




本文来说说 OB 多租户的资源隔离技术历史和原理。跟性能密切相关, OB 4.2+ 客户或公有云客户感兴趣的可以看看。
云数据库资源隔离
数据库租户最早是云数据库厂商推出的概念,云数据库(租户)(也叫 RDS)可以按需分配,资源在线弹性伸缩,事后可以多退少补。云数据库客户买云租户,按规格付费,一分钱一分货。由于花钱了,云客户对租户的能力就非常关注,担心自己的租户能力受其他客户的租户影响。占便宜没关系,吃亏是不行的。
最早的 RDS MySQL 服务就是单机部署多个 MySQL 实例。服务器的配置都是当时最新最顶配,MySQL 能力有限,不能发挥单机硬件能力,所以单机部署多个 MySQL 是架构上最优的选择。云厂商从这个里面看到商机,包装升级为 RDS MySQL 服务。
多个 MySQL 为了避免彼此影响,使用 Linux 系统的 cgroup 资源隔离技术(早期应该还是 v1 版本)。cgroup 能对 CPU、内存、IOPS和 IO 吞吐做限制。
先说内存隔离。MySQL 的内存大头主要是 Buffer Pool,似乎 MySQL 可以控制自己的内存大小。但是 MySQL 5.7 之前的版本大查询生成的磁盘上的临时表都是 MyISAM 引擎,这个会占用 Page Cache 内存。当 cgroup 对 MySQL 实例做内存限制后,很容易导致 MySQL 实例 OOM。
此外这种临时表的读写 IO 都是 buffer IO,cgroup v1 也无法做 IOPS 资源隔离,导致无法避免多实例间 IO 影响时有发生。后来 AliSQL 5.6 将临时表引擎改为 InnoDB 。MySQL 5.7 社区版本也很快看到了支持参数配置临时表的引擎为 InnoDB 。再后来据说 cgroup v2 版本可以针对 buffer IO 做 IOPS 限制了。 提这段历史,是想说资源隔离事情没有想的那么单纯。
cgroup 对 CPU 的资源隔离技术也很丰富,可以控制不同进程(和线程)的 CPU 使用时间比例或者精确控制进程(和线程)的 CPU 利用率。后来兴起的 docker 技术、k8s 技术,其资源隔离技术底层使用的依然是 cgroup 技术。
OB 多租户资源隔离
OB 在 2015 年推出 1.0 版本的时候就支持多租户,并且租户就有资源隔离的设计。最早的资源定义包括:CPU(max_cpu
和min_cpu
)、内存(max_memory
和min_memory
)、IOPS、sessions、disk_size
等。实际 OB 1.0 的租户资源隔离只是针对 CPU 和内存做了限制,这个设计一直延续到 V3.2 版本。
OB 早期做的资源隔离是在 OBServer 进程内部。OB 的设计理念就是在普通 x86 服务器上部署单进程 OBServer 软件,OBServer 启动后将主要硬件资源(CPU、内存和磁盘空间)攥在手里。多个 OBServer 进程组成了一个集群,从而输出一个超级大的资源池子。OB 优秀的地方就在于组建这个集群,在软件层面架构却非常的简单,就是多个节点的进程之间的网络通信。每个进程有两个监听端口 2881 和 2882, 分别是 MySQL 连接端口和 RPC 连接端口。OB 用一个软件就把云厂商想做的事情轻松实现了。
所以 OBServer 进程能够对拿到手的资源做内部二次划分,这就是 OB 的多租户概念。 OBServer 只需要做好内部的资源定义和配额管理即可。默认情况下资源是实打实使用的,有多少资源分配多少资源。但是 OBServer 也提供了参数resource_hard_limit
可以扩大资源的超分配(也叫超卖)。资源超卖是云厂商盈利的关键技术之一。对于 OB 而言,如果 OBServer 从主机拿到 30C200G 内存,OBServer 可以在内部租户分配出去 40C300G 内存资源。超卖的原理是利用 CPU 和 内存资源定义的min
和max
值设计。min
值的总和是不能超过 OBServer 拿到的资源,而max
值的总和会超过。超卖业务实际上就是赌大部分租户不会实际要使用这么多的资源。尤其是内存。超卖的风险就是当所有租户的实际内存总和接近 OBServer 从主机获取的内存资源总和时,就会有租户开始内存不足报错了(云厂商产品能监控物理资源利用率,动态调整资源使用或补充资源)。
在 OB V4 版本以前这个参数resource_hard_limit
都只是在内部开发测试环境用用,但 OB V4 版本后 OCP 开始提出“资源超卖”这个概念了,并且推荐在生产环境使用。 因为 OB V4 版本彻底废弃了内存资源定义的min
和max
设计。这个设计的风险就是内存超卖的风险。所以 OB V4 后的资源超卖就只有 CPU 资源。
