




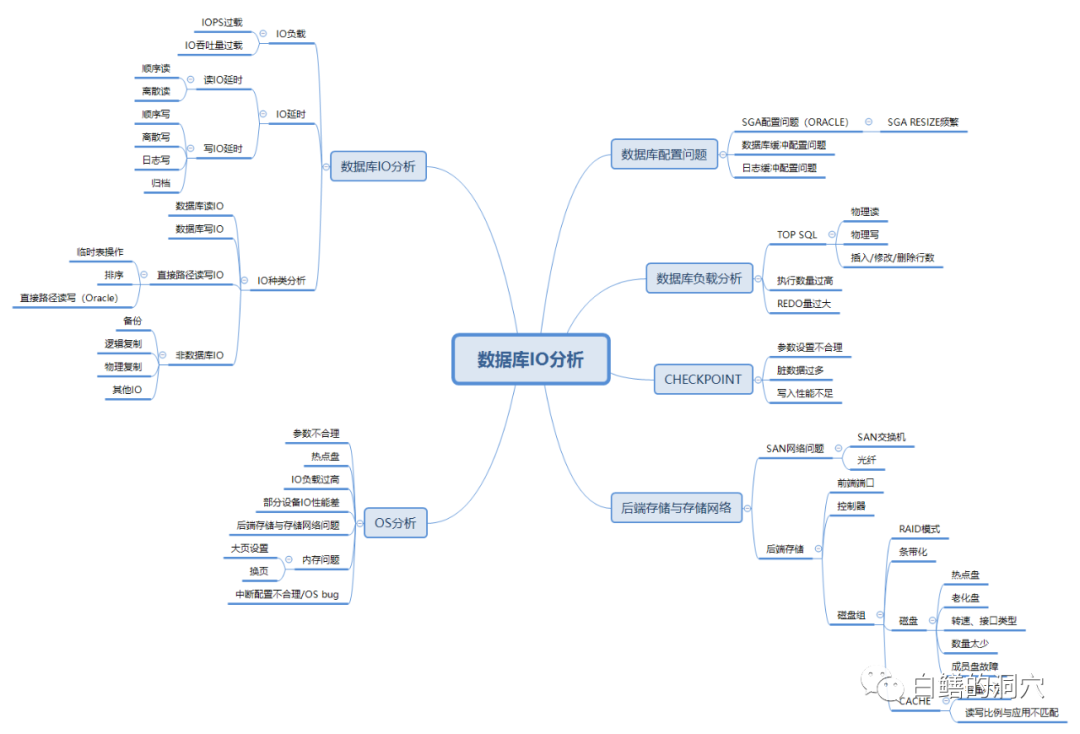
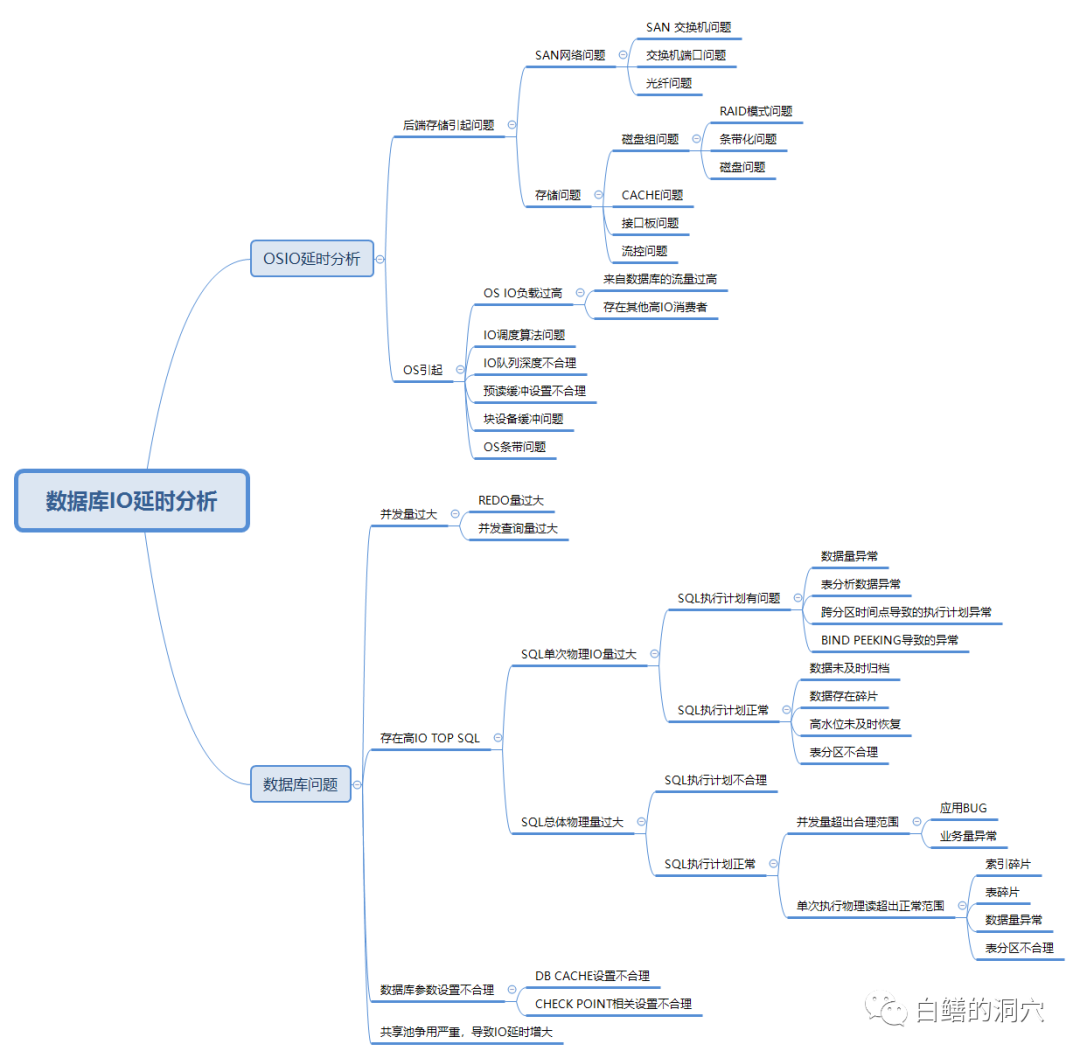
以存储系统为例,第一张图中列出了存储IO分析的几个主要方面。比如SAN网络,一般来说目前SAN交换机与接口的端口吞吐量已经不会称为瓶颈了,SAN交换机端口丢包或者光纤存在质量问题可能是SAN网络出问题的多发地段。老白不止一次遇到类似的问题,SAN交换机端口丢包导致多路径切换从而引起数据库严重IO性能故障的问题是十分多发的。因为使用了劣质光纤导致IO性能问题也遇到过几次。还有就是光纤走线随意,被碰松了接口或者弯折过大导致IO性能问题的事情也是遇到过几次的。
存储上的另外一个容易被忽视的问题是前端接口板负载过高,这些很可能都是和系统集成与运维人员的随意性配置导致的。老白在2016年做一个系统的优化的时候甚至遇到过客户买了一台有16个前端端口的高端存储,上面接了90多套系统,其中有60多套都被配置在1号、2号端口上,而有8个端口上居然没有配置一台服务器。而这个一号端口每天业务上来后的CPU就达到100%了,挂在这个端口上的所有系统的IO延时都是偏高的。
CACHE的问题也是容易被忽视的,CACHE的命中率一般都会在60-70%这个范围,低于60%就说明CACHE命中率偏低了。如果CACHE命中率长期过低,那么对存储的性能影响还是很大的。
