




金点分享
本期继续邀请嘉宾大唐小少,他将基于自身的实践分享GoldenDB中分布式事务的实现,这也是系列文章的第五篇。

1、分布式数据库理论
1.1 CAP理论
一致性Consistency
可用性Availability
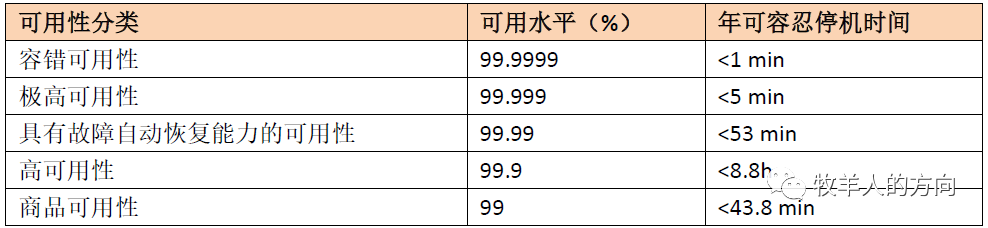
分区容忍性Partition Tolerance
CAP的权衡
CP without A:分布式系统容许系统停机或者长时间无响应,一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。传统的分布式数据库事务都属于这种模式,对于金融行业的分布式数据库产品而言,优先保证数据的一致性。 AP without C:分布式系统中允许数据不一致,一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
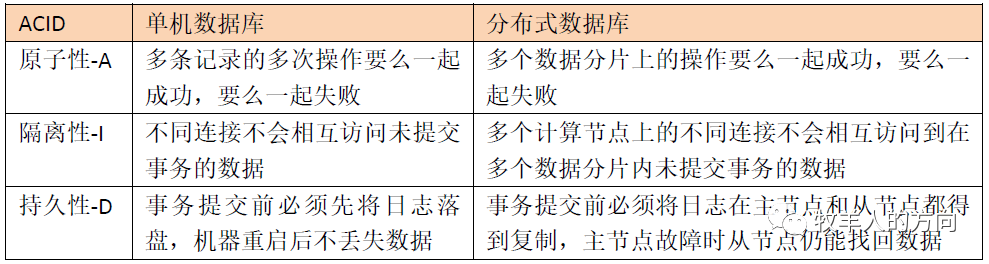
1.2 ACID原则
原子性:一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。 一致性:在事务开始之前和事务结束以后,数据库的完整性限制没有被破坏。 隔离性:当两个或者多个事务并发访问数据库的同一数据时所表现出的相互关系。 持久性:在事务完成以后,该事务对数据库所作的更改便持久地保存在数据库之中,并且是完全的。
1.3 分布式事务一致性算法
1.3.1 2PC(two-phase commit)
阶段1:请求阶段
阶段2:提交阶段
同步阻塞:在二阶段提交的执行过程中,所有参与该事务操作的逻辑都处于阻塞状态,也就是说,各个参与者在等待其他参与者响应的过程中,将无法进行其他任何操作。 单点问题:协调者的角色在整个二阶段提交协议中起到了非常重要的作用。