




本文对阿里巴巴集团李飞飞等人撰写的2024SIGMOD论文《PolarDB-MP:A Multi-Primary Cloud-Native Database via Disaggregated Shared Memory》进行解读。全文共约4231字,预计阅读时间约为20至30分钟。
数据库设计的核心矛盾在于 ACID 保证与性能/扩展性的平衡,而 PolarDB-MP 的背景正是针对这一矛盾提出的解决方案。传统云原生数据库(如 AWS Aurora、PolarDB)采用主从架构,写操作集中于单一主节点,在写密集型负载下受限于计算和存储资源,且扩展性只能通过纵向扩展实现,依赖物理机资源。这在云计算环境中受限于资源竞争(如 vCPU 分配),故障切换还可能导致短暂停机,影响高可用性。共享无(shared-nothing)架构(如 TiDB、CockroachDB)通过数据分区实现水平扩展,但跨分区事务需要两阶段提交(2PC)等分布式事务机制,带来显著延迟和复杂性,难以应对高吞吐量 OLTP 负载,这也是 Spanner 等系统引入复杂一致性协议的原因。传统共享存储(shared-storage)架构(如 IBM pureScale、Oracle RAC)支持多节点读写,但依赖昂贵的分布式锁管理和高网络开销,部署在专用硬件上,缺乏云环境的灵活性,总拥有成本(TCO)高,不适应现代 DBaaS 需求。新兴多主方案如 Aurora Multi-Master(Aurora-MM)采用乐观并发控制,在低冲突场景下高效,但在高冲突下事务中止率高,增加应用层复杂度;而 Taurus-MM 使用悲观并发控制,依赖页面存储和日志回放,缓存一致性开销大,8 节点仅提升 1.8 倍吞吐量,暴露了共享存储系统中同步的传统痛点。
单主云原生数据库(如 Aurora、Hyperscale、Socrates)通过分离存储实现容错和一致性,添加副本无需额外存储,但写性能受限,且无法通过横向扩展解决,纵向扩展又受物理机资源约束。云提供商虽可动态分配资源,但在资源紧张时(如多实例共享机器),扩展受阻,迁移到新机器则需停机。共享无架构在分布式计算和数据库中广泛应用,通过独立节点消除单点故障,但跨分区事务的 ACID 保证需高效同步,现有优化(如局部分区、推测执行)虽缓解问题,却增加用户设计复杂性,且数据重分区耗时。共享存储架构则需全局协调(如锁管理器和 TSO),传统系统(如 IBM pureScale)因网络和锁开销效率低,而 Aurora-MM 和 Taurus-MM 的日志同步和高中止率问题仍未解决。MVCC(多版本并发控制)在现代数据库中普及,但多主场景下数据可见性判断需全局事务信息,同步开销大,这也是现有系统未彻底解决的难题。
