




111:总体需要调整的参数,进行列举和调整(读、写、日志、用户线程、并发)
1. 连接相关的参数
max_connections#最大连接数
max_connection_errors#最大错误连接数
2. 用户连接线程相关的参数
thread_cache_size#复用的线程数
query_cache_size#查询缓冲
3. 日志相关的参数,包括redo log、binlog、slowlog、err log
redo log
innodb_flush_log_at_trx_commit#指定redo记录日志的方式
innodb_log_file_size#重做日志文件大小
innodb_log_files_in_group#重做日志文件的数量
innodb_mirrored_log_groups#日志镜像文件组的数量
innodb_log_group_home_dir#日志文件组所在路径
bin log
log_bin #指定文件名和开关
sync_binlog #缓冲刷新的次数
max_binlog_size#指定单个二进制文件的最大值
binlog_cache_size#分配给每个线程的缓存大小
binlog-do-db #需要写入哪些库的日志
binlog-ignore-db#需要忽略哪些库的日志
log_slave-update#从库中是否需要重写主库的二进制
binlog_format #记录二进制日志的格式
(slow log上面已提过)
log_error #记录错误日志的路径
4. innodb buffer pool相关的参数
innodb_buffer_pool_size#指定缓冲池占用内存的大小
innodb_buffer_pool_instances#缓冲池实例数量
innodb_max_dirty_pages_pct#进行脏页刷新的百分比
innodb_log_buffer_size#重做日志缓冲池大小
innodb_lru_scan_depth#控制lru列表可用页的数量
5. undo相关的参数
innodb_undo_directory#文件路径
innodb_undo_logs#回滚段的个数
innodb_undo_tablespaces#构成回滚段的文件数量
6. 读写线程相关的参数
innodb_io_capacity#io吞吐量
innodb_io_capacity_max#io最大吞吐量
innodb_write_io_threads#写线程数量
innodb_read_io_threads#读线程数量
innodb_purge_threads#刷新线程数量
innodb_flush_neighbors#刷新邻接页开关
innodb_doublewrite#两次写开关
7. 事务相关的参数
8. 主从相关的参数
9. 并发相关的参数
10. 5.7新特性相关的参数
slave-parallel-type=LOGICAL_CLOCK#选择并行复制的方式
slave-parallel-workers#worker线程数
slave-preserve-commit_order#是否需要严格保持
master_info_repository#决定从机的二进制日志位置是否被写入文件或表
relay_log_info_repository#决定从机的中继日志位置是否被写入文件或表
relay_log_recovery#此参数控制是否启动实例就开始读中继日志恢复数据
112:mysql 重启面临的巨大风险,如何避免。
风险:
1. 可能需要很长时间进行脏页刷新,undo回收和insert buffer合并写入;
2. 重启后可能需要进行大量的物理读操作;
3. 重启后可能会进行前滚和回滚操作;
4. 参数不一致,有可能导致数据库起不来
5. 发生性能抖动
如何避免:
1. 避免有大事务和长事务
2. 对比参数,写入my.cnf
3. 正常关闭,提高关闭安全级别
4. 不重启
113:5.7 里面如何对 undo 进行收缩。
innodb_undo_tablespaces=4
innodb_undo_logs=128
innodb_max_undo_log_size=1G
innodb_purge_rseg_truncate_frequency
innodb_undo_log_truncate=1
首先要通过第一个参数打开undo的独立表空间,然后第五个参数是该特性的开关;它就会自动检测大于100M的undo log日志,如果有就进行truncate操作,对它进行空间的回收,回收后的大小默认为10M。
114:详细解读MySQL 常用参数。
[mysqld]
# basic settings
user = mysql 使用哪个用户启动数据库
sql_mode ="STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER"
autocommit = 1
character_set_server=utf8mb4
transaction_isolation =READ-COMMITTED 事物的隔离级别
explicit_defaults_for_timestamp = 1
max_allowed_packet = 16777216
event_scheduler = 1
# connection #
interactive_timeout = 1800
wait_timeout = 1800
lock_wait_timeout = 1800
skip_name_resolve = 1
max_connections = 1500
max_connect_errors = 1000000
# session memory setting #
read_buffer_size= 16777216 如果没有myisam业务表和频繁的访问需求,这个参数不需要调整这么大
read_rnd_buffer_size = 33554432
sort_buffer_size = 33554432
tmp_table_size = 67108864
join_buffer_size = 134217728
binlog_cache_size=2048000
如果tmp_table_size,join_buffer_size太小的话,会导致
Created_tmp_disk_tables和Created_tmp_tables大量的增大
Sort_merge_passes如果大于0,说明sort出现空间不够的情况,需要增加sort buffer size
如果binlog_cache_disk_use大于0
说明binlog_cache_size设置小了
# log settings #
log_error = error.log #错误日志
slow_query_log = 1 #启用慢查询
slow_query_log_file = slow.log 慢查询记录地址
log_queries_not_using_indexes = 1 记录没有使用索引的sql(对于mysql,凡是DML操作基本上都要走索引)
log_slow_admin_statements = 1 对一些管理性的sql,如果执行慢的话会进行记录,mysql的管理sql风险很大!