CPU 能力是硬件的,只有操作系统才能做进程 CPU 时间片的管理,也只有操作系统才有权利和能力做 CPU 资源隔离这种事情。OB 早期版本的 CPU 资源隔离实际上都是 OBServer 进程内部对多个租户的线程的 CPU 配额的使用管理。这种 CPU 资源隔离我称之为逻辑隔离。在不超卖的情况下,OBServer 声称拿到的 CPU 个数为主机 CPU 超线程后核数减去 2 。
比如说 OBServer 名义上拿到了 30 个 CPU ,然后开始内部分配这个 CPU 资源的使用。每个 CPU 默认对应租户 10个 worker 线程。这些设计跟 OS 都没有太大关系。如果 OB 集群里只有一个租户,且租户只有 4个 CPU (min_cpu
和max_cpu
都是4),对这个租户进行高并发读写压测,在主机层面 OBServer进程的 CPU 利用率是一定会超出 400% 很多的, OBServer实际使用的 CPU 个数也远不止 4个。这是完全正常的,因为 OBServer 并不会约束自己使用的 CPU 个数,在 OB 集群内部,也没有其他租户跟这个租户竞争 CPU 资源,所以这个租户对 CPU 资源的使用会超出它应得的。
如果有两个租户 A 和 B,CPU 配额分别是 4C 和 8C ,OBServer 保证的是如果两个租户对 CPU 资源最大使用时,A 能得到的CPU时间和B 的一半。即 OBServer 保证这里面 CPU 使用率相对公平。但是如果 B 租户不忙,A 租户很忙,A 租户的线程集合在主机层面的 CPU 利用率之和依然是超出 4 个物理 CPU 的能力。反过来 A 不忙 B 很忙,也是一样的。如果熟悉 cgroup 的 CPU 隔离中cpu.shares
的使用,就会发现功能很类似(不是什么高深的东西,就是资源管理技术,跟生活中资源大管家的工作思路差不多)。然后 OBServer 还允许min_cpu
跟max_cpu
不一样,这个实际情况就更复杂了,对 DBA 管理 CPU 资源也带来很大的复杂度,所以我的建议都是设置为一样的值。
这个可能跟大家想的不一样,但是这个结果实际上确实是有好处的,CPU 资源不会因为资源隔离而出现浪费。在 OB 企业客户里,非核心业务和核心业务往往是在集群层面就分开了(物理隔离),所以不用担心核心集群租户的资源能力被不重要的业务租户影响。尽管如此,也有不少 OB 用户会认为这是个问题。这个问题的争论最终会上升到管理层面。多租户资源隔离需求可能是想风险和责任的隔离。这也有一定合理性。
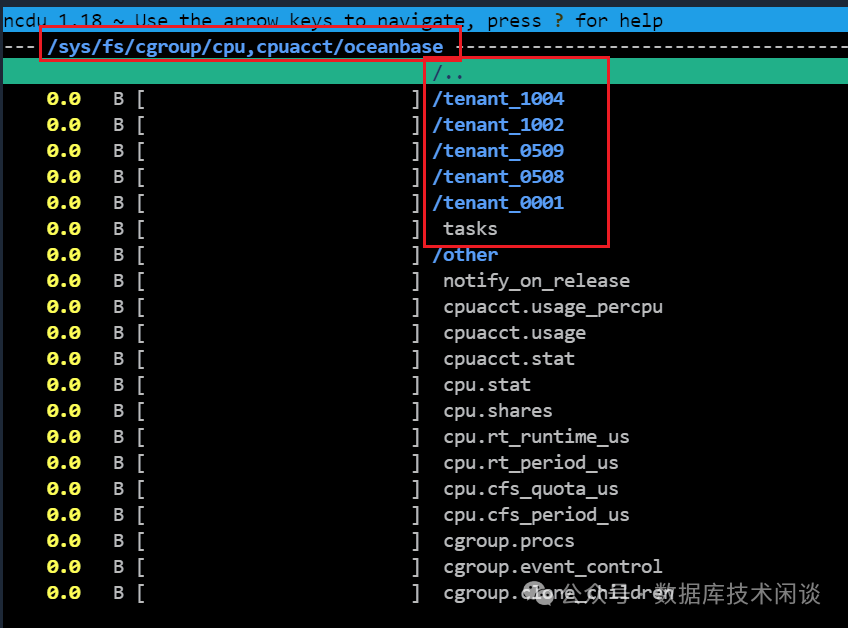
所以 OB V3.2 开始推出了新的参数enable_cgroup
,引入 cgroup 的资源隔离技术。OB V4.0 一开始就有这个参数,并且默认值就是开启(true
)。开启后,OB 会在租户创建和资源规格调整的时候,在 cgroup 文件系统相应目录下/sys/fs/cgroup/cpuacct/
下创建 oceanbase 和租户的子目录,并且在租户的子目录里cgroup.procs
里写入 OBServer 进程ID ,在tasks
里写入对应租户的线程 ID。
然后同时使用cpu.shares
和cpu.cfs_quota_us
两种 CPU 资源隔离技术。 截止到这里,还不涉及 CPU 超卖设置。
如果 OB 要开启超卖设置,首先要调大集群参数resource_hard_limit
大于 100 。然后就可以设置租户的min_cpu
和max_cpu
值不一样。跟前面一样,所有租户的min_cpu
之和不能超出 OBServer 获取的 CPU 资源(也是参数cpu_count
值,为0表示自动获取),所有租户max_cpu 的值之和不能超出 cpu_count * resource_hard_limit 100 。
OB 引入 cgroup 的 CPU 资源隔离技术后,超卖后的逻辑就好解释了。如果两个租户只有一个忙,这个租户最大能用的 CPU 个数就是其max_cpu
定义的(cgroup会牢牢限制其CPU利用率上限);如果别的租户也很忙,这个租户最大能用的 CPU 个数会接近其min_cpu
份额(这个是cgroup
的cpu.shares
定义的),其他忙的租户也是同理。也就是所有租户都忙的时候,那大家对 CPU 的配额分布就按cpu.shares
定义的配额来分。 这一段涉及到 cgroup 的原理,有兴趣的可以网上搜索一下。
OB 4.2 多租户资源隔离示例
这里我们就直接看一个案例。先看 OB 里租户的资源定义。
select t1.name resource_pool_name,
