





在生成式AI浪潮中,GPU常被视为大模型推理的唯一选择。然而,随着ARM架构的崛起和量化技术的成熟,CPU推理的性价比逐渐凸显。本文基于Amazon Graviton系列实例与llama.cpp工具链,实测了Llama 3、DeepSeek等模型的推理性能。
CPU运行大模型的核心场景
在以下场景中,CPU可作为经济高效的解决方案:
边缘推理与实时交互:低延迟需求的场景(如客服机器人、轻量化AI助手)中,CPU无需复杂硬件部署即可满足实时响应。
成本敏感型业务:通过量化技术压缩模型后,CPU可降低硬件采购与运维成本。
混合架构补充:在GPU资源受限时,CPU可作为弹性资源池处理突发请求。
隐私合规场景:部分场景需避免使用外部加速卡以简化数据流安全管控。
数据预处理和特征工程:文本处理,特征提取,数据清洗,这种依赖单线程库的,CPU 更合适。
无高频调用或高吞吐算力要求场景:CPU更适合小吞吐但是高延迟敏感、或者虽然高吞吐但是使用频率低的任务。
CPU与GPU的架构差异及性能影响
1
硬件特性对比
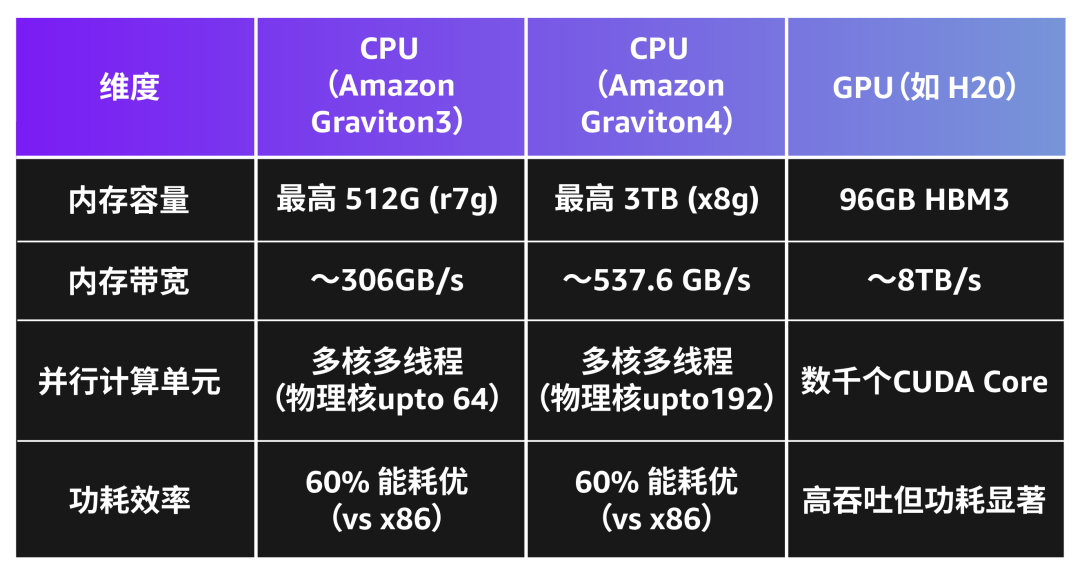
2
模型加载与推理差异
模型加载:CPU将模型权重加载到主存(RAM)中,而GPU则是将模型权重加载至显存(VRAM)中。
Prompt Token处理:CPU会将输入token从内存加载到CPU缓存中,然后逐步执行推理过程,CPU能够并行利用多个内核,推理速度与计算核心数量密切相关,但相较GPU并行能力有限;GPU会通过CUDA将输入数据加载到显存中,然后并行执行模型推理。
Token生成:CPU在生成token时需要访问大量的KV缓存,在流式推理(Streaming Inference)场景下,每个token需要不断访问已有缓存,因此容易受到内存带宽影响,相比较GPU内存带宽来讲,CPU内存带宽瓶颈往往限制token生成速度。
总结:GPU依赖并行计算单元实现高吞吐,而CPU需通过批处理与线程绑定提升效率,所以CPU更适合低并行度任务或小型模型。
Amazon Graviton
运行大模型的架构优化
1
硬件架构特性
Amazon Graviton3和Amazon Graviton4的核心改进:
Amazon Graviton3拥有15条宽发射通道和两倍更大的指令窗口,相比较Amazon Graviton2显著提升了指令级并行度。
