




 点击蓝字,关注我们
点击蓝字,关注我们

▍作者:汪煜 蚂蚁集团图计算开发工程师
之前在「姊妹篇」《Stream4Graph:动态图上的增量计算》中,向大家介绍了在图计算技术中引入增量计算能力「图+流」,GeaFlow [1] 流图计算相比 Spark GraphX 取得了显著的性能提升。那么在流计算技术中引入图计算能力「流+图」,GeaFlow 流图计算相比 Flink 关联计算性能如何呢?
当今时代,数据正以前所未有的速度和规模产生,对海量数据进行实时处理在异常检测、搜索推荐、金融交易等各个领域都有着广泛的应用。流计算作为最主要的实时数据处理技术也变得越来越重要。
与批处理需要等待数据全部到齐才进行计算不同,流计算将持续生成的数据流划分成微批,对每个微批的数据进行增量计算。这样的计算特性使得流计算具有高吞吐、低延迟的特性。常见的流计算引擎包括 Flink、Spark Streaming 等,他们都采用表的方式处理流中的数据。随着流计算应用的深入,越来越多的计算场景涉及到大数据之间关联关系的计算,此时基于表的流计算引擎性能会大幅下降。
蚂蚁图计算团队开源的流图计算引擎 GeaFlow,将图计算与流计算相结合,提供了高效的流图处理框架,大幅提升了计算性能。下面为大家介绍传统流计算引擎在关联关系计算的局限性,GeaFlow 流图计算高效的原理以及他们的性能对比。
1. 流计算引擎:Flink
Flink 是经典的基于表的流处理引擎,他将输入的数据流切分成微批,每次计算当前批次的数据。在计算过程中,Flink将计算任务翻译成由 map、filter、join 等基础算子组成的有向图,每个算子都有他的上游输入和下游输出。增量数据经过所有算子的计算后输出当前批次的结果。
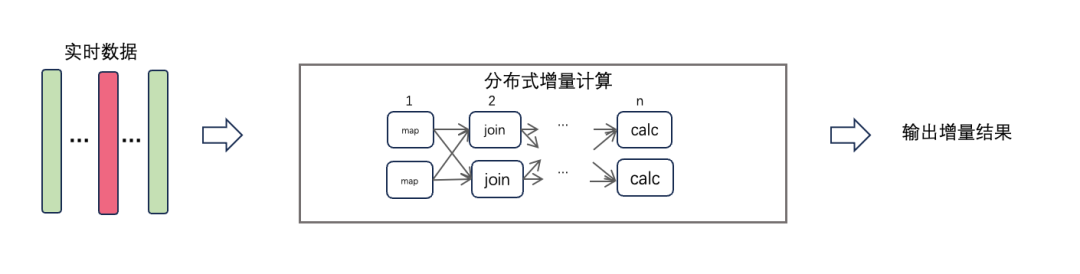 Flink 增量计算
Flink 增量计算
我们以 k-Hop 算法为例,描述 Flink 的计算过程。k-Hop 是指 K 跳关系,例如在社交网络中 k-Hop 指的是可以通过K个中间人相互认识的关系链,在交易分析中指资金的 K 次连续转移的路径。假定以2跳关系为例,输入的数据格式 src dst 代表了两两关系。Flink 的计算 SQL 如下文所示
-- create source tableCREATE TABLE edge (src int,dst int) WITH ();CREATE VIEW `v_view` (`vid`) ASSELECT distinct * from(SELECT `src` FROM `edge`UNION ALLSELECT `dst` FROM `edge`);CREATE VIEW `e_view` (`src`, `dst`) ASSELECT `src`, `dst` FROM `edge`;CREATE VIEW `join1_edge`(`id1`, `dst`) AS SELECT `v`.`vid`, `e`.`dst`FROM `v_view` AS `v` INNER JOIN `e_view` AS `e`ON `v`.`vid` = `e`.`src`;CREATE VIEW `join1`(`id1`, `id2`) AS SELECT `e`.`id1`, `v`.`vid`FROM `join1_edge` AS `e` INNER JOIN `v_view` AS `v`ON `e`.`dst` = `v`.`vid`;CREATE VIEW `join2_edge`(`id1`, `id2`, `dst`) AS SELECT `v`.`id1`, `v`.`id2`, `e`.`dst`FROM `join1` AS `v` INNER JOIN `e_view` AS `e`ON `v`.`id2` = `e`.`src`;CREATE VIEW `join2`(`id1`, `id2`, `id3`) AS SELECT `e`.`id1`, `e`.`id2`, `v`.`vid`FROM `join2_edge` AS `e` INNER JOIN `v_view` AS `v`ON `e`.`dst` = `v`.`vid`;
他的执行计划如下图所示,他由 Aggregate、Calc、Join 等算子组成,数据流经每个算子最终得到增量结果。核心算子join实现了关联关系的查找,我们来详细分析 Join 算子的实现方式。
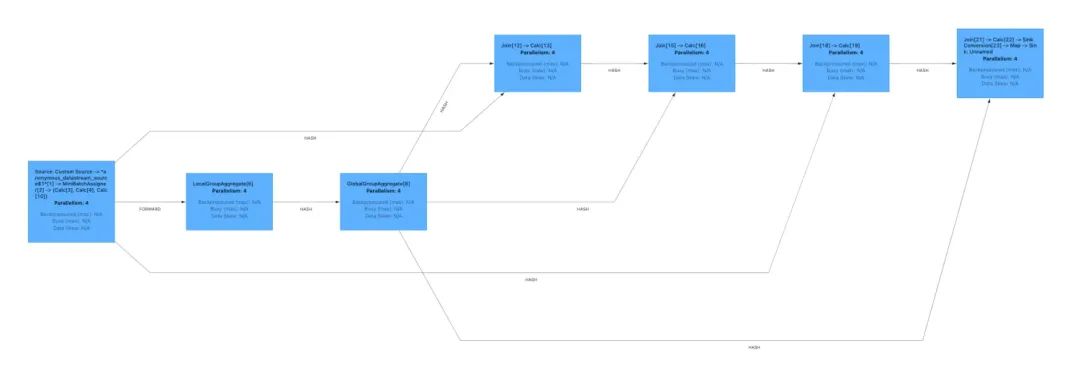 Flink 执行计划
Flink 执行计划
如下图所示,Join 算子有两个输入流 LeftInput 和 RightInput,分别代表了 join 的左表和右表,Join 算子在接收到上游的数据后执行计算。以左输入流为例,输入的数据首先被加入到 LeftStateView 中保存起来,然后去 RightStateView 中查询是否有数据符合 join 条件,这个查询过程需要遍历 RightStateView,最后将 join 结果输入到下一个算子中。
join 计算主要的性能瓶颈就在遍历 RightStateView。LeftStateView 和 RightStateView 实际上存储 join 的左表和右表。随着数据不断输入,StateView 中的数据量持续膨胀,最终导致遍历的耗时急剧上升,严重影响系统性能。
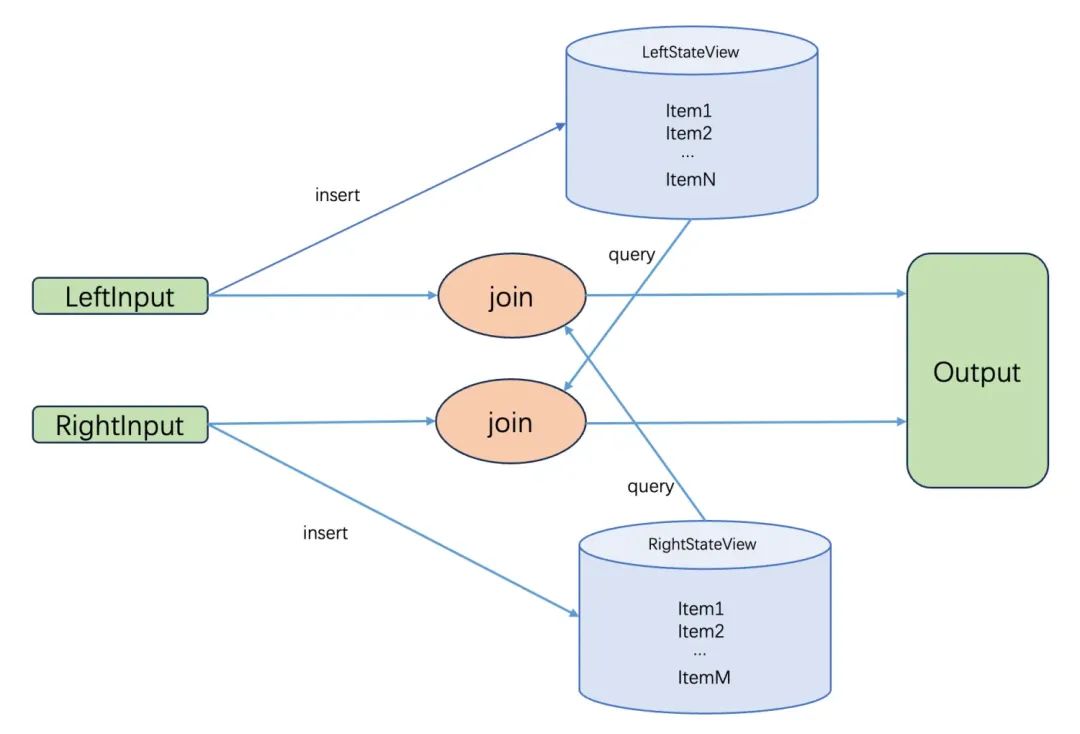
Flink Join 算子实现
2. 流图计算引擎:GeaFlow
2.1. 图计算&流图
图计算是一种基于图数据格式的计算范式,其中图 G(V,E) 由点集合 V 和边集合E构成,边代表了数据之间的关联关系。以公开数据集 web-Google 为例,其中每一行数据由两个数字组成,代表了两个页面之间的跳转关系。如下图所示,左侧是原始数据,常规的数据建模方式是建立一张包含两列数据的表,而图的建模方式是将网页作为点,将页面的跳转关系作为边,构成一张跳转网络图。在表的建模方式中,关联关系的计算是通过表的 join 实现的,join 需要遍历左表或者右表。而在图计算中,关联关系被直接存储在边中,省去了遍历的过程。
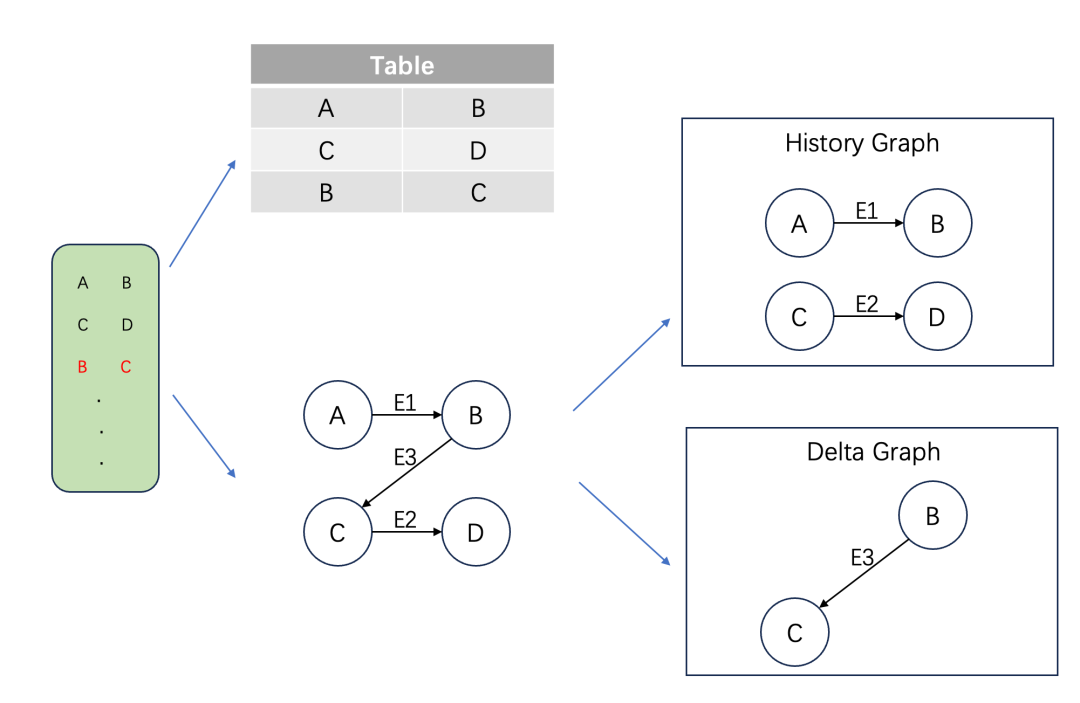
表建模 vs. 图建模
流图是图在流场景中的应用,他依据数据流对图的更新将图分成历史图和增量图两个部分。例如在上图中,假设第一行和第二行数据已经输入并完成相应计算,当前处理第三行数据。此时历史图就是由前两行数据建模得到,而增量图是由第三行数据组成的图,两者合并起来就得到完整的图。在流图上应用增量图算法,可以高效完成计算任务,实现实时计算。
2.2. GeaFlow 架构