一旦协调者出现问题,那么整个二阶段提交流程将无法运转,更为严重的是,如果协调者是在阶段二中出现问题的话,那么其他参与者将会一直处于锁定事务资源的状态中,而无法继续完成事务操作。 数据不一致:在阶段二时,当协调者向所有的参与者发送Commit请求之后,发生了局部网络异常或者是协调者尚未发送完Commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了Commit请求。于是,这部分收到了Commit请求的参与者就会进行事务的提交,而其他没有收到Commit请求的参与者则无法进行事务提交,于是整个分布式系统便出现了数据不一致现象。 太过保守:二阶段提交协议没有设计较为完善的容错机制,任何一个节点的失败都会导致整个事务的失败。
1.3.2 3PC(three-phase commit)
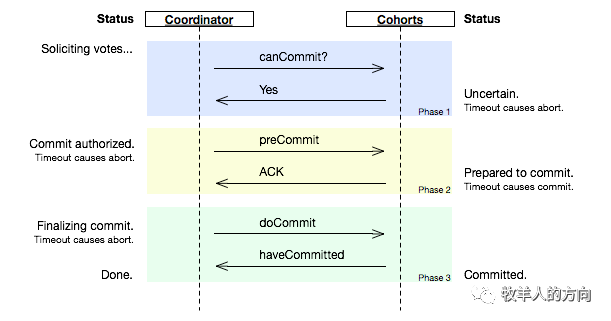
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会进行事务的预执行: 发送预提交请求。协调者向参与者发送PreCommit请求,并进入Prepared阶段。 事务预提交。参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。 响应反馈。如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。 假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就中断事务: 发送中断请求。协调者向所有参与者发送abort请求。 中断事务。参与者收到来自协调者的abort请求之后(或超时之后,仍未收到Cohort的请求),执行事务的中断。
执行提交 发送提交请求。协调者接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。 事务提交。参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。 响应反馈。事务提交完之后,向协调者发送ACK响应。 完成事务。协调者接收到所有参与者的ACK响应之后,完成事务。 中断事务 协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
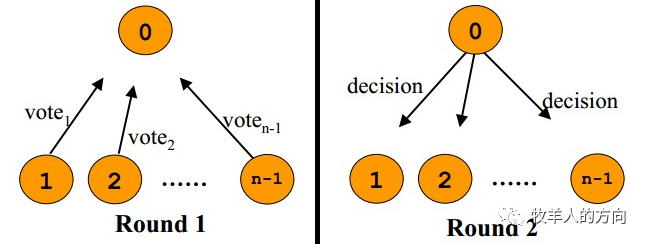
1.3.3 Paxos和Raft
Paxos算法属于多数派算法,主要解决数据分片的单点问题,目的是让整个集群对某个值的变更达成一致。集群中的任何一个节点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的节点同意,所以Paxos算法建议集群中的节点为奇数。 Raft算法是简化版的Paxos, Raft划分成三个子问题:一是Leader Election;二是Log Replication;三是Safety。Raft 定义了三种角色Leader、Follower、Candidate,最开始大家都是Follower,当Follower监听不到Leader,就可以自己成为Candidate,发起投票,选出新的leader。
1.3.4 1PC一阶段提交
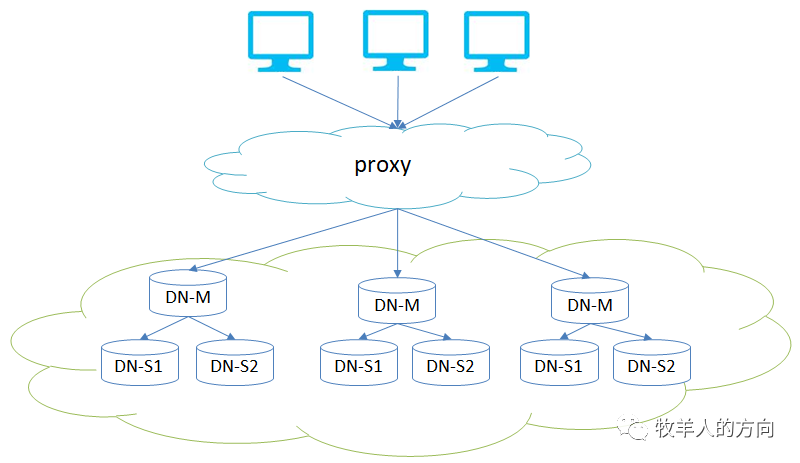
2、GoldenDB中分布式事务实现
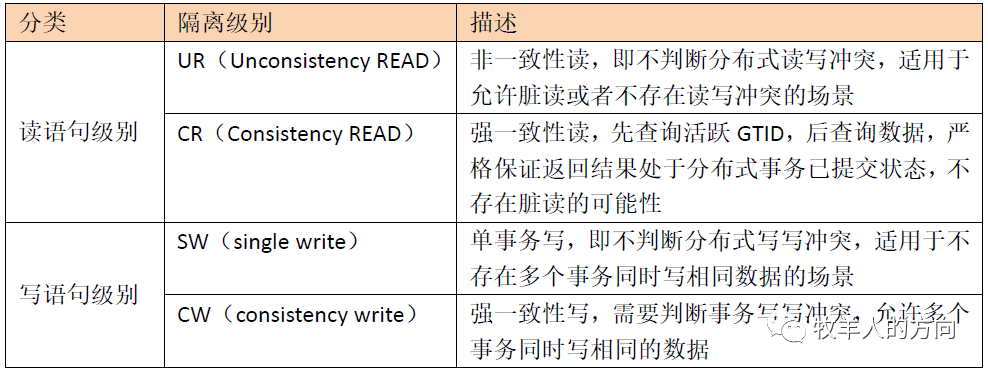
2.1 隔离级别

2.2 分布式事务的难点
部分DB提交失败,如何保证全局事务的原子性 并发访问时,每个事务都不知道其它事务的状态,如何保证事务之间的隔离性 当有部分DB提交成功,部分DB提交失败时,如何保证回滚期间的隔离性
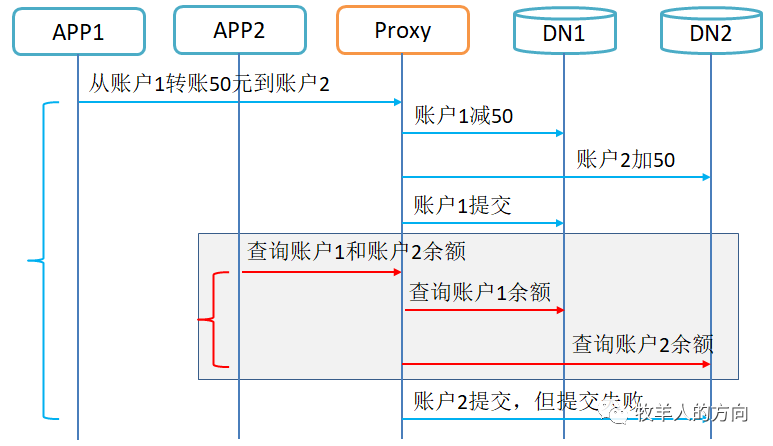
交易前账户1和账户2余额为100元,事务T1从账户1转账50到账户2 在事务T1提交期间,事务T2读取2个账户的余额,发现两个余额之和是50+100=150元。因为事务之间的隔离性问题产生数据读不一致 可能存在事务T1对账户T1扣钱成功,但是给账户2加钱失败的情况。因为事务内部的原子性问题产生数据写不一致
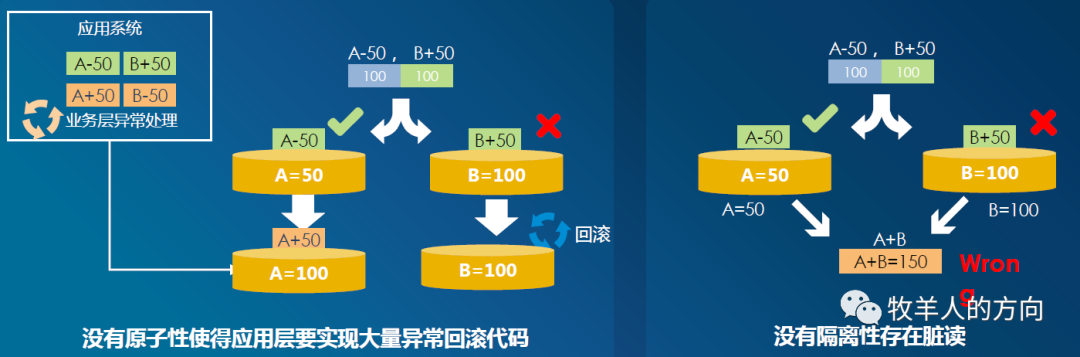
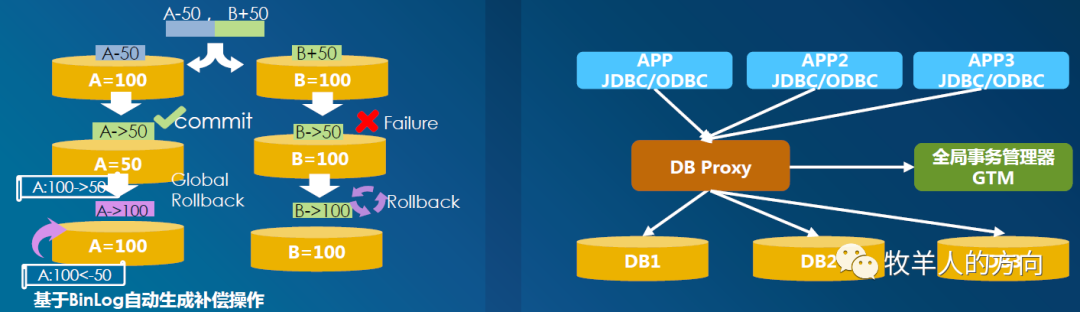
2.3 事务原子性
各分片直接提交:各分片并行在本地执行子事务,并在本地各自记录子事务日志。当每个分片都完成后,提交事务全局状态 自动补偿机制:某个分片执行失败,其它分片会反向解析本地binlog日志,将数据还原到执行前的状态
2.3.1 异常事务原子性流程
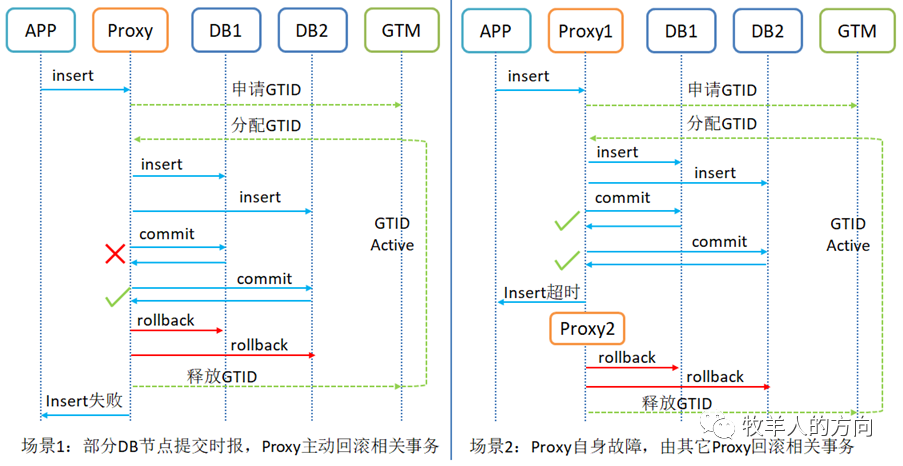
2.3.2 ROLLBACK流程
在SQL执行阶段,当部分数据节点的SQL执行失败、执行超时或者计算节点异常,此时需要业务根据SQL的执行结果选择rollback或者选择其它分支继续执行其它SQL 在事务提交阶段,当部分数据节点的SQL执行失败、执行超时或者计算节点异常,需要在已经提交的DB上进行已提交事务的回滚
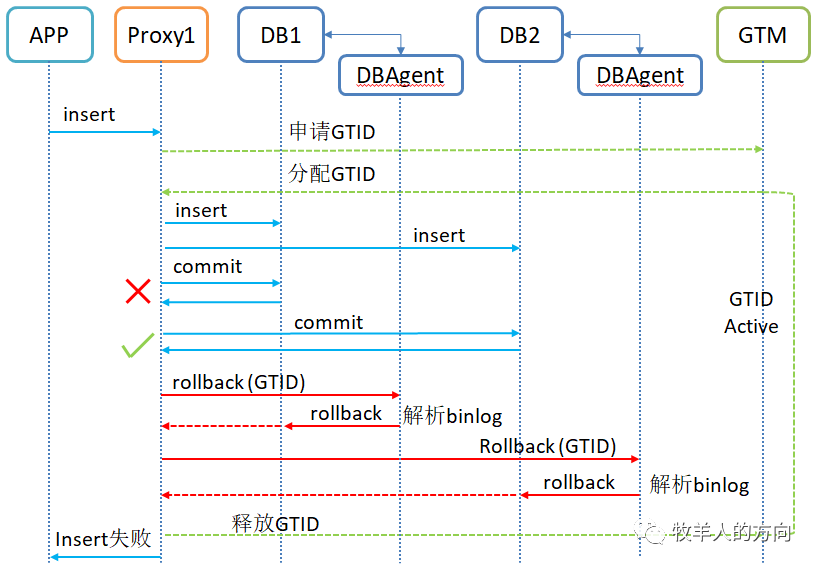
DBProxy将GTID发送给DB节点上部署的事务回滚组件DBagent DBAgent解析该事务的Binlog,然后对数据进行回滚 当所有DB分片回滚完成后,再释放GTID
定位:根据GTID相关信息定位要进行分析binlog日志文件的列表 遍历:遍历binlog日志文件,找到GTID对应的事务日志块 生成:分析日志块,为事务中每条SQL语句生成反向的SQL语句 执行:将所有反向SQL语句逆序执行,并保证在一个事务中
2.4 事务隔离性
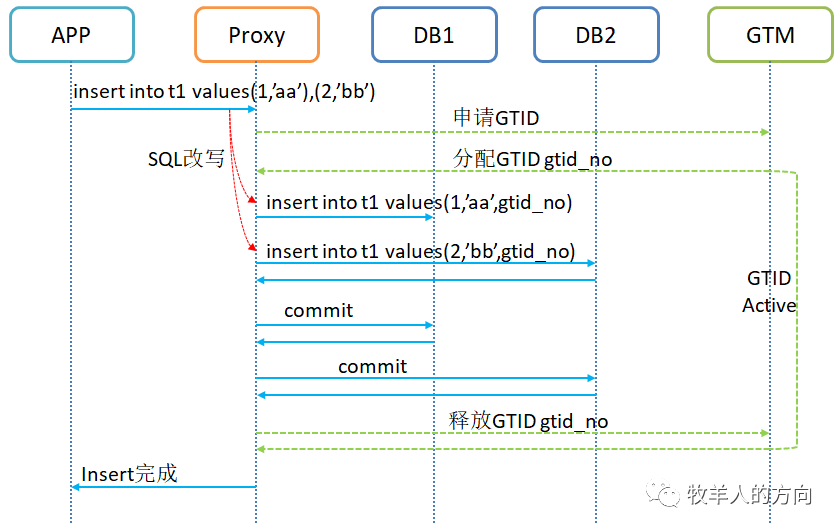