log_slow_slave_statements = 1
log_throttle_queries_not_using_indexes =10 对没有使用索引的sql最多只记录10个
expire_logs_days = 90 自动保存90天binlog,定期会手工区清理,因为机器可能会造成抖动。。。。。
long_query_time = 2 慢查询设置时间
min_examined_row_limit = 100 sql执行大于100行会记录到慢查询
binlog-rows-query-log-events = 1
log-bin-trust-function-creators = 1 支持建立函数
log-slave-updates = 1 从库是否记录主库的binlog
# innodb settings #
innodb_page_size = 16384 数据页默认16k
innodb_buffer_pool_size = 160G
innodb_buffer_pool_instances = 16 缓冲池实例数量
innodb_buffer_pool_load_at_startup =1 开启的时候会把热数据相关地址开启
innodb_buffer_pool_dump_at_shutdown = 1 关闭的时候会把热数据相关地址记录
innodb_lru_scan_depth = 4096
innodb_lock_wait_timeout = 5 锁超时时间
innodb_io_capacity = 10000
innodb_io_capacity_max = 20000
innodb_flush_method = O_DIRECT 往回写的时候不用文件系统缓存,直接写到磁盘上,安全保证
innodb_file_format = Barracuda
innodb_file_format_max = Barracuda
innodb_undo_logs = 128
innodb_undo_tablespaces = 3
innodb_flush_neighbors = 0
innodb_log_file_size = 17179869184
innodb_log_files_in_group = 2
innodb_log_buffer_size = 16777216
innodb_purge_threads = 4
innodb_large_prefix = 1 建索引的时候可以达到3k
innodb_thread_concurrency = 64 允许的并发的线程的数量(至少等于cpu的核数)(两倍cpu的核数最好,小机可以达到四倍)
innodb_print_all_deadlocks = 1
innodb_strict_mode = 1 严格限制模式,会把许多有warnng当成错误来报
innodb_sort_buffer_size = 67108864
innodb_write_io_threads = 16 默认情况下 cpu核数的一半
innodb_read_io_threads = 16
innodb_file_per_table = 1 表的存储方式
innodb_stats_persistent_sample_pages =64 采样 页
innodb_autoinc_lock_mode = 2
# replication setting #
master_info_repository = TABLE
relay_log_info_repository = TABLE
sync_binlog = 1
gtid_mode = on
enforce_gtid_consistency = 1
log_slave_updates
binlog_format = ROW
binlog_rows_query_log_events = 1
relay_log = relay.log
relay_log_recovery = 1
binlog_gtid_simple_recovery = 1
slave_skip_errors = ddl_exist_errors
slave-rows-search-algorithms ='INDEX_SCAN,HASH_SCAN'
#semi sync replication settings #
plugin_load ="validate_password.so;rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
rpl_semi_sync_master_enabled = 1
rpl_semi_sync_master_timeout = 3000
