




 点击蓝字,关注我们
点击蓝字,关注我们
▍作者:庞同学,TuGraph 社区开源贡献者
本文介绍了来自中国科学技术大学的 TuGraph 社区开源贡献者庞同学的工作 Awesome-Text2GQL。
仓库链接:TuGraph-family/Awesome-Text2GQL
引言
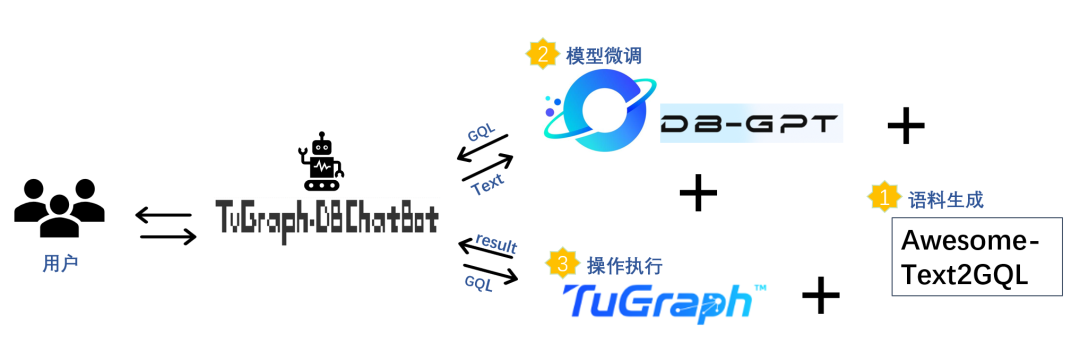
在上一篇文章 Awesome-Text2GQL 中我们已经详细解读了 Awesome-Text2GQL 语料生成框架的设计目标、实现原理和语料生成的能力,在本文中,我们将结合 Awesome-Text2GQL 的使用方法带领大家从0开始构建一个 GQL 语料数据集,使用生成的数据集基于 DB-GPT-Hub 的微调能力训练一个 Text2GQL 模型,最终搭建一个 ChatBot 实现与图数据库 TuGraph-DB 的对话。
Awesome-Text2GQL 回顾
在最开始,我们还是简要回顾一下 Awesome-Text2GQL 框架的内容。
Awesome-Text2GQL 是一个面向自然语言到图数据库查询语言任务的语料生成框架,框架具备问答对语料生成(一个问答对包括 Question 自然语言部分和 Query 数据库查询语言两部分)、语料泛化的能力,也支持进一步结合 DB-GPT-Hub 和 TuGraph-DB 构建 ChatBot 应用。

