




11:如何调整内存参数 innodb_old_blocks_pct,以及 innodb_old_blocks_pct的意义?用来避免什么问题?innodb_old_blocks_pct 如何通过相关的指标值来确认这几个参数,是否需要调整?
innodb_old_blocks_pct代表LRU列表中midpoint的位置,也是冷端所占的比例。可以在配置文件my.cnf中添加innodb_old_blocks_pct=20进行修改。
innodb_old_blocks_time表示页读取到midpoint位置后需要等待多久才会被加入到热端。
使用show engine innodb status \G;这个命令可以查看相关信息

Pagesmade young有多少页刷到热端 ;not young有多少页没有刷到热端
youngs/s每秒有多少页刷到热端;non-youngs/s每秒有多少页没被刷到热端
non-young很高的原因:
1.可能存在严重的全表扫描
2.可能是pct设置过小
3.可能是time设置过大
pages madeyoung很高的原因:
1.pct过大
2.time过小
Bufferpool hit rate 该值表示缓冲池的命中率,该值不应小于95%,如果小于,该观察LRU列表是否被污染。
12:关于 log buffer 调整成 100M 的理论依据
适合调整成100M的场景:
1.内存空间足够大
2.操作频繁,日志产量大
默认只有1M,根据刷新的机制,如果在大文本等情况下写入频繁,就会造成刷新频繁产生额外的IO,但IO线程是有限的,一旦发生阻塞现象造成log buffer写满,会影响数据库的正常运行,甚至宕机。可以参照Innodb_log_waits这个值,如果它不是0,就需要增加innodb_log_buffer_size了。
13:描述 change buffer 的作用,确认 change buffer 占用的大小,确认 change buffer 带来的效果,分析 change buffer 占用过大,或者效果不明显的原因。
Change buffer的主要目的是将对二级索引的数据操作缓存下来,以此减少二级索引的随机IO,并达到操作合并的效果。一般DML操作过多的情况下,就会产生索引的随机IO过多的问题。在MySQL5.5之前的版本中,由于只支持缓存insert操作,所以最初叫做insert buffer,只是后来的版本中支持了更多的操作类型缓存,包括 insert buffer、delete buffer、purge buffer,才改叫change buffer。Change buffer 在innodb buffer pool 中开辟内存空间 ,物理上存储在共享表空间中。
innodb_change_buffer_max_size确定change buffer 最大使用内存(默认25,最大50)
如何解决索引的离散读问题(因为DML造成的):
1.尽量调大change buffer的大小
2.适度建立索引 ,单表索引数不要过多,建议使用联合索引
Change buffer: size 1, free list len 0, segsize 2, 0 merges
merged operations: 被合并的操作
insert 0, delete mark 0, delete 0
discarded operations: 消失的操作
insert0, delete mark 0, delete 0
seg size(表示change buffer 占用内存的大小 为2*16k)
change buffer 过大且增长迅猛的原因:
1.数据库的索引列DML操作频繁,或者出现批量操作
2.表的索引过多
3.有一些索引几乎不会被使用
14:调整 change buffer 占用空间大小,以及调整依据,调整只是对 insert 进行合并(merge)。
附加一个问题:怎么判断一个表上索引的数量,以及在那些列上建立索引(查询数据字典)?
