




写在文章开头
你好,我叫sharkchili,目前还是在一线奋斗的Java开发,经历过很多有意思的项目,也写过很多有意思的文章,是CSDN Java领域的博客专家,也是Java Guide的维护者之一,非常欢迎你关注我的公众号:「写代码的SharkChili」,这里面会有笔者精心挑选的并发、JVM、MySQL数据库专栏,也有笔者日常分享的硬核技术小文。
在业务体量还不是很大的时候,单库单表即可满足业务上的需求,随着业务体量的增大,无论是CPU还是IO都可能出现性能瓶颈,由于大量连接达到单库上,导致单库无法承载这些活跃的连接数,这使得我们从Java进程的角度看来就是数据库连接很少或者没有连接可用,最终出现并发、吞吐全面下降甚至是系统崩溃。
所以笔者整理了这篇分库分表的文章来逐一分析拆解这些问题。
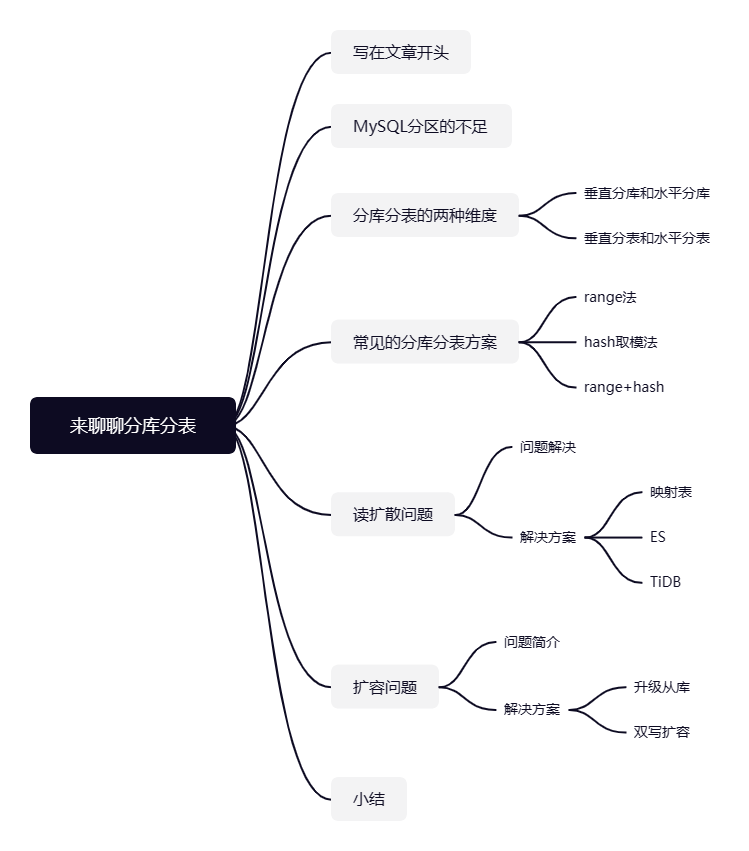
这里我们补充一下IO瓶颈和CPU瓶颈,关于IO瓶颈,即是数据表中存在大量热点数据,大量的请求都需要到数据库进行查询,因为大量的IO请求进来导致数据库连接数不足导致性能瓶颈这就是所谓的IO瓶颈,针对这种情况我们可以考虑根据热点数据类型采取垂直分表或者分库的方式解决。
就像下面这种情况,因为有大量请求专门查询用户名和地址,所以我们采用垂直分表的方式将热点数据拆出来,热点数据量直接减小,那么IO瓶颈也就小了,如此便可通过添加中间件等方式解决问题。
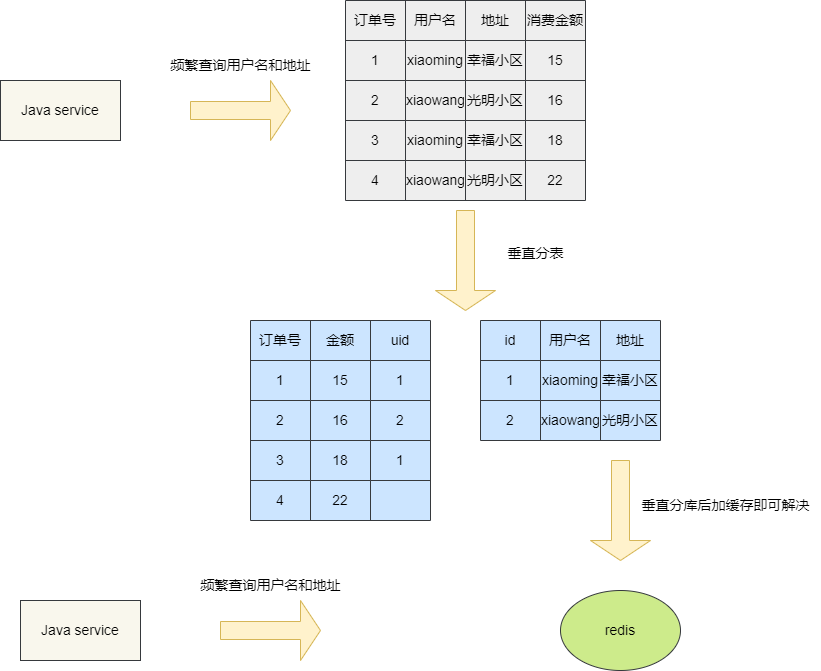
假如热点数据在垂直分表后,数据量可以减小,那么我们就采取垂直分表结合缓存中间件的方式解决。如果热点数据无法通过垂直分表或者说通过垂直分表后数据规模仍然很大的话,那么我们就必须通过水平分库解决了。
而「CPU瓶颈」则是因为表关联join或者各种运算例如「group by」,「order by」等导致查询效率低下,这种情况如果无法通过索引或者业务代码层面进行计算的方式解决的话,那么就只能通过水平分表解决了。
你好,我叫sharkchili,目前还是在一线奋斗的Java开发,经历过很多有意思的项目,也写过很多有意思的文章,是CSDN Java领域的博客专家,也是Java Guide的维护者之一,非常欢迎你关注我的公众号:「写代码的SharkChili」,这里面会有笔者精心挑选的并发、JVM、MySQL数据库专栏,也有笔者日常分享的硬核技术小文。
使用MySQL分区表不行吗?
可能也会有读者问到,为什么不采用MySQL分区表呢? 这里我们需要了解一下MySQL分区表的工作原理,它会将分区的数据表在在物理层面进行分区,但在逻辑上还是一张表,这使得用户在查询的时候对分区是没有感知的。所以说使用MySQL分区会带来以下好处:
在一定的数据量情况下,使用分区键进行查询可以快速定位数据。 因为分区会在物理层面进行切分,所以对于需要定期删除分区数据的场景下,MySQL分区是非常方便管理的。
而同样的它也存在如下缺点:
无法创建外键,当然这对于现代开发规范来说这一点没有太大影响。 并发量上来了依然存在IO瓶颈。 查询时必须带上分区键,否则会对所有分区进行扫描。 对分区查询时的优化都是由MySQL优化器自定义,对用户来说是黑盒可控性较差,不如分库分表灵活。
分库分表的两种维度
垂直分库或者水平分库
垂直分库是解耦服务间依赖的常见手段,在传统单体架构时,我们的所有的数据表都在一个数据库中。随着业务体量的增加,为了针对业务进行优化,我们可以将不同业务进行圈表拆分到不同库中,这就是垂直分库,通过垂直分库进行针对性优化,从而针对这些业务孵化出一个业务模式,达到服务化。
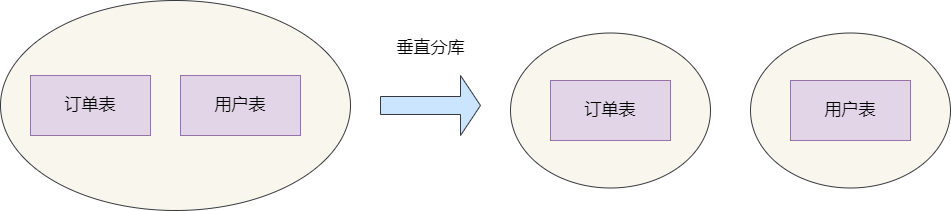
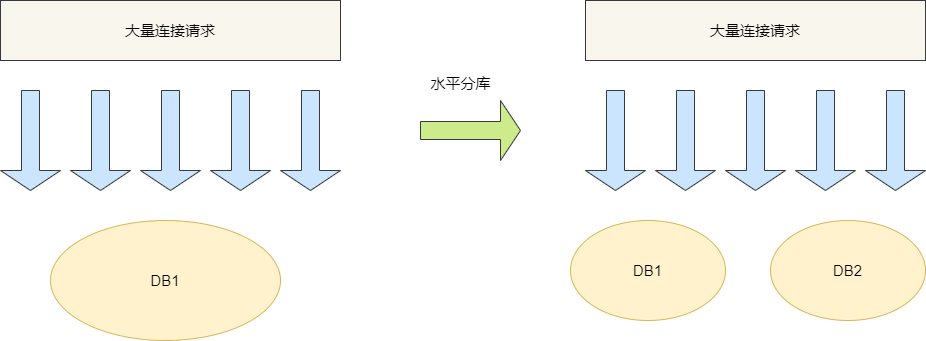