分布式事务更新:分布式事务更新数据时,Proxy会从GTM申请GTID,同时改写SQL语句,将申请的GTID更新到数据行中 分布式一致性读过程:当事务隔离级别为cr时,查询事务会通过proxy查询GTID中当前的活跃事务列表,并进行活跃状态校验,如果该数据正在被修改则不会返回。
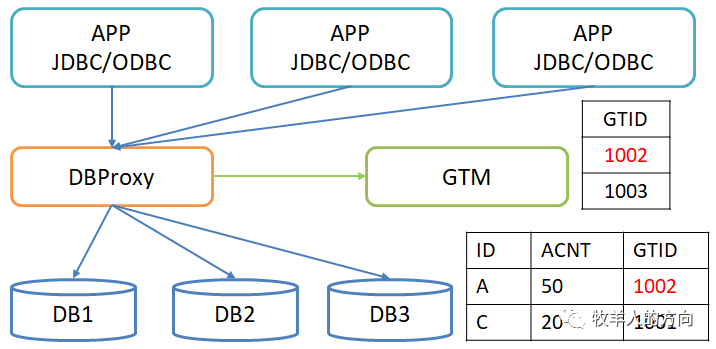
事务开始时申请GTID,事务结束时释放GTID,所有活跃事务由GTM统一管理,称为活跃事务列表 建表时会在表上自动增加GTID列(对应用不可见),更新数据行时同时会更新GTID列。如果数据行的GTID在活跃事务列表中,表明该数据正在被其它事务修改 proxy计算节点会对事务的SQL语句进行修改,将GTID加入到语句中下推到数据节点 GTID单调递增
insert into t1 values(1,’aa’),(2,’bb’);
语句会改写为
insert into t1 values(1,’aa’,gtid_no),(2,’bb’,gtid_no);复制
2.4.1 一致性读

向GTM请求查询当前的活跃事务列表 DBProxy将查询的SQL进行改写
原语句select a,b from t1 where改写为
select a,b,gtid from t1 where复制
将改写后的SQL下发到数据节点进行查询 DBproxy根据查询后的表数据行的GTID和GTM查询的GTID进行活跃判断,如果GTID不在活跃事务列表中,则合并结果集返回给应用;如果在GTID活跃事务列表中,会进行尝试重新查询活跃事务列表GTID进行判断,超过重试次数后也会返回结果集,不过返回的是更新前的数据 由于数据节点的隔离级别为rc模式,下发到数据节点的SQL语句返回的是事务更新提交之前的数据 在dbproxy节点进行GTID判活及retry的时候,会有短暂的阻塞读的情况,时间会很短,大概是ms级别
2.4.2 MVCC模式下的一致性读
