





错误,在ALERT LOG 中,也发现了一些报警信息:
Rejected the attempt to advance SCN over limit by 13 hours worth to
0x0bd8.0000133b, by distributed transaction remote logon, remote DB:
ORA10G.
通过MOS 查到了这是SCN HEEADROOM 的问题,我们暂且称之为SCN 天花板。MOS 的建议是下载并安装最新的PSU,并设置参数_external_scn_rejection_threshold_hours 为24。刚开始的时候并没有搞明白这个参数具体的含义。确实设置这个参数后,问题就没有再出现了。不过随着关于这个问题讨论的深入,很多疑问又冒了出来。特别是周末时和美国ORACLE 的一个哥们在MSN 上聊到此事,那个哥们说是由于客户安装了CPU 2012 JAN 安全补丁,才出现很多用户出现了ORA-19706 的问题。回退了这个补丁,问题就解决了。而且这个问题在ORACLE 内部讳莫如深,他们也不太清楚具体的原因是什么。
(本贴附件为各个版本的oracle 公司提供的scnhealthcheck.sql,实际上各个版本(11g 之前)的差异不是很大,部分打了补丁的11g 的系统,每秒SCN 增长阀值被加大为32K了)
INFOWORLD 在发现这个问题后,在进一步的测试发现更严重的问题,就是DBLINK 的SCN 同步机制。为了实现分布式处理,ORACLE 在多个库做DBLINK 访问的时候,会将SCN 进行同步,也就是将较高的SCN 同步为参与DBLINK 的两个库的SCN,执行DBLINK 操作后,两个库的SCN就同步了。这个机制就可能把SCN 增长异常传播到所有的数据库服务器上。也就是说,如果一个服务级别很低的报表服务器出现故障,可能会影响服务级别特别高的生产服务器。INFOWORLD 把这个问题报告给了ORACLE,并一起进行了一系列的工作,于是在CPU 2012 JAN 中出现了对这个DBLINK 问题的补丁。在介绍这个补丁之前,我们先来了解一段ORACLE SCN 的背景资料。
背景:
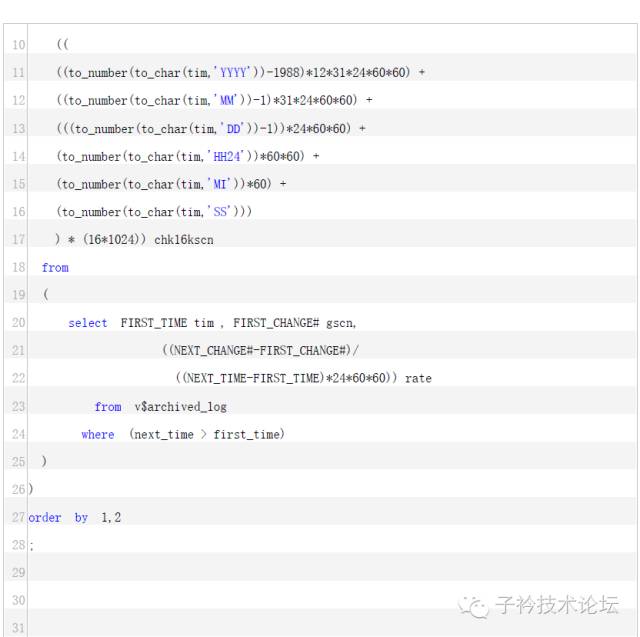
ORACLE SCN 的硬限制和软限制:ORACLE 的SCN 是由48 位来表示的,因此最大值不能超过2 的48 次方,这就是ORACLE scn 的硬限制。Oracle 为了确保48 位的SCN 能够用足够长的时间(500 年),于是对SCN 做出了一个限制,就是每秒钟SCN 最大增长不能超过16K,Oracle 使用了一个十分简单的算法,就是以从1988 年1 月1 日0 点0 分0 秒为基准时间,到当前的秒钟数乘以16K,就是当前SCN 的最大允许值这就是SCN HEADROOM。如果在某个时刻SCN 达到了这个最大值,那么事务就无法提交,需要等到下一秒,这个HEAD ROOM又变大了,才能继续进行事务的提交。
关于这些背景资料请参考:
NOTE:1376995.1 - Information on the System Change Number (SCN) and ho
w it is used in the Oracle Database
NOTE:1393363.1 - Installing, Executing and Interpreting output from the
"SCNhealthcheck.sql" script
NOTE:1388639.1 - Evidence to collect when reporting "high SCN rate" i
ssues to Oracle Support
NOTE:1393360.1 - ORA-19706 and Related Alert Log Messages