innodb_change_buffer_max_size=50 该大小与buffer pool 相关。
索引被缓存的条件:
1.用户设置了选项innodb_change_buffering;
2.只有叶子节点才会去考虑是否使用change buffer;
3.对于聚集索引,不可以缓存操作;
4.对于唯一二级索引(unique key),由于索引记录具有唯一性,因此无法缓存插入操作,但可以缓存删除操作;
5.表上没有flush 操作,例如执行flush table for export时,不允许对表进行 change buffer 缓存 。
被合并的条件:
1.用户线程选择二级索引进行数据查询,这时候必须要读入二级索引页,相应的change buffer需要merge到Page中。
2.当尝试缓存插入操作时,如果预估page的空间不足,可能导致索引分裂,则定位到尝试缓存的page no在change buffer btree中的位置,最多merge 8个page,merge方式为异步,即发起异步读索引页请求。
3.若当前change buffer tree size 超过change buffer->max_size + 10时,执行一次同步的merge,merge的page no为随机定位的cursor,最多一次merge 8个page,同时放弃本次缓存。
4.若本次插入change buffer操作可能产生change buffer btree索引分裂时:
当前change buffer size< change buffer max_size, 不做处理;
当前change buffer size>= change buffer max_size + 5 时,执行一次同步change buffer merge,位置随机;
当前Change buffer size介于change buffer max_size 和change buffer max_size +5 之间时。执行一次异步change buffer merge,位置随机。
5.后台master线程发起merge
master线程有三种工作状态:
IDLE:实例处于空闲状态,以100%的io capacity来作merge操作,相当于一次merge的page数等于innodb_io_capacity。
ACTIVE:实例处于活跃状态,这时候会以如下算法计算需要merge的page数,默认merge的数量为innodb_io_capacity的5%,如果当前change bufferbtree size超过最大值的一半,则尝试多做一些merge操作。
SHUTDOWN:当执行slow shutdown时,会强制做一次全部的change buffer merge
6.对某个表执行flush table 操作时,会触发对该表的强制change buffer merge,例如执行:
flush table tbname for export;
flush table tbname with read lock;
实际上强制change buffermerge主要是为flush forexport准备的,当执行该命令后,为了保证能安全的将ibd拷贝到其他实例上, 需要对该表应用全部的change buffer 缓存。
show index from tblname;或者show keys from tblname;可以查看表的索引信息
命令查询的信息:
Table(表的名称)
Non_unique(是否唯一)
Key_name(索引名称)
Seq_in_index(索引的序号)
Column_name(列名称)
Collation(列的存储方式,有值‘A’(升序)或NULL(无分类))
Cardinality(索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机 会就越大)
Sub_part(如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。)
Packed(指示关键字如何被压缩。如果没有被压缩,则为NULL。)
Null(判断列是否含有NULL)
Index_type(用过的索引方法:BTREE, FULLTEXT, HASH, RTREE)
15:描述一下索引的工作过程,适合使用的场合,描述一下索引如何结合 insert buffer 进行数据访问。如何建立索引,确认索引是否生效。
索引的工作过程:索引是对记录按照多个字段进行排序的一种方式。对表中的某个字段建立索引会创建另一种数据结构,其中保存着字段的值,每个值又指向与它相关的记录。这种索引的数据结构是经过排序的,因而可以对其执行二分查找。 假设使用线性查找搜索id字段共100万个数据块,且这个字段是键字段(每个字段的值唯一),需要访问 N/2 = 500 000个数据块才能找到目标值。不过,因为这个字段是经过排序的,所以可以使用二分查找法,而这样平均只需要访问log2 1000000 = 19.93 = 20 个块。显然,这会给性能带来极大的提升。辅助索引比主键索引多一倍的IO,因为需要回表进行查询具体数据。
适合的场合:
1.建索引的列应该是热条件。
2.建索引的列的唯一性要高。
3.在经常使用范围和排序的列上可以建立索引。
4.在经常做表连接的列上可以建立索引。
5.在where条件中经常出现的列上可以建立索引。
6.使用函数和运算的列不会走索引。
7.在经常查询的多个列上建立复合索引,但要按频率来确定索引的顺序。
8.数据量小的情况下可以使用覆盖索引避免回表。
9.对于长字段的列不使用索引,但MySQL支持前缀索引。
insertbuffe带来的问题:
1.磁盘上的索引在正常工作期间,索引数据和表数据有可能是不一致的;
2.通过索引进行数据查询时,需要先将索引页读取到内存,再将change buffer中的相关数据合并到索引页中,保证数据一致性,再进行进一步的查询;
3.数据库崩溃后,要使索引能够正常使用,需要磁盘上的索引数据+change buffer中的索引数据+内存中的changebuffer 对应的redo log进行恢复。
建立索引: CREATE [UNIQUE|CLUSTERED]INDEX INDEX_NAME ON TABLE_NAME(PROPERTY_NAME)
要查看索引是否生效,可以通过explain执行计划查看相应的SQL进行分析查询。
16:描述一下 double write 解决的场景,工作过程,如何打开和关闭这个功能,通过这个功能对应的指标(status),来确认系统写操作是否有压力,并做出解释.