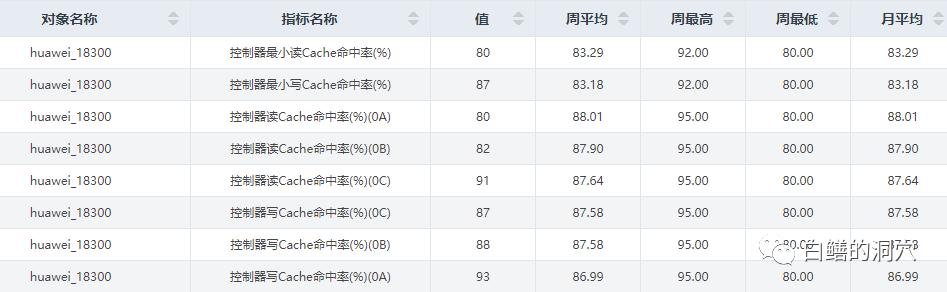
对于存储的控制器CACHE的命中率需要进行全面的监控,除了关注每个控制器的CACHE命中率之外,还要关注各个控制器之间的命中率的差异,以及最小命中率指标。
CACHE除了要关注命中率问题外,对于一些CACHE较小的低端存储,还要十分关注读写CACHE的分配比例是否和你的应用系统的读写特性相吻合。一般缺省的配置是大多数CAHE被分配为写CACHE,而实际上我们的业务系统大多数IO是读IO,如果这样,CACHE的读写分配比例就是不合适的。2013年老白团队做的一个优化项目中就遇到过类似的问题。
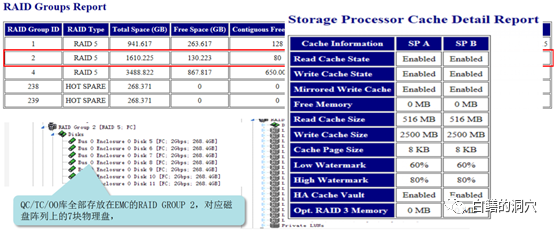
上面的存储有4G的CACHE,其中可用部分为3gb多点,2500M被分配为写缓冲。当时优化组通过分析QC/TC这些应用系统的IO特点,发现数据大多数都是分散写入的,而查询、统计分析才是日常感觉到慢的主要模块,所以说,大量的写缓冲并没有让业务人员感受到系统性能的提升,某个单一写入稍微慢点,也不会影响用户的使用感知。反而是读的性能不佳对用户的使用体验造成了较大的影响。CX3-40的读缓冲仅有516M,在IO分散较广,IO请求较为集中的业务高峰期,读缓冲极有可能被击穿,导致IO总体性能接近于裸盘的性能。在这种情况下,仅仅由5块盘组成的RAID组的性能就十分有限了。于是在优化方案中调整了读写缓冲的比例。
