这是一个2014年的案例了,客户的系统是Oracle 11.2.0.3,操作系统是AIX 6.1,服务器是IBM P740。当时客户有几个RAC系统中的某个节点或者多个节点会突然变慢,甚至严重时会出现宕机现象。在MOS上也开了SR,但是好像并没有找到问题的根源在哪。老白接手这个案例后,首先要了SR的信息。从中可以看出宕机时的ALERT LOG: