




DBA的日常苦恼
日常工作中,你是否有过这样的经历:由于业务上线前,磁盘容量规划和预留空间不足,且未设置任何监控设施,导致运行过程中磁盘爆满,损坏relay log,正在稳定运行的数据库突然出现告警。因此,当遇到从库relay log损坏导致数据库主从集群同步报错时,应如何快速定位并解决问题呢?话不多说,直接上案例~
DBA线上故障演练场
某天凌晨,身处客户项目现场的你正忙着给数据库做“美容”。突然收到告警,提醒从节点状态异常。DBA心中一紧,仿佛听到了“紧急状态”警报,立马像超人一样跃起,准备展开一场“数据库大战”,心里想着:“这下可真是‘凌晨的惊喜’了!”
故障分析
故障秘籍第一招:勘探故障现场,寻找蛛丝马迹
DBA立即登陆GreatDB数据库集群,发现确有节点状态异常,登录异常节点确认主从状态,结果登录失败(ps-elf过滤进程,发现该节点greatdb的进程也没了)。
故障秘籍第二招:锁定关键日志,查找问题原因
于是,DBA通过查看对应节点的errorlog,发现如下关键信息:
[Repl] Error reading relay log event for channel '': binlog truncated in the middle of event; consider out of disk space复制
一查看,原来是空间问题导致节点异常 ,确认下df -TH,果然如此。此外 ,relay log可能也损坏了。
故障秘籍第三招:快速修复故障,减少业务影响
此时,DBA立即着手清理空间,清理完毕后,将实例启动并start slave,执行show slave status\G,发现主从同步状态异常如下:
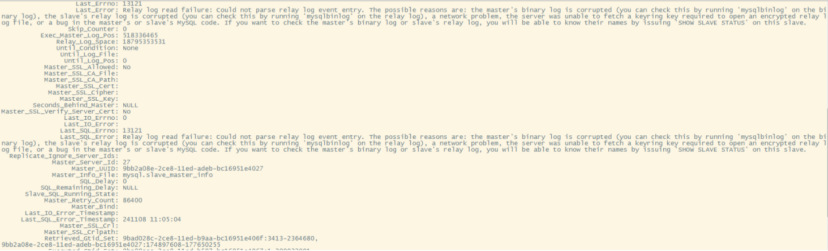
由主从报错得知relay log确实损坏了,主从同步通道启动异常;若要恢复,需要将损坏的relay log进行恢复。这里选用重置relay log,即选择重新从主库拉取的方式做恢复。
问题复现
在生产环境做恢复之前,我们先在本地测试环境中验证一下恢复步骤:
1)使用与生产环境同版本的数据库搭建本地主从测试环境,用于本地验证恢复操作,搭建步骤略;
2)主库构造测试数据,从库正常同步
SQL#主库执行create database test;use test;CREATE TABLE `t` ( `id` int(11) NOT NULL, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `a` (`a`), KEY `b` (`b`)) ;delimiter //create procedure testData()begindeclare i int;set i=1;while(i<=10000)doinsert into t values(i, i, i);set i=i+1;end while;end //delimiter ;call testData();select count(*) from t;#从库执行select count(*) from t;show slave status\G--主从数据一致,主从同步通道正常复制