技术挑战在于如何在多主架构中实现高效的全局事务协调、缓存一致性和并发控制,同时避免分布式事务的复杂性,并利用现代硬件(如 RDMA)降低网络瓶颈。RDMA 的低延迟和高带宽已被分布式系统(如 FaRM)验证,其在 Alibaba 云基础设施中的普及为 PolarDB-MP 提供了技术前提。PolarDB-MP 旨在通过引入分离式共享内存,结合共享存储和 RDMA 网络,解决这些问题,提供高性能、可扩展的多主数据库方案,试图在硬件加速与软件架构间找到平衡点,或将成为下一代云原生数据库的标准范式。
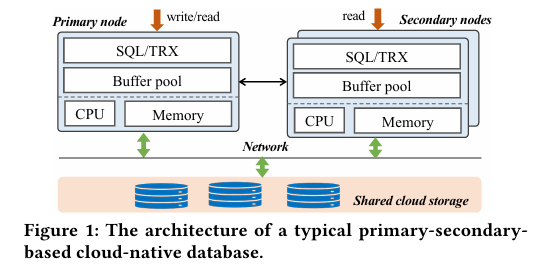
图 1 典型主从云原生数据库架构
PolarDB-MP 是一种基于分离式共享存储和共享内存的多主云原生数据库,其架构(图 2)继承自 PolarDB 的存储分离设计,新增共享内存层,通过 Polar Multi-Primary Fusion Server(PMFS)协调多主节点。这种“存储 + 内存”分离的混合模型在云原生领域较为新颖,与 Aurora 的日志分离或 Spanner 的分布式存储相比,其目标是通过共享内存提升协调效率。所有节点平等访问数据,支持读写请求,无需分布式事务,这一设计避免了 Paxos 等协议的协调开销,直指多主数据库的理想目标,尽管一致性保证的严格性仍需评估。存储层使用 PolarStore 和 PolarFS,但兼容其他共享存储方案,体现了模块化设计的通用性,尽管与非阿里系存储的集成成本值得关注。
核心组件 PMFS 包括 Transaction Fusion(事务协调)、Buffer Fusion(缓冲管理)和 Lock Fusion(锁管理),基于共享内存实现,类似于分布式系统的控制平面,负责全局事务和缓存一致性,其单点故障风险和大规模集群适应性是关注的重点。节点与 PMFS 间的通信使用单边 RDMA 或 RDMA-based RPC,确保低延迟,RDMA 的应用是亮点,其在高性能计算中的优势已被熟知,但在普通网络环境下的可行性需验证。高可用性通过写前日志同步到备用集群实现,保障跨区域容错,这一标准 HA 手段可靠,但同步延迟和跨区域一致性策略的细节尚待补充。PolarDB-MP 的目标是提供高性能、高可扩展性和高可用性的多主云原生数据库,特别针对写密集和高冲突场景,契合云原生趋势,可能成为 DBaaS 的潜在竞争者,替代现有方案(如 MySQL 集群)并降低 TCO。
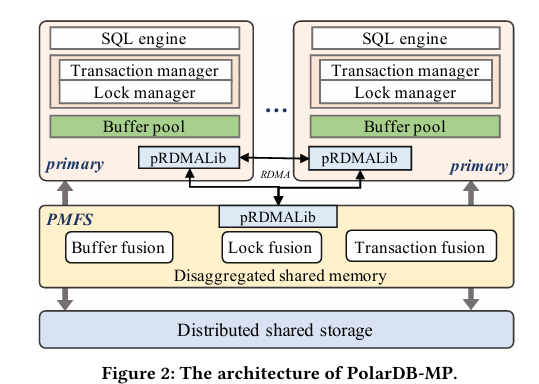
图 2 PolarDB-MP 架构
PolarDB-MP 的技术创新集中在 PMFS 和 LLSN,通过共享内存和 RDMA 解决多主数据库的协调难题。PMFS(Polar Multi-Primary Fusion Server)分为三层,类似分布式系统的分层解耦设计,通过共享内存将事务、缓冲和锁管理高效结合:
