





最近一位客户和我们大吐苦水,他们和一家大厂谈落地ChatBI,测试了将近一年,准确率才60%。
客户有点儿郁闷:怎么效果和说好的不一样,是我不会用吗?
企业数据分析是一个非常严肃的场景,对错误的容忍度很低。客户见到厂商,第一个问题肯定是:
你这ChatBI,保准吗?

过去几年,我们服务了几十家大型和超大型企业客户,很多企业都有和开头的那位客户一样的困惑,很多ChatBI总是“看起来很美”,落地效果又不尽如人意。
今天就基于我们多年的经验,来聊聊ChatBI的数据结果为什么不准确,以及站在落地的视角,有哪些隐藏的坑。

为什么买家秀和卖家秀差这么多?
大模型有幻觉,这事儿已经不必再强调。幻觉导致两方面问题,一是不准确;二是不一致,“篡改”了用户的输入,回答得文不对题。
看起来无所不能的DeepSeek-R1,幻觉率甚至更高了,达到14.3%。

今天我们看到最先进的大模型,在真实测试中的NL2SQL/Text2SQL输出准确率在80%左右,其他模型还要更低。
没错,买家秀和卖家秀就是差这么多。
在实际应用中,大模型NL2SQL还会面临其他的挑战,比如:
复杂条件的查询:例如多表关联、嵌套问题,对模型的语义理解和逻辑推理能力有极高的要求,翻车率极高。
查询性能:用户对ChatBI的期待是实时响应,等待3秒钟还没结果,就关掉窗口了。在企业级的数据查询中,表和字段的数量、prompt的长度、SQL的复杂程度、模型的参数规模等等都会影响模型响应时间,我们看到的很多ChatBI都要等待10秒以上。
两类常见的技术路线
大模型直接输出代码NL2SQL不靠谱,很容易想到用RAG、finetune等方法来限制幻觉。我们在市面上见到的方案大体可分两种路径。
路径一:题海战术
一种路径类似于题海战术。把问题和正确的SQL代码作为知识模板放在知识库里,让大模型在做题的时候参考合适的例题,套模板。
这种方式有两个明显的问题。
第一,死读书,见过的题会做,没见过的题不会。
第二,读死书,大模型并没有真正的理解问题,有很大概率套错模板。
这两个问题带来的结果就是,运维成本很重,得尽可能多地穷尽例题,才可能提升一点儿效果,而一旦迁移到其他场景(比如从零售行业扩展到制造行业,或者从销售场景扩展到财务场景),一切又要从头来过。