t2.max_cpu, t2.min_cpu,
round(t2.memory_size/1024/1024/1024,2) mem_size_gb,
t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,
t4.tenant_id, t4.tenant_name
from __all_resource_pool t1
join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
leftjoin __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
orderby t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;复制
两个租户的min_cpu
分别是 2 和 4,max_cpu
分别是 6 和 8 。然后我们看cgroup
文件里的值。
[root@server065 oceanbase]# pwd
/sys/fs/cgroup/cpuacct/oceanbase
[root@server065 oceanbase]# ls
cgroup.clone_children cpu.cfs_period_us cpu.rt_runtime_us cpuacct.stat notify_on_release tenant_0001 tenant_1002
cgroup.event_control cpu.cfs_quota_us cpu.shares cpuacct.usage other tenant_0508 tenant_1004
cgroup.procs cpu.rt_period_us cpu.stat cpuacct.usage_percpu tasks tenant_0509
[root@server065 oceanbase]# grep . -Hn */cpu.shares
other/cpu.shares:1:1024
tenant_0001/cpu.shares:1:6144
tenant_0508/cpu.shares:1:5120
tenant_0509/cpu.shares:1:2560
tenant_1002/cpu.shares:1:4096
tenant_1004/cpu.shares:1:2048复制
从这里可看出cpu.shares
最小单位是 1024,tenant_0001
占比是 6,tenant_1002
占比是 4,tenant_1004
占比是 2,分别对应 OB 3个租户资源规格的min_cpu
值。这里也看到了通常说的 500 租户(tenant_0508
和tenant_0509
)也给了最低的 CPU 配额。
[root@server065 oceanbase]# grep . -Hn */cpu.cfs_*_us
other/cpu.cfs_period_us:1:100000
other/cpu.cfs_quota_us:1:-1
tenant_0001/cpu.cfs_period_us:1:100000
tenant_0001/cpu.cfs_quota_us:1:-1
tenant_0508/cpu.cfs_period_us:1:100000
tenant_0508/cpu.cfs_quota_us:1:500000
tenant_0509/cpu.cfs_period_us:1:100000
tenant_0509/cpu.cfs_quota_us:1:250000
tenant_1002/cpu.cfs_period_us:1:100000
tenant_1002/cpu.cfs_quota_us:1:800000
tenant_1004/cpu.cfs_period_us:1:100000
tenant_1004/cpu.cfs_quota_us:1:600000复制
再看上面输出,CPU 时间片单位时间都是 100000us (即100ms),tenant_0001
占比是 -1(不受限制,这是对的,限制sys
租户的 CPU 资源的想法是错误的),tenant_1002
占比是 8,tenant_1004
占比是 6 ,后两者值分别对应租户的max_cpu
值。
以上是理论分析,还需要实践验证。 cgroup 提供了一个命令systemd-cgtop
可以观察各个资源组的 CPU 利用率。
[root@server065 oceanbase]# systemd-cgtop -h
systemd-cgtop [OPTIONS...]
