




https://www.cnblogs.com/klb561/p/10666296.html
为什么这里要讲查询算法和数据结构呢?因为之所以要建立索引,其实就是为了构建一种数据结构,可以在上面应用一种高效的查询算法,最终提高数据的查询速度。
2.1 索引的本质
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
2.2 常见的查询算法
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。那么有哪些查询算法可以使查询速度变得更快呢?
2.2.1 顺序查找(linear search )
最基本的查询算法当然是顺序查找(linear search),也就是对比每个元素的方法,不过这种算法在数据量很大时效率是极低的。
数据结构:有序或无序队列
复杂度:O(n)
实例代码:
//顺序查找 int SequenceSearch(int a[], int value, int n) { int i; for(i=0; i<n; i++) if(a[i]==value) return i; return -1; }复制
2.2.2 二分查找(binary search)
比顺序查找更快的查询方法应该就是二分查找了,二分查找的原理是查找过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。
数据结构:有序数组
复杂度:O(logn)
实例代码:
//二分查找,递归版本 int BinarySearch2(int a[], int value, int low, int high) { int mid = low+(high-low)/2; if(a[mid]==value) return mid; if(a[mid]>value) return BinarySearch2(a, value, low, mid-1); if(a[mid]<value) return BinarySearch2(a, value, mid+1, high); }复制
2.2.3 二叉排序树查找
二叉排序树的特点是:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树。
搜索的原理:
- 若b是空树,则搜索失败,否则:
- 若x等于b的根节点的数据域之值,则查找成功;否则:
- 若x小于b的根节点的数据域之值,则搜索左子树;否则:
- 查找右子树。
数据结构:二叉排序树
时间复杂度: O(log2N)
2.2.4 哈希散列法(哈希表)
其原理是首先根据key值和哈希函数创建一个哈希表(散列表),燃耗根据键值,通过散列函数,定位数据元素位置。
数据结构:哈希表
时间复杂度:几乎是O(1),取决于产生冲突的多少。
2.2.5 分块查找
分块查找又称索引顺序查找,它是顺序查找的一种改进方法。其算法思想是将n个数据元素”按块有序”划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须”按块有序”;即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,依次类推。
算法流程:
- 先选取各块中的最大关键字构成一个索引表;
- 查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;然后,在已确定的块中用顺序法进行查找。
这种搜索算法每一次比较都使搜索范围缩小一半。它们的查询速度就有了很大的提升,复杂度为。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
2.3 平衡多路搜索树B树(B-tree)
上面讲到了二叉树,它的搜索时间复杂度为O(log2N),所以它的搜索效率和树的深度有关,如果要提高查询速度,那么就要降低树的深度。要降低树的深度,很自然的方法就是采用多叉树,再结合平衡二叉树的思想,我们可以构建一个平衡多叉树结构,然后就可以在上面构建平衡多路查找算法,提高大数据量下的搜索效率。
2.3.1 B Tree
B树(Balance Tree)又叫做B- 树(其实B-是由B-tree翻译过来,所以B-树和B树是一个概念) ,它就是一种平衡多路查找树。下图就是一个典型的B树: 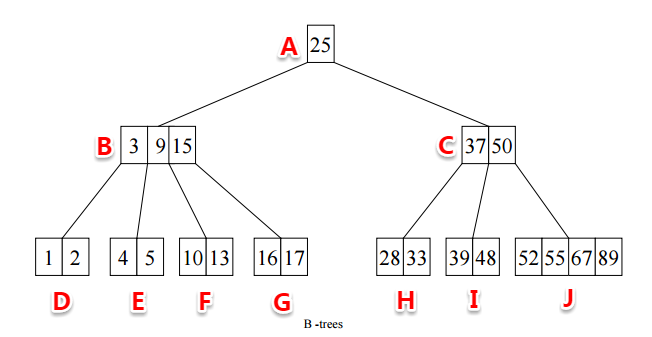
从上图中我们可以大致看到B树的一些特点,为了更好的描述B树,我们定义记录为一个二元组[key, data],key为记录的键值,data表示其它数据(上图中只有key,没有画出data数据 )。下面是对B树的一个详细定义:
1. 有一个根节点,根节点只有一个记录和两个孩子或者根节点为空; 2. 每个节点记录中的key和指针相互间隔,指针指向孩子节点; 3. d是表示树的宽度,除叶子节点之外,其它每个节点有[d/2,d-1]条记录,并且些记录中的key都是从左到右按大小排列的,有[d/2+1,d]个孩子; 4. 在一个节点中,第n个子树中的所有key,小于这个节点中第n个key,大于第n-1个key,比如上图中B节点的第2个子节点E中的所有key都小于B中的第2个key 9,大于第1个key 3; 5. 所有的叶子节点必须在同一层次,也就是它们具有相同的深度;复制
由于B-Tree的特性,在B-Tree中按key检索数据的算法非常直观:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到null指针,前者查找成功,后者查找失败。B-Tree上查找算法的伪代码如下:
BTree_Search(node, key) { if(node == null) return null; foreach(node.key){ if(node.key[i] == key) return node.data[i]; if(node.key[i] > key) return BTree_Search(point[i]->node); } return BTree_Search(point[i+1]->node); } data = BTree_Search(root, my_key);复制
关于B-Tree有一系列有趣的性质,例如一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2),检索一个key,其查找节点个数的渐进复杂度为O(logdN)。从这点可以看出,B-Tree是一个非常有效率的索引数据结构。
另外,由于插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质,本文不打算完整讨论B-Tree这些内容,因为已经有许多资料详细说明了B-Tree的数学性质及插入删除算法,有兴趣的朋友可以查阅其它文献进行详细研究。
2.3.2 B+Tree
其实B-Tree有许多变种,其中最常见的是B+Tree,比如MySQL就普遍使用B+Tree实现其索引结构。B-Tree相比,B+Tree有以下不同点:
- 每个节点的指针上限为2d而不是2d+1;
- 内节点不存储data,只存储key;
- 叶子节点不存储指针;
下面是一个简单的B+Tree示意。 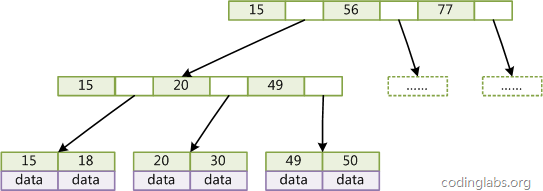
由于并不是所有节点都具有相同的域,因此B+Tree中叶节点和内节点一般大小不同。这点与B-Tree不同,虽然B-Tree中不同节点存放的key和指针可能数量不一致,但是每个节点的域和上限是一致的,所以在实现中B-Tree往往对每个节点申请同等大小的空间。一般来说,B+Tree比B-Tree更适合实现外存储索引结构,具体原因与外存储器原理及计算机存取原理有关,将在下面讨论。
2.3.3 带有顺序访问指针的B+Tree
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。 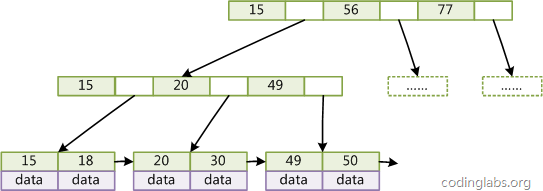
如图所示,在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
这一节对B-Tree和B+Tree进行了一个简单的介绍,下一节结合存储器存取原理介绍为什么目前B+Tree是数据库系统实现索引的首选数据结构。