rpl_semi_sync_slave_enabled = 1
# password plugin #
validate_password_policy=STRONG
validate-password=FORCE_PLUS_PERMANENT
[mysqld-5.7]
# new innodb setting #
loose_innodb_numa_interleave=1
innodb_buffer_pool_dump_pct = 40 数据库关闭,会记录40%的热区域
innodb_page_cleaners = 16 增加刷新脏页的线程的数量
innodb_undo_log_truncate = 1
innodb_max_undo_log_size = 2G
innodb_purge_rseg_truncate_frequency =128
# new replication setting #
slave-parallel-type = LOGICAL_CLOCK
slave-parallel-workers = 16
slave_preserve_commit_order=1
slave_transaction_retries=128
# other change setting #
binlog_gtid_simple_recovery=1
log_timestamps=system 生成log记录当前服务器时间
show_compatibility_56=on (5.7版本以后很多参数从information 改到performance中,目的是为了让很多工具可以使用,打开之后可以找到)
115:mysql 最佳实践安装,同时进行压力测试,不断调试各种参数,得到最佳性能,写出安装以及调试整个过程,并且划出性能趋势图,写出调试依据。
根据新特性及业务场景需求进行版本最佳选择
压力测试及参数优化调整
硬件选型及硬件参数分析解读
OS 全方位参数优化
BBU 及 BIOS 参数优化调整
PCIe 闪卡性能分析及对应参数优化
使用 shell、python、zabbix 对几十种状态值进行监控和分析
能够对系统几十种状态参数进行深度分析,剖析关联性及对应的故障点分析
反复调整、迭代方式进行参数优化、性能监控
116:mysql 服务器常见的几种硬件架构,文件系统选型及 mount 注意事项。
1. 硬件
1.1 CPU
调整服务器的BIOS设置,目的是发挥CPU最大性能和避免经典的NUMA问题:
(1)选择Performance Per Watt Optimized(DAPC)模式,发挥CPU最大性能,跑DB这种通常需要高运算量的服务就不要考虑节电了;
(2)关闭C1E和C States等选项,目的也是为了提升CPU效率;(3)MemoryFrequency(内存频率)选择Maximum Performance(最佳性能);
(4)内存设置菜单中,启用Node Interleaving,避免NUMA问题;
1.2 磁盘IO
按照IOPS性能提升的幅度排序,对于磁盘I/O可优化的一些措施:(1)使用SSD或者PCIE SSD设备,至少获得数百倍甚至万倍的IOPS提升;
(2)购置阵列卡同时配备CACHE及BBU模块,可明显提升IOPS(主要是指机械盘,SSD或PCIe SSD除外。同时需要定期检查CACHE及BBU模块的健康状况,确保意外时不至于丢失数据);(3)有阵列卡时,设置阵列写策略为WB,甚至FORCE WB(若有双电保护,或对数据安全性要求不是特别高的话),严禁使用WT策略。并且关闭阵列预读策略,基本上是鸡肋,用处不大;
(4)raid卡尽可能选用RAID-10,而非RAID-5;
(5)使用机械盘的话,尽可能选择高转速的,例如选用15KRPM,而不是7.2KRPM的盘。
2. 操作系统
2.1 文件系统层
在文件系统层,下面几个措施可明显提升IOPS性能:
(1)使用deadline/noop这两种I/O调度器,不使用cfq(不适合跑DB类服务);
(2)使用xfs和ext4文件系统,不使用ext3;但业务量很大的情况下更适合用xfs;
(3)文件系统mount参数中增加:noatime, nodiratime, nobarrier几个选项(nobarrier是xfs文件系统特有的);
117:选择和调整mysql所在服务器的硬盘的调度策略(针对闪盘和普通硬盘),并解释noop、deadline、anticipatory、cfq 工作机制。
1.CFQ(Completely FairQueuing, 完全公平排队)
特点:
在最新的内核版本和发行版中,都选择CFQ做为默认的I/O调度器,对于通用的服务器也是最好的选择.