对于INFOWORLD 发现的问题,ORACLE 采取了两个很重要的手段,一个是在11.2 中,将SCN 每秒最大的增长量从16K 加大为32K,第二个是引入了一个阀值,用于阻断有SCN HEADROOM问题的系统将故障传播到其他系统。这个修复包含在CPU 2012 JAN 中,打了这个补丁后,我们可以设置一个参数_external_scn_rejection_threshold_hours。这个参数的含义是,当有一个系统和我进行DBLINK 操作的时候,我需要检查他的SCN HEADROOM 的值,如果这个系统的SCN HEADROOM 的值小于这个参数所设置的小时数,那么我就拒绝这个DBLINK 访问(如果DBLINK 两端的数据库都打了补丁,设置了参数,这种检查是双向的),通过拒绝DBLINK 访问,来避免错误被传播。
由于10G 的这个补丁打了后,_external_scn_rejection_threshold_hours 的缺省值是31天(31*24),是个十分大的值,因此很多系统打了这个补丁后,就出现ORA-19706 错误了。而回退了这个补丁后,这方面的限制取消了,报错就没有了。不过隐患就出现了。
实际上这个问题包含两个方面,一方面是如何防止问题的发生,就是防止核心生产系统出现SCN 增长异常的问题出现。目前发现的一系列BUG 都已经得到了控制,包括那个INFOWORLD发现的BEGIN BACKUP 的问题。还有bug13916709,这个补丁是为了修复另外一个SCN BUG而引发的。当一个长时间运行的SQL 和DDL,job 或者GATHER 操作一起执行的时候,会引起CURSOR INVALIDATE,从而触发SCN 异常增长。
另外一个方面是如何在某个系统发生故障的时候,阻止这个故障的传播。CPU 2012 JAN就是用来解决这个问题的,不过这个补丁也摆了一个乌龙,在10g 上,新引入的参数的缺省值太大,需要设置为24,以避出现过多的ORA-19706。如果由于目前系统的SCN 已经比较高了,设置为24 还无法避免ORA-19706,可以尝试进一步减小这个参数。很多客户把这个参数减少为1,这样可以最大限度的减少ORA-19706,不过设置为1,存在一定的隐患,一旦系统遇到了一个人新的SCN 增长过快的BUG,那么,可能我们都没有时间来解决这个问题,建议尽可能不要设置这么低。
事实上,ORACLE 的这些补丁解决了一部分SCN 异常增长的情况,也防止了异常增长的扩散,不过仅仅这些还是没有彻底解决这个问题。如果SCN HEADROOM 的问题出现在一个核心系统上,那么哪怕它没有被扩散,那么核心系统业务受到影响也是无法容忍的。因此我们需要做的事情还更多,特别是如何发现SCN 的异常增长,这就需要我们经常性的对数据库进行监控,并把SCN HEADROOM 检查作为标准的健康检查项,定期进行检查。
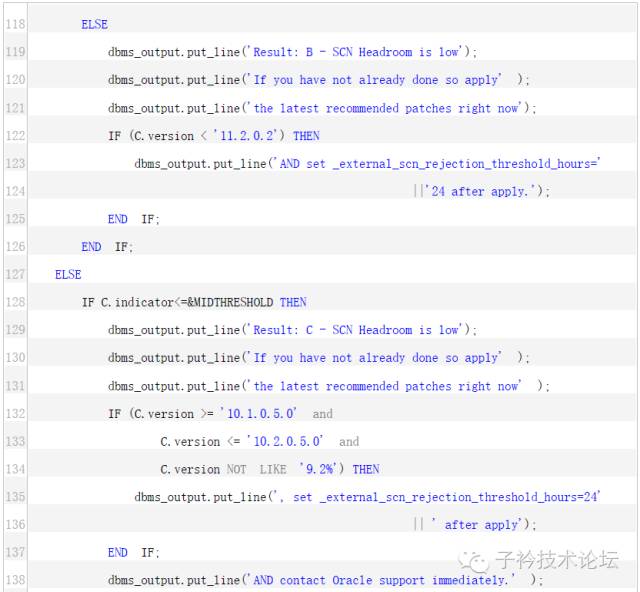
Oracle 发布了一个补丁:Patch:13498243,这个补丁实际上包含的就是一个脚本scnhealthcheck.ql,通过这个脚本可以检查目前本系统的SCN HEADROOM(单位为天),如果SCNHEADROOM 大于62,那么说明这个系统没有SCN HEADROOM 问题,如果小于62 大于10,说明存在问题,不过还不致命。如果小于10,那么就说明问题十分严重,必须立即处理了。实际上这个脚本的核心是以下的SQL:
 除了这个脚本外,我们还可以通过以下手段进行检查(以下建议来自于
除了这个脚本外,我们还可以通过以下手段进行检查(以下建议来自于
Doc ID 1393383.1):
1、经常性检查"calls to kcmgas"系统调用的情况,并建立基线数据。这个指标可以从V$SYSSTATE 去查找,也可以通过AWR 查找历史数据(在AWR 数据中查找历史统计数据的方法参考How to extract the historical values of a statistic from AWR Repository [ID 948272.1])。也可以通过下面的脚本检查某个会话的情况:

2、如果本机的这个调用很少,那么很可能故障是从别的机器传播过来的,如果要查找哪个远程服务器经常连接到某个数据库,可以通过下面的方法:A)对于已经打了补丁的系统,当SCN 传播发生时,ALERT LOG 中会有记录,可以通过ALERT LOG 查找问题的系统。