Show top control groups by their resource usage.
-h --help Show this help
--version Print version and exit
-p Order by path
-t Order by number of tasks
-c Order by CPU load
-m Order by memory load
-i Order by IO load
--cpu[=TYPE] Show CPU usage as time or percentage (default)
-d --delay=DELAY Delay between updates
-n --iterations=N Run for N iterations before exiting
-b --batch Run in batch mode, accepting no input
--depth=DEPTH Maximum traversal depth (default: 3)复制
输出结果如下:
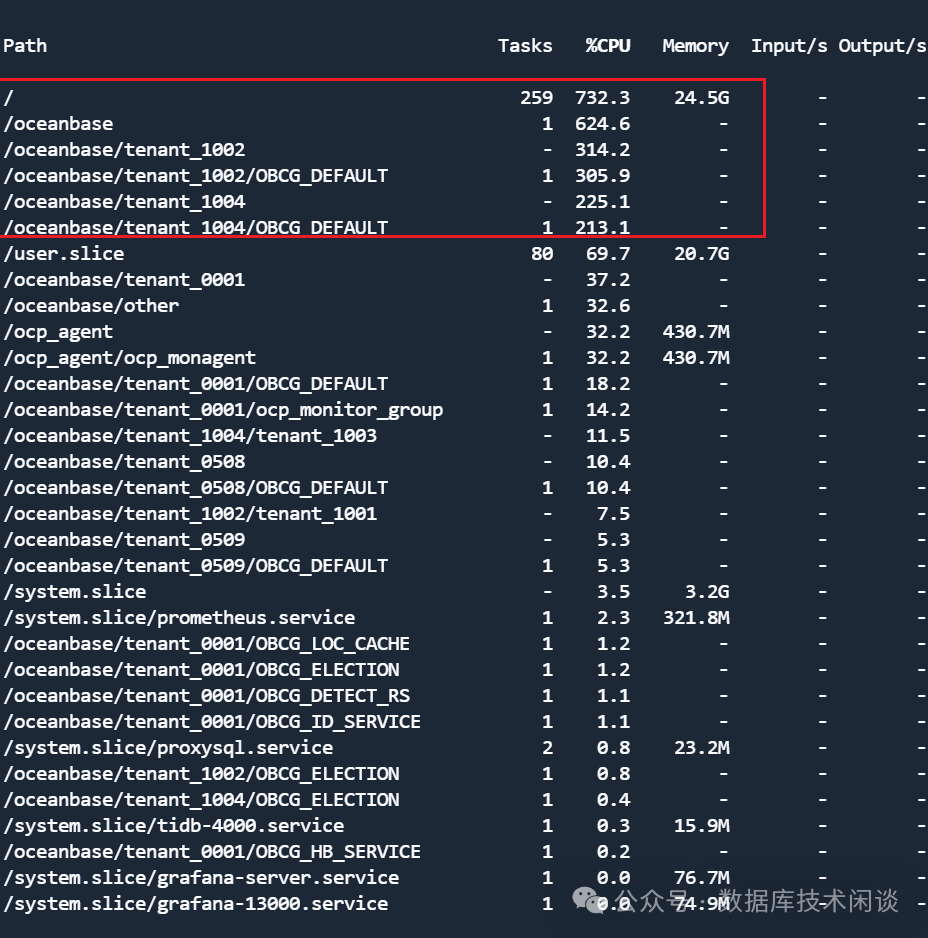
OCP 里的租户 CPU 利用率现在也非常的精准。
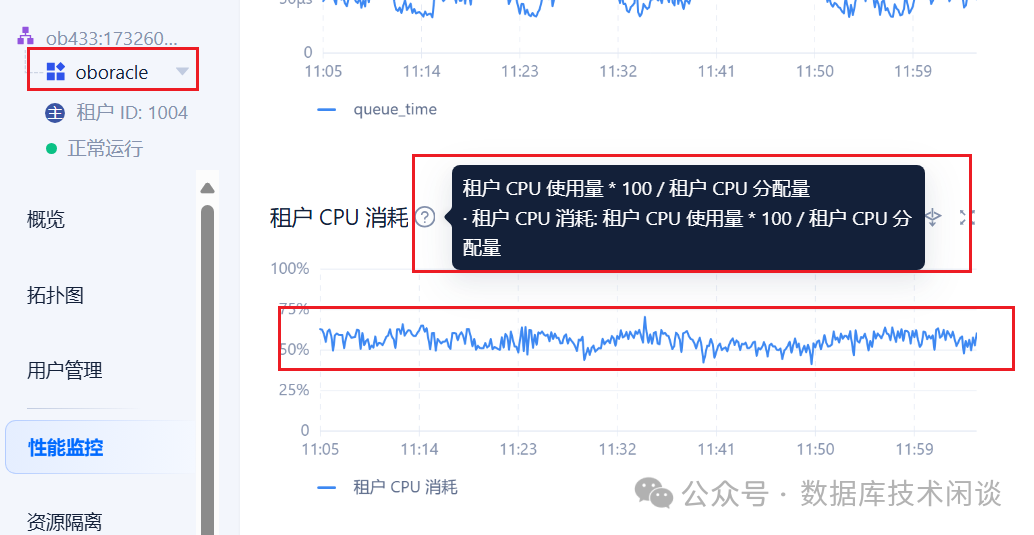
二者监控数据的结果是非常一致的。
OB CPU 超卖技术2
上面说了 OB 利用 cgroup 后实现的超卖效果。这里还提另外一个“超卖”场景和技术。 在测试环境当主机(很有可能是虚拟机)的 CPU 核数很少的时候,导致 OB 分配的租户 数量不多或者分出来的租户的 CPU 个数都很少。
OBServer 取到的 CPU 个数跟参数cpu_count
