




深度学习作为机器学习的一个分支,利用多层神经网络从数据中自动提取特征,尤其在处理复杂数据(如图像、文本和时间序列数据)方面表现出色。在金融领域,深度学习特别适合于处理非线性关系与高维数据,这使得其在预测市场行为和识别模式方面具有显著优势。以算法交易为例,算法交易发展到现在大致经过了四代,目前所处的 AI 算法时代与前三代最大的区别在于引入了复杂的深度学习模型,根据模型信号指导算法执行。
尽管深度学习在量化金融中展现出巨大潜力,但在实际应用中仍存在着以下难点:
- 大规模因子(特征值)的存储和计算
- 因子实时流式计算
- 因子数据与深度学习模型集成工程化
DolphinDB 作为分布式计算、存储及实时流计算一体化的高性能时序数据库,非常适合因子的存储、计算、建模、回测和实盘交易,能够很好地应对深度学习中涉及到的大规模因子计算和存储、因子实时计算等关键环节。与此同时,为了解决第三个问题,DolphinDB 先后推出了 AI DataLoader 和 Libtorch
本文以股票实时波动率预测为例,介绍 DolphinDB 在深度学习实践的各个环节中的解决方案,包括高频因子存储与计算、在 Python 中使用 AI DataLoader 加载因子完成训练、在 DolphinDB 中使用 Libtorch 插件完成实时推理等。注意,本文重点在于介绍上述操作流程,而不是提供股票波动率预测的最佳模型,所以预测模型和结果仅供参考。
本文将提供完整的代码和部分样例数据,以便读者可以跟随教程练习。本文全部代码的运行环境请见附录中的开发环境。虽然本文使用了 GPU 版本的 DolphinDB 和 GPU 版本的 LibTorch 插件,但是在实际使用中,同样可以使用 CPU 版本的 DolphinDB 和 CPU 版本的 LibTorch 插件运行本文代码。
1. 概述
以 AI 算法交易为例,主要分为算法研究和算法实盘两个阶段,算法研究与实盘计算在技术选型上各有侧重。本章首先分析现有技术栈的优缺点,再介绍基于 DolphinDB 的一站式解决方案。
1.1 现有解决方案的优缺点
在算法研究方面,NAS 文件存储 + HDFS大数据存储集群 + Python 的方式是目前算法研究阶段最常用的解决方案。Python 拥有丰富的数据科学和机器学习库,但是由于 Python 的 Global interpreter lock 的限制,无法进行并行计算。实际使用中,也可以结合其他框架(比如 Ray )来实现 Python 的分布式计算,但这将涉及到更复杂的系统使用和运维。与此同时,算法研究会频繁存储和访问高频数据,尽管 NAS 和 HDFS 被设计用于大规模数据存储,但是在实际操作中,面对不断增长的数据量和计算需求,在容量可扩展性、性能和高可用上逐渐难以满足要求。并且这种解决方案需要大量的二次开发以及持续的运维成本。
在算法因子流式计算方面,性能和开发效率很难取得平衡。对实时数据进行计算时,由于 python 仅支持全量计算,不支持增量计算,所以无法达到实时计算的性能要求。为生产环境中的性能考虑,很多机构会用 C++ 重新实现研究(历史数据)代码。不过,这种解决方案需要维护两套代码,开发成本(时间和人力)会大幅增加。此外,还要耗费大量精力确保两套系统的结果完全一致。
1.2 DolphinDB 解决方案
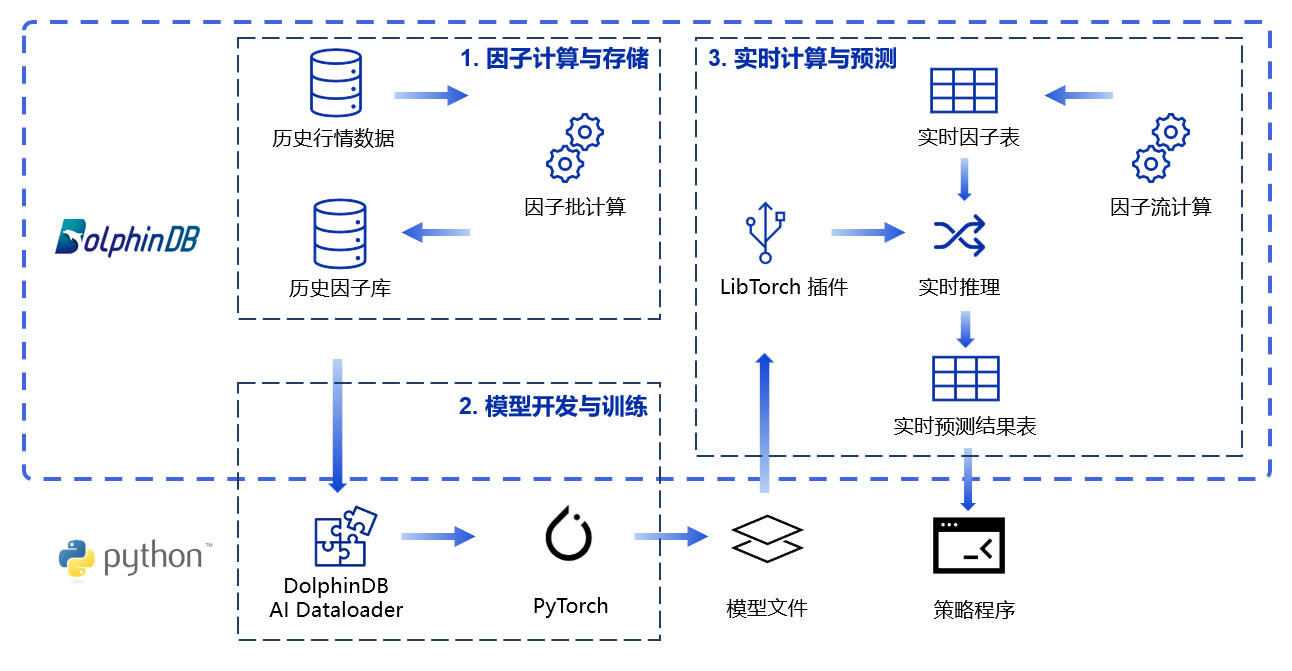
基于上述现状,DolphinDB 提供了一站式的解决方案。首先,在 DolphinDB 分布式数据库中存储海量历史行情数据,进行大批量的因子计算,充分发挥 DolphinDB 在大规模数据计算上的速度优势。其次,可以在 Python 中使用 DolphinDB 开发的 AI Dataloader 工具,便捷地读取数据库内的因子数据并转换为 PyTorch 等深度学习框架可识别的 Tensor,实现在 Python 环境中进行深度学习模型训练。最后,训练得到的模型文件可以被 DolphinDB 的 Libtorch 插件识别,在 DolphinDB 中完成推理任务,配合 DolphinDB 功能强大的流数据表和流计算引擎,可以迅速处理实时数据得到实时因子表及实时预测结果表。最后,实时预测结果表可以被 Python 等策略程序订阅进行后续的信号加工等操作,完成完整的算法执行流程。具体流程如下图所示:
2. 特征因子计算与存储
本章将参考 开发股票波动率预测模型的 676 个输入特征 这一教程,使用股票的 Level 2 快照数据(每幅快照间隔时间为 3 秒),在 DolphinDB 中构建频率为 10 分钟的特征。通过元编程的方式低代码量实现了 676 列衍生特征的计算,并且在 DolphinDB 中创建数据库存储这些特征,以便后续的模型训练使用。
本文使用的快照数据文件结构如下:
| 字段 | 含义 | 字段 | 含义 | 字段 | 含义 |
|---|---|---|---|---|---|
| SecurityID | 证券代码 | LowPx | 最低价 | BidPrice[10] | 申买十价 |
| DateTime | 日期时间 | LastPx | 最新价 | BidOrderQty[10] | 申买十量 |
| PreClosePx | 昨收价 | TotalVolumeTrade | 成交总量 | OfferPrice[10] | 申卖十价 |