当innodb存储引擎正在写入某页到表中的时候,如果这个时候发生数据库宕机,就可能出现这个页只写了一部分的现象,比如16K可能只写了4K,这种情况被称为部分写失效,会导致数据丢失。利用double write就可以解决这个问题,它保证了数据页的可靠性。
工作过程:double write 具有两个部分,一个是在内存中doublewrite buffer,一个是在共享表空间里的连续的128个页,两部分大小都为2MB。刷新脏页时,会先将脏页写到doublewrite buffer中,然后分两次每次1MB顺序的写入到共享表空间中,完成这个操作后,再将脏页通过fsync函数同步到磁盘中。
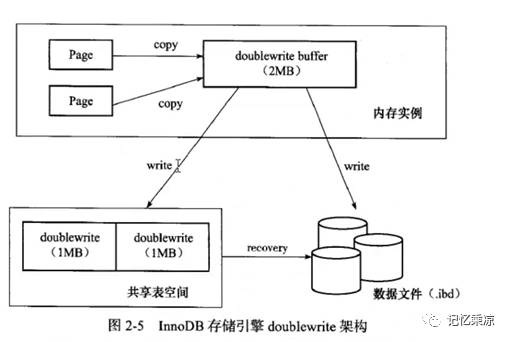
、
innodb_doublewrite # 该参数为double write 的开关
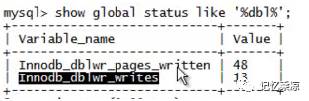
Innodb_dblwr_pages_written表示通过double write写入的页数
Innodb_dblwr_writes 表示实际写入的次数
因为double write是按照1MB的大小写入的,所以一次最多写64页。也就是说这两个参数的比如果是64:1的话表示每次都写满,代表着系统写的压力很高;如果远小于64:1的话就说明系统写入压力不高。
17:通过索引来访问表,主要资源消耗分析,尤其在什么情况下,资源消耗特别厉害(多行的时候)。
索引页也是B+树结构,通过索引会消耗树高
走非聚集索引时,会进行回表,消耗IO
通过索引进行group by和order by时会进行排序,消耗CPU
范围查找同样需要排序,也会消耗CPU
18:自适应哈希索引要降低的是哪个资源消耗,描述其工作过程,理解哈希运算,通过读取相关指标,来确认这个功能效果,学会打开和关闭这个功能。
哈希是一种非常快的查找方法,其时间复杂度为O(1)。哈希算法是由哈希表实现的,哈希表也称散列表是直接寻址表改进得来,在哈希表中,有关键字域和元素链表,每一个关键字都映射着链表中的某一个元素,实现数据查询。在innodb中,哈希函数就采用了除法散列的方式,哈希表都会有一个指向相同哈希函数值的页,其关键字则是表空间space_id左移20位加上自身space_id和数据页偏移量offset的值。
自适应哈希索引可以降低树高消耗的问题,访问树高一般是消耗内存,基本上不会造成性能影响。
工作过程:innodb存储引擎会监控表上各索引页的情况,会自动根据访问的频率和模式来自动的为某些热点页建立哈希索引。其规则有三点:
条件中使用等值查询即=号
以同一模式访问同一数据100次
以同一模式访问同一数据N次,N=页中记录/16
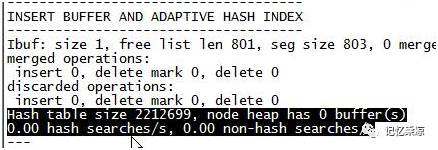
可以通过hashsearches/s和non-hashsearches/s大概了解AHI的效率,据官方文档显示,启用该功能后,IO速度可以提升2倍,副主索引的连接操作性能可以提升5倍。
Innodb_adaptive_hash_index 该参数为AHI的开关,默认为开启状态。
19:描述异步 io 的好处,如何确认打开异步 io(操作系统层面确认异步 io 开启,linux 默认开启,数据库层面开启 参数:| innodb_use_native_aio | ON )
Sync IO:每进行一次IO操作,需要等待整个操作流程结束才可以进行下一次的操作。
AIO:异步IO可以发出一个IO请求后立即发出另一个IO请求,都发送完成后再等待其操作结束。它还可以进行IO merge操作,会将相同的多个IO合并为1个IO,可以提高IOPS性能。
如果是进行像全文查询这样的操作,异步IO就可以解决死等的问题,大大提高了磁盘的操作性能。官方文档中,启用该功能可以提高恢复速度75%。数据库开启该功能需要操作系统的支持,windows和Linux支持,mac osx不支持。
20:描述一下 innodb_flush_neighbors 的功能,以及学会如何打开和关闭。
刷新邻接页工作原理:当写一个脏页到磁盘时,innodb存储引擎会检测该页所在区的所有页,如果有脏页便会一起写入,
优点:利用AIO将多个IO操作合并成一个,提高IO和效率。
缺点:一般进行写入的脏页是比较冷的,进行邻接页写入的时候有可能会把比较热的页一起写入,那比较热的页可能很快又会脏,反而降低了效率。
是否开启该参数应参考实际情况,主要是磁盘的选型和IOPS的性能,一般建议关闭该功能。