Transaction Fusion:负责全局事务排序和可见性管理,支持 MVCC(现代数据库如 PostgreSQL 的标配)。其核心是时间戳 oracle(TSO)分配提交时间戳(CTS),通过分布式事务信息表(TIT)去中心化存储元数据。每个节点维护本地 TIT,其他节点通过 RDMA 远程访问,避免集中式事务管理器的高延迟。TIT 的 RDMA 友好设计(固定槽位 + 版本号)借鉴了分布式键值存储的元数据管理思路,确保高效访问,与 Spanner 的 TrueTime 类似但延迟更低,尽管 TIT 规模扩展时的内存开销需关注。
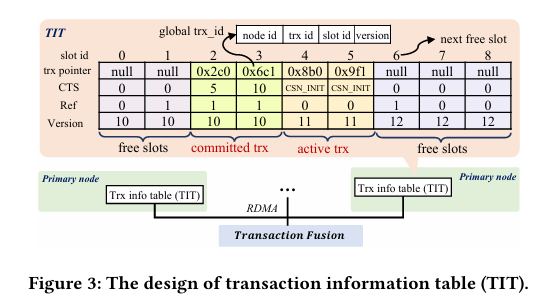
图 3 事务信息表(TIT)设计
Buffer Fusion:提供分布式共享缓冲池(DBP),维护缓存一致性,相比 Taurus-MM 的日志回放,直接共享页面数据减少 I/O 和 CPU 开销。节点将修改后的页面推送到 DBP,其他节点从中拉取最新版本,利用共享内存和 RDMA 实现快速同步。这一方法比传统缓存(如 PostgreSQL 的共享缓冲区)更适合多节点共享,可能成为性能提升的关键,但高写负载下的带宽需求需验证,类似内存数据库(如 Redis)的优化。
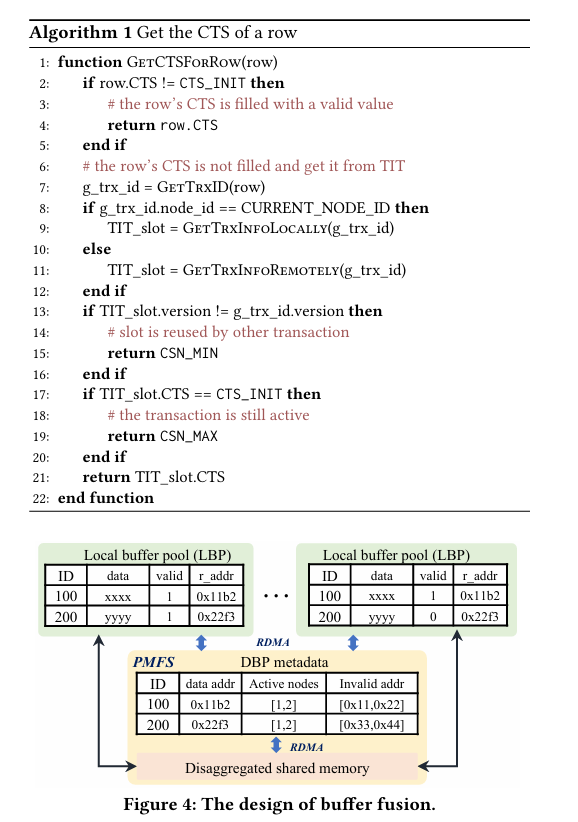
图 4 Buffer Fusion 设计
Lock Fusion:实现跨节点并发控制,页面锁(PLock)确保物理一致性,行锁(RLock)维护事务一致性。PLock 通过懒释放优化频繁访问,RLock 嵌入行数据减少消息开销,利用共享内存和 RDMA 降低锁冲突开销。懒释放类似操作系统缓存策略,嵌入设计与 MySQL InnoDB 的锁实现相比更简洁,分布式锁管理的去中心化降低了传统方案(如 Oracle RAC)的网络瓶颈,但高冲突下的锁等待时间值得关注。
LLSN(Logical Log Sequence Number)为多节点写前日志建立部分顺序,确保同一页面日志按生成顺序应用。每个节点维护本地 LLSN,更新页面时记录并递增,PLock 保证顺序更新,日志按生成顺序持久化。部分顺序设计借鉴了分布式系统中的因果一致性(如 Raft 的日志序列),避免全局排序,简化恢复复杂度,优化了多主日志管理的传统痛点,但在日志量激增时的表现需验证。RDMA 的深度集成是硬件与软件协同设计的典型案例,提升了性能潜力,但也增加了架构复杂度。
PolarDB-MP 的设计与实现细节体现了工程上的细致优化:
事务融合(Transaction Fusion):TIT 包含指针、CTS、版本号和引用计数,节点通过 g_trx_id(全局事务 ID)远程访问,MVCC 可见性基于 g_trx_id 和 CTS 判断。TIT 结构紧凑,类似内存数据库的事务元数据,RDMA 的单边操作使其在高并发下保持低延迟,可能优于传统网络 RPC。TIT 槽位回收由后台线程根据全局最小视图执行,这一机制常见于内存管理(如 JVM GC),但对事务活跃度的影响需评估。
