




金点分享
本期继续邀请嘉宾大唐小少,他将基于自身的实践分享GoldenDB数据库分片和重分布,这也是系列文章的第三篇。
大唐小少目前任职华南地区某股份制银行数据中心DBA,拥有近10年核心业务系统数据库运维经验,目前负责国产化核心分布式数据库运维体系建设。

1、数据分片规则
垂直切分是按照不同的表切分到不同的数据库中,适用于业务系统之间耦合度低、业务逻辑清晰的系统 水平切分是根据表中数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库上,对应用来说更为复杂
无限扩展:数据分片水平切分扩展到多个物理节点,理论上支持无限扩展 性能提升:数据分片以后单个数据节点上上的数据集变小,数据库查询的压力变小、查询更快,性能更好;同时水平切分以后查询可以并发执行,提升了系统的吞吐量 高可用:部分分片节点宕机只会影响该部分分片的服务,不会影响整个系统的可用性
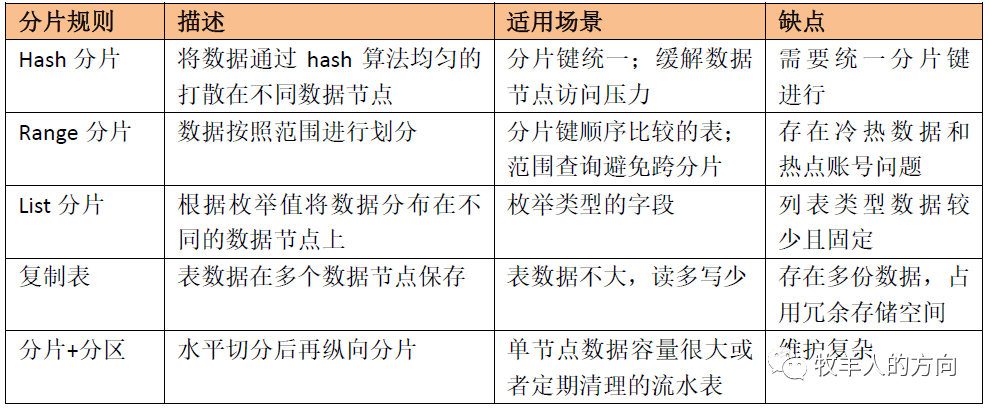

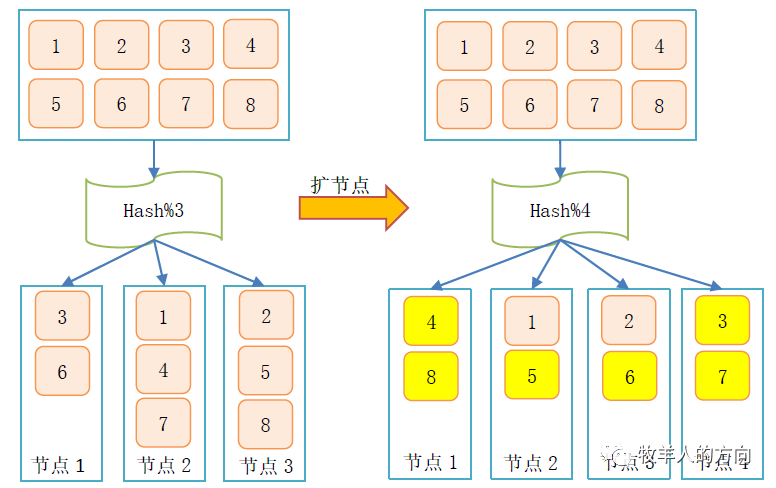
1.1 Hash分片
1.1.1 普通hash算法
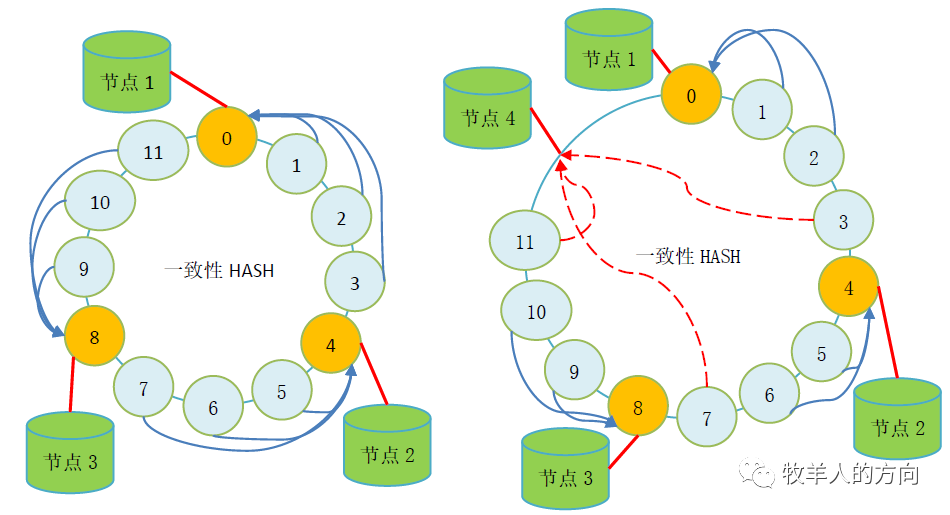
1.1.2 一致性hash算法
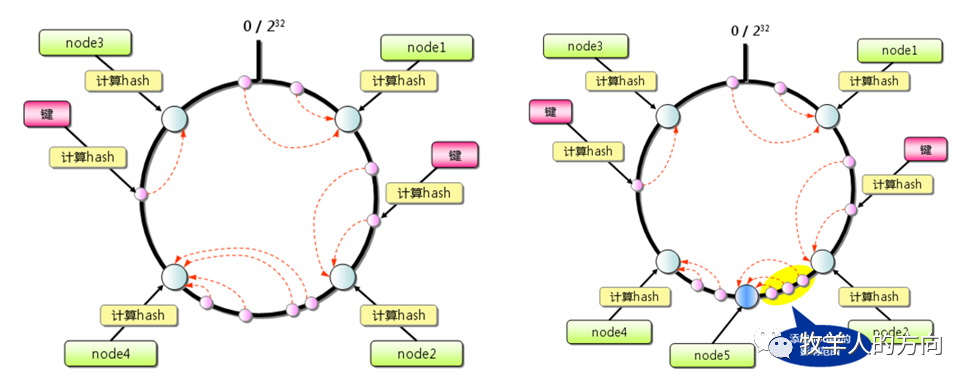
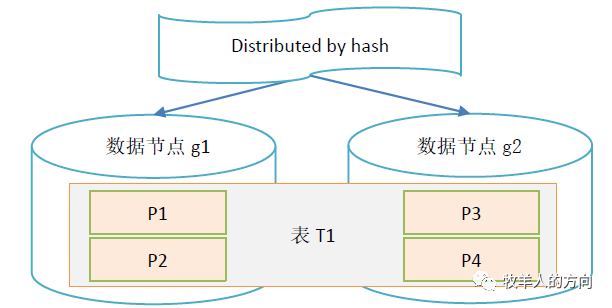
GoldenDB中的hash算法