Amazon Graviton3采用了优化的分支预测器,为更大型的模型提供了更准确的分支预测。它还配备了16位BFloat支持和256位SVE矢量计算能力,针对人工智能和机器学习工作负载进行了专门加速。
存储子系统方面,Amazon Graviton3也做出了重大改进。与Amazon Graviton2相比,它的SIMD带宽提升了一倍,内存访问带宽提高了50%。同时,它还支持2倍内存预取增强,TLS指令提速约一倍,确保数据高效流动。
Amazon Graviton4也对内存子系统进行了强化,内存带宽比Amazon Graviton3提升了75%,确保数据能够高效流动,满足人工智能和机器学习对存储带宽的旺盛需求。
2
软件栈优化措施
量化支持:基于ARM NEON指令的8-bit/4-bit量化算子优化(如GGML库)。
线程调度:绑定物理核心避免超线程争抢,NUMA-aware内存分配。
编译优化:使用GCC 11+或Clang 14+开-mcpu=native与-O3优化。
3
Amazon Graviton社区持续活跃
主流的机器学习框架都已经为Amazon Graviton3的特性做好了充分适配,包括PyTorch 2.0及更高版本、TensorFlow 1.9.1及更高版本,以及 OnnxRuntime 1.17.0及更高版本、Scikit-learn 1.0及更高版本等。
llama.cpp这种创新的开源框架,也已针对Amazon Graviton3进行了优化。
亚马逊云科技还提供了预装这些优化框架的Python Wheel文件和深度学习容器镜像,用户可以一键启动,免去手动配置的麻烦。
性能实测与对比分析
以下数据基于llama.cpp测试框架:
1
典型模型吞吐表现(量化模型)
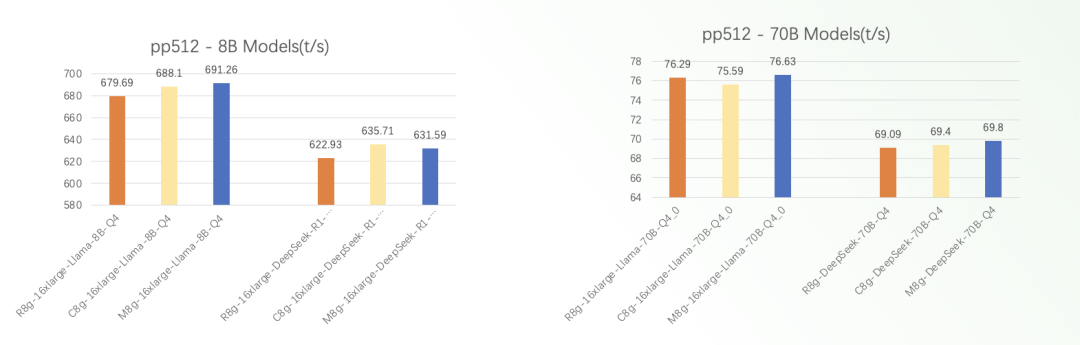
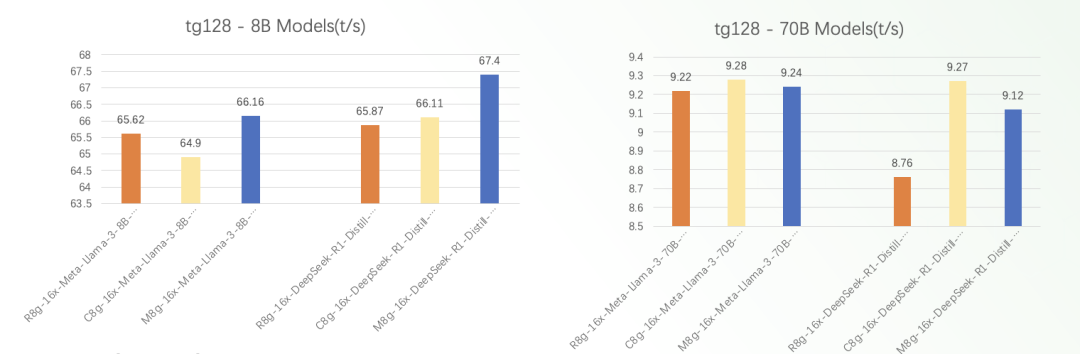
*上图测试数据针对模型meta-llama-3-8b-instruct.Q4_0.gguf和meta-llama-3-70b-instruct.Q4_0.gguf。
*pp512指标为prompt processing 512个token,tg128为生成128个token。
从图中我们可以看出:
Amazon Graviton3/4实例提供了卓越的性价比表现。
对于相同的llama模型和测试用例,亚马逊云科技新一代Amazon Graviton4实例始终拥有明显更高的推理吞吐能力,较上一代Amazon Graviton3实例的性能提升是显著的。