有关。可以通过调大这个参数值来“欺骗” OBServer。比如说主机只有 8个 CPU ,可以将这个参数设置为 16 。这样 OBServer内部分配租户的 CPU 资源就是基于 16 去做的。前面说过 OS 才是决定进程和线程使用 CPU 多少的关键,OBServer 作为一个进程只是在内部分配时间片。当调大cpu_count
后,无疑就是让 OBServer 里的单位 CPU 的能力打折扣。这种效果非常类似金融场景里“货币超发”。原本值 100元的货物 你超发了 200元货币去购买,这个购买力就贬值了。
这个就不要跟enable_cgroup
结合使用了,这个也只适合于开发测试环境。生产环境服务器 CPU 资源都充足,不需要这么抠的过日子。
总结
OB 的多租户设计决定了它是天生的云数据库。企业客户使用 OB 可以在本地机房部署 OB 集群,为内部客户提供类似云厂商的云数据库一样的服务。 OB 也顺水推出公有云服务。
本文介绍了 OB 多租户资源隔离技术的原理和演变过程。OB 4.2 版本默认都打开了 cgroup 的资源隔离,这个会严格限制租户的 CPU 利用率。(开启或关闭cgroup 需要重启 OB 集群,所以尽量部署前就要想好这个选择。)这个效果好坏主要看管理者的管理策略。很有可能导致 CPU 资源浪费。 为此,OCP 还相应的推出了“CPU超卖”设置,达到一个更复杂灵活的 CPU 资源使用策略。
OB 4.2 还支持 IOPS 资源隔离。跟 CPU 一样,做 IOPS 隔离最好的做法是用 cgroup 在 OS 层面做。不过由于 OB 整体是 LSM-Tree 架构,天然的读写 IO 分离。加上合并逻辑的特殊,IOPS 隔离效果还需要实践总结,目前个人建议是不需要去限制租户 IOPS (OCP 默认也是不限制) 。