对分片键计算hash值,该hash值会落到0~N的封闭圆环中 按照分片数量M将hash值均分为M段(M<<N),确定每个分段的值范围 将落入同一个分段的hash值划分在同一个分片上 当增加数据节点时候,会使用到hash流式重分布策略,将其它分片的hash值搬动到新增的节点,使得数据均匀分布
Hash分片的语法如下:
Create table t1(a int,b int) distributed by hash(a)(g1,g2,g3);复制
1.2 Range分片
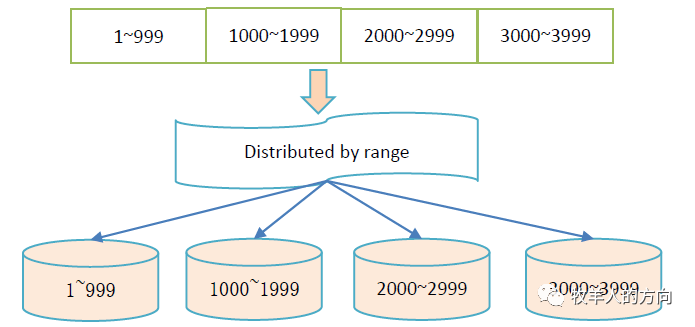
GoldenDB中range分区示例:
Create table t1(a bigint,b char(6)) distributed by range(a)
(g1 values less than (1000),g2 values less than (2000),g3 values less than maxvalues);复制
1.3 List分片
GoldenDB中List分片示例:
Create table t1(a varchar(4),b char(6)) distributed by list(a)
(g1 values in(‘CN’),g2 values in (‘HK’));复制
1.4 复制表
GoldenDB中复制表示例:
Create table t1(a varchar(4),b char(6)) distributed by duplicate(g1,g2,g3);复制
1.5 多级分片
GoldenDB中多级分片示例:
Create table t1(a int,b int,c int) distributed by
case c when 1 then case when b<100 then subdistributed by hash(a) (g1);