因为高并发导致单点数据库无法承载这些连接,所以我们将相同结构的数据表放到不同的数据库,然后用户通过分库算法定位到这些数据进行操作,以减轻数据库的io和cpu压力,这就是典型的水平分库。
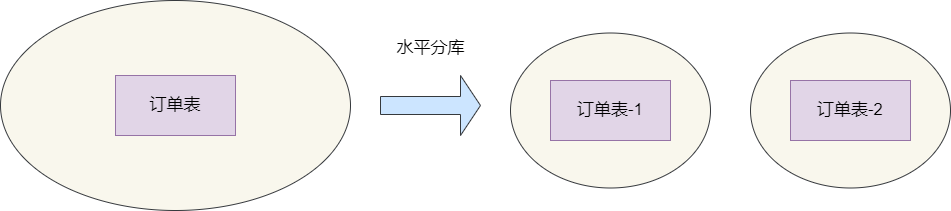
垂直分表和水平分表
如果仅仅是为了提升数据查询的速度,分表就以足够了,关于常见的分表技术有垂直分表和水平分表,其中垂直分表主要是优化查询的一种常见手段,从物理角度来说,它就是将一张表垂直进行拆分以实现确保将热点数据与非热点数据进行隔离,确保每次进行查询时缓存行可以尽可能缓存更多的字段,避免到磁盘进行随机IO导致的IO瓶颈。

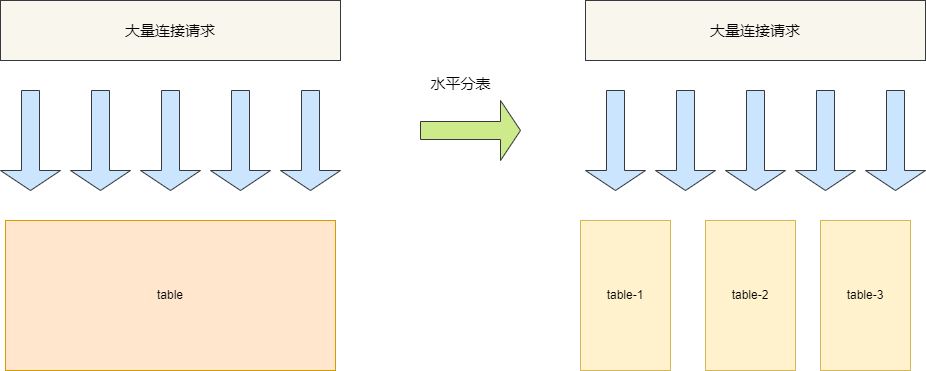
水平分表则是为了解决大数据存储和查询问题,从物理角度来说它就是将大数据表横切一刀分为无数张小表,然后所有的操作都需要针对体积更小的小表进行操作,从而减轻CPU负担,提升查询效率。
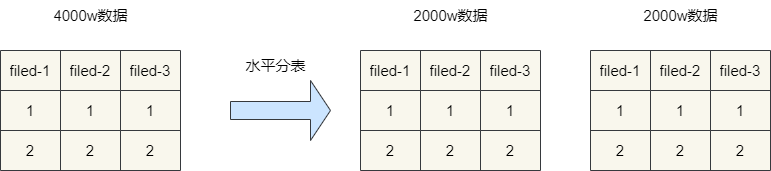
常见的分库分表方案
简介
为保证分库分表后数据能够被准确的定位并查询到,分表的策略也是很重要的,这里笔者列出几种比较常见的分表方案:
range法 hash法 range+hash法
range法分表
rang法实现比较简单,就是针对每个表都指定一个id范围,假设我们现在有3张分表,分表1存储1-500w的数据,分表2存储500w-1000w的数据,分表3存储1000w-1500w的数据。因为每个表范围是固定的,那么我们在进行数据查询时就很方便了,例如我们想查询id为1500的订单详情,直接通过id%500w即定位到分表0。
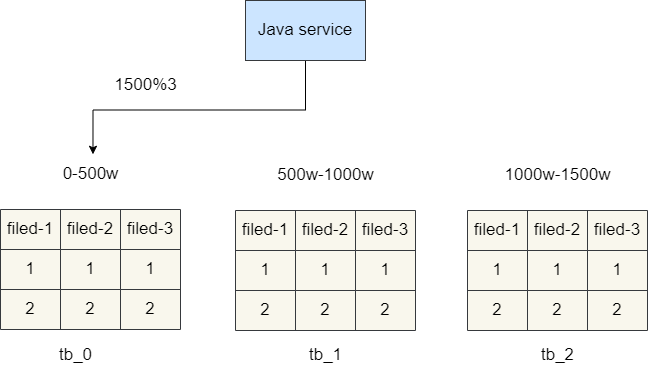
这种方案在数据查询比较均衡的情况下表现良好,遇到热点问题就比较棘手了,例如双十一淘宝订单都集中在分表3和分表4,这就会导致这两张表单位时间内承载大量查询和操作请求,而其他表却无法去负担这些压力。