| OpenPx | 开始价 | TotalValueTrade | 成交总金额 | OfferOrderQty[10] | 申卖十量 |
| HighPx | 最高价 | InstrumentStatus | 交易状态 | …… | …… |
本文所需的 2021 年某交易所所有股票快照测试数据已经提前导入至 DolphinDB 数据库中,一共约 17 亿条数据。为了方便读者跟随本文实操学习,在文末附录中提供了一支股票一个月的快照数据(见附录中 Snapshot 文件),以及建库建表和数据导入脚本(见附录中 snapshot 建库建表与文件导入文件)。数据导入方法详细介绍请参考 数据迁移方法 。注意,本文使用了全年数据进行模型训练,由于附录大小限制,附录中仅提供了一个月数据。
2.1 特征因子计算
因子挖掘是量化交易的必备环节之一,随着量化交易和 AI 模型训练规模的发展,量化投资团队在投研环节势必需要处理大量因子数据。本文基于 Level 2 快照行情数据中的 10 档买卖单量价数据,分别计算了一级指标和二级指标。其次,对一级指标和二级指标进行 10 分钟级别的聚合计算,最终得到衍生特征。同时,考虑到特征具有时效性,将 10 分钟的特征切分成 0-600s(全部)、150-600s、300-600s、450-600s 四段,最终实现了 676 维聚合特征的计算。特征因子结构如下图所示:
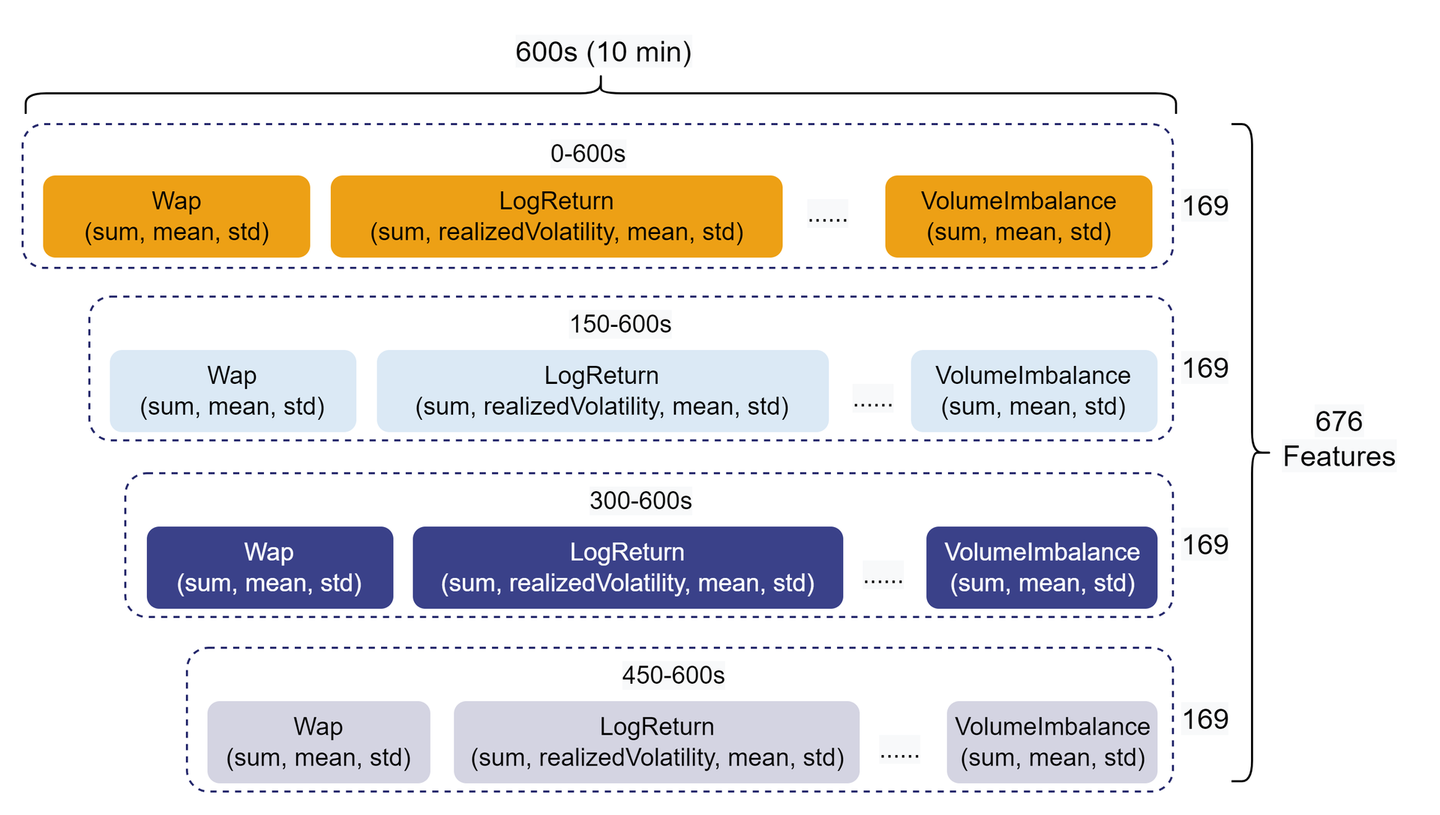
本小节完整代码见附录中特征因子计算与存储脚本。上述 676 个因子均由元编程动态生成,代码量不超过 70 行。与多个 Python Pandas 进程并行计算相比,相同并行度的 DolphinDB 分布式计算能带来约 30 倍的性能提升。具体的因子设计、代码说明和性能测试请参考 开发股票波动率预测模型的 676 个输入特征 。部分示例代码如下:
// 定义聚合函数 defg featureEngineering(DateTime, BidPrice, BidOrderQty, OfferPrice, OfferOrderQty, aggMetaCode){ wap = (BidPrice * OfferOrderQty + BidOrderQty * OfferPrice) \ (BidOrderQty + OfferOrderQty) wapBalance = abs(wap[0] - wap[1]) priceSpread = (OfferPrice[0] - BidPrice[0]) \ ((OfferPrice[0] + BidPrice[0]) \ 2) BidSpread = BidPrice[0] - BidPrice[1] OfferSpread = OfferPrice[0] - OfferPrice[1] totalVolume = OfferOrderQty.rowSum() + BidOrderQty.rowSum() volumeImbalance = abs(OfferOrderQty.rowSum() - BidOrderQty.rowSum()) logReturnWap = logReturn(wap) logReturnOffer = logReturn(OfferPrice) logReturnBid = logReturn(BidPrice) subTable = table(DateTime as `DateTime, BidPrice, BidOrderQty, OfferPrice, OfferOrderQty, wap, wapBalance, priceSpread, BidSpread, OfferSpread, totalVolume, volumeImbalance, logReturnWap, logReturnOffer, logReturnBid) colNum = 0..9$STRING colName = `DateTime <- (`BidPrice + colNum) <- (`BidOrderQty + colNum) <- (`OfferPrice + colNum) <- (`OfferOrderQty + colNum) <- (`Wap + colNum) <- `WapBalance`PriceSpread`BidSpread`OfferSpread`TotalVolume`VolumeImbalance <- (`logReturn + colNum) <- (`logReturnOffer + colNum) <- (`logReturnBid + colNum) subTable.rename!