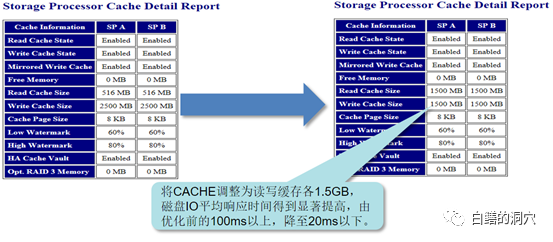
将读缓冲调整为1500M后,数据库IO的平均响应时间得到了较大提升,业务高峰期IO延时从100ms以上降低到20ms以下。
类似数据库IO问题的例子还有很多,其实很多分析如果要深入下去都是十分复杂的,甚至很多以前我们觉得十分得意的案例,随着对技术的深入理解,也会被认为当时的分析结论仅仅是个皮毛。真正潜在深处的问题根因以前并没有触摸到。这是专家分析模式必然会遇到的瓶颈。随着大数据、人工智能的发展,一条新的根因分析的路子也展现在我们的面前。构建完善的指标集,精准的采集动态性能数据,结合专家总结出来的经验以及基于专家经验与案例抽象的“泛知识”体系,利用现在服务器强劲的计算能力,在一个扩大的动态指标集上进行异常检测、关联度分析、相似性分析等分析,从而实现智能化或者更谦虚的说是自动化的分析是完全可行的。
要完成这个工作,类似老白这样的专家经验是必不可少的,这种专家通过多年实践获得的知识作为药引子,构建了知识图谱后,就可以利用这个图谱做各种泛化处理,从而获得比专家经验更为广泛的分析诊断路径,然后在实践中去不断地修正,就可以获得比原始地专家经验更为丰富地知识图谱。知识就可以不断地演进了。