GeaFlow 引擎的计算流程分为流数据输入、分布式增量图计算、增量结果输出几个部分。和传统的流计算引擎一样,输入的实时数据按照窗口被切分成微批。对于当前批次的数据,先按照建模策略解析成点边构成增量图。增量图和之前数据构成的历史图一道组成完整的流图。计算框架在流图上应用增量图算法得到增量结果输出,最后把增量图添加到历史图中。
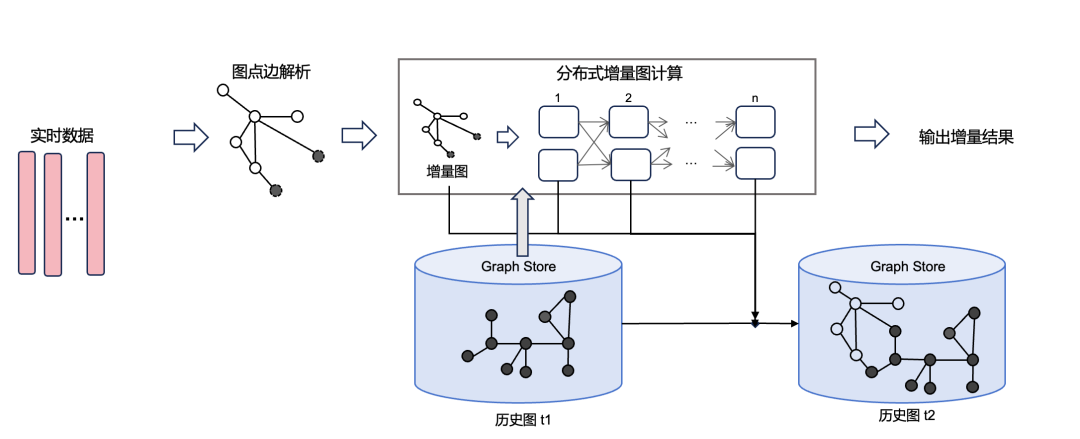
GeaFlow 增量计算
GeaFlow 计算框架是以点为中心的迭代计算模型。他以增量图中的点作为第一轮迭代的起点。在每一轮迭代中,每个点都独立维护自身的状态,根据与每个点关联的历史图和增量图完成当前迭代轮次的计算,最后将计算结果通过消息传递给邻居点,开启下一轮迭代。
以前文中提到的 k-Hop 为例,增量算法如下:在第一轮迭代中,我们找到增量图中的所有边,将这些边作为初始的入向路径和出向路径,分别发送到他们的起点和终点。在后续的迭代中不断扩展入向路径和出向路径。当达到求取跳数时,将出向路径和入向路径发送给起点,在起点组合成最终结果。详细代码实现在开源仓库的IncKHopAlgorithm.java文件中 [2]。
下图是两跳场景的描述。在第一轮迭代,增量边 B->C 分别构建入向路径和出向路径,将他们分别发送给点 B 和点 C。在第二轮迭代,B 收到入向路径,并加上当前点的入边形成2跳入向路径,发送给点 B。同样点 C 也收到出向路径,加上当前的出边形成2跳出向路径,发送给点 B。最后一轮迭代在 B 点将收到的出向和入向路径整合成新增的路径。可以看到,和 Flink 中需要查找所有的历史关系不同,GeaFlow 采用基于流图的增量图算法,计算量和图中的增量路径成正比。
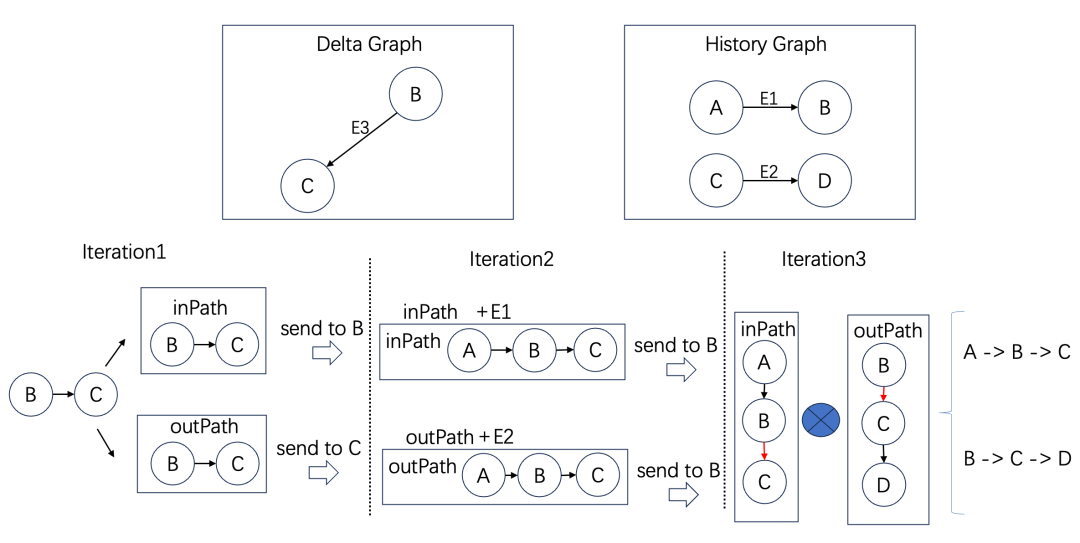
两跳增量路径计算
上述图算法已经集成到 GeaFlow 的 IncKHop 算子中,用户可以直接通过 DSL调用。
set geaflow.dsl.max.traversal=4;set geaflow.dsl.table.parallelism=4;CREATE GRAPH modern (Vertex node (id int ID),Edge relation (srcId int SOURCE ID,targetId int