CFQ试图均匀地分布对I/O带宽的访问,避免进程被饿死并实现较低的延迟,是deadline和as调度器的折中.
CFQ对于多媒体应用(video,audio)和桌面系统是最好的选择.
CFQ赋予I/O请求一个优先级,而I/O优先级请求独立于进程优先级,高优先级进程的读写不能自动地继承高的I/O优先级.
工作原理:
CFQ为每个进程/线程单独创建一个队列来管理该进程所产生的请求,也就是说每个进程一个队列,各队列之间的调度使用时间片来调度,以此来保证每个进程都能被很好的分配到I/O带宽.I/O调度器每次执行一个进程的4次请求.
2. NOOP(电梯式调度程序)
特点:
在Linux2.4或更早的版本的调度程序,那时只有这一种I/O调度算法.
NOOP实现了一个FIFO队列,它像电梯的工作主法一样对I/O请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一介质.
NOOP倾向饿死读而利于写.
NOOP对于闪存设备,RAM,嵌入式系统是最好的选择.
电梯算法饿死读请求的解释:
因为写请求比读请求更容易.
写请求通过文件系统cache,不需要等一次写完成,就可以开始下一次写操作,写请求通过合并,堆积到I/O队列中.
读请求需要等到它前面所有的读操作完成,才能进行下一次读操作.在读操作之间有几毫秒时间,而写请求在这之间就到来,饿死了后面的读请求.
3. Deadline(截止时间调度程序)
特点:
通过时间以及硬盘区域进行分类,这个分类和合并要求类似于noop的调度程序.
Deadline确保了在一个截止时间内服务请求,这个截止时间是可调整的,而默认读期限短于写期限.这样就防止了写操作因为不能被读取而饿死的现象.
Deadline对数据库环境(ORACLERAC,MYSQL等)是最好的选择.
4. AS(预料I/O调度程序)
特点:
本质上与Deadline一样,但在最后一次读操作后,要等待6ms,才能继续进行对其它I/O请求进行调度.
可以从应用程序中预订一个新的读请求,改进读操作的执行,但以一些写操作为代价.
它会在每个6ms中插入新的I/O操作,而会将一些小写入流合并成一个大写入流,用写入延时换取最大的写入吞吐量.
AS适合于写入较多的环境,比如文件服务器
AS对数据库环境表现很差.
查看当前系统的I/O调度:
#cat /sys/block/sda/queue/scheduler
noop anticipatory deadline [cfq]
临时更改I/O调度:
例如:想更改到noop电梯调度算法:
echonoop > /sys/block/sda/queue/scheduler
永久更改I/O调度:
修改内核引导参数,加入elevator=调度程序名
#vi /boot/grub/menu.lst
更改到如下内容:
kernel/boot/vmlinuz-2.6.18-8.el5 ro root=LABEL=/ elevator=deadline rhgb quiet
重启之后,查看调度方法:
#cat /sys/block/sda/queue/scheduler
noop anticipatory [deadline] cfq
普通硬件:deadline
固态盘或者闪卡:Noop
118:解释何为BBU 的自动校正功能,为何自动校正期间,服务器 io 性能大幅减低,出现明显的性能抖动。
BBU自动校正便于raid卡了解电池的状态,同时延长电池的使用寿命,定期会启动自动校准模式,检测能支持系统多少时间,当检测到时间不够的时候,会报警系统,写缓存关闭。
每隔一段时间,会进行一次充放电,计算中间时间,这个时间段默认关闭相关参数(如果不关闭,会造成数据损坏)。充放电期间,写缓存关闭,读性能大幅度降低,整体io带宽降低,数据库性能发生抖动。