hash取模法
于是就有一种均摊数据的分表算法即「hash」取模法,这种算法要求我们尽可能在功能实现前,评估将来的数据量,例如就是「5000w」,那么我们就设置「10」张表,每张表「500w」。后续进行插入操作时我们只需根据自增id值进行取模运算然后均摊存储到不同表即可。例如:我们现在有一条数据得到id为「1000」,通过「1000%10=0」,由此可知这条数据就可以存到「tb_0」表中.
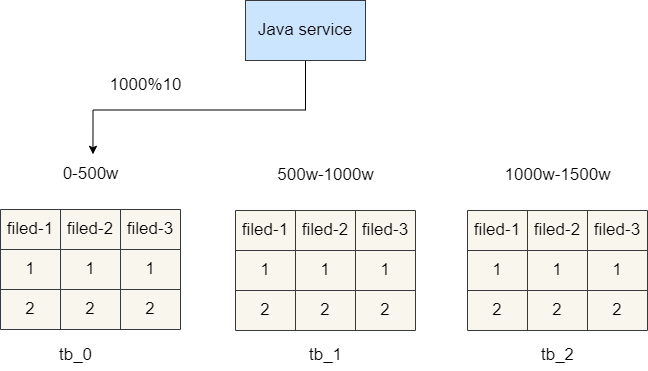
hash分表算法虽然可以均摊数据存储,避免数据热点问题,但是也存在一定的缺点,即查询问题,假如我们现在只有3张分表,id算法为「id%3」,一旦数据体量增加,我们的分表需要增加到6张,那么规则就需要改变了,很明显这种改动量存在的风险是非常大的。
range+hash法
由上可知range法可以很好的进行扩容,而hash法可以完美的均摊存储。所以我们更建议使用「range+hash法」进行分库分表,通过「range法」决定当前存储的区域,再结合「hash取模法」指定这个区域中具体的一张表。
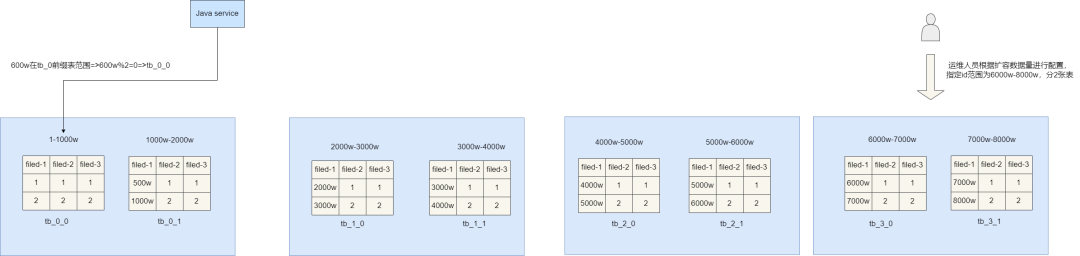
例如: 举个例子,笔者现在根据业务需求对数据表进行拆分得到6张分表,每张表存储「1000w」条数据,对应表名和含义如下:
-- tb_0前缀 存储0-2000w的数据
tb_0_0
tb_0_1
-- tb_1前缀 存储2000-4000w的数据
tb_1_0
tb_1_1
-- tb_2前缀 存储4000w-6000w的数据
tb_2_0
tb_2_1复制