(colName) subTable['BarDateTime'] = bar(subTable['DateTime'], 10m) result = sql(select = aggMetaCode, from = subTable).eval().matrix() result150 = sql(select = aggMetaCode, from = subTable, where = <time(DateTime) >= (time(BarDateTime) + 150*1000) >).eval().matrix() result300 = sql(select = aggMetaCode, from = subTable, where = <time(DateTime) >= (time(BarDateTime) + 300*1000) >).eval().matrix() result450 = sql(select = aggMetaCode, from = subTable, where = <time(DateTime) >= (time(BarDateTime) + 450*1000) >).eval().matrix() return concatMatrix([result, result150, result300, result450]) } // 元编程生产查询语句并查询 whereConditions = [<date(DateTime) between 2021.01.04 : 2021.12.31>, <SecurityID in stockList>, <(time(DateTime) between 09:30:00.000 : 11:29:59.999) or (time(DateTime) between 13:00:00.000 : 14:56:59.999)>] result = sql(select = sqlColAlias(<featureEngineering(DateTime, matrix(BidPrice), matrix(BidOrderQty), matrix(OfferPrice), matrix(OfferOrderQty), aggMetaCode)>, metaCodeColName <- (metaCodeColName+"_150") <- (metaCodeColName+"_300") <- (metaCodeColName+"_450")), from = snapshot, where = whereConditions, groupBy = [<SecurityID>, <bar(DateTime, 10m) as DateTime>]).eval()复制
2.2 特征因子存储
因子的存储也是一个关键问题,目前 DolphinDB 支持宽表和窄表两种存储模式。相较于宽表,窄表存储支持更加高效地添加、更新、删除因子等操作,因而本文推荐使用窄表存储因子库。针对十分钟频率因子库,经过各项测试后(测试见 中高频多因子库存储最佳实践 ),提供了以下最佳实践。
本例采用了“时间维度按月 + 因子名”的组合分区方式存储,使用存储引擎 TSDB ,“股票代码 + 交易时间”作为排序列。更多金融数据与因子库分区方案见 存储金融数据的分区方案最佳实践 。
create database "dfs://tenMinutesFactorDB" partitioned by VALUE(2021.01M..2021.12M), VALUE(`f1`f2) engine = 'TSDB' create table "dfs://tenMinutesFactorDB"."tenMinutesFactorTB"( SecurityID SYMBOL, DateTime TIMESTAMP[comment="时间列", compress="delta"], FactorNames SYMBOL, FactorValues DOUBLE ) partitioned by DateTime, FactorNames, sortColumns=[`SecurityID, `DateTime], keepDuplicates=ALL, sortKeyMappingFunction=[hashBucket{, 500}]复制
3. 模型开发与训练
本章将在 Python 中通过 AI DataLoader 加载 DolphinDB 数据库中的因子作为特征值,调用 PyTorch 框架进行深度学习模型训练,从而预测未来 10 分钟的波动率。在金融市场中,波动率常用于衡量股票价格随时间变化的程度,所以选取 LogReturn0_realizedVolatility 变量作为模型预测的目标值。本章的完整 Python 代码见附录中模型训练脚本,以下正文中仅包含与 DolphinDB 功能相关的关键代码。
3.1 AI Dataloader 加载训练数据
定义 AI Dataloader ( DDBDataloader ),将训练数据转换为 PyTorch 等深度学习框架等可识别的 tensor 数据类型。通过使用 AI Dataloader ,用户不需要花费过多时间设计 Dataset ,只需要用简单的 SQL 语句配合 DolphinDB server 就可以轻松构建 DataLoader 。同时,AI Dataloader 充分利用了 DolphinDB 的特性,将 SQL 查询拆分为多个查询,从而减少了数据在客户端的内存占用,帮助用户更好地控制内存。
首先,需要安装DolphinDB Python API ,以及其提供的深度学习工具类 DDBDataLoader。详情请参考 Python API 安装 和 AI DataLoader 安装 。
pip install dolphindb pip install dolphindb-tools复制
之后,进行数据预处理。相关 Python 代码如下:
# 数据预处理,并切分训练集和测试集 conn = ddb.session("192.168.100.201", 8848, "admin", "123456") conn.run("""startDay = 2021.01.01 endDay = 2021.12.31 splitDay = (startDay..endDay)[((endDay-startDay)*0.8).floor()] Data = select FactorValues from loadTable("dfs://tenMinutesFactorDB", "tenMinutesFactorTB") where date(DateTime) >= objByName('startDay') and date(DateTime) <= objByName('endDay') and SecurityID=`600030 pivot by DateTime, SecurityID, FactorNames Data = Data[each(isValid, Data.values()).rowAnd()] """)复制
上述代码连接 DolphinDB 数据库进行数据预处理,通过 conn.run 接口将脚本语句发给 DolphinDB server 进行数据处理。本例使用了 2021.01.01-2021.12.31 的因子数据,按照日期将数据按 8:2 比例划分为训练集和测试集。通过 pivot by 语句将以窄表形式存储的因子转为宽表,以便在 Python 端转为 tensor。此外,还去除了包含空值因子的数据行。若需要标准化处理数据等操作,也同样可以在此处完成。
接下来,实例化两个 DDBDataloader 对象,分别用于加载训练数据和测试数据。它们唯一的区别是参数 sql 指定了不同时间范围的数据。
# Dataloader 参数 targetColumns = ["LogReturn0_realizedVolatility"] excludedColumns = ["SecurityID", "DateTime", "LogReturn0_realizedVolatility"] batchSize = 256 windowSize = [120, 1] windowStride=[1, 1] offset = 120 trainSql = """select * from objByName('Data') where date(DateTime) >= objByName('startDay') and date(DateTime) <= objByName('splitDay')""" testSql = """select * from objByName('Data') where date(DateTime) > objByName('splitDay') and date(DateTime) <= objByName('endDay')""" # 实例化 DDBDataloader trainLoader = DDBDataLoader(ddbSession=conn, sql=trainSql, targetCol=targetColumns, excludeCol=excludedColumns, batchSize=batchSize, device=device, windowSize=windowSize, windowStride=windowStride, offset=offset) testLoader = DDBDataLoader(ddbSession=conn, sql=testSql, targetCol=targetColumns, excludeCol=excludedColumns, batchSize=batchSize, device=device, windowSize=windowSize, windowStride=windowStride, offset=offset) print("Using DDBDataLoader, data is ready")复制
- ddbSession:指定与 DolphinDB 数据库的连接会话。
- sql:定义从数据库中提取数据的 SQL 查询语句。DDBDataLoader 对象会根据数据库分区将查询分为多个子查询。DDBDataLoader 对象内部线程根据拆分的数据,会在后台线程中转换以及拼接成 PyTorch 训练所需的数据,再放入预准备队列中。
- targetCol:指定目标列(即模型预测的目标变量),这里设置为 LogReturn0_realizedVolatility。
- excludeCol:指定需要排除的列,这里排除了 SecurityID、DateTime 和 LogReturn0_realizedVolatility,确保这些列不会作为输入特征。
- batchSize:设置每个批次的数据量,这里为 256。
- windowSize:定义滑动窗口的大小,这里设置为 [120, 1],表示输入数据窗口大小为 120 个时间点,目标数据窗口大小为 1 个时间点。即每 120 个时间点的因子时序数据会作为一条样本输入,对应一个时间点的 LogReturn0_realizedVolatility 值。
- windowStride:定义滑动窗口的步长,这里设置为 [1, 1],表示每次滑动 1 个时间点。