else subdistributed by hash(a) (g2);
end case;
when 2 then subdistributed by hash(a) (g3);
else subdistributed by hash(a) (g4);
end case;复制
1.6 GoldenDB中分区
GoldenDB中分片+分区示例:
Create table t1(a int,b int,c int) partition by range (c)
(partition p1 values less than (20210101), partition p2 values less than (20210201),
partition p3 values less than (20210301), partition p4 values less than (20210401))
distributed by hash (a) (g1,g2);复制
2、分片路由

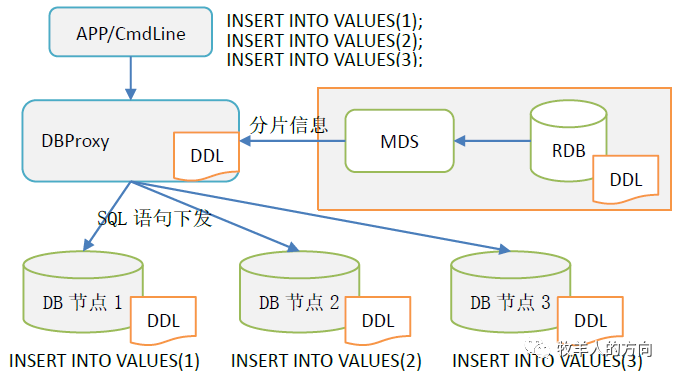
2.1 表分片DDL过程
2.2 表分片的插入过程
计算节点接收到SQL信息后,从MDS获取表的分片信息并解析SQL 计算节点根据分片规则将SQL语句下发到不同的DB分片节点 DB分片节点执行insert语句,并返回执行结果给计算节点计算节点
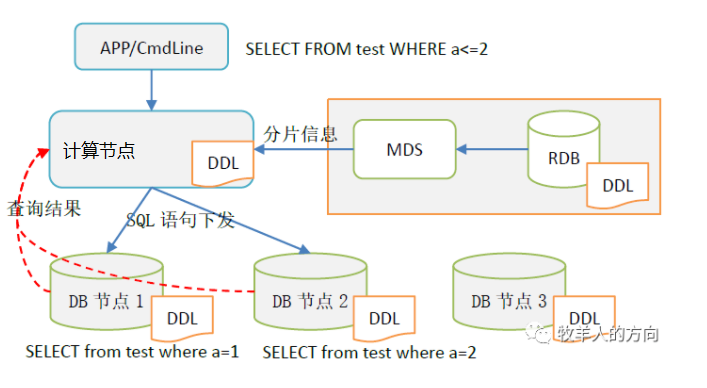
2.3 表分片的查询过程
计算节点接收到SQL信息后,从MDS获取表的分片信息并解析SQL 计算节点根据分片规则将查询语句下发到不同的DB分片节点 DB分片节点执行SQL查询语句,并返回结果集给计算节点计算节点进行汇总,再返回给客户端