根据我们上文所说,通过「range」决定区域,假设我们现在数据id为「600w」,根据上表前缀可知我们要存储的数据表为「tb_0」开头的表,因为「tb_0」开头的表有两张,由此我们再用「hash法」进行取模,即「600w%2=0」,由此可知数据最终要存到「tb_0_0」表。 我们再回过头说说扩容问题,因为我们通过「range法」决定存储的分表「area」,所以假设需要增加分表,我们也只需定义一个新的「range」范围和这个范围的分表算法即可。
就比如,我们现在就需要增加两张分表,那么我们可以直接指定这两张分表区域为3,的id范围是「6000w到8000w」,因为这个区域还是两张分表,所以算法也是「hash%2」,简单配置一下即可实现扩容,无需对代码进行改造,可以说这套方案相较于前两者会更出色一些。
非partition key查询问题(读扩散问题)
问题简介
进行分表后,对于「非partition key」的查询就由为的复杂,因为「非partition key」和「partition key」没有任何关联如果没有采取任何措施的话,查询效率就会十分低下。最简单的例子就是上文600w那条数据,他记录着一个用户的个人信息,假如我们希望通过用户名定位到他又该如何做呢?很明显在没有任何措施的情况下,只能通过逐表遍历查询解决了。
解决方案
映射法
对此我们提出第一种解决方案——映射法,即通过建立一张中间表将「partition key」和「非partition key」进行关联,以上面的例子,我们想通过name进行查询时,可直接通过映射表带入对应的name,从而得到对应的id,进而根据id得到对应的表即进行查询了。
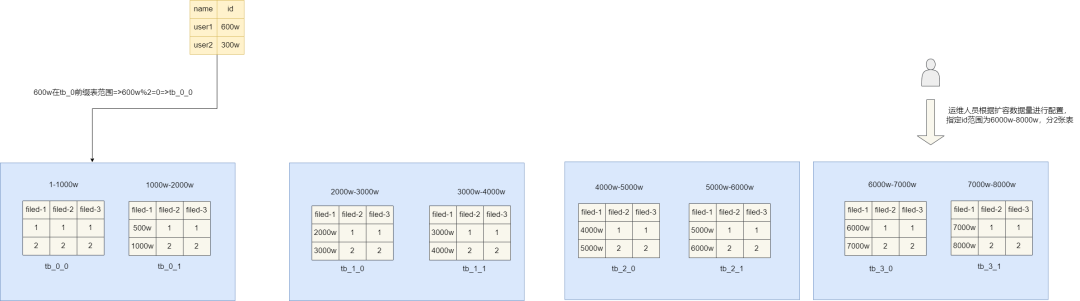
映射算法也存在一定的缺陷,其一为了查询要同时维护两套表,并且普通索引更新时对应的映射表也得更新,而且一旦数据量逐渐增大时,可能还需要对映射表进行水平拆分,再一次增加的业务实现的复杂度。
Elasticsearch
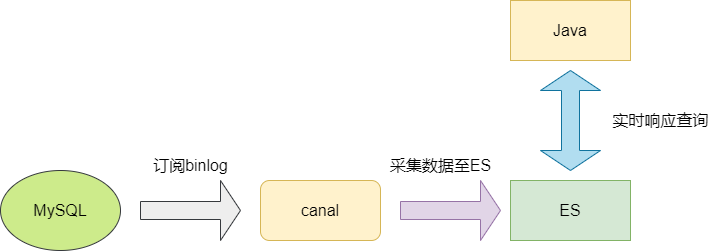