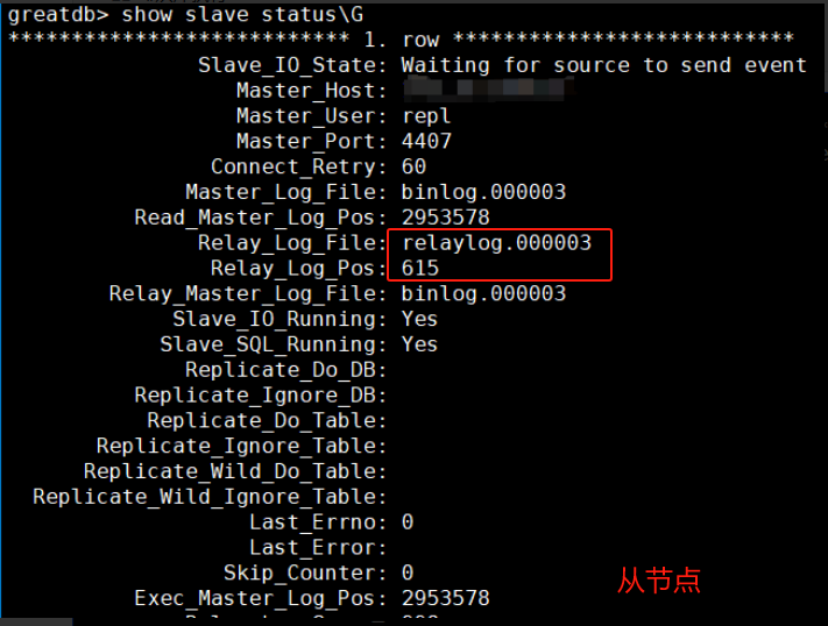
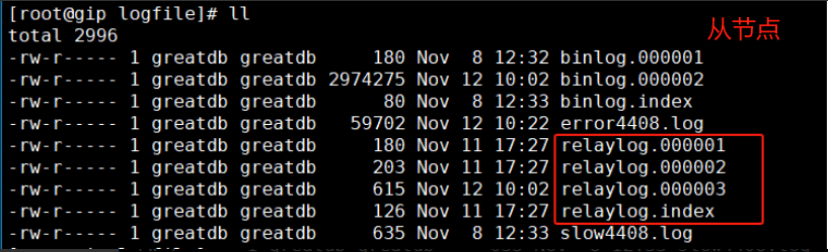
由上图得知:当前主从数据一致,同步正常,从节点应用的relay log文件为relaylog.000003 ,从库保留的relaylog文件为relaylog.000001-relaylog.000003
3)验证修复操作
从库执行stop slave; reset slave; show slave status\G,发现历史的relay log被清除,重置为初始文件relaylog.000001
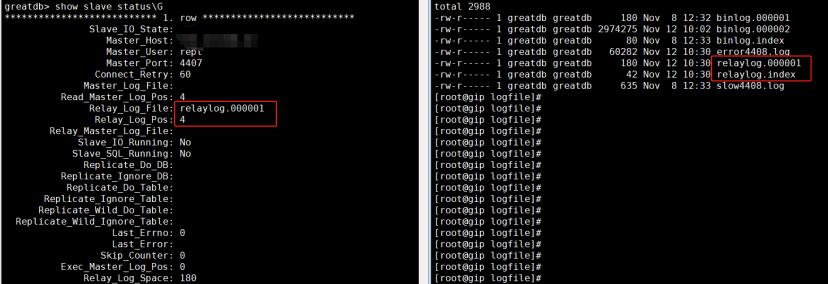
主库继续构造测试数据
create table t1 like t;insert into t1 select * from t;
从库执行start slave,此时从库从show master status获取的GTID点位开始重新拉取主库的binlog并应用
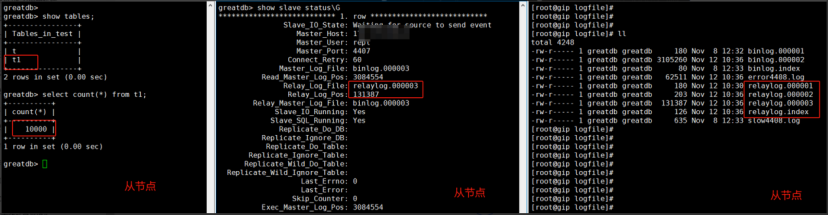
如上图,relay log成功修复,主从同步恢复正常,新建表test.t1成功同步至从库。
故障解决方案
登陆故障从节点 stop slave;reset slave;start slave;持续刷新show slave status\G,观察同步状态直到数据追平。
复盘总结
1)故障主要原因
本次故障的主要原因是空间满了导致relay log被损坏,从而导致主从同步异常。由此可见,业务上线之初要重视磁盘容量的规划,并添加必要的监控;
2)方案解读
从库执行reset slave、start slave后,从库会从show master status获取的GTID点位开始,重新拉取主库的binlog并应用;
reset slave方案可行的前提是主库对应的binlog存在;
reset slave后从库会删除所有的relay log(即使它们尚未被复制SQL线程完全执行),并启动新的relay log;
reset slave不会更改任何复制连接参数,这些参数包括:源的主机名和端口、复制用户帐户及其密码等;
故障寄语
出现故障并不可怕,可怕的是我们没有任何解决思路。如果这篇文章没有帮到你,请关注《包拯断案》专栏,期待下篇文章给你带来更多精彩干货。