图1 Awesome-Text2GQL 框架总览
Text2GQL 任务的每条语料是一个问答对,主要由两部分组成:
Question:人类可阅读的自然语言,表明数据库操作人员的操作意图
Query: 查询语句 GQL(Graph Query Language)Query,图数据库可理解的查询语言
下面展示了一个问答对的示例:
MATCH (n {name: 'Carrie-Anne Moss'}) RETURN n.born AS born查找Carrie-Anne Moss的出生年份复制
整个框架由基于 Antlr4的语料生成模块和基于 LLMs 的语料泛化模块两部分组成,语料生成模块对输入的 Query 模板进行词法语法分析和语义分析,并结合 DB 实例的 schema 和数据来生成符合模板句式的 cypher 语句,也可以基于语义分析对 cypher 语句初步的翻译出对应的自然语言 Question。语料泛化模块基于阿里云百炼平台的 Qwen 推理服务构建,完成对语料对的 Question 部分的生成和泛化,满足在数据集构建过程中不同场景的语料生成和泛化需求。相较于其他构建 Text2GQL 语料数据集的方法,Awesome-Text2GQL 具有以下优势:
1、语料生成效率:在构建完成框架所需输入 Query 模板后,可以达到每十分钟每千条语料的生成效率,框架具有乘法增加能力,一条 Query 模板可以对应生成数十条到上百条语料对。
2、语料生成质量:生成的语料几乎不需要二次清洗。Query 部分在保证查询语句语法正确的基础上,具有明确的查询意图。Question 部分贴近自然语言表达。
3、泛化能力:语料生成框架可以便捷地迁移到新的 DB 实例上,从而扩展语料数据集以覆盖新的 DB 实例,可以很大程度上缓解模型在新的 DB 上迁移表现差的问题。
微调数据集
在正式开始使用 Awesome-Text2GQL 构建语料数据集之前,我们在这里也补充一些在大模型微调任务中构建高质量数据集的方法、原则和注意事项。
微调数据集构建步骤
构建微调数据集通常有一系列的步骤,包括数据收集、数据清洗和数据增强等。
数据收集:可通过已有的公共数据集、目标任务相关文档提取或者生成等方式来收集。
数据增强:目的是提高数据集的丰富性,对应 Awesome-Text2GQL 里的语料泛化功能,我们使用大模型来辅助完成。
数据清洗:在获得数据集后,需要进行数据清洗,去除噪声、重复和低质量的数据,并将其统一转化为可训练的格式。
高质量数据集的考虑要素
想要构建高质量的数据集,通常有以下几方面需要考虑。
数据质量:数据集的质量对于模型的微调至关重要,数据集中的每个数据样本都应具有明确的实际意义,以便模型能够较好地理解其含义。
微调数据集的规模:用于大模型微调的数据集的规模比预训练数据集小得多,典型的相比于几个 TB 的预训练文本数据,微调数据集的存储大小通常在几MB 到1GB 左右。
相似性:预训练模型已经具备一定的理解能力,过度的语料增强或泛化将被视作重复,尽管这不会降低微调的效果,但会增加额外的微调成本。表明微调数据在保证多样性的前提下,数据规模不需要很大也可以达到不错的效果。在我们的任务中,语料泛化可以增加语料的多样性,但是仍然不建议将泛化的倍数设置过高,2-5倍即可。
数据集划分:数据集通常会被划分为训练集、验证集和测试集,分别用于模型训练、训练时评估和超参数调整以及评估最终模型的性能,划分比例通常为7:1.5:1.5。数据划分时应当遵循随机原则,针对不同的数据来源,应当先分层划分。
使用Awesome-Text2GQL构造微调数据集
在这里我们从使用 Awesome-Text2GQL 的角度来展开如何构造一个微调数据集。大家可以参考我们仓库中的 README.md 文档来配置环境,项目由 Python 编写,推荐大家使用 Anaconda/Miniconda 等虚拟环境构建工具来配置环境。如果还想使用语料泛化模块中的功能,可以申请阿里云百炼平台的 Qwen API。
Pipeline
使用 Awesome-Text2GQL 生成语料首先需要构造语料 Query 模板,然后依次生成语料对的 Query 部分、生成语料对的 Question 部分、泛化语料和后处理生成数据集,对应下图中的步骤一到步骤四。
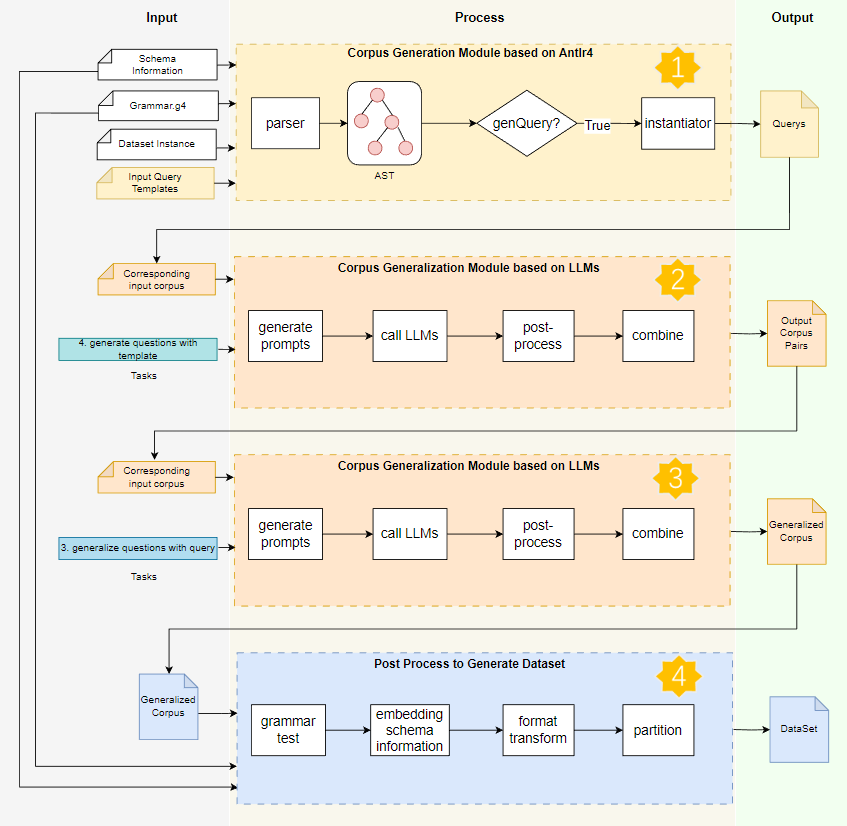
图2 Awesome-Text2GQL 语料生成工作流
框架中./scripts 文件夹中覆盖了完整 Pipeline 和各个功能独立运行的执行脚本,./input_examples 文件夹中覆盖了本框架中所有的功能的输入输出示例和格式。在配置环境完成后,可以一键执行以下命令,体验 Awesome-Text2GQL 全流程:
sh ./scripts/run_the_whole_flow.sh复制
以下四个步骤将会被串行执行:
1、生成Query:通过语料模块生成 Query 语句,输入为语料模板。
2、生成Question: 通过基于LLMs的语料泛化模块生成 Query 对应的 Question 语料,输入为上个步骤中生成的 Querys,输出为语料对。
3、语料泛化:对上一步生成的语料进行泛化。
4、后处理:将上述步骤生成和泛化的语料进行语法测试、嵌入数据库 Schema 信息并转换为训练格式的语料。
构造输入模版
下图所示是一个输入模板的示例,一条输入模板也是由 Question-Query 语料对组成。