3、在线重分布
3.1 数据重分布策略
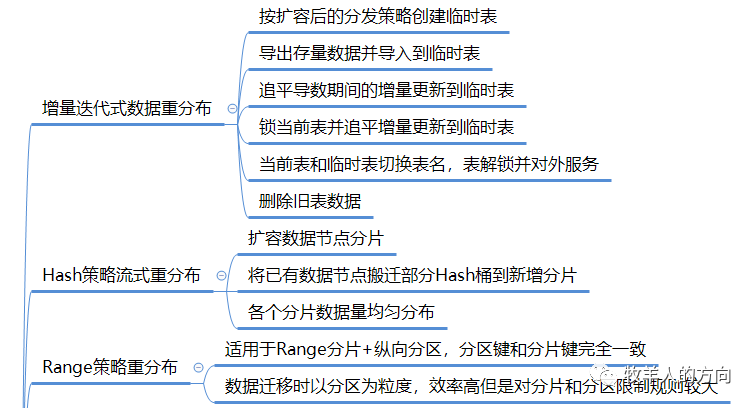
3.1.1 增量迭代式数据重分布
分片策略的变更,由hash变为range,复制表变为分片表等 表分片键的变更,由A列调整为B列 分片策略不变,数据节点横向扩容的场景
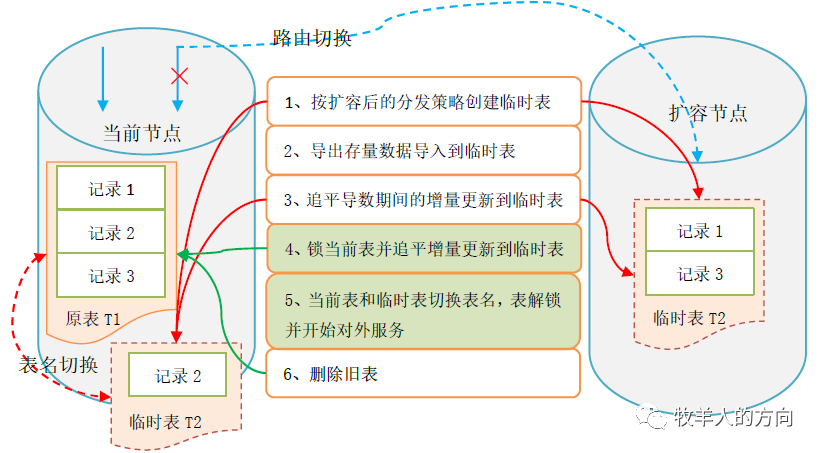
按照扩容后的分发策略创建临时表 导出需要重分布的数据节点的数据,并导入到临时表 通过binlog数据追平导数期间增量更新的数据到临时表 将当前表锁住(此时应用不能更新表),并通过binlog追平增量更新数据 数据校验完毕后,将临时表和新表切换表名,解锁并对外提供服务 删除旧表的数据
锁表和切换表名的过程中,影响应用的写操作 重分布过程中临时表需要额外的存储空间,重分布操作前需要保证存储空间充足
3.1.2 Hash策略流式重分布
系统中默认包含2048*128个HASH桶,新增数据节点的过程中会并行的从现有的每个分片节点迁移部分数据到新增分片上,确保所有分片数据平均 整个数据迁移的过程是在现有分片数据上动态操作,对磁盘空间没有额外的要求 同步更新MDS和DB节点中表的分片信息
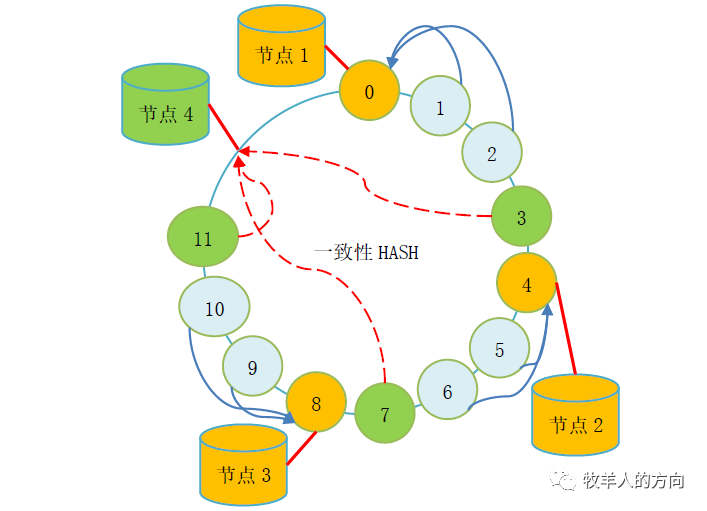
分片数据从现有分片移动到新增分片的方法,直接导出再load进去? 数据移动的过程中,应用访问到的数据的节点信息和移动后的数据信息不一致该如何处理? 现有分片数据移动到新增分片的算法,即哪些数据会搬到新的分片节点 Hash桶数量是有限的,是否会出现Hash值重复的情况?