- offset:指定目标数据相对于输入数据的偏移量,这里设置为 120,表示目标数据是输入数据之后 120 个时间点的值。
- device:指定数据加载到 GPU 还是 CPU。
通过这些参数设置,AI DataLoader 能够高效地从 DolphinDB 数据库中提取数据,并将其转换为适合 LSTM 等深度学习模型训练的格式。同时滑动窗口的支持极大地简化了数据处理代码。除此之外还可以设置一些其余的参数帮助训练。更多参数含义及使用教程参考 AI DataLoader 。
3.2 模型搭建
本次训练的目标是股票的波动率,具有很强的时序性,因此本文选用 LSTM 模型
# 模型定义 class LSTMModel(nn.Module): def __init__(self, inputSize, units): super(LSTMModel, self).__init__() self.lstm1 = nn.LSTM(input_size=inputSize, hidden_size=units, batch_first=True, dropout=0.4) self.lstm2 = nn.LSTM(input_size=units, hidden_size=128, batch_first=True, dropout=0.3) self.lstm3 = nn.LSTM(input_size=128, hidden_size=32, batch_first=True, dropout=0.1) self.fc = nn.Linear(32, 1) def forward(self, x): out, _ = self.lstm1(x) out, _ = self.lstm2(out) out, _ = self.lstm3(out) out = out[:, -1, :] out = self.fc(out) return out复制
3.3 模型训练
AI Dataloader 的使用方式与 Pytorch 的 Dataloader 的使用方式基本相同。以训练过程为例,代码如下:
# 训练阶段 model.train() trainLoss = 0.0 trainLen = 0 for inputs, targets in trainLoader: inputs = inputs.float().to(device) targets = targets.float().to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, targets) trainLoss += loss.item() loss.backward() optimizer.step() trainLen += 1 trainLoss /= trainLen复制
遍历 trainLoader,从其内部队列中迭代获取批量数据,计算并优化模型的损失函数。
最终,需要将训练好的模型保存为 TorchScript 格式,便于后续在 DolphinDB 的 server 端中通过 Libtorch 插件进行调用。
torchScriptModel = torch.jit.script(model) torchScriptModel.save("/your_path/LSTMmodel.pt")复制
3.4 训练性能
基于一支股票一年的 10 分钟因子数据进行 LSTM 模型训练,训练 100 轮总耗时 72 秒。测试环境软硬件配置见附录。具体的测试工况如下:
- 数据集总数据量:5832 行(一年 10 分钟频率数据)。
- 特征数量:676 个因子(输入维度为 675,目标维度为 1)。
- 数据预处理:
- 数据按日期范围(2021 年 1 月 1 日至 2021 年 12 月 31 日)筛选。
- 使用滑动窗口处理数据,窗口大小为 120,步长为 1,目标偏移量为 120。
- 模型结构:
- 3 层 LSTM,隐藏单元数分别为 256、128 和 32。
- 输出层为全连接层,输出维度为 1。
- 使用 Dropout 防止过拟合(LSTM1: 0.4, LSTM2: 0.3, LSTM3: 0.1)。
- 损失函数:SmoothL1Loss。
- 优化器:Adam,初始学习率为 0.0001。
- 批量大小:256。
- 训练轮数:100 轮。
- 设备:NVIDIA GPU(具体型号见附录)。
4. 实时计算与预测
上述计算都是基于历史数据的批量计算,然而在实际生产环境中,数据的来源往往是以“流”的方式。本章将介绍如何复用上述复杂的衍生特征计算脚本实现流式实时因子计算,并且通过 Libtorch 插件实现实时模型推理。本章的完整 DolphinDB 脚本见附录中模型实时推理脚本,以下正文中仅包含部分关键代码。
本例通过回放数据库内一天的原始快照数据,模型实时数据写入和后续的实时计算与预测。首先,创建用于测试数据回放的 SnapshotStream 流表。
name = loadTable("dfs://l2StockSHDB", "snapshot").schema().colDefs.name type = loadTable("dfs://l2StockSHDB", "snapshot").schema().colDefs.typeString share(streamTable(100000:0, name, type), `SnapshotStream)复制
