




前几天发过一篇文章,谈到我们准备做一个PG等待事件分析的工具。这些天有空就会去分析一下PG的等待事件。我也查阅了大量的资料,想学习学习大家是如何分析PG等待事件的,不过发现这方面的资料真的太少了。可能这方面的实践活动并不多,或者说这方面的实践对于PG运维来说帮助不大,这两方面的问题都有可能存在。
不过我想既然PG 9.6开始引入了等待事件的统计,一定是有道理的,从数据库的基本原理上来看,通过等待事件来发现数据库的问题,从基本原理上是没有问题的,只是说我们如何去采样,如何去分析,大家可能还没有比较深入的掌握吧。
比如说LwLock这种类型的等待事件,都是数据库内部为了保护某个数据架构而设置的串行化锁(类似Oracle的LATCH),这些等待事件肯定能够反映出某些内存数据架构上的争用,从而让运维人员发现数据库可能存在的问题。
比如说SInvalReadLock这个LwLock如果出现了较多的等待,那意味着进行共享内存操作时遇到了并发方面的问题,很有可能是shared buffers的访问性能出现了问题。这一点从对PG的源码分析后是可以确认的。不过我在实际压测环境中一直想捕捉这个等待事件,而并没有捕捉到它,这是为什么呢?
我想在我们的应用场景中,可能能够模拟出来的并发场景有限,因此我们要捕获某些等待事件可能也不容易。以我们以往的经验,在Oracle数据库里,如果产生一个持久性的差不多类似的压力,那么从等待事件的统计上能看到比较类似的现象。于是我们模仿Oracle的检查等待事件的方法,写了一个简单的查询语句,在进行benchmark压测的时候检查PG的等待事件。
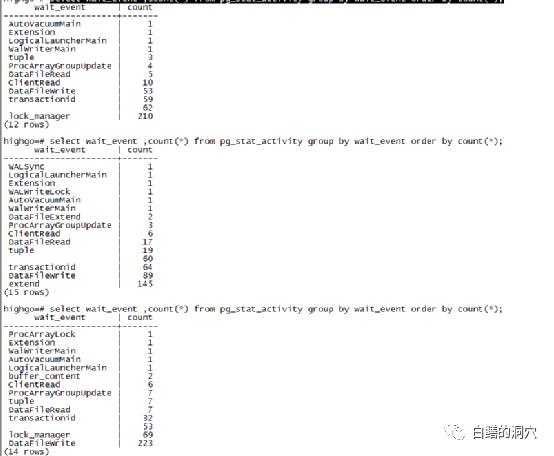
大家可以发现,这几次执行的等待事件变化十分快,虽然压测的负载模型是稳定的,不变的,但是从等待事件上来看,变化相当大。这种情况和我们以往监控Oracle数据库的时候完全不同。以往我们监控Oracle的等待事件,是每3-5分钟采集一次数据,然后进行某个时间段的问题分析的,而且如果这些不够准确的话,还可以通过Oracle的ASH来获得更全面的信息,因此在Oracle数据库中国做等待事件分析,其效果还是相当好的,我们可以通过等待事件分析,发现超过90%的系统问题。但是把分析Oracle等待事件的方法照搬到PG数据库上,就完全没有效果了。
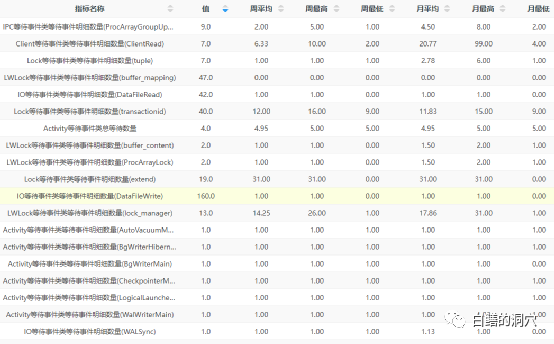
D-SMART的等待事件采集是5分钟一个采样的,看样子采样周期有点长了,2分钟或者3分钟可能更好一些。如果采样周期太短,可能对于并发量很大,负载较高的系统也会产生较大的影响。5分钟的采样,对于大部分数据库监控来说也是够用的,不过对于遇到一些十分古怪的问题,需要进行深度定位的话,肯定是不够的。最佳的方式还是在PG数据库的内核实现类似Oracle ASH的数据采样,在内存中保存一段时间,并定期写入某张物理表,供后续分析使用。
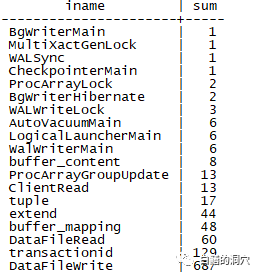
利用我们每隔5分钟一次的采样数据,对等待事件进行统计的情况,我们做了一个排序。发现最多的是DataFileWrite,其次是transactionid,再后面是DatafileRead和buffer_mapping。DatafileWrite是等待想relation文件写入,DatafileRead是从relation文件读入。Transactionid是等待一个事务结束。Buffer_mapping是等待将数据块与缓冲池中的缓冲区。这些都是和Benchmark测试关联比较紧密的。Extend是等待relation文件扩展结束。这个等待居然比tuple还高,tuple是等待获取元组锁。
从上面的情况看,如果在某个时间段内,负载相对式稳定的,哪怕采集的粒度较粗,还是能从这段时间的统计数据看出一些蛛丝马迹来。不过粗粒度的数据,要用在十分细微的问题分析上发挥作用,还是不够的。解决方案还是那个,把类似ASH的等待事件采集功能合并到PG的内核中去。