上述的映射表起始就是一种倒排索引的思想,而ES天生就是做这种事情的,针对当前问题,我们直接集成「ES」,通过开源工具「canal」监听「MySQL」的「binlog」拿到日志变更,将数据采集到ES中,通过「ES」近乎实时查询能力即可完美解决上述问题。
最终方案
这些做法要么会增加维护的困难和复杂度,亦或者需要增加新的中间件,还需要为了考虑可靠性增加更多的硬件资源。所以,如果业务允许的情况下,针对这种大数据存储,我们更建议直接采用TIDB进行数据存储,它是成熟的分布式数据存储数据库,它通过引入「range」的概念对数据表进行分片,有点类似于「range范围分表」,而支持普通索引分片类似倒排索引。且其语法和「MySQL」几乎一样,市面也有很多工具可以辅助完成数据迁移,如果项目允许的话,很明显这套数据库是最干净利落的解决方案了。
遗留分库分表扩容问题
问题简介
因为各种原有我们需要对旧有数据表进行扩容,对此数据迁移就是一个很麻烦的问题,有没有什么比较安全且易实现的方案呢?这里笔者为大家推荐两种比较常见的解决方案。
解决方案
升级从库
先说说升级从库法,这种方式就是通过升级从库为主库的方式实现数据迁移再改造hash的迁移方式。 举个例子,假设我们现在有两个分库,每个库中有一张分表,对应的分库分表算法即id%2得到库索引,然后将数据存入对应分库的分表中,例如我们现在要存储一个id为「600w」的数据,通过算法得到值为0,那么这条数据就存入「分库0」的tb表,对应的我们的从库也跟随「db0」做数据同步。 当现有主库数据已达到一定体量导致查询性能下降,我们可直接将各自的从库升级为主库,这是第一步。
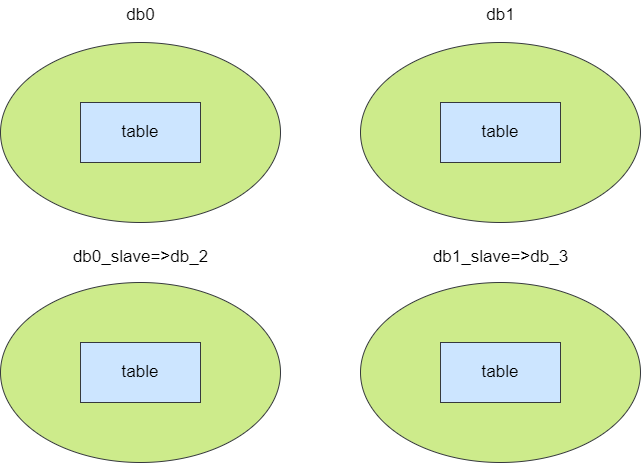
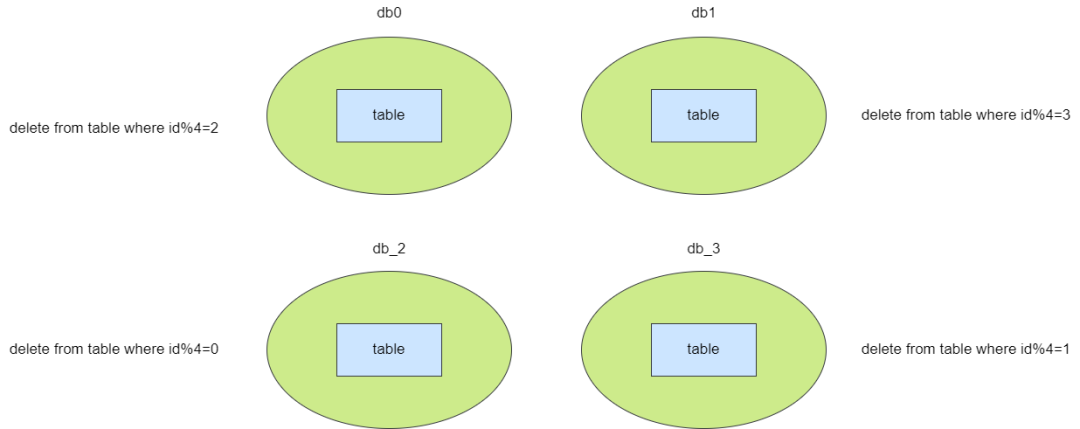