对于相同实例类型和线程数量,8B规模的较小模型通常会比70B的大规模模型拥有更高的吞吐量表现。
2
DeepSeek相关蒸馏模型表现
(无量化模型)
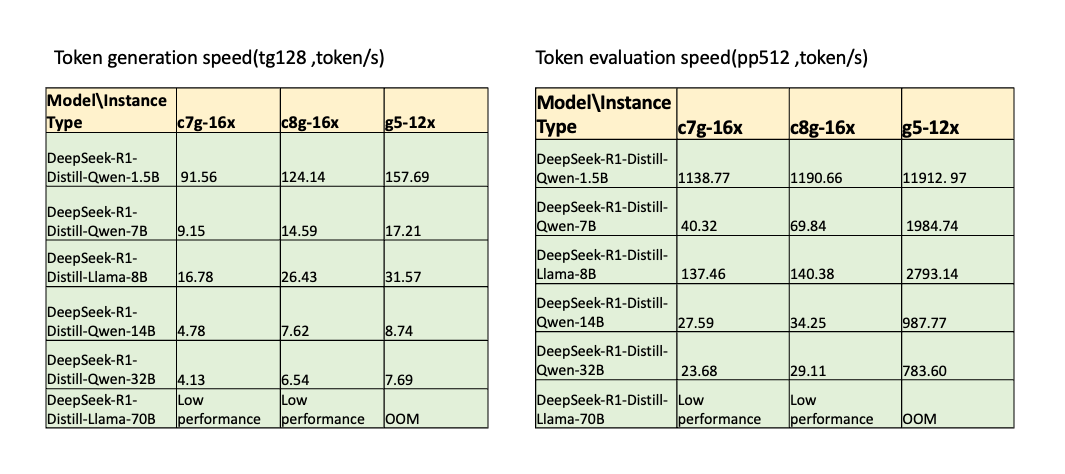
从图中我们可以看出,Amazon Graviton3实例在8B及以下无量化模型表现基本可以满足人眼阅读速度,Amazon Graviton4实例在32B及以下都能够达到或者接近人眼阅读速度,对于prompt相对较短的场景,Amazon Graviton效价比还是比较可观。
3
不同实例规格性能
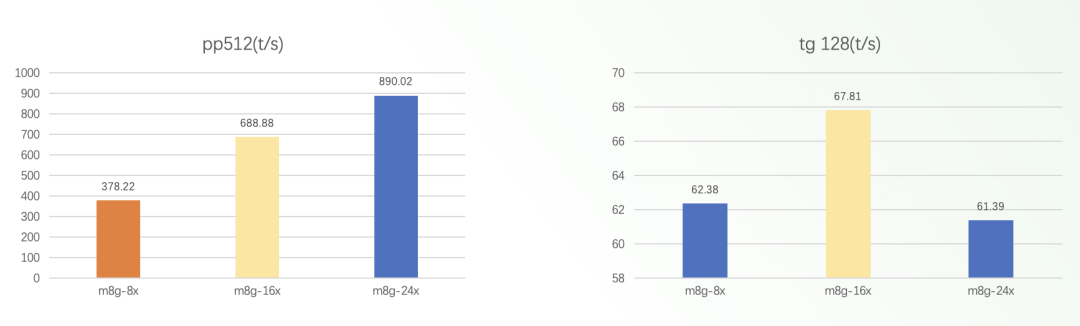
从图中我们可以看到:
随着vCPU核心数从8核增加到16核,再到24核,pp512的吞吐量也呈现出近乎线性的增长趋势,说明对于这类计算密集型的工作负载,增加更多的计算资源能够有效提升系统的prompt token处理能力。
另一方面,tg128模拟了生成128个token的场景,可以对应文本续写或对话生成等应用。但是,与pp512不同的是,tg128的吞吐量随着vCPU核心数的增加,提升空间并不太大。从8核到16核,吞吐量仅有小幅提升,进一步增加到24核时,性能提升也相当有限。
这种现象主要是由于语言模型生成任务本身的特殊性质所决定的。生成过程需要模型在每个时间步都捕捉上下文语义,并根据条件概率预测下一个token,这种高度串行化的计算模式使得单个请求的延迟降低了对并行化的需求。因此,对于像tg128这样的生成任务,单纯增加vCPU核心数不太可能带来理想的线性加速比,还需要结合其他的优化手段,比如通过模型剪枝减小参数量、利用更高带宽的内存等来进一步提升生成效率。
4
不同实例类型性能
从图中可以看出:
较小的8B模型由于参数体积更小,对计算资源的利用率更高,因此对实例硬件配置的差异会表现出更明显的性能差异。而对于70B这种大规模模型来说,由于计算和内存带宽长期处于饱和状态,不同实例类型之间的性能变化就相对不太显著了。
在部署Llama/DeepSeek等大规模语言模型时,我们不仅需要根据具体的应用场景来选择合适的实例规格,还要平衡参数量和硬件资源之间的匹配关系。只有做到有机结合,才能充分释放语言模型的潜能,实现最优的性价比。
5
关键场景性能
批处理场景测试(model:DeepSeek-R1-Distill-Llama-8B-Q4_0.gguf,instance:c8g-16x)