Advanced SCN by 13238271 minutes worth to 0x0bd6.00000f21, by distribu
ted transaction remote logon, remote DB: ORA10G.
Client info : DB logon user SCOTT, machine gc, program sqlplus@gc
(TNS V1-V3), and OS user oracle
3、除了上面的脚本外,ORACLE 官方还在
How to handle "high SCN rate" Service Requests (Doc ID 1393383.1 中提
供了一个脚本,可以查找历史的SCN HEADROOM:





解决方式:
Oracle 官方关于这个问题的解决方案中,还有两条,一是在今后的版本中将SCN 扩展到64位,第二是今后的版本中可能进一步加大SCN HEADROOM 为更大的值,因为目前已经出现了每秒超过16K 个事务的系统。
如果你的系统已经出现了问题,发现某台核心系统的SCN 被传染了,想要找出是哪些系统和本机有DBLINK 连接,可以通过两个方法,一是通过系统的LOGON 触发器,记录LOGON 的情况,二是通过LOGON 审计,将LOGON 审计数据写入DB,只要设置"AUDIT CREATE SESSION"审计,就可以通过下面的SQL 查询到相关信息:
select distinct "COMMENT$TEXT",userhost from aud$ where "COMMENT$TEXT" like '%DBLINK%'。
以下内容摘自Oracle 公司给客户下发的SCN 问题紧急处置方案中的内容:
在《关于Oracle DB SCN 生成率过高的预警及处理建议》的文章中,我们已经提出SCN生产率过高的原因。作为oracle db 的一种重要预警,我们建议对此作重点关注。在此,我们提出以下几点处理建议:
1. 在全系统内做SCN 生成率的普查,看看各系统的SCN 生成情况是否牵涉生成率过高的现象;
2. 发现SCN 生成率过高的相关数据库,根据本指南及时进行修正处理;
3. 形成日常检查机制,每半月或者每月运行scnhealthcheck.sql,例行检查SCN 的生成率情况;
4.根据相关数据库的dblink 使用情况,形成dblink 跟踪列表,便于日后检查SCN 状态。列表内容包括源数据库名称、目标数据库名称、dblink 名称、dblink 用途,甚至包括关联对象等信息。
方案一:安装PSU/CPU 补丁修复方案
本方案主要针对以下数据库版本:
Oracle 10.2.0.5
Oracle 11.1.0.7
Oracle 11.2.0.2
Oracle 11.2.0.3
针对上述版本的数据库,oracle 建议给数据库安装2012 年4 月发布的PSU,并在安装该PSU的基础上,安装补丁13916709。如果是集群架构,同时给集群软件最新安装PSU。《《《白鳝注:也可以直接安装2012 年7 月的PSU,这个PSU 已经包含了13916709 补丁的修复,如果觉得暂时无法升级PSU,那么也可以单独打13916709 的独立补丁,这个补丁的目的是解决SCN 异常增长的BUG》》》》》
Ø 10.2.0.5 数据库
对于版本为10.2.0.5 的数据库, 建议安装2012 年4 月发布的PSU 13632743,并在安装PSU 13632743 的基础上,安装补丁13916709。参数
_external_scn_rejection_threshold_hours 在2012 年4 月(包含2012 年4 月)以后发布的PSU/CPU 中已经定义默认值为24,所以安装最新PSU 补丁以后,不需要再设该参数。如果是集群架构,同时给集群软件安装PSU 9952245。
Ø 11.1.0.7 数据库
对于版本为11.1.0.7 的数据库,建议安装2012 年4 月发布的PSU 13621679,并在安装PSU 13621679 的基础上,安装补丁13916709。参数