之后,编写计算逻辑,订阅原始快照数据,详情见本章 4.1 和 4.2 小节。最后,回放历史数据写入流表中。以下示例以 100 倍速回放了一只股票一天的快照数据。
testSnapshot = select * from loadTable("dfs://l2StockSHDB", "snapshot") where SecurityID=`600030 and date(DateTime)=mdDate submitJob("replaySnapshot", "replay 1 day snapshot", replay{testSnapshot, SnapshotStream, `DateTime, `DateTime, 100, false, 1, , true})复制
4.1 流式实时因子计算
DolphinDB 实现流批一体的方式之一是使用函数或表达式实现金融高频因子,代入不同的计算引擎进行历史数据或流数据的计算。在本例中,我们复用了 2.1 小节中定义的所有因子函数,在 2.1 小节中我们将因子代入 SQL 引擎,实现对历史数据的计算;在 4.1 小节我们将其代入聚合引擎,实现对流数据的计算。
// 创建实时因子表 share(streamTable(100000:0 , `DateTime`SecurityID`ReceiveTime <- metaCodeColName <- (metaCodeColName+"_150") <- (metaCodeColName+"_300") <- (metaCodeColName+"_450") <- `HandleTime,`TIMESTAMP`SYMBOL`NANOTIMESTAMP <- take(`DOUBLE, 676) <- `NANOTIMESTAMP) , `aggrFeatures10min) go // 创建时序聚合引擎 metrics=sqlColAlias(<featureEngineering(DateTime, matrix(BidPrice[0],BidPrice[1],BidPrice[2],BidPrice[3],BidPrice[4],BidPrice[5],BidPrice[6],BidPrice[7],BidPrice[8],BidPrice[9]), matrix(BidOrderQty[0],BidOrderQty[1],BidOrderQty[2],BidOrderQty[3],BidOrderQty[4],BidOrderQty[5],BidOrderQty[6],BidOrderQty[7],BidOrderQty[8],BidOrderQty[9]), matrix(OfferPrice[0],OfferPrice[1],OfferPrice[2],OfferPrice[3],OfferPrice[4],OfferPrice[5],OfferPrice[6],OfferPrice[7],OfferPrice[8],OfferPrice[9]), matrix(OfferOrderQty[0],OfferOrderQty[1],OfferOrderQty[2],OfferOrderQty[3],OfferOrderQty[4],OfferOrderQty[5],OfferOrderQty[6],OfferOrderQty[7],OfferOrderQty[8],OfferOrderQty[9]), aggMetaCode)>, metaCodeColName <- (metaCodeColName+"_150") <- (metaCodeColName+"_300") <- (metaCodeColName+"_450")) createTimeSeriesEngine(name="aggrFeatures10min", windowSize=600000, step=600000, metrics=[<now(true) as ReceiveTime>, metrics, <getHandleTime() as HandleTime>], useSystemTime=false ,dummyTable=SnapshotStream, outputTable=aggrFeatures10min, timeColumn=`DateTime, useWindowStartTime=true, keyColumn=`SecurityID) // 订阅原始行情数据,实时写入时序聚合引擎 subscribeTable(tableName="SnapshotStream", actionName="aggrFeatures10min", offset=-1, handler=getStreamEngine("aggrFeatures10min"), msgAsTable=true, batchSize=2000, throttle=0.01, hash=0, reconnect=true)复制
创建因子计算的流数据时间序列引擎,并订阅 SnapshotStream 流表实时写入引擎。引擎对增量快照数据进行聚合计算,缓存必要的历史数据,并将计算得到的因子源源不断地写入 aggrFeatures10min 流表中。
