




1:IT 行业数据库布局分析
大型数据库 Oracle 中型数据库 SQL Server 小型数据库 MySQL
2:完整的描述 sql 工作过程,用户线程建立,工作区分配,内存读,物理读,commit,redo log(日志写),物理写(为什么说是后台物理写)
1.线程建立:
每一个用户连接,会产生一个用户线程;showfull processlist; 查看当前用户线程。
2.工作区分配:
每一个用户线程分配一个工作区。
工作区:每个线程会分配一小块内存,作为工作区。
3.内存读:
数据行在内存中,直接从内存读取的过程。
4.物理读:
数据从内存中找不到,就去磁盘里找,从磁盘读到内存叫物理读。
5.物理写:
数据从内存写到硬盘。物理写不计算在sql执行时间里面,物理写也叫作后台写。
6.redo log(日志写)
详细的记录了每一个数据页里面的数据行的修改(物理操作)
DML会产生 redo log(数据页的地址,数据行,具体动作,动作内容)
可能非常大,增长很快,可以构造脏块
7.commit提交
mysql会将log buffer里面的日志写入到log file中(innodb_flush_log_at_trx_commit)
只要提交成功的sql,保证sql修改的数据就会永久保存(保证事务一致性)
读写过程:
1.用户线程对数据页发送读请求
2.专门的读线程会调用磁盘响应的数据(物理读)(磁盘数据区>内存区)
3.读到内存的数据放入工作区进行修改(内存读)(这时,内存中的这一修改的数据叫做脏页,因为这一块数据与原来的数据不一致,没有写入磁盘)(sql语句到这里完成)
1.产生 redo
2.把redo写到buffer中
3.提交commit
4.内存中的数据重新写入磁盘中(数据区)(物理写)
sql语句执行时间包括: 内存查找+物理读+内存读(修改里面的数据行)+logbuffer 写入redo log 中;
执行完成,会留下一个脏数据块;
sql并不管是否执行写动作,但是读会计算到sql执行时间里面;
物理写不计算在sql执行时间里面,物理写也叫作后台写。
3:存储中的缓存和闪存工作机制
缓存:cache(附带有电池,如果存储掉电,cache不掉电,可以提供一个写缓存的过程)
读缓存
工作机制:用户线程来找数据,从内存、存储的cache中找,如果没有,最后从磁盘里面读取,数据读到缓存中,再往内存中读取
特点:
1.缓存里面的数据页跟磁盘数据页是一致的
2.读取数据的时候找缓存,写入数据的时候绕过缓存
3.对读操作,原理上可以提高读取速度,但是对于数据库系统来说,性能提升不是很明显,特别是系统稳定以后
4.对写操作,不能够提高写入速度
写缓存
工作机制:当一个用户线程来找数据,从内存、存储的cache中找,如果没有,最后从磁盘里面读取到内存中,没有必要读到缓存中,修改完之后,写入缓存中。每个用户线程都会去读缓存,因为缓存中有着脏页(最新的数据页,而磁盘中数据页可能是原数据页)。
对写性能有显著着的提升
对读性能基本上和读缓存差不多存储里面主要是写缓存
写缓存失效有三种:
1.电池坏掉
2.电池生命周期结束
3.存储对电池有一个周期性的充放电自动校正功能。充放电期间,存储关闭写缓存,一般三个月一次。
流程:内存中找数据,内存中没有先找存储中的cache,如果没有再找磁盘中。之后找到了数据返回于cache,再由cache写入内存
mysql当内存容量>cache容量时,读cache意义不大。因为cache会起反作用。
Q:cache什么时候起作用??