缓冲融合(Buffer Fusion):每个节点有本地缓冲池(LBP),与 DBP 协同,页面元数据新增 valid 和 r_addr 字段,跟踪页面状态。LBP 和 DBP 的协作类似多级缓存,更新页面时推送到 DBP,未命中时从 DBP 或存储读取,推送机制减少拉取延迟,但在高写负载下的带宽占用需验证。
锁融合(Lock Fusion):PLock 为节点级锁管理,懒释放减少 RPC 开销,冲突时通过协商消息协调,优化了局部性,但协商机制可能导致锁饥饿。RLock 嵌入行数据,仅在 Lock Fusion 维护等待关系,仅支持独占锁,读请求依赖 MVCC,简化了锁管理,但不支持共享锁可能限制某些事务模式。
日志与恢复:采用 ARIES 风格日志,节点独立维护 redo 和 undo 日志,这一工业标准可靠,但多节点日志的同步开销需关注。恢复时分批读取日志,按 LLSN 顺序应用,避免全量排序,降低了内存需求,可能比 MySQL 的 binlog 恢复更快。
这些细节展示了 PolarDB-MP 对高并发 OLTP 负载的针对性优化,TIT 和 DBP 的分布式设计避免了单点瓶颈,锁机制的简化和 RDMA 的使用提升了效率,但极端冲突场景下的健壮性仍需验证。
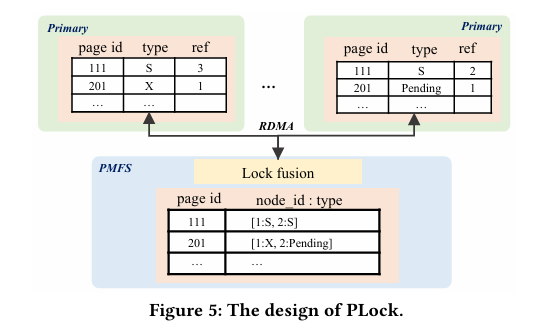
图 5 PLock 设计
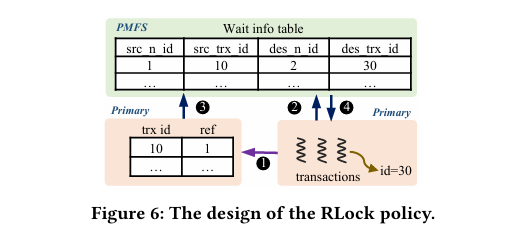
图 6 RLock 策略设计
PolarDB-MP 的性能评估在高端环境(Intel Xeon 8369B,1TB DRAM,100Gbps RDMA 网络)下进行,配置为 8 vCPU/32GB 实例,24GB 缓冲池,读提交隔离级别,这一常见设置具代表性,但普通硬件上的表现需关注:
基准测试:SysBench 显示读写负载下 8 节点 100% 共享数据吞吐量提升 5.4 倍,写负载提升 3 倍,高冲突场景下的显著提升归功于共享内存和 RDMA,避免了日志同步开销,可与 MySQL 集群对比验证优越性。TATP 因分区良好实现线性扩展,低冲突特性突出其扩展性,但更复杂负载的表现需验证。TPC-C 在 32 节点(1024 vCPU)达 910 万 tpmC,28 倍单节点性能,大规模集群的高吞吐量令人印象深刻,但在跨仓库事务中的一致性需评估。生产负载近线性扩展,冲突少,验证了实用性,但高冲突生产案例仍待补充。