图3输入模板示例
在初始模板构建时,可以从 TuGraph-DB的测试文档和 README 文件中提取初始 Query,然后通过手动标注 Question 或使用框架中的直接根据 Query 生成 Question 的功能。
控制台指令:
sh ./scripts/gen_question_directly_llm.sh复制
可以修改脚本中指明的输入文件的内容,替换为你想要用于制作模板的 Query 语句。

Awesome-Text2GQL 目前支持的语法算子有 MATCH、CREATE、MERGE、ORDER BY、LIMIT、SKIP、OPTIONAL、多跳匹配模式等常用算子,目前在 WHERE、UNION、WITH 等算子的支持上还存在缺陷,欢迎大家参与贡献!
生成Query
语料生成模块在生成 Query 时,首先将解析出 AST 的匹配模式,如()-[]->(),也就是节点间以及节点和边之间的连接关系,然后进一步查找 Schema 中符合上述匹配模式的节点和边,最后在 Schema 对应的数据库实例中取出相应的节点和边的数据,对 AST 进行实例化批量得到多条 Query。
在实例化时可以以一定的小概率扩展简单的 AST 分支如 OPTIONAL、SKIP、LIMIT,来丰富 Query 的形式。这种 Query 生成策略可以保证生成的查询语句在数据库实例中一定可执行,符合生成意图(不会生成出跟模板相差很大的 Query),且相对具有一定的多样性。
控制台指令:
sh ./scripts/gen_query.sh复制
输入:一对或多对语法正确的语句模板,需人工构造
MATCH (n {name: 'Carrie-Anne Moss'}) RETURN n.born AS born查找Carrie-Anne Moss的出生年份复制
输出:批量生成的多条 Query 语句,这些语句与 Query 模板具有相同或扩展的 AST。

生成 Question
根据输入成对的 Query 和 Question 语料组成的模板,理解相同句式的 Query 的含义,并生成 Query 对应的 Question。通过给大模型提供相同句式的模板,来帮助大模型理解某类 Query 语句更高层次的语义信息,而不是仅仅依靠预训练基座模型以前学习的图数据库查询语言的信息。
控制台指令:
sh ./scripts/gen_question_with_template_llm.sh复制
输入:作为模板的 Query 与 Question,以及与模板 Query 对应的多条相似 Query,输入可以来自生成 Query 步骤的输出,也可以人工构造

