




1 Spark SQL执行计划概述
1.1 4个计划
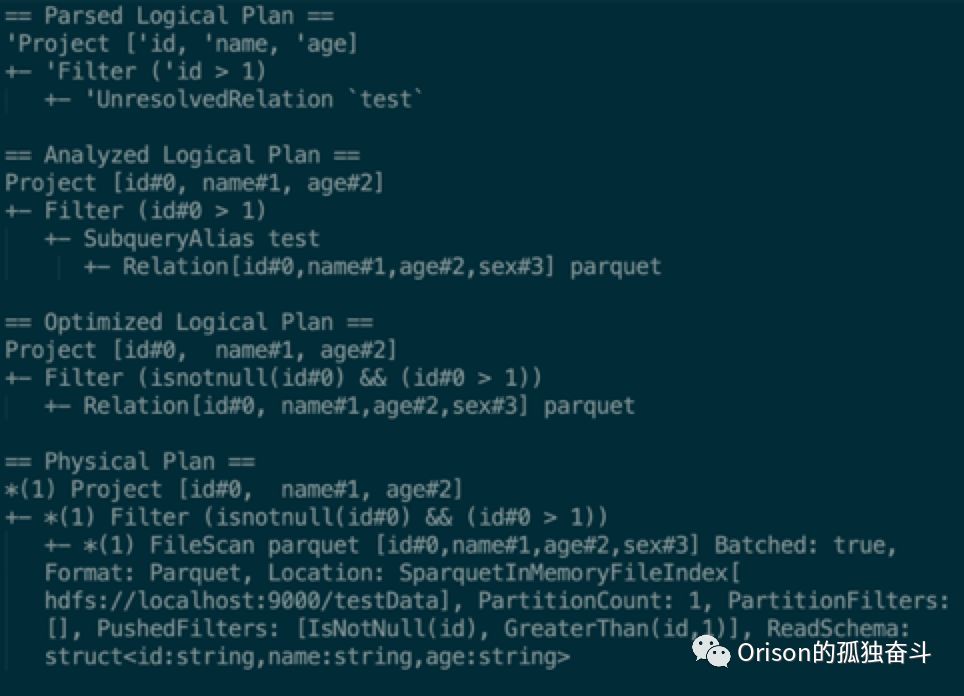
Parsed Logical Plan
Spark使用 ANTLR4来将SQL字符串解析为最初的LogicalPlan。
Analyzed Logical Plan
调用Spark的Analyzer将最初的Parsed Plan转化成分析后的LogicalPlan。
Optimized Logical Plan
将Analyzed Logical Plan调用catalyst内置的优化策略,生成优化后的LogicalPlan。
Physical Plan
使用Spark的物理策略处理优化后的LogicalPlan的每个节点。
1.2 一个例子
SELECT id, name, age FROM test
WHERE id > 1复制
1.3 Spark SQL目前所做的优化
Databricks以及众多Spark代码贡献者为Spark做了许多优化,最著名的,有SQL优化引擎Catalyst,有针对内存、CPU和I/O的Tungsten计划,还有正在逐步完善的CBO。在其中产生了Code Generation技术和Vectorization技术。参考[SPARK-12795]和[SPARK-12992]。
CodeGen
全称是Whole-Stage Code Generation技术,会在运行时动态生成Java代码,避免虚函数调用。
Vectorization
每次调用next()返回一个batch的数据,减少虚函数调用次数。
CBO
基于代价的优化,主要用来减少join的shuffle。
首先还是说一下基本的火山模型。
1.3.1 Volcano
火山模型是一般SQL引擎经常使用的一种模型,还是用上文的例子:
SELECT id, name, age FROM test
WHERE id > 1复制
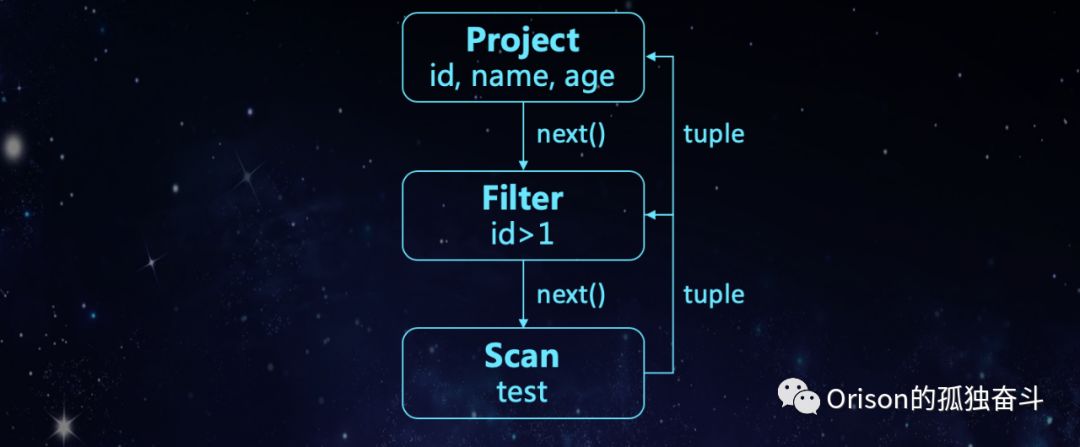
其语法树的火山模型如上图,project节点传next()方法给filter节点,filter节点传next()给全表扫描节点,然后全表扫描节点返回元组给tuple,以此类推。可以发现调用了非常多的next()方法。而next()函数又是虚函数,那么什么是虚函数?给出以下几个定义:
虚函数的存在是为了多态和继承。
编译器会创建虚函数表,虚函数表的作用就是保存自己类中虚函数的地址。
虚函数会调用多个CPU指令。
Java中其实没有虚函数的概念,它的普通函数就相当于C++的虚函数。
可以看到,如果是这种传统的火山模型,效率会非常低。
1.3.2 Whole-Stage Code Generation
那么我们再看一个例子:
SELECT count(*) FROM test
WHERE id = 100复制
这个例子当然可以用火山模型来画出来,但是如果换种Java手写代码的方式呢?
int count() {
int count = 0;
for (tuple : test) {
if (tuple.getId() = 100) {
count += 1;
}
}
return count;
}复制
可以看到完全不需要next()方法。网上有一张很著名的图,是一张关于火山模型和大学新生手写代码的性能对比:
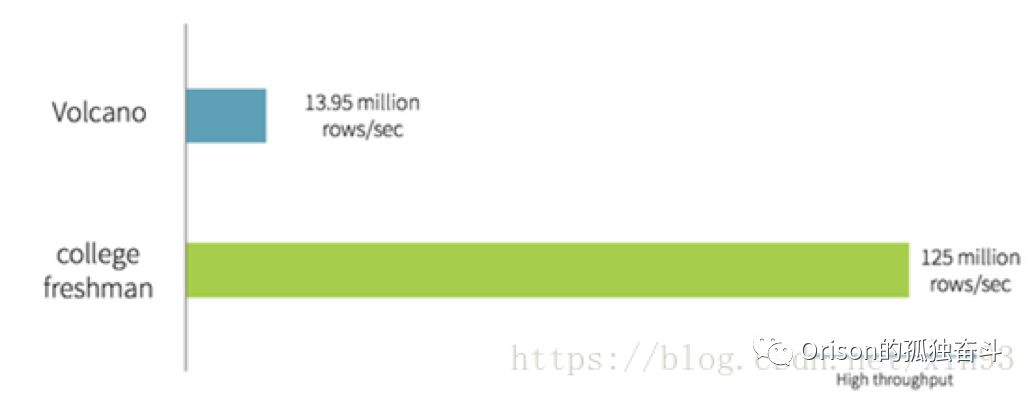
非常可怕,对不对?Spark为此实现了Whole-Stage Code Generation优化技术。其目的如下:
避免了虚函数调用:生成的Java代码没有任何虚函数调用逻辑。
使用CPU寄存器存取中间数据:在生成的Java代码中,原本返回的数据会作为变量存放在寄存器中,而不是作为返回值放在内存中。存取更快。
编译器Loop Unrolling:手写代码针对某特定功能使用简单循环,而现代的编译器可以自动的对简单循环进行Unrolling,生成单指令多数据流(SIMD),在每次CPU指令执行时处理多条数据。
1.3.3 Vectorization
向量化的作用与CodeGen类似:
减少虚函数调用:从调用next()转为调用nextBatch() 。
针对列式存储的优化:列式读取,减少磁盘I/O。
使用SIMD:利用CodeGen技术生成单指令多数据流(SIMD),在每次CPU指令执行时处理多条数据。
2 Spark 查询优化之数据源优化
一个IoT下的场景:数据原本存于传统RDBMS,有唯一标识id,为了迎接工业4.0,迁移到大数据平台,要求查询性能跟查询RDBMS性能持平,并且还需要一些固定查询做ETL和报表。
那么IoT数据有什么特征?