A:就像cat命令,只是分配内存中的非常小的一小块内存,cat只能先找cache,然后cache到存储中取。
缓存中有预读机制。
例如cat命令,cat查找的时候会将数据分成很多块,一块一块的索要。先要1m的数据,cache会预读2m的数据。磁盘先给内训1m数据,然后内存直接从cache中读取数据。
闪存:1.代替缓存 2.代替存储
闪存每秒可以读五十万次
闪盘对写没有影响
Log file 放在闪存中提高运行速度的前提是数据更新频繁了,否则就无影响
4:msyql 存储引擎简单描述
1.mysql是基于表的插件式存储引擎,储存引擎是如何储存数据,如何为存储的数据建立索引、更新、查询等技术的实现方法。
2.mysql数据库提供了多种储存引擎(例如InnoDB、MyISAM、NDB、Memory),可以根据需求选择。现在绝大多数的场景都是使用innoDB存储引擎,默认也是InnoDB存储引擎。通过show engines;命令可以查看可以使用的引擎。
3.建立表的时候会建立存储引擎。
4.因为存储引擎是基于表的,所以允许同一实例库中存在多个存储引擎。
5:单台服务器安装两套 mysql 实例库
使用多个配置文件启动不同的进程来实现多实例,这种方式的优势逻辑简单,配置简单,缺点是管理起来不太方便。
通过官方自带的mysql_multi使用单独的配置文件来实现多实例,这种方式定制每个实例的配置不太方便,优点是管理起来很方便,集中管理。
数据库的架构设计主要有Shared Everything、Shared Nothing和Shared Disk:
Shared Everything:一般是针对单个主机,完全透明共享CPU/MEMORY/IO,并行处理能力是最差的,典型代表SQL Server。MySQL未能很完美的实现。(科莱斯特尔)
Shared Nothing:各个处理单元都有自己私有的CPU/MEMORY/IO等,不存在共享资源,各处理单元之间通过协议通信,并行处理和扩展能力更好。典型代表DB2和Hadoop。
Shared Disk:各个处理单元使用自己私有的CPU/MEMORY,共享磁盘系统,典型代表Oracle,它是数据共享,可通过增加节点来提高并行处理的能力,扩展能力较好。
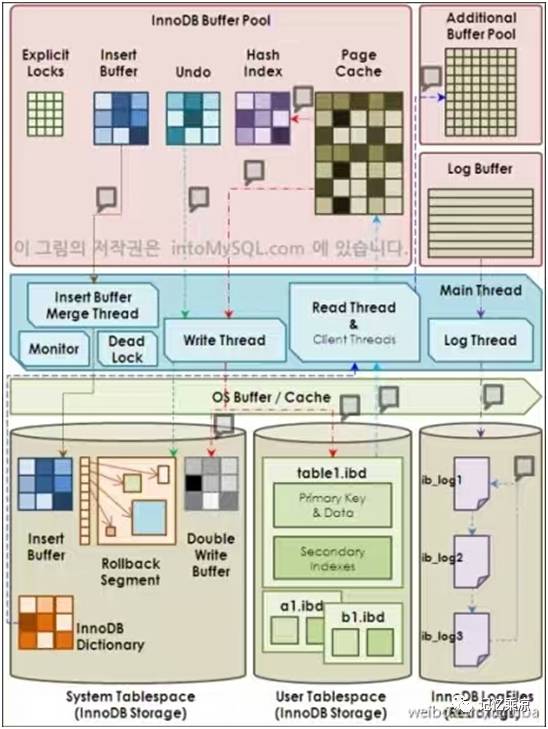
6:绘制 innodb 存储引擎的结构图,进行讲解
Innodb随mysql版本升级且统一。
innodb引擎优点:1.支持行锁,颗粒度小并发性能好;2.支持MVCC多版本并发控制; 3.支持外键 ; 4.支持事务
innodb存储引擎包括
1.后台线程(master thread、IO thread 、Purge thread 、Page Cleaner thread)
2.内存(缓冲池、LRU,Free,Flush List、重做日志缓冲、额外的内存池)
3.物理文件(共享表空间、独立表空间)
7:详细描述一下 commit 的过程和 rollback 的过程,为什么 commit 的速度总是那么快,rollback 很多时候执行的很慢,可能非常慢
undo的作用:
1、rollback;
2、MVCC:一致性读(根据事务隔离级别的不同,在事务中进行读操作时会用undo进行不同版本的读取);写不锁定读(读不加锁,读写互不影响)
事务操作过程:
1.物理读undo数据页
2.物理读表的数据页
3.修改undo数据页,产生redo
4.修改表数据,产生redo
5.(1)commit ,将redo写入log file中
(2)rollback,读取undo中的数据,根据这些数据反向操作修改数据页,产生redo
无论是commit还是rollback,成功执行之后,原则上undo数据就没有用了。之后会进行undo页的回收,purge thread回收undo页,读取undo 页,将里面的一些内容清空;undo页默认存储在共享表空间中,新版本允许移到别的物理位置上。
8:调整相关参数 innodb_buffer_pool_size:物理内存的 50%
读 写 purge 线程为 6
增加 logfile 的大小(5G),增加 logfile 的组数(5 组)