119:判断 BBU 是否处于自动校准模式工作中、电池是否需要更换。
查看BBU的状态:
Megacli64-AdpBbuCmd -GetBbuStatus -Aall
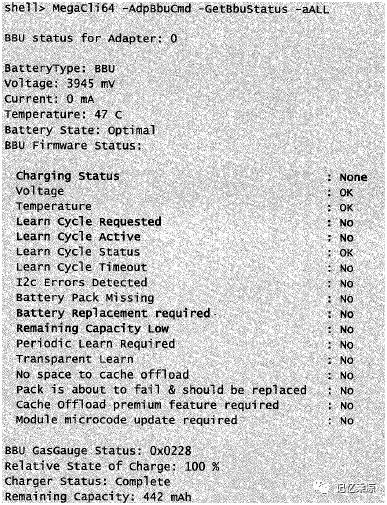
ChargingStatus: None, Charging, Discharging:分别表示BBU处于不充放电状态,充电状态,放电状态
Learn CycleRequested:yes代表当前有learn cycle请求,正处于校准中。
Learn CycleActive:yes代表处于learn cycle校准阶段,控制器开始校准
BatteryReplacement Required:yes表示电池需要更换
RemainingCapacity Low: yes表示电池容量过低,需要更换电池
电池校准一般经过三个阶段:
raid卡控制器将bbu充满到最大程度
开始放电
放点结束后重新将bbu充满到最大程度
120:解释默认和当前生效的 raid 卡策略:写缓存策略、预读策略、读缓存策略、电池故障是否启用写缓存。
通过Megacli64 -LDinfo-Lall -aALL查看当前raid卡设置的缓存策略
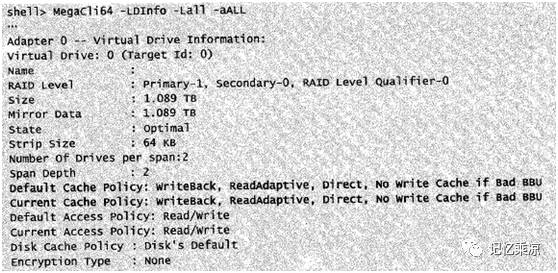
Default Cacbe Policy:默认的缓存策略
Current Cache Policy:当前生效的缓存策略
缓存策略第一段:(写缓存策略)
写缓存策略,包括WriteBack 和WriteThrougha
WriteBack:写入操作的时候,将数据写入raid卡之后直接返回,raid卡空值其将在系统负载低或者raid缓存满的情况下把数据写入磁盘,减少了磁盘操作的频次,大大提升了raid卡的写入性能,在大多数的情况下有效的降低系统IO。写入raid卡缓存的数据可靠性由raid卡的bbu保证
WriteThrough:进行写入操作的时候,不使用raid卡缓存,数据直接写入磁盘才返回,也就是raid卡写缓存被穿透,每次写入都直接写入磁盘,大多数情况下,WriteThrough的策略设置会造成系统IO负载上升。与WriteBack相比,不需要BBU电池来保证数据的完整性,但写性能大幅度下降
缓存策略第二段:(预读策略)
是否开启预读,包括ReadAheadNone,ReadAhead 和ReadAdaptiveo
ReadAheadNone:不开启预读
ReadAhead:开启预读(随机读的情况下,会降低随机读的性能)
ReadAdaptive:自适应预读,需要消耗一定的计算能力,默认的策略
缓存策略第三段:(读缓存策略)
读操作是否缓存到raid卡缓存中,包括direct和cached
Direct:读操作不缓存到raid卡缓存中
Cached:读操作缓存到raid卡缓存中
缓存策略第四段(电池故障是否启用策略)
No Write Cache if Bad BBU:如果bbu出现问题,则不再使用Write Cache,从WriteBack自动切换到WriteThrough模式。确保在没有bbu电池支持的情况下,直接写入磁盘而不是raid卡缓存,以确保数据安全
Write Cache OK ifBad BBU:如果bbu出问题,仍然启用Write Cache(不推荐)。如果bbu出问题,无法保证意外断电后的数据能完整写会磁盘,除非有ups后备电源。
Raid卡的缓存策略可以通过MegaCii64-LDSetProp进行修改。
常用操作如下:WriteBack, WriteThrough,WriteCacheOKifBadBBU, NoWriteCacheifBadBBU