4.2 使用 Libtorch 插件进行实时模型推理
DolphinDB 提供了 Libtorch 插件,使得可以在 DolphinDB 环境中直接加载和使用 TorchScript 模型。我们将订阅上一小节中时序聚合引擎的输出表,将实时因子和历史因子一同处理为模型的输入数据,数据格式为 Tensor。
首先需要安装和加载 Libtorch 插件。使用 loadPlugin 命令加载插件,CPU 版本插件名为 "Libtorch",GPU 版本插件名为 "GpuLibtorch"。注意两个版本的插件不能同时加载。本例使用的 DolphinDB server 为 GPU 版本(Shark),因此这里选择了 GpuLibtorch 插件。
installPlugin("GpuLibtorch") loadPlugin("GpuLibtorch")复制
接下来加载训练好的模型,并且调用 setDevice 函数将模型放置到 GPU 上:
// 加载模型 modelPath = "/home/lnfu/ytxie/LSTMmodel.pt" model = Libtorch::load(modelPath) Libtorch::setDevice(model, "CUDA")复制
成功加载 Python 中训练得到的模型之后,订阅 aggrFeatures10min 流表并进行实时模型推理。每当 aggrFeatures10min 流表中有新的数据到达时,就会调用 predictRV 函数并将计算结果写入 result10min 流表内。
// 创建实时预测结果表 share(streamTable(100000:0 , `Predicted`SecurityID`DateTime`ReceiveTime`HandleTime`PredictedTime, `FLOAT`SYMBOL`TIMESTAMP`NANOTIMESTAMP`NANOTIMESTAMP`NANOTIMESTAMP), `result10min) go // 定义实时处理方法:数据预处理和模型推理 def predictRV(model, window, msg){ tmp = select * from msg tmp.dropColumns!(`ReceiveTime`HandleTime) tmp.reorderColumns!(objByName(`historyData).columnNames()) predictedtSet = [] for(row in tmp){ objByName(`historyData).tableInsert(row) data = tail(objByName(`historyData), window) data.dropColumns!(`SecurityID`DateTime`LogReturn0_realizedVolatility) data = data[each(isValid, data.values()).rowAnd()] input = tensor([matrix(data)$FLOAT]) predict = Libtorch::predict(model, input) predictedtSet.append!(predict[0][0]) } ret = select predictedtSet as predicted, SecurityID, DateTime, ReceiveTime, HandleTime, now(true) as PredictedTime from msg objByName("result10min").append!(ret) } // 获取当天往前 20 日的十分钟因子,为滑动窗口准备历史数据 data = select FactorValues from loadTable("dfs://tenMinutesFactorDB", "tenMinutesFactorTB") where date(DateTime) between (mdDate-20):(mdDate-1) and SecurityID=`600030 pivot by DateTime, SecurityID, FactorNames data = data[each(isValid, data.values()).rowAnd()] share(data, `historyData) // 时间窗口大小,用 120 个时间点的因子预测下一个时间点的波动率 window = 120 // 预热模型,避免第一次调用模型推理时的较大耗时 warmupData = tail(objByName(`historyData), window) warmupData.dropColumns!(`SecurityID`DateTime`LogReturn0_realizedVolatility) input = tensor([matrix(warmupData)$FLOAT]) out = Libtorch::predict(model, input) // 订阅实时因子表 subscribeTable(tableName="aggrFeatures10min", actionName="predictRV", offset=-1, handler=predictRV{model, window}, msgAsTable=true, batchSize=100, throttle=0.001, hash=1, reconnect=true)复制
- 从数据库中获取了当天往前 20 日的十分钟因子,为构造模型的输入数据做准备。因为模型以 120 个时间点的 676 维特征作为一个样本,所以在当日实时预测的过程中也需要用到这部分历史数据。在
predictRV函数中我们拼接了这两份数据,并用 tail 取最后 120 条。 - 注意,需要保证 676 维特征的顺序与 Python 中训练时一致。这里用
reorderColumns!函数修改了时序聚合引擎输出的因子的顺序。 - 本例在实时预测之前先调用了一次模型,作为模型预热。这并不是必选的操作,但是可以优化实时预测的性能。由于 CUDA 初始化、GPU 预热和模型初始化等原因会造成第一次调用模型推理时耗时较大,若不进行此处的预热操作,则在第一次实时预测时(也就是
predictRV函数被触发时)出现加大的时延。
部分结果如下图所示:

4.3 通过 PythonAPI 实时订阅预测结果
在 Python 中通过 subscribe 函数订阅实时计算结果。关于 Python 如何订阅 DolphinDB 流表数据,可以参考 流数据订阅 。
# 订阅实时计算结果流表 import dolphindb as ddb s = ddb.session(keepAliveTime=60) s.connect("192.168.100.201", 8848, "admin", "123456") s.enableStreaming() def handler(lst): print(lst) s.subscribe(host="192.168.100.201", port=8848, handler=handler, tableName="result10min", actionName="result10min", offset=-1, resub=True, msgAsTable=True, batchSize=100, throttle=0.001)复制
订阅成功的输出结果如下所示:

4.4 实时预测性能
实时预测的时间开销主要是实时因子计算和模型实时推理两个部分,本例我们通过在各个环节采用时间戳的方式进行统计。实时因子计算部分的具体方式是在数据注入引擎时打一个时间戳 ReceiveTime ,在数据计算结束时打一个时间戳 HandleTime ,取差值即可得到引擎计算因子的耗时。模型实时预测部分的具体方式是在模型推理结束时打一个时间戳 PredictedTime,取 PredictedTime 和 HandleTime 的差值得到模型推理耗时。
通过将一天的原始快照数据以 100 倍速回放,我们测试了一只股票通过 LSTM 模型进行实时预测的耗时,单次响应总时延约 9.8 毫秒。测试环境软硬件配置见附录,模型结构见 3.4 小节。
| 平均时延(毫秒) | 95分位时延(毫秒) | 最小时延(毫秒) | 最大时延(毫秒) | |
|---|---|---|---|---|
| 因子计算时延 | 2 | 2 | 2 | 2 |
| 模型推理时延 | 7.5 | 8.7 | 7 | 12 |
| 总时延 | 9.8 | 10.7 | 9 | 14 |
性能统计脚本:
stat = select (HandleTime-ReceiveTime)/1000/1000 as factorDelay, (PredictedTime-HandleTime)/1000/1000 as predictDelay, (PredictedTime-ReceiveTime)/1000/1000 as totalDelay from result10min select avg(factorDelay), percentile(factorDelay, 95), min(factorDelay), max(factorDelay), avg(predictDelay), percentile(predictDelay, 95), min(predictDelay), max(predictDelay), avg(totalDelay), percentile(totalDelay, 95), min(totalDelay), max(totalDelay) from stat复制
5. 总结
结合金融市场中常见的预测股票实时波动率场景,本文介绍了 DolphinDB 在深度学习实践的各个环节中的解决方案,充分发挥其在大规模数据计算和流计算上的速度优势,迅速处理实时数据,得到实时因子表及实时预测结果表。用户可以根据实际业务场景,进行适当调整和修改。
附录
开发环境:
- CPU:AMD EPYC 7513 32-Core Processor @ 2.60GHz
- 逻辑 CPU 总数:128
- GPU:NVIDIA A800 80GB PCIe
- 磁盘:NVMe * 1块
- CUDA 版本:12.4
- OS:64 位 CentOS Linux 7 (Core)
- DolphinDB 版本:3.00.2.3 2024.11.04 LINUX_ABI x86_64 shark版本
- DolphinDB Python API 版本:3.0.2.3
- Python 版本:3.12.9
评论

 0 点赞
0 点赞