DESTINATION ID)) WITH (storeType='rocksdb',shardCount = 4);CREATE TABLE web_google_20 (src varchar,dst varchar) WITH (type='file',geaflow.dsl.table.parallelism='4',geaflow.dsl.column.separator='\t',`geaflow.dsl.source.file.parallel.mod`='true',geaflow.dsl.file.path = 'resource:///data/web-google-20',geaflow.dsl.window.size = 8);INSERT INTO modern.nodeSELECT cast(src as int)FROM web_google_20;INSERT INTO modern.nodeSELECT cast(dst as int)FROM web_google_20;INSERT INTO modern.relationSELECT cast(src as int), cast(dst as int)FROM web_google_20;;CREATE TABLE tbl_result (ret varchar) WITH (type='file',geaflow.dsl.file.path='${target}');USE GRAPH modern;INSERT INTO tbl_resultCALL inc_khop(2) YIELD (ret)RETURN ret;
3. GeaFlow 性能测试
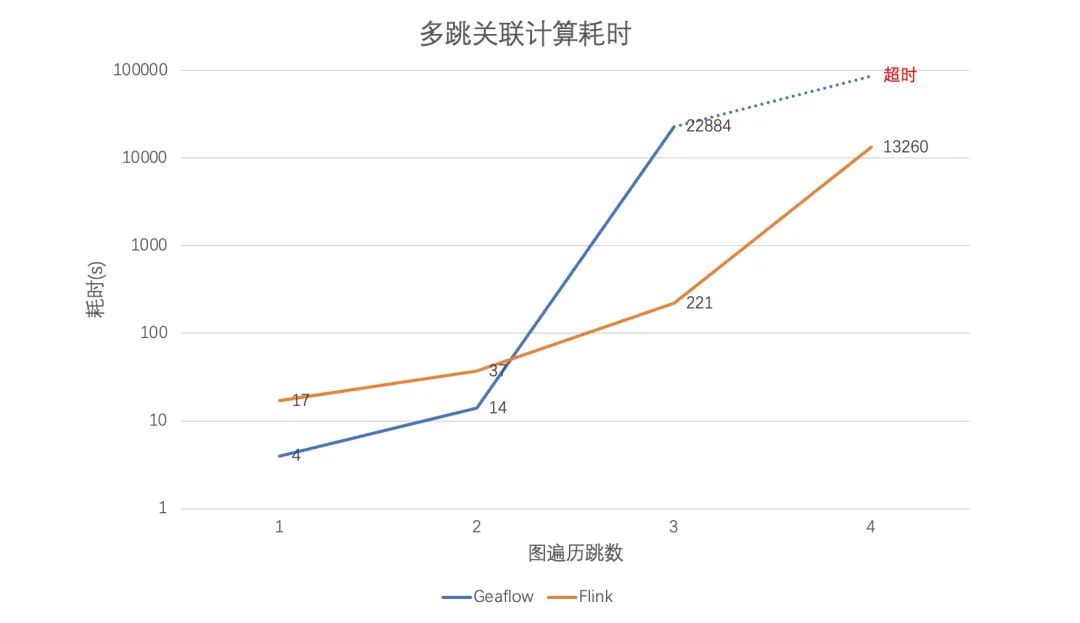
4. 总结和展望
支持增量 k-Core 算法。( Issue 466 )
支持增量最小生成树算法。( Issue 465 )
...
参考链接:
审校:范志东
·END·

欢迎关注TuGraph代码仓库✨
https://github.com/tugraph-family/tugraph-db
https://github.com/tugraph-family/tugraph-analytics