1.进入my.cnf(数据库配置文件)中进行添加修改
innodb_buffer_pool_size =1G (free命令查看内存大小)
innodb_purge_threads=6
innodb_read_io_threads=6
innodb_write_io_threads=6
innodb_log_file_size=5G
innodb_log_files_in_group=5
2.重启服务(1. service mysqld restart 2.shutdown/mysqld_safe )
3.查询 show variables like '相关参数';
如何修改参数
1.参照官方文档
2.参数是否动态
3.参数是全局(是否动态)还是全局+会话(一定是动态,不需要重启数据库)
4.静态参数 修改配置文件 /etc/my.cnf(需要重启)
5.动态参数
set @@ global ;让所有会话重新登陆;修改/etc/my.cnf中的参数
6.修改参数的时候 ,需要参考值的范围以及数据类型
7.强烈建议,修改参数时详细阅读官方文档参数的作用说明
9:描述一下 free list,lru list ,flush list 的作用,为什么需要这三种链
MySQL数据库的缓冲池是一个很大的内存区域,其中存放着各种类型的页,管理起来很麻烦,所以采取了链的方式对其进行管理。
LRU list:LRU列表用来管理已经读取到内存的页,使用频繁的页在链的前端,使用较少的页在链的尾端,当读取的页已经饱和的时候会先释放尾端的页。在LRU列表上有意个midpoint位置,它是新读取的页存放的位置也是old页和new页的分界点。
Free list:Free列表里管理着内存中的空闲页
Flush list:在内存中被修改后的页称为脏页,Flush列表就管理着所有脏页,脏页既存在于Flush列表也存在于LRU列表;Flush列表中的页需要刷新回磁盘。
当需要数据页时,首先会在Free列表中查找是否有可用的空闲页,若有就将该页从Free列表删除并加入LRU列表;若没有则会刷新LRU列表尾部的页,将该内存空间分配给新的页。
10:描述一下 latch 争用的过程,现象,监控指标,解读指标,如何降低 latch 争用
latch 一般称为闩锁(轻量级的锁) 因为其要求锁定的时间非常短,若迟勋时间长,则应用性能非常差,在InnoDB存储引擎中,latch有可以分为mutex(互斥锁)和rwlock(读写锁)其目的用来保证并发线程操作临界资源的正确性,并且没有死锁检测的机制
对于链来说,当线程需要进行遍历时,就锁住这个链,进行遍历。这个线程就开始读这个链的数据结构,看是否是空的,表明是否有人正在遍历,当没有的时候,就把自己的信息写入,表明这个线程持有锁,这个锁就是latch锁。当其他线程需要遍历这个链时,读取其信息就会发现已经有线程正在使用,则其需要等待,等待有两种情况。
举例:
线程1 持有latch,对链正在进行遍历、
线程2 也想持有latch,对链进行遍历
线程2被阻塞,
线程1 工作,占用1个cpu
线程2等待,占用1个cpu. 这个时候该线程有两个选择
1.退出cpu
2.不退出cpu(线程1从链上找页是非常快的,找到之后便会释放这个latch)
表现出的三种状态:
gets 想去获取latch
misses 获取失败就会随机等待一段时间(没有排队),执行空代码,表现出CPU繁忙,防止将其踢出(自旋)。
sleeps 多次misses之后 就会sleeps 一旦sleep发生,说明latch争用比较严重
latch争用原因:
1.内存访问频繁
2.链太长,数据页太多(增加instance的数量)
mutex(互斥锁)是latch锁的一种,比latch小;操作系统有很多链,从操作系统申请一个个的mutex 来管理链。mutex取代了原来的latch(大部分)。
对访问不是很频繁,同时相对较短的链,我们使用mutex就可以来保护这些链;
对于访问频繁的链,会有大量的读写,如果使用mutex保护会出现错误的概率很高,所以使用latch来进行保护。
sleep次数过多的解决方案:
1.优化sql,降低对内存读的数量(效果好)
2.增加instances的数量