第一组:prompt 64 token,generate 128 token


第二组:prompt 128 token,generate 128 token

第三组:prompt 256 token,generate 128 token


第四组:prompt 512 token,generate 128 token

所以在生成128token的场景测试中,生成token的速度可以在16个batch场景下达到296 t/s。
首Token延迟
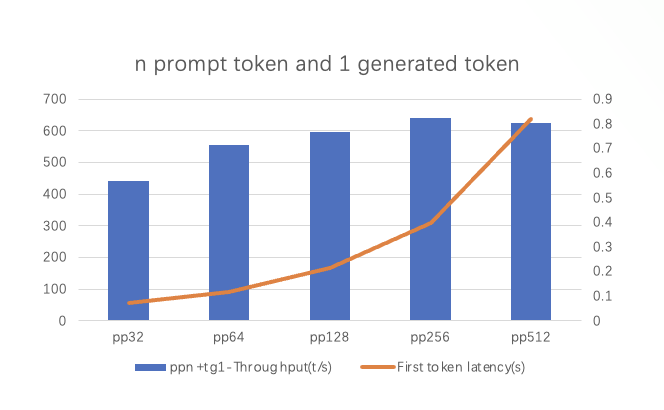
从图中我们可以看出:
吞吐量随Prompt Token增加先升后降:当Prompt Token增加到pp256或pp512时,吞吐量接近峰值,随后略有下降,即Prompt Token的数量对吞吐量的影响存在一个最佳区间。
首Token延迟随Prompt Token增加而增加:随着Prompt Token数量从pp32增加到pp512,首Token延迟显著上升。在pp512时,延迟达到最大(约8秒)。
吞吐量变化原因包括以下几个方面:
Prompt Token数量少时(如pp32):初始化开销较大,资源利用率较低,吞吐量较低。
Prompt Token数量适中时(如pp256):计算单元和硬件资源达到较优的并行处理效率,吞吐量达到峰值。
Prompt Token数量过多时(如pp512重复情况):数据传输开销增加,硬件资源的带宽限制和缓存效率下降,吞吐量略微下降。
6
TCO表现(model:DeepSeek-R1-Distill-Llama-8B-Q4_0.gguf,pp=128token tg=128token)
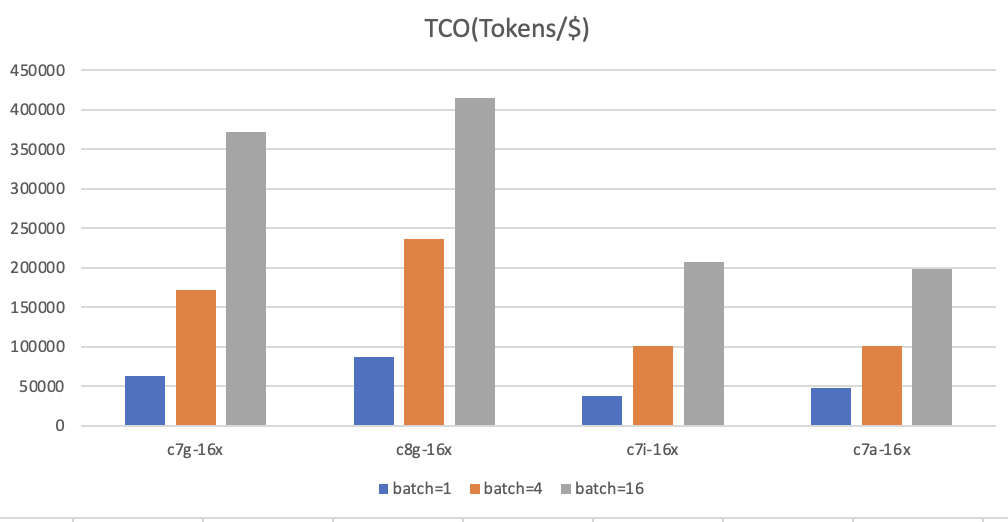
由图中可以看出,Amazon Graviton3可以在1美元cost下生成360000 token,而Amazon Graviton4可以生成多达420000+的token。这不仅说明Amazon Graviton4在CPU领域处于领先地位,而且对于那些希望从小规模开始,并在LLM应用之路上逐步扩展的用户来说,也提供了一个极具吸引力的优势。
调优实践指南
1
参数调优策略
在本地编译llama.cpp并使用-DCMAKE_CXX_FLAGS=”-mcpu=native”-DCMAKE_C_FLAGS=”-mcpu=native”编译参数,可以让llama.cpp基于本地CPU参数编译,从而达到理想性能。