数据量大
异构性
数据质量不稳定
没有更新和删除的操作
我们没有用HBase和Impala,为什么呢?因为我们的数据
没有Update、Delete操作和多版本需求,这是HBase的一大特性;
我们需要建立跟RDBMS看起来一样的Table使用Spark SQL查询。
有很多基于标识字段和时间字段的混合查询。
Impala是MPP架构,适合即时查询,不适合批量查询,而我们有ETL job。
所以最终我们选择的方案是直接存到HDFS上:
使用Parquet
Spark推荐的、其支持非常好的高性能列式存储格式,Spark SQL也为其实现了向量化。并且Parquet支持min/max,同时也会将count等信息存入其meta中。
使用Spark分区表
将数据最常见使用场景中的关键字段作为分区字段,使用一个分区UDF或者直接使用该分区字段作为分区值,将数据根据分区按照时间顺序存放在HDFS。
实现谓词下推
Parquet结合Spark可以实现分区过滤。将查询条件里的分区字段下推求UDF后的分区,实现分区过滤,减少I/O。此外,通过Parquet的min/max过滤,进一步减少开销。
假设有一个titem表有三个字段,id,name,type,其中type是ttype表的主键,那么我们可以用type外键来当作分区字段,分区前的schema如下:
{
"type" : "struct",
"fields" : [{
"name" : "id",
"type" : "string",
"nullable" : false,
"metadata" : {}
},{
"name" : "name",
"type" : "string",
"nullable" : true,
"metadata" : {}
},{
"name" : "type",
"type" : "int",
"nullable" : false,
"metadata" : {}
}]
}复制
分区后的schema如下:
partitionColumn:
{
"name" : "type",
"type" : "int",
"nullable" : false,
"metadata" : {}
}复制
dataColumns:
{
"type" : "struct",
"fields" : [{
"name" : "id",
"type" : "string",
"nullable" : false,
