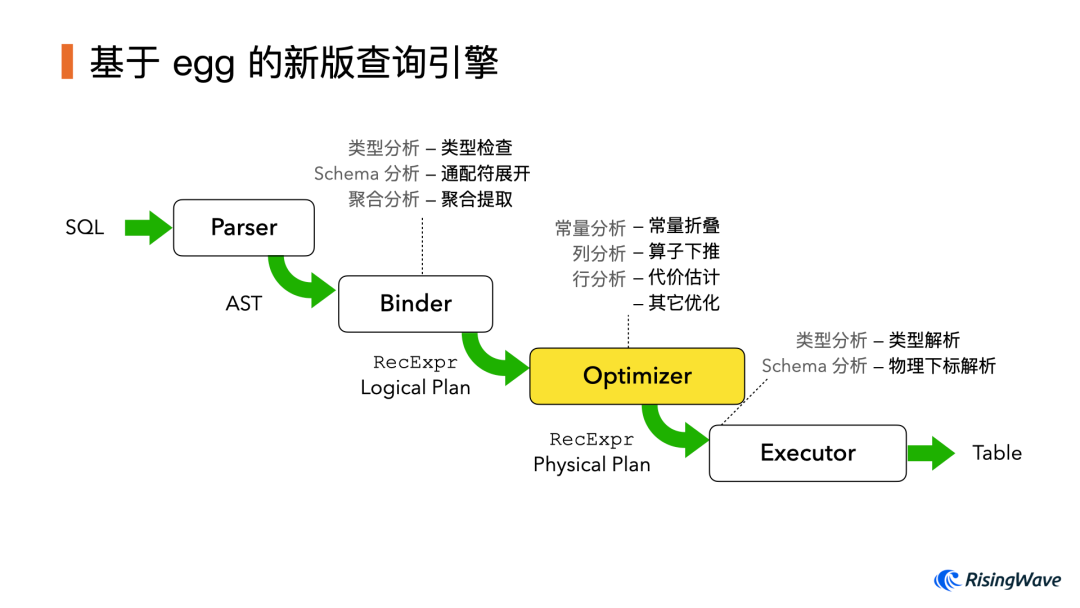
除了优化器本身以外,在它前后的 Binding 和生成 Executor 阶段,我们也利用了 egg 的 Analysis 功能来对查询计划进行必要的分析和处理。整个表达式和查询计划也深度依赖 egg 的数据结构进行表示。
4评估和分析
RisingLight 使用 OLAP 领域经典的 TPC-H 进行基准测试。这里我们选取其中的 Q5 来检验新版优化器的表现。Q5 包含 6 个表的连接,对优化器有很大考验。我们的优化器花了 39ms 进行优化,之后用 1s 时间执行。而相比之下 DuckDB 分别只用了 5ms 和 15 ms。这说明我们的原型系统距离业界一流水平仍有很大差距。

具体拆解每个优化的效果和贡献:
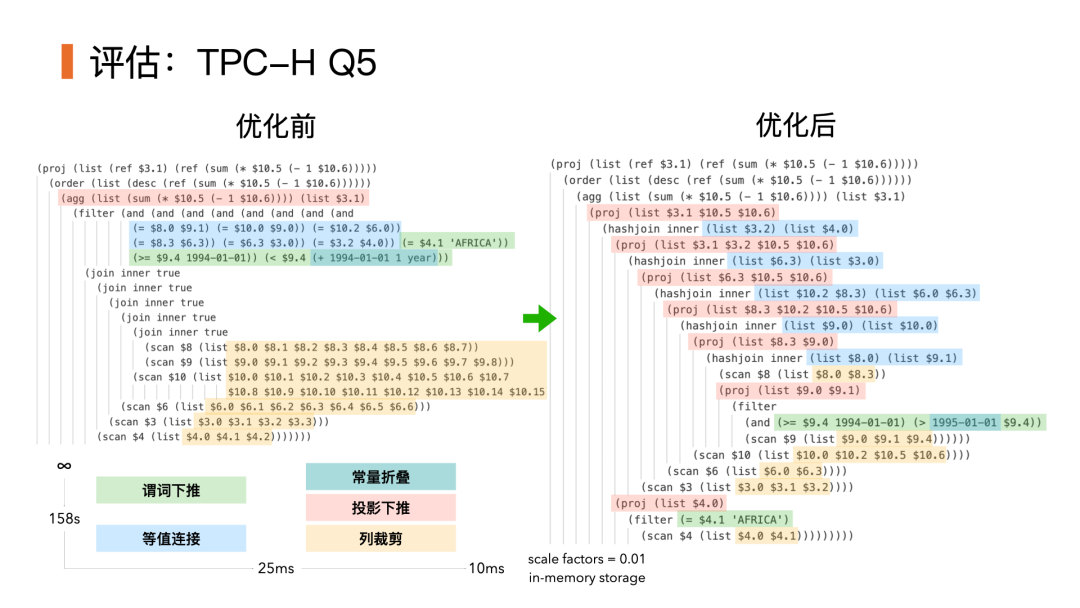
我们可以看出在优化之前这个查询基本是不可做的。谓词下推大幅削减了数据量,而后 HashJoin 进一步大幅降低了计算复杂度,最后投影下推和列裁剪(本文中没有提及)也进一步消除了未使用的数据。
最后我们来总结下 egg 的好处和不足:

egg 最大的优势在于它引入了一套 DSL 来简单、直观、优雅地描述优化规则,将编写规则的复杂度降低到了难以置信的程度。同时配合 Rust 语言也有能力描述复杂逻辑。有意思的是,这届大会上我们都在宣扬 Rewrite Everything In Rust!可我这边却是在 Rewrite Rust in Lisp。这说明虽然 Rust 是很好的语言,但它不是万能的语言。在做 PL 相关的时候还是用正统的 PL 语言更合适。
正由于它简单,因此 egg 非常适合快速开发原型系统。我当时从知道 egg 到用 egg 重新实现完整个优化器只用了一周时间,代码也只有一千多行。我觉得用在 RisingLight 这种教学项目中是非常合适的。当然必须要说明的是,我之后又花了两周多时间将它整合到 RisingLight 的 pipeline 里。其实要将现有项目迁移到 egg 还是需要一番彻底重构的。
下面来谈谈它的问题。这也是我们目前还不考虑在 RisingWave 中使用它的原因。
首先,egg 是一个天然的 CBO 框架,它对纯 RBO 的场景并不友好。这体现在你必须要给一个 Cost Function 才能真正拿到最终的优化结果。它并没有提供一个方法在应用一条规则后把原来的表达式删掉。当然,有一些 hack 可以做到,而且理论上也可以抛开它的 Runner 自己实现一个 RBO 专用的。因此这里是有改进空间的。
第二,它没有启发式搜索。这导致它面对复杂查询容易出现组合爆炸问题,无法在有限时间给出最优结果。当然,我们也提到了可以手动多轮迭代来缓解这个问题。
还有一点比较 tricky 的是,egg 实际上是个动态类型系统。注意到我们所有类型的节点都定义在同一个 enum 中,因此在 egg 看来各种节点的组合都是合法的。我们并不能规定说表达式节点的孩子只能是表达式。这就导致一旦规则写错,比如参数顺序写反了,这种情况就很难 debug。

最后再分享一些前沿进展。egg 是华盛顿大学一个 PL 研究组的作品。他们今年开发了 egg 的后续项目,叫做 egglog。顾名思义,就是将 egraph 和 datalog 缝合起来,看起来非常 fancy。但是,egglog 进化成了一门纯语言,而不再是 Rust 库了。因此我们可能很难在 Rust 项目中继续集成 egglog,不过它仍然值得我们进一步的探索和尝试。
5总结
本文介绍了 egg 这个程序优化器框架,以及我们用它在数据库中实现 SQL 优化器的经验。如果你对这些内容感兴趣,欢迎访问 RisingLight[3] 了解更多细节,或是从 sql-optimizer-labs[4] 开始亲手实现自己的 SQL 优化器!
6References
完整录像: https://www.bilibili.com/video/BV1aa4y1c78Y
[2]文章: https://zhuanlan.zhihu.com/p/596119553
[3]RisingLight: https://github.com/risinglightdb/risinglight
[4]sql-optimizer-labs: https://github.com/risinglightdb/sql-optimizer-labs