llama.cpp支持多种模型量化格式,在实际生产中,在保证模型可以确保SLA的前提下可以通过减少权重精度降低内存占用和计算量,从而提高整体性能。
合理设置线程数,通常设置为物理核心数,从而充分利用实例的多核能力。
绑定CPU核心,减少跨NUMA节点的内存访问延迟。
减少上下文长度(使用合适的context长度),调整批处理策略(例如使用合理的batch-size),简化生成参数等,都可以从不同层面使得CPU达到最佳性能。
2
部署建议
以模型DeepSeek-R1-Distill-Llama-8B-Q4_0.gguf为例,在确定运行4bit量化的8B参数模型所需的虚拟机vCPU和内存配置时,需综合考虑模型存储、计算需求和系统开销:
内存需求
参数数量:8B(80亿)个参数
量化存储:4bit/参数=0.5字节/参数
总共参数量内存:
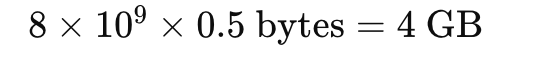
推理内存需求:激活值和中间缓存,通常为参数内存的1-3倍(8~12GB),取决于输入序列长度和模型结构。
系统与框架开销:操作系统和推理框架本身需要额外内存(约1-2GB)。
总内存估算约4+8+2=14GB
vCPU配置
由上面测试3的图可以看出因为推理框架支持多线程,增加vCPU可以提升prompt处理的吞吐量。但随着vCPU核心数增加,token生成的速度仅有小幅提升,进一步增加到24核,系统提升也相当有限。所以我们可以以8个vCPU进行初始实测,然后逐步调整力争达到客户需求的SLA。
综上所述,我们可以按照以下配置来测试:
结 语
Amazon Graviton实例通过硬件架构创新与软件优化,为CPU推理场景提供了高性价比的选择。在8B~70B参数规模的模型中,Amazon Graviton4可达到10-60 t/s的吞吐表现,结合量化技术与参数调优,可满足生产级AI应用的性能与成本需求。未来随着ARM指令集与模型编译器的进一步优化,CPU在大模型推理领域的潜力将持续释放。
本文作者

肖萍
亚马逊云科技解决方案架构师,负责亚马逊云科技计算方案的咨询与设计,致力于生成式AI应用方面的研究和推广,提升客户的使用体验。













期待你的分享 收藏 在看 点赞!
亚马逊的一小步,云计算的一大步!
点击阅读原文,获取更多精彩内容!