_external_SCN_rejection_threshold_hours 在2012 年4 月(包含2012 年4 月)以后发布的PSU/CPU 中已经定义默认值为24,所以安装最新PSU 补丁以后,不需要再设该参数。如果是集群架构,同时给集群软件安装PSU 11724953。
Ø 11.2.0.2 数据库
对于版本为11.2.0.2 的数据库,建议安装2012 年4 月发布的PSU 13696224,并在安装PSU 13696224 的基础上,安装补丁13916709。如果是集群架构,同时给集群软件安装PSU 13696242。
Ø 11.2.0.3 数据库
对于版本为11.2.0.3 的数据库,建议安装2012 年4 月发布的PSU 13696216,并在安装PSU 3696216 的基础上,安装补丁13916709。如果是集群架构,同时给集群软件安装PSU 13696251。
《《白鳝注:10.2.0.4 目前在PSU 中也已经包含了13916709 的修复。对于目前无补丁发布的版本,Oracle 10.2.0.1、Oracle 10.2.0.2、Oracle 10.2.0.3》》》
10.2.0.4 版本解决方案
本方案针对数据库版本是Oracle 10.2.0.4。oracle 为此提供两种修正方式:
方式一:紧急修复方案
采用前提:数据库SCN 问题急需解决,但升级数据库版本从管理、业务应用、时间上都不适合。
方式建议程度:中
处理方式:保持数据库版本不变,安装2012 年4 月发布的PSU 12879933。在安装12879933之前,必须先安装9352164,这是安装10.2.0.4.4 之后PSU 的前提条件。如果是集群架构,同时给集群软件安装PSU 9294403。参数_external_SCN_rejection_threshold_hours 在2012 年4 月(包含2012 年4 月)以后发布的PSU/CPU 中已经定义默认值为24,所以安装新PSU 补丁以后,不需要再设该参数。
方式二:补丁集升级修复方案
采用前提:数据库SCN 问题急需解决,安装最近补丁集,从管理、应用、时间上都比较适合,但数据库版本升级计划不能在短期内完成。
方式建议程度:中
处理方式:将数据库升级到10.2.0.5 的版本,安装2012 年4 月发布的PSU 13632743,并在安装PSU 13632743 的基础上,安装补丁13916709。如果是集群架构,同时给集群软件安装PSU 9952245。
《《白鳝注:对于其他未涉及版本,ORACLE 为发出补丁包,ORACLE 建议升级到上述已发补丁包的版本:
Oracle 9.2.0.1~9.2.0.8
Oracle 10.1.0.3~10.1.0.5
Oracle 11.1.0.6
Oracle 11.2.0.1
》》》
Oracle 11.2 引入了一个新的隐含参数来控制每秒的SCN HEADROOM,11G 的缺省值是32K
Parameter Sessio
n Value
---------------------------------------- -------------------------------------
---
_max_reasonable_scn_rate 32768
在网上看到一个查SCN 增长速度的脚本,挺有用的


2013年,我的一个客户突然爆发SCN HEAD ROOM故障,导致大量应用受到影响,为了尽快在数百套数据库中排查出问题,我和海军连夜写了两个用于检查kcmgas 的脚本,9i 采集了statspack 就可以使用。10g,11g 基于awr kcmgas_9i.sql。然后让全省十多个地市和省公司的dba分头排查,耗时70多个小时,终于找到了源头,一台地市公司的某个业务员在WINDOWS上建的一个统计库,这个库要从好多生产库中通过DBLINK抽取数据,然后自己计算。最恐怖的是这套数据库是在这个业务人员的个人电脑上装的,一下班,电脑关机,啥事没有。第二天这哥们一开机,我们忙活一天的成果化为乌有。