"metadata" : {}
},{
"name" : "name",
"type" : "string",
"nullable" : true,
"metadata" : {}
}]
}复制
存到HDFS上的路径就会是如下图的格式:
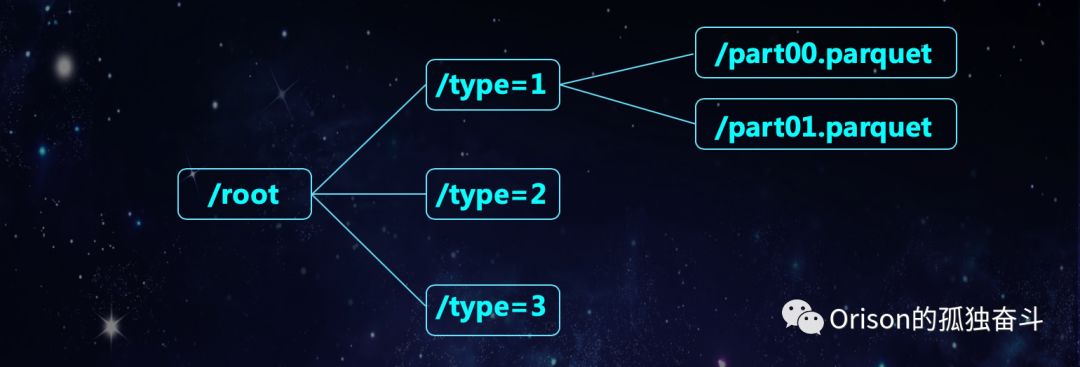
在这种情况下,用Spark来读写分别是:
val df = spark.read.parquet(path).where(“type=xx”)
df.write.partitionBy(“type”).parquet(path)复制
当然,实际情况下我们并不会用这种方式来写,因为这种方式会导致全部shuffle,数据还是通过Kafka或者Flink来导入单独append在每个分区目录的里面的。
这种情况下性能对比如图:

2.1 Vectorization的使用限制
Spark源码中,FileFormat接口有一个方法叫supportBatch(),顾名思义,就是能不能使用nextBatch(),也就是向量化的批量返回。那么在ParquetFileFormat实现类里,是这么继承这个方法的:
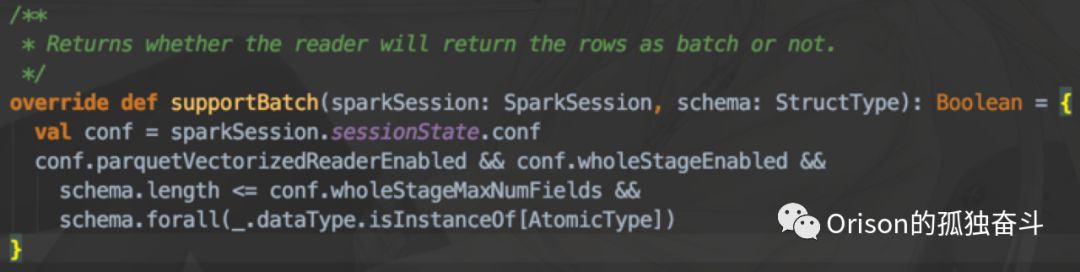
可以看到,当中有一个参数,叫做 wholeStageMaxNumFields
,也就是支持CodeGen的最大字段数量:

可以看到,它的默认值是100,为什么会有这个设置呢?两个原因:
首先,如果字段太多的话,其生成的Java代码就会超过JVM的最长限度;
其次,向量化会占用比较多的内存,如果字段太多的话,性能会很差,GC时间会非常多,当然也有办法可以适当解决这个问题,Tungsten加入了非堆内存的使用,可以给ColumnarBatch的默认内存设置为使用非堆内存,GC时间可降至个位数,但是平均仍然会比按行返回要多些。
2.2 谓词下推
需要继承接口:

3 Spark 查询优化之执行计划优化
3.1 Cost-Based Optimization(CBO)
基于代价的优化,就是根据实际数据量,评估每个计划的执行代价,选择代价最小的执行计划,主要用于Join优化,减少Shuffle。举一个tpc-ds的例子:
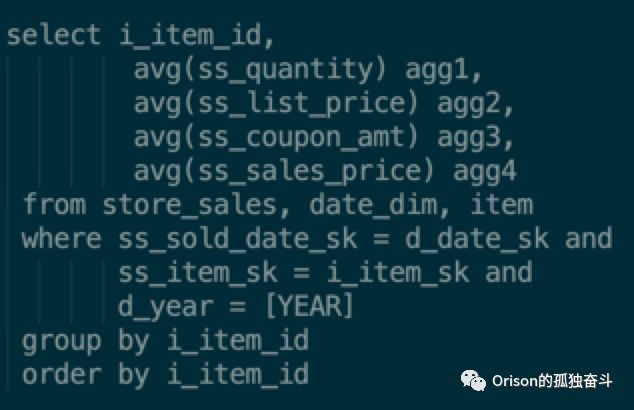
它的语法树是:
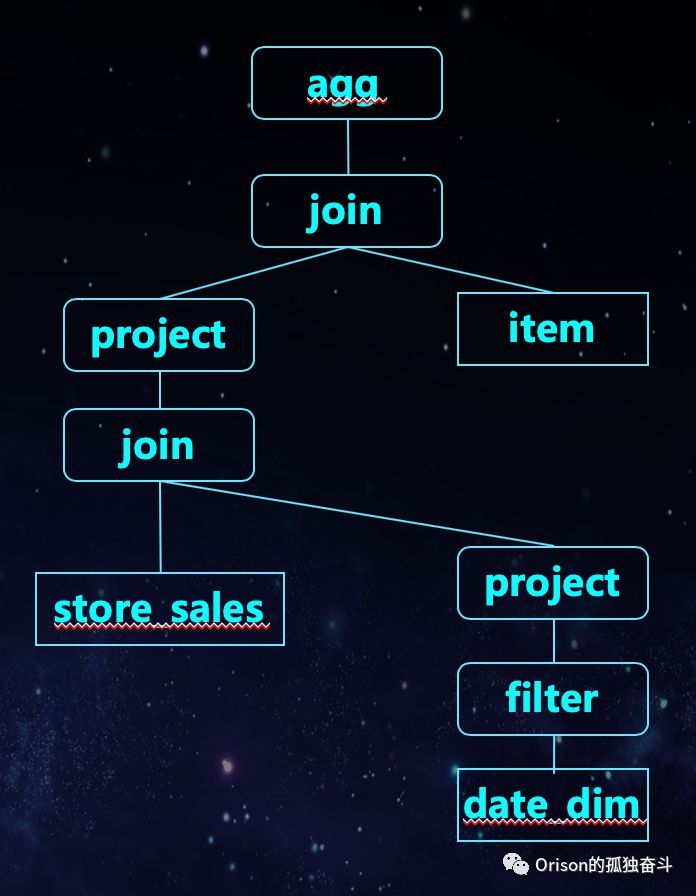