DB节点使用proxy上收到的active_gtm_gtid_list进行数据活跃判断 如果当前数据行上的GTID判断不活跃,直接返回数据 如果当前数据行上的GTID判断活跃,则通过undo构造全局的镜像数据
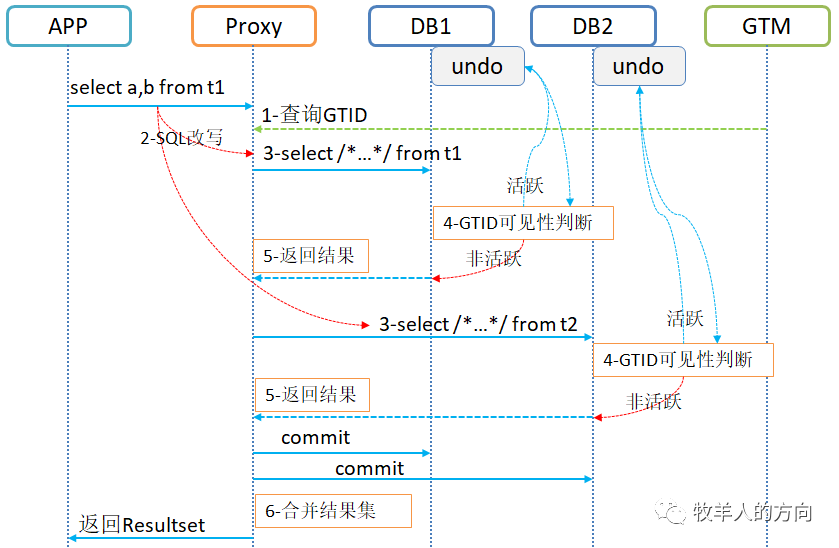
DBproxy向GTM请求当前的活跃事务列表 DBProxy将原SQL进行改写,即将活跃事务列表下推到数据节点
将select a,b from t1 where改写为
select /*+SET_VAR(active_gtm_gtid_list=活跃事务列表的BASE64编码) SET_VAR(next_gtm_gtid=ulonglong变量)*/ a,b,gtid from t1 where复制
将改写后的SQL语句和GTID活跃事务列表下发到数据节点 在计算节点判断对应的GTID是否全局可见 如果GTID不活跃,则直接返回数据;如果GTID活跃,则通过undo数据构造全局的前项数据返回 DBproxy将结果集汇总后返回给应用
2.4.3 一致性写
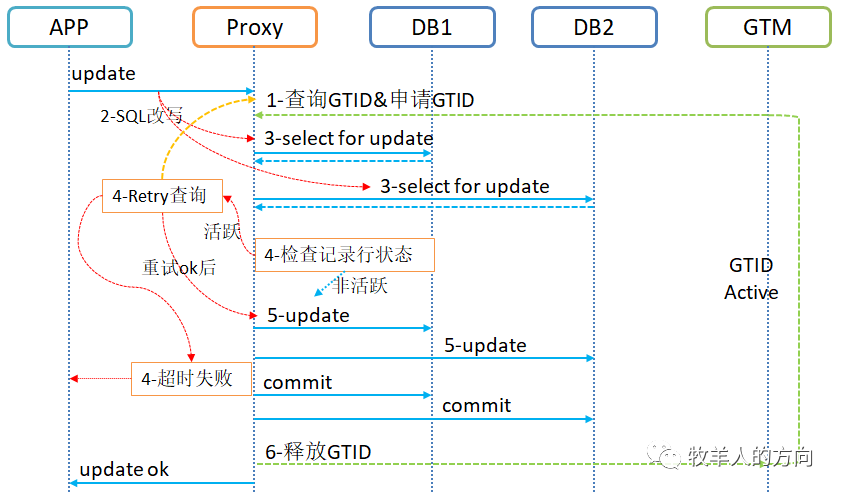
DBProxy计算节点请求活跃事务列表GTID,同时请求创建GTID DBproxy将update更新语句进行改写
将update set a=’xxx’改写为
select pkey,gtid from t1 for update和
update t1 set a=’xxx’,gtid=gtid_no复制
将select for update语句下发到数据节点,并返回结果,select for update会申请加锁,如果出现等锁超时则直接失败 DBProxy对返回的结果进行GTID活跃检查,如果是非活跃GTID,则可以直接下发update语句;如果是活跃GTID,则尝试重新查询活跃GTID列表,检查OK后可以继续update,如果超时则失败 GTID活跃检查OK以后,将update语句下发到数据节点执行,update语句会更新gtid字段,当前时段该数据行的记录是被该事务更新,GTID为活跃状态 所有节点更新完成并提交后,是否GTID DBProxy再将事务处理的结果返回给应用端