输出:成对的 Query 与 Question

泛化
sh ./scripts/generalize_llm.sh复制


后处理
数据集的后处理的步骤包括但不限于数据的进一步清洗、Query 语法检查、数据格式转换和数据集划分。
{"db_id": "yago","instruction": "我希望你像一个Tugraph数据库查询语句编写专家一样工作,你只需要返回给我任务对应的cypher语句。下面是一条描述任务的指令,写一条正确的response来完成这个请求.\n\"\n##Instruction:\nyago包含节点Person、City、Film和边HAS_CHILD、MARRIED、BORN_IN、DIRECTED、WROTE_MUSIC_FOR、ACTED_IN。节点Person有属性name、birthyear、phone。节点City有属性name。节点Film有属性title。边BORN_IN有属性weight。边ACTED_IN有属性charactername。\n\n","input": "查询所有人的最小年龄是多少?","output": "MATCH (n:Person) RETURN min(n.age)","history": []},复制
sh ./scripts/generate_dataset.sh复制
数据集划分
模型微调
模型评估
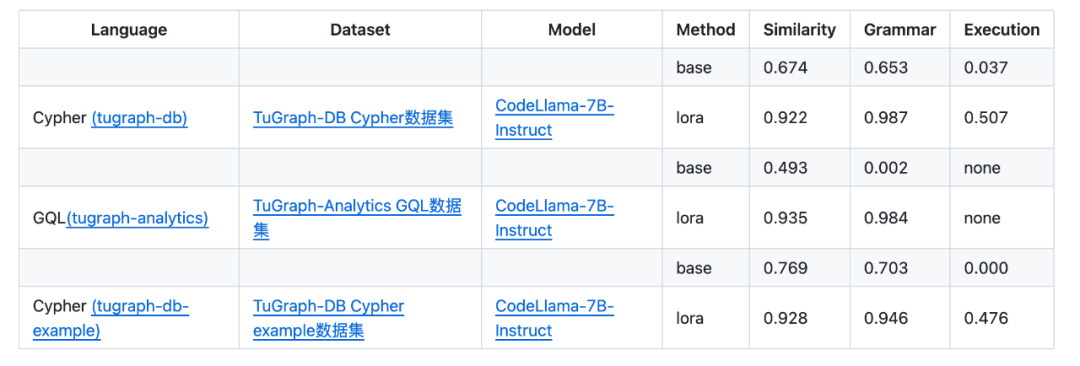
对于读者自行训练的模型,如果想要评估模型翻译准确度,DB-GPT-Hub 的 DB-GPT-GQL 子项目同样提供了语句相似度、语法正确性、执行结果一致性三种评估方式,TuGraph 团队公布的微调模型的翻译准确度评估结果已经在 DB-GPT-Hub 上列出 ( https://github.com/eosphoros-ai/DB-GPT-Hub/blob/main/src/dbgpt-hub-gql/README.zh.md )
Demo搭建
硬件资源: 我们在 CodeLama-7B-Instruct 预训练模型上进行基于 LoRA(Low-Rank Adaptation) 的低参微调,以下是实测的硬件资源: 硬盘资源:系统盘110G 及以上,最低需求为系统盘40G+数据盘60G(需要将模型下载到数据盘,默认下载到系统盘) 软件环境: TuGraph-DB 的 server 端依赖 python3.6,而 DB-GPT 依赖 python3.10,因此我们需要同时用到 TuGraph-DB 的 runtime 和 compile 这两个镜像。更换 compile 镜像中 python 版本为3.10并编译得到 TuGraph-DB 的 client 端,之后在 runtime 镜像中搭建整个项目。 搭建步骤:
在你的服务器上安装 Nvidia Docker,确保你可以在 Docker 中使用 GPU。 在 Compile 镜像中更换 Python 和 Cython 版本并编译 TuGraph-DB 获得 RPC client 端的动态链接库。 生成数据集或直接拷贝微调数据集、TuGraph-DB ChatBot 代码和上一步骤中编译的动态链接库至 runtime 镜像。 配置 DB-GPT-GQL 软件环境,下载预训练模型并开始微调。 向 TuGraph-DB 中导入数据。 启动 TuGraph-DB server 端。 最后启动 TuGraph-DB ChatBot 即可开始跟数据库对话啦!
·END·

欢迎关注TuGraph代码仓库✨
https://github.com/tugraph-family/tugraph-db
https://github.com/tugraph-family/tugraph-analytics