完成升级从库为主库之后,db0对应的从库变为db2,此时这两个数据的数据表是重复的,因为我们将分表算法修改为「id%4」,所以我们需要基于这个算法清除冗余数据,即主库0删除「id%4=2」(这些是升级为主库的db2数据),db1删除「id%4=3」(这个是升级为主库的db3的数据),其余两个从库同理,自此完成算法和数据迁移的升级。
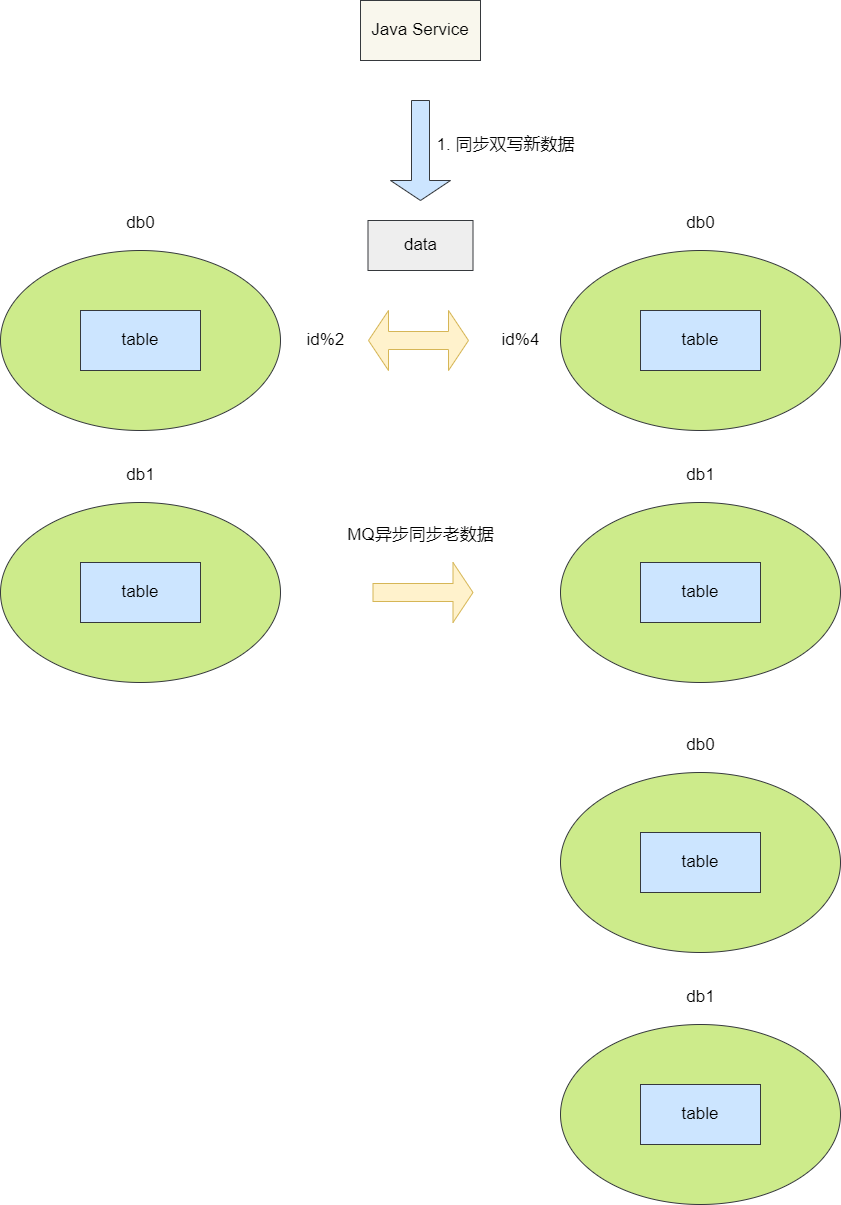
双写扩容
双写扩容是现如今比较常见的方案,步骤为:
设计一套全新的算法的分库分表将新的数据插入到新表中。 通过同步双写将新数据插入新老两库。 通过异步的方式查询老库的数据全部写到新表中。 完成迁移工作后以老库为准核对数据,核对结束后配置关闭双写,后续的数据都写入新库。
这种方案相较于前者更加稳妥,也是笔者较为推荐的一种解决方案。
小结
以上便是笔者关于分库分表的全部内容,文章大抵包含分库分表方案以及常见问题的兜底方案,后续笔者还会针对分布式ID生成方案进行整理,感兴趣的朋友可以点击关注。
我是「sharkchili」,「CSDN Java 领域博客专家」,「开源项目—JavaGuide contributor」,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号:「写代码的SharkChili」,同时我的公众号也有我精心整理的「并发编程」、「JVM」、「MySQL数据库」个人专栏导航。
参考资料
【MySQL】不建议使用分区表 :https://blog.csdn.net/u022812849/article/details/122266186
MySQL:互联网公司常用分库分表方案汇总! :https://zhuanlan.zhihu.com/p/137368446
分库分表会带来读扩散问题?怎么解决? :https://zhuanlan.zhihu.com/p/522839484
图解分库分表,写的太好了! :https://mp.weixin.qq.com/s/OI5y4HMTuEZR1hoz9aOMxg