也就是说,在CBO开启的情况下,它知道storesales和datedim优先join是最好的,因为date_dim是维度表,数据量非常小,而item的数据量是大的。
使用方法:
配置项:spark.sql.cbo要设置为true。
要使用analyze命令来统计表信息。如:
ANALYZE TABLE table_name
COMPUTE STATISTICS FOR COLUMNS column_name1, column_name2,...复制
意义:
减少Join的开销。
对于不含Join的查询,如果数据源可能包含了某些聚合结果,直接返回聚合结果也会大大减少磁盘读写和网络传输的开销。
3.2 Aggregate Pushdown
聚合下推,曾经号称在Spark2.3就要实现,但是迟迟未上,可能由于其真的难点太多,主要难点有二:
对于有Join的情况,要确定推其哪个分支。
对于case when、window、count distinct、count(*)等很难把聚合函数下推。
但是在某些特定case下聚合下推还是比较好实现的,比如一个大学Oracle课程中的小例子:
SELECT AVG(salary), deptName
FROM emp
JOIN dept
ON emp.deptNo = dept.deptNo
GROUP BY deptName;复制
在聚合下推前,执行计划是这样的:

在聚合下推后,执行计划变成了这样:
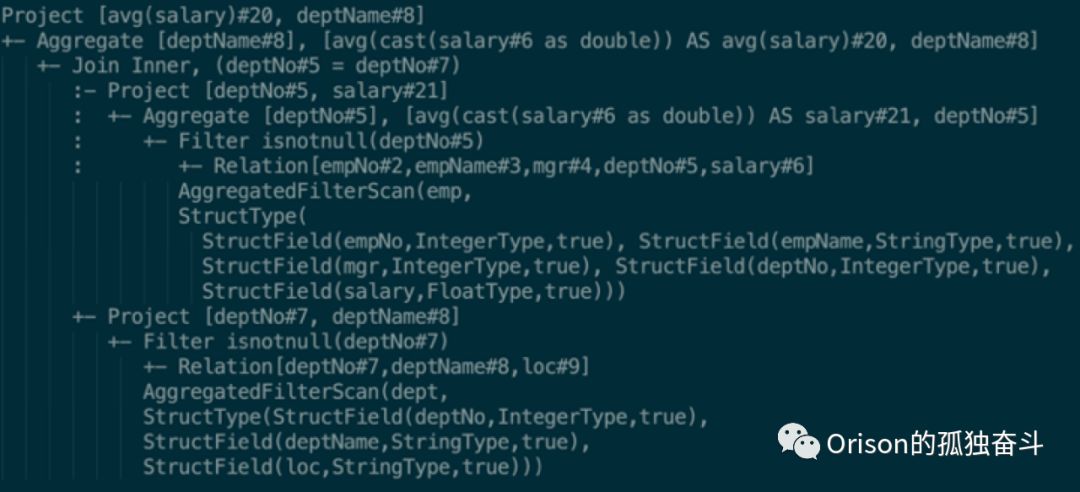
可以看到,在Join的其中一个分支,加入了一个聚合节点。
在tpc-ds某句SQL中拉下来一个单独的子SQL的性能对比如下:
SELECT AVG(cs_ext_discount_amt)
FROM catalog_sales, date_dim
WHERE d_date
BETWEEN '1999-02-22' AND CAST('1999-05-22' AS DATE)
AND d_date_sk = cs_sold_date_sk
GROUP BY cs_sold_date_sk;复制
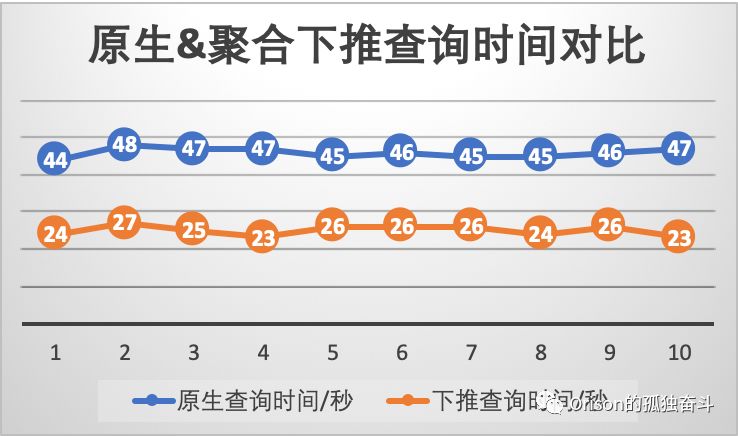
由于下推到的数据源本身并没有实现聚合功能,所以相当于推到Spark的driver端后我们自己写代码计算了一遍聚合,如果在数据源本身就有聚合结果的话,查询时间是完全可以在10秒以内的。