路径2:NL2X2SQL
另一种路径是增加一个更加可控的中间层,不让大模型直接生成SQL,我们称之为“NL2X2SQL”。这个“X”又有几种情况,比如NL2API、NL2DSL、NL2Metric等。
简而言之,NL2X2SQL的核心是不让大模型直接生成代码,而是生成一种结构化的语言,或者说对SQL的一层抽象,比如指标、维度、过滤条件等。
大模型把用户的提问转化成中间语义层,系统再根据一定的规则转化为SQL执行数据查询。
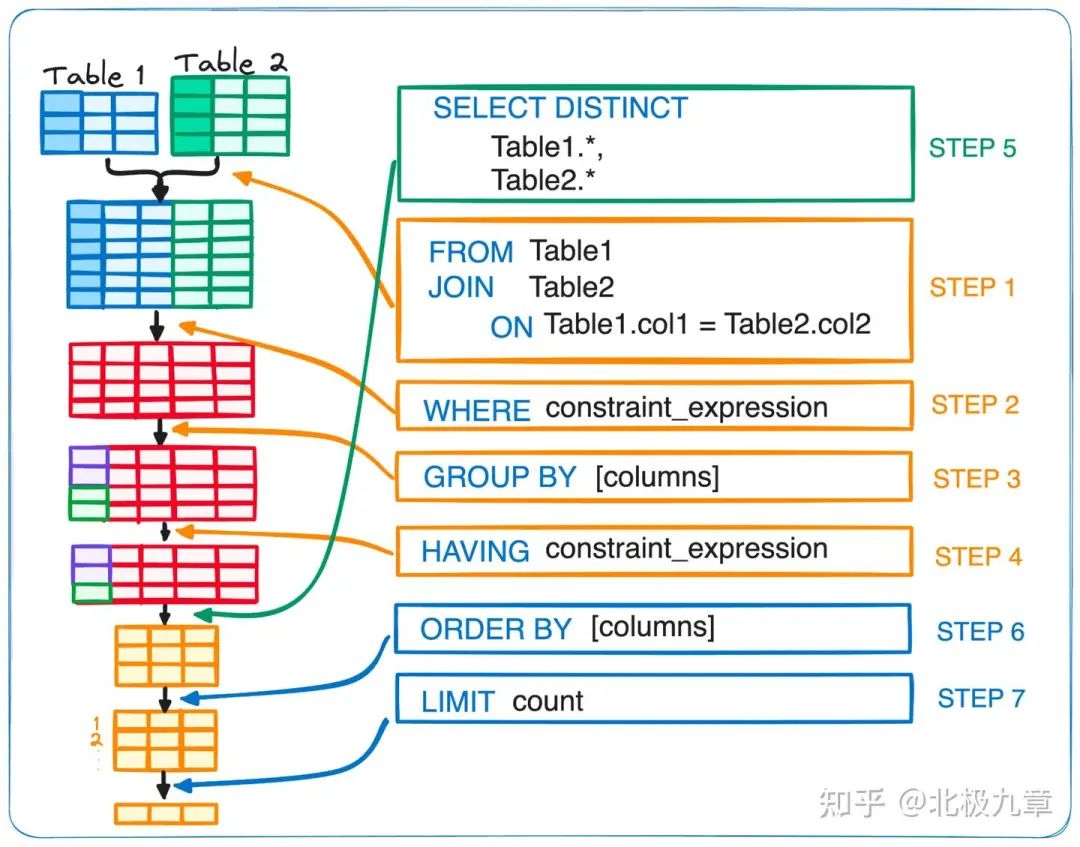
相比前文的方案,这种技术路径在准确性、稳定性等方面,都有所提升。
不过问题仍然没有完全解决:大模型的幻觉能完全消除吗?
我们注意到,这种技术路线实际上是通过多层限制来“拦截”大模型的幻觉输出,就如同《猫和老鼠》中一片片的奶酪,看上去很严密,但每一片上都有许多孔洞,还是有一定的几率“穿过”每一层窟窿,输出错误答案。
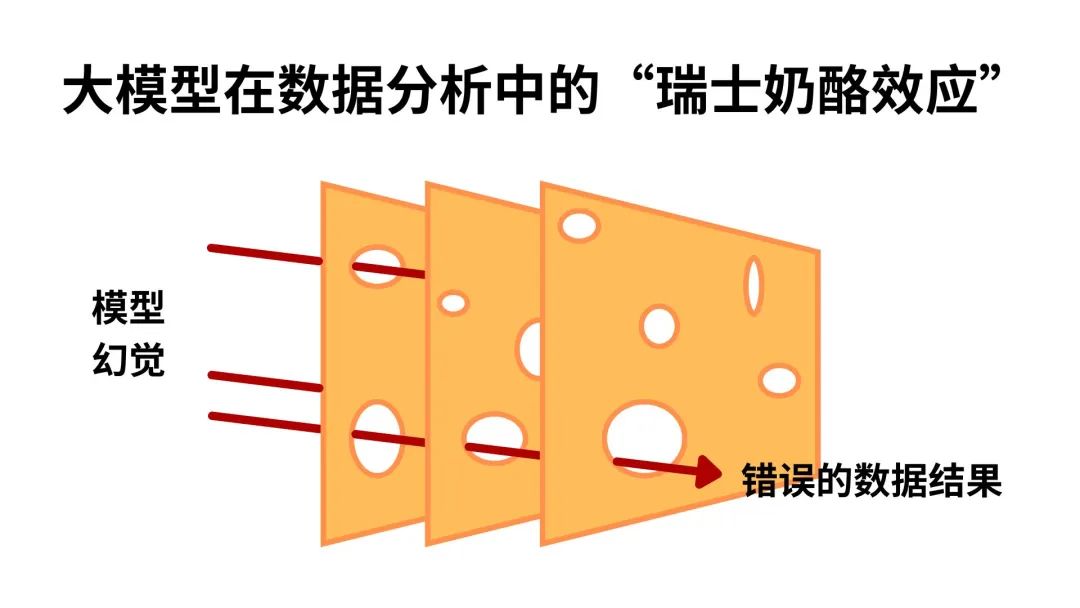
在实际应用中,我们还注意到一些问题:
比如,当一个问题需要输出多段SQL才能解决时,准确率会明显降低,例如,“今年6月和去年11月的业绩对比”。涉及多表关联的问题,也会出现选错表的问题。
除此之外,性能和成本也是需要考虑的问题。prompt越长、给大模型的“参考资料”越多、思考的内容越长,响应速度就越慢。正如前文所说,用户期待的是“秒回”。
我们的解法
在数据分析场景,ChatBI需要更可靠、更精确、更负责的东西,所以我们采用了混合AI模型,将生成式AI和传统人工智能结合起来。
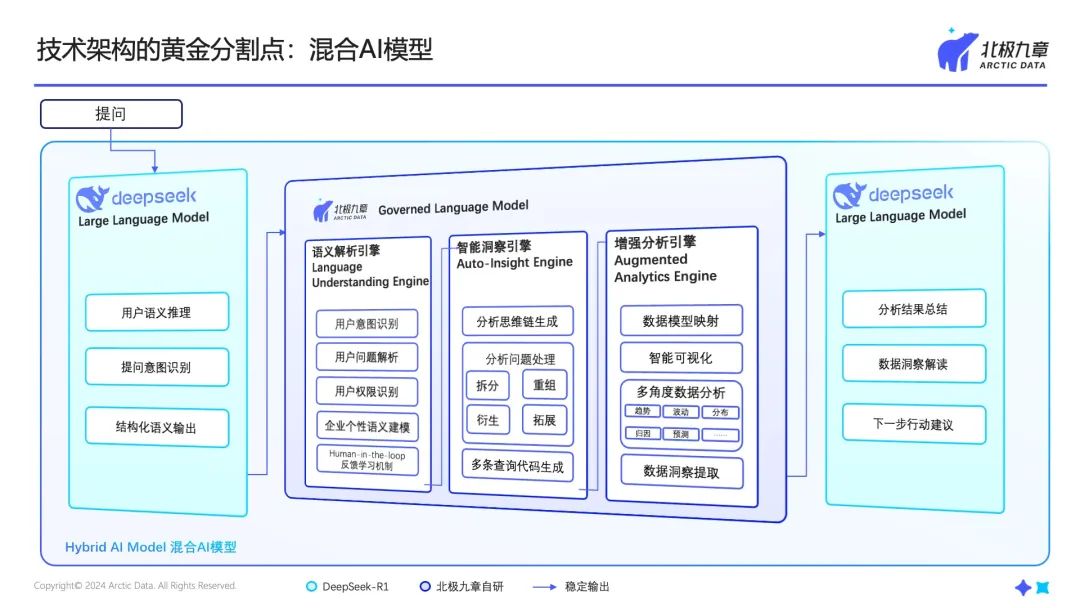