最后修改时间:2021-12-25 08:38:31
文章转载自GoldenDB分布式数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
3347.6万!国家开发银行定向采购 GoldenDB 授权及服务
通讯员
251次阅读
2025-03-06 16:50:57
GoldenDB数据库社区正式上线!期待与您共享新知
GoldenDB分布式数据库
230次阅读
2025-03-12 14:06:39
乌兰察布市政府数据库框采:金仓、海量、东方金信、神通、GreatDB、虚谷、GoldenDB等产品入围
通讯员
123次阅读
2025-03-26 10:34:16
聊聊跨数据库迁移的数据比对那些事儿
吾亦可往
113次阅读
2025-03-06 09:03:06
GoldenDB革新数据库 DDL 事务执行,提升效率与性能
吾亦可往
107次阅读
2025-03-05 11:30:03
GoldenDB的数据库查询优化:如何让数据查询更快、更高效?
吾亦可往
88次阅读
2025-03-04 11:15:18
首届GoldenDB金融核心应用技术研讨会在京成功举办!
GoldenDB分布式数据库
78次阅读
2025-03-12 10:23:13
GoldenDB数据转发方法、系统、电子设备和存储介质
李奇
63次阅读
2025-03-04 15:17:29
GoldenDB:赋能公积金系统数字化转型,打造安全高效的数据基石
张芝
57次阅读
2025-03-28 17:41:22
GoldenDB孤岛演练
韦
53次阅读
2025-03-28 21:15:56