3.2 重分布任务
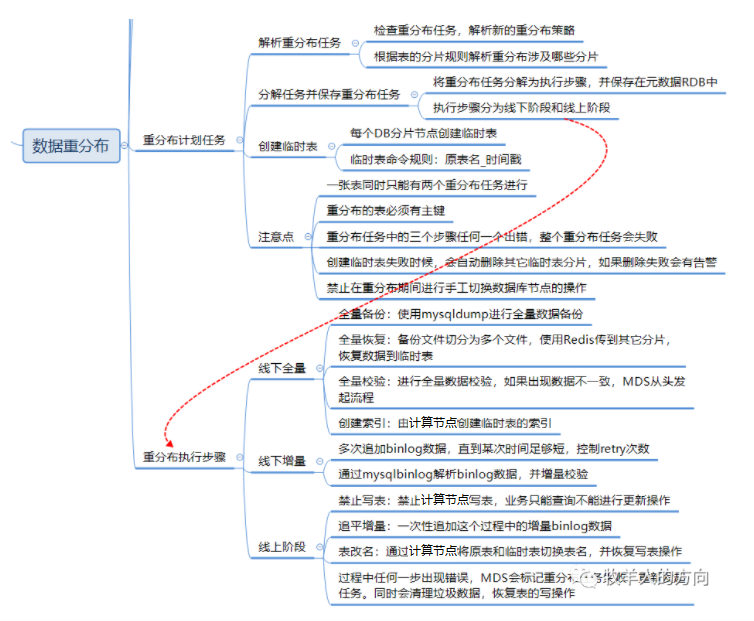
3.2.1 创建重分布任务
解析重分布任务:MDS对重分布任务进行检查,解析出新的重分布策略,并根据表的老旧分发规则解析出本次重分布涉及哪些分片 分解重分布步骤并保存重分布任务:MDS会把重分布任务分解为执行步骤,并保存到元数据RDB中 创建临时表:MDS向各DB分片发起创建临时表的请求,临时表的命名规则为原表名_时间戳
3.2.2 线下阶段(全量部分)
全量备份:使用mysqldump进行全量数据备份 全量恢复:全量恢复是将备份文件根据新的分发策略切分为多个文件传输到其它DB数据节点,并恢复到临时表中 全量校验:进行全量数据校验,如果数据出现不一致,需重头发起重分布任务 创建索引:数据校验完成后会通过计算节点为临时表创建索引
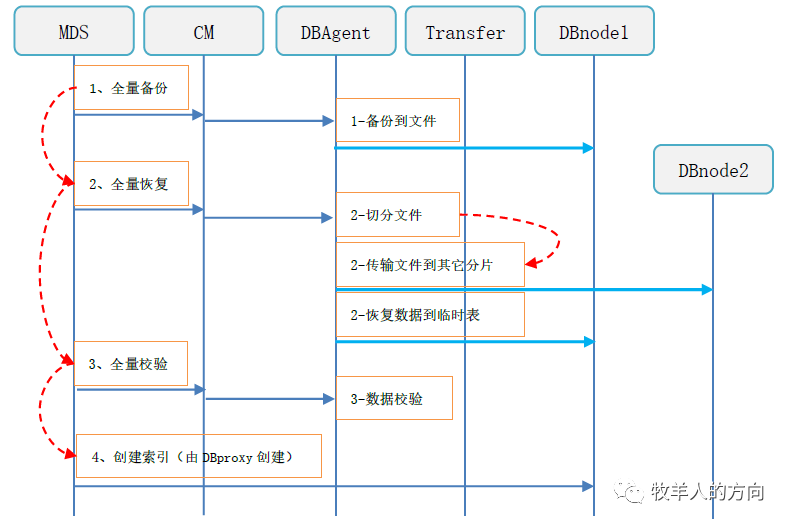
3.2.3 线下阶段(增量部分)
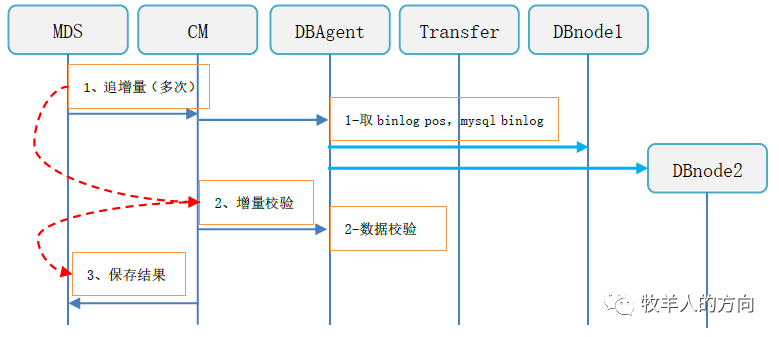
3.2.4 线上阶段
表写禁止,此时业务只能查询,不能增删改操作 追加全部的binlog数据 增量校验数据的一致性,如果不一致则需要重新开始重分布任务 数据校验完成后切换表名 恢复表的写访问,对外提供服务 清理旧表的数据
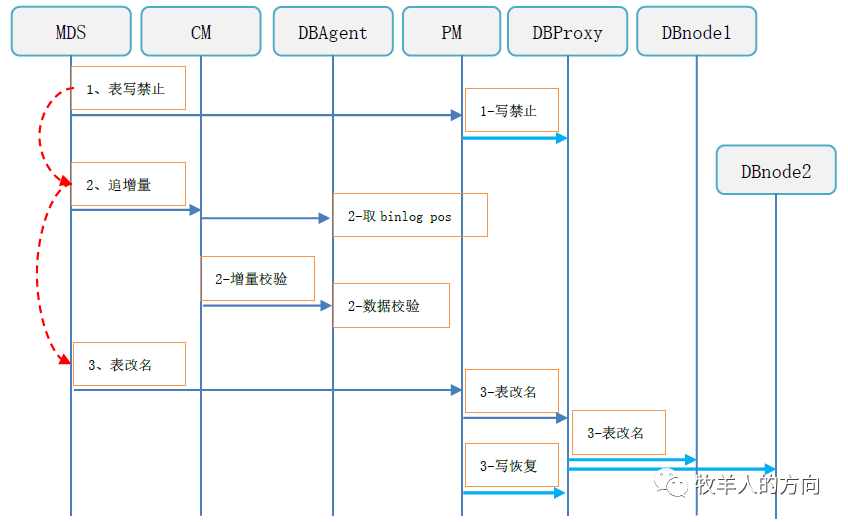
最后修改时间:2021-12-11 08:06:52