这样做有几个好处:
首先,大幅提高ChatBI的准确率。
在一家上市公司客户的测试中,我们的初始正确率可以达到97%以上,经过排查,3%无法有效回答的问题涉及语言表述的歧义或者模糊,人也很难一次性理解清楚,后续可以通过运营的手段提升和优化。
其次,能更好地处理复杂场景和复杂问题。
同环比、对比、占比等复杂结构的问题,以及针对问题选表等情况,在企业实际应用中非常常见,是落地应用必须解决的问题。这些能力已经内置在我们的模型中,都可以即开即用,不需要专门调优。
第三,低延时,性能更强。
我们的模型专门面向数据分析场景设计,语义解析和推理速度更快,生成的代码运行性能更高,整体的响应速度远远高于其他产品。经客户评测,用户问题的综合响应时间在2秒左右(根据实际的数据库、网络条件有所不同),其他ChatBI的平均响应时间基本超过10秒。
第四,具备可解释性和可运营性。
大模型是个黑盒子,它的推理过程不可见,用户和管理员不知道为什么这次它这样理解、下次又那样理解,对于企业级应用和运维来说,造成了极大的不便。在我们的模型中,语义理解、代码生成是白盒可见的,用户能知道AI是否理解了自己的问题,管理员能知道错在哪里、如何修正错误。

结语
过去几年,我们跟很多客户、同行交流,大家普遍发现,做一个60分的ChatBI demo容易,做到80分、90分乃至100分的企业级应用却很难。
因为在企业中,数据分析工具面临着更加复杂的问题,从技术上说,有运维的问题、与现有IT架构和数据架构融合的问题,等等;从价值上说,有与业务场景结合的问题、有投入产出比的问题,等等。
无论采用哪种方式落地,最终还是要以用户价值为导向,更便捷、更低成本地去解决用户真正的问题。




