




产品介绍
PolarSearch是PolarDB基于OpenSearch研发的高性能分布式数据检索与分析引擎,兼容Elasticsearch、OpenSearch生态。您无需手动将PolarDB中的数据同步至其他数据检索平台,便可直接通过API或SDK进行文本文档、图片特征、日志等多模态数据的毫秒级全文检索、向量检索与智能分析。
借助PolarSearch,您可以进行:
1、全文检索curl -X GET "https://<endpoint>:<port>/articles/_search" -H "Content-Type:application/json" -d '
{
"query": {
"match": {
"content": "PolarSearch"
}
}
}'复制2、向量检索curl -X GET "https://<endpoint>:<port>/my-vector-index/_search" -H "Content-Type:application/json" -d ' { "size": 2, "query": { "knn": { "vector_field": { "vector": [0.1, 0.5, -0.3, 0.8], "k": 2 } } } }'复制
技术架构
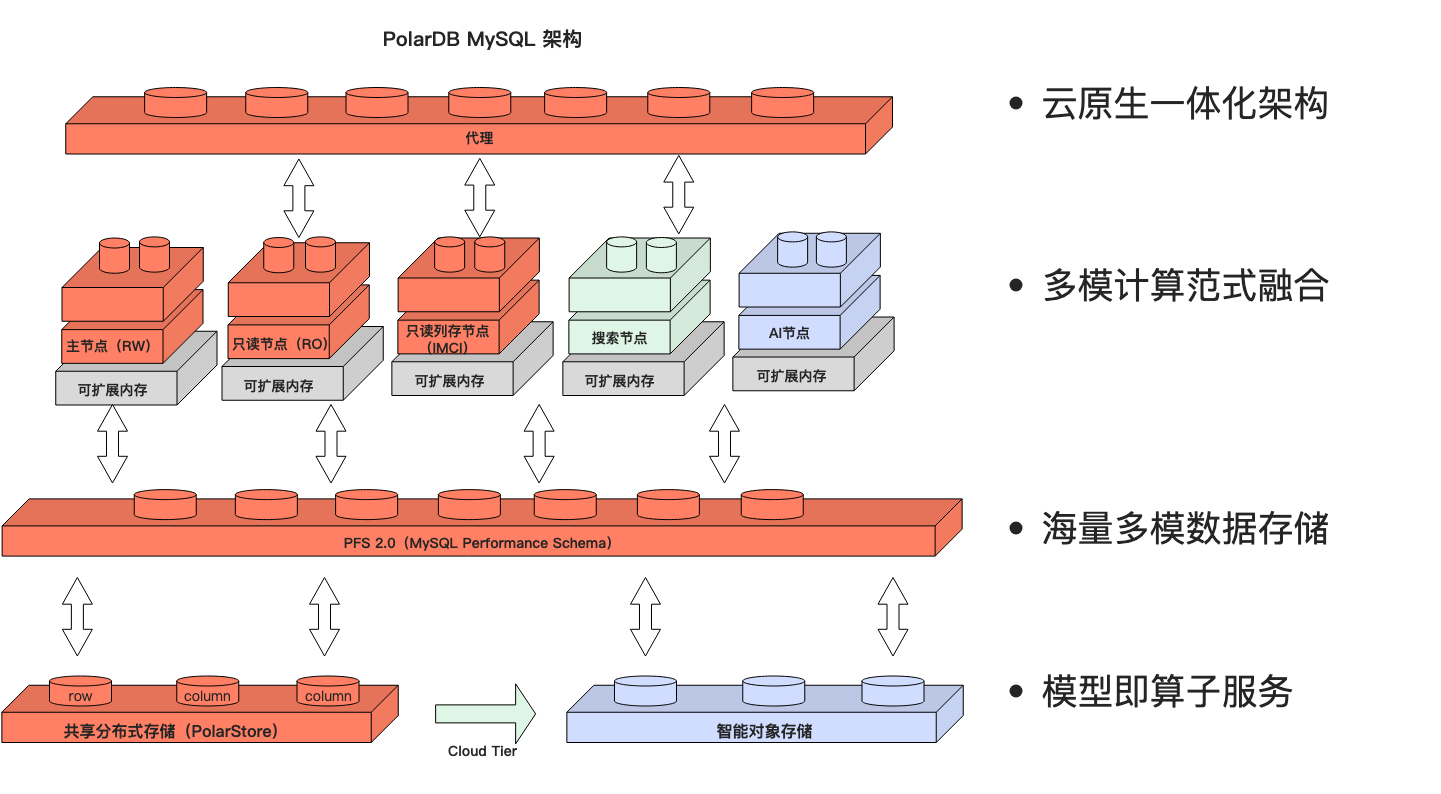
产品价值
效率提升:无需手工搭建MySQL到检索引擎的数据同步链路,检索类
workload耗时从分钟级降至毫秒级,开发周期缩短50%。成本优化:替代传统“数据库+文件存储+计算引擎”多引擎、多系统架构,基于PFS多层级分布式共享存储,TCO资源消耗降低40%。
业务创新:依托非结构化数据存储与挖掘、AI向量检索等能力,构建智能推荐、RAG知识库、Agent记忆库等AI infra基础设施。
适用场景
电商内容平台与SaaS服务
商品标题/详情页的模糊搜索、语义匹配、个性化推荐。
用户评论、UGC内容的实时关键词分析与情感挖掘。
企业RAG知识库与文档管理
PDF、Word等文档内容的全文检索与文档召回。
图片特征向量化存储,支持相似图片搜索。
Agent记忆库与智能体数据管理
短期记忆:如当前对话的上下文内容、会话上下文信息、临时变量等。
长期记忆:存储用户偏好、历史查询内容、LLM参数等长期交互数据。
日志分析与运维监控
PB级日志数据的实时检索、聚合统计与异常告警。
多维度日志字段的关联分析与可视化报表生成。
物联网与实时IoT数据流
IoT设备时序数据的海量并发写入与快速检索。
传感器数据流的多条件过滤与动态聚合。
核心特性
高可用与弹性扩展
分布式架构自动负载均衡,单节点故障无感知切换,服务可用性达99.99%。
支持在线动态扩容,存储与计算资源按需扩展,轻松应对亿级数据量。
智能搜索引擎
支持针对PolarDB RW节点中InnoDB主表数据建立倒排二级索引,提供事务级可见性。
支持对InnoDB主表数据的全文检索请求基于优化器识别并自动转发至搜索节点完成检索。
支持文本分词、语义向量化、数值范围等多维度混合索引,提升查询效率10倍以上。
内置中文NLP增强模型,实现同义词扩展、拼音纠错、意图识别等高级功能。
多模态数据融合
支持标量正排、全文倒排、向量等多种数据类型的统一存储与多路融合检索。
提供海量异构非结构化数据(如图片、文档)的存储、提取与内容解析插件。
实时检索与聚合分析
数据写入后百毫秒内可检索,支持复杂条件过滤、分桶统计及Top-K排序等操作。
内置时序数据滚动窗口计算、地理位置围栏判断等场景化函数。