文章转载自GoldenDB分布式数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
3347.6万!国家开发银行定向采购 GoldenDB 授权及服务
通讯员
251次阅读
2025-03-06 16:50:57
GoldenDB数据库社区正式上线!期待与您共享新知
GoldenDB分布式数据库
230次阅读
2025-03-12 14:06:39
乌兰察布市政府数据库框采:金仓、海量、东方金信、神通、GreatDB、虚谷、GoldenDB等产品入围
通讯员
122次阅读
2025-03-26 10:34:16
聊聊跨数据库迁移的数据比对那些事儿
吾亦可往
113次阅读
2025-03-06 09:03:06
GoldenDB革新数据库 DDL 事务执行,提升效率与性能
吾亦可往
107次阅读
2025-03-05 11:30:03
GoldenDB的数据库查询优化:如何让数据查询更快、更高效?
吾亦可往
88次阅读
2025-03-04 11:15:18
首届GoldenDB金融核心应用技术研讨会在京成功举办!
GoldenDB分布式数据库
77次阅读
2025-03-12 10:23:13
GoldenDB数据转发方法、系统、电子设备和存储介质
李奇
63次阅读
2025-03-04 15:17:29
GoldenDB:赋能公积金系统数字化转型,打造安全高效的数据基石
张芝
57次阅读
2025-03-28 17:41:22
GoldenDB孤岛演练
韦
53次阅读
2025-03-28 21:15:56