对比分析:与 Taurus-MM 相比,8 节点读写吞吐量高 3.17 倍,写负载高 4.02 倍,可扩展性远超(5.64 vs. 1.88),共享内存优势明显,但 Taurus-MM 数据的可信度需验证。与 Aurora-MM 在低冲突(10% 共享)场景下对比,Aurora-MM 4 节点无提升,PolarDB-MP 更优,暴露了乐观控制的局限,全面对比尚待补充。GSI 更新比共享无数据库(如 TiDB)高数倍,因无需两阶段提交,是 OLTP 的关键优势。
恢复性能:两节点测试,节点崩溃后另一节点无影响,恢复仅需 10 秒,得益于共享内存加速,但在大规模故障中的表现需验证。
这些结果表明 PolarDB-MP 在高冲突 OLTP 场景下的优异表现和对复杂应用的支持,但测试条件的可复制性(竞品未开源)和极端负载下的性能仍需进一步验证。
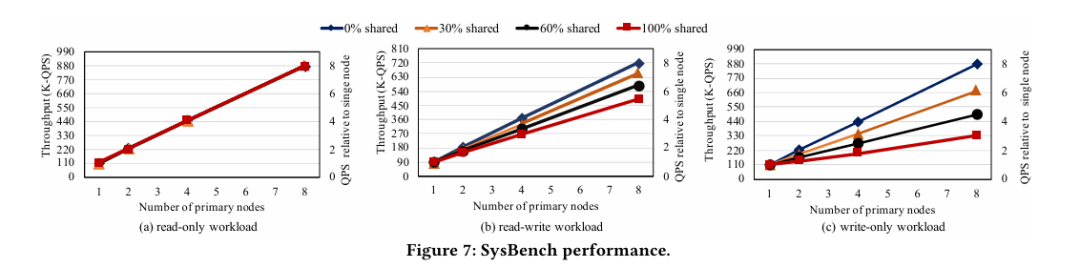
图 7 SysBench 性能
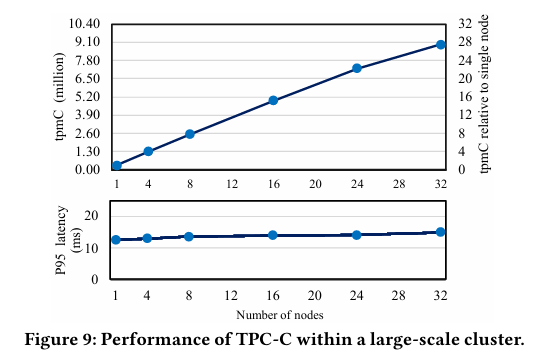
图 8 大规模集群的 TPC-C 性能
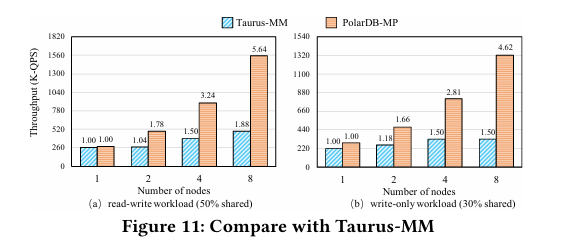
图 9 与 Taurus-MM 对比
PolarDB-MP 已部署于 Alibaba Cloud,商业试用验证了其实用性,适合写密集、高并发、高可用需求的云应用,契合云原生趋势,可能改变 DBaaS 竞争格局并降低 TCO,但客户案例和市场反馈需进一步观察。其局限性包括:
硬件依赖:RDMA 网络不可或缺,限制了非高端环境的部署,其成本和普及度是瓶颈,适配非 RDMA 网络(如 TCP)的降级方案可提升通用性。
故障处理:未详细讨论 PMFS 节点失效的容错机制,单点风险是隐患,增强 PMFS 高可用性(如多副本,借鉴 Raft)可提升健壮性。
资源开销:高冲突下锁冲突和内存使用未深入分析,资源效率是生产环境的关键,针对极端负载的锁优化和内存管理策略可进一步改进。
改进方向包括兼容普通网络、增强 HA 设计和优化资源使用,这些是数据库成功的关键,可能参考分布式一致性协议和工业标准(如 MySQL 的锁优化)。未开源可能阻碍社区验证,相比 TiDB 等开源项目需更多实际案例支持,但其落地潜力仍令人期待。

图 10 PolarDB-MP 恢复性能
PolarDB-MP 通过共享内存、RDMA 和 PMFS/LLSN 的创新,提供了一个高性能、可扩展的多主云原生数据库。其在高冲突场景下的表现、对 OLTP 的优化以及商业化落地使其在数据库领域独树一帜。业内人士可深入研究其技术细节(如 TIT 和 DBP 的实现),评估其在特定场景中的适用性,同时关注硬件依赖和高可用性等改进方向。这一方案可能推动数据库向硬件加速与架构创新结合的方向发展,成为云原生数据库的新范式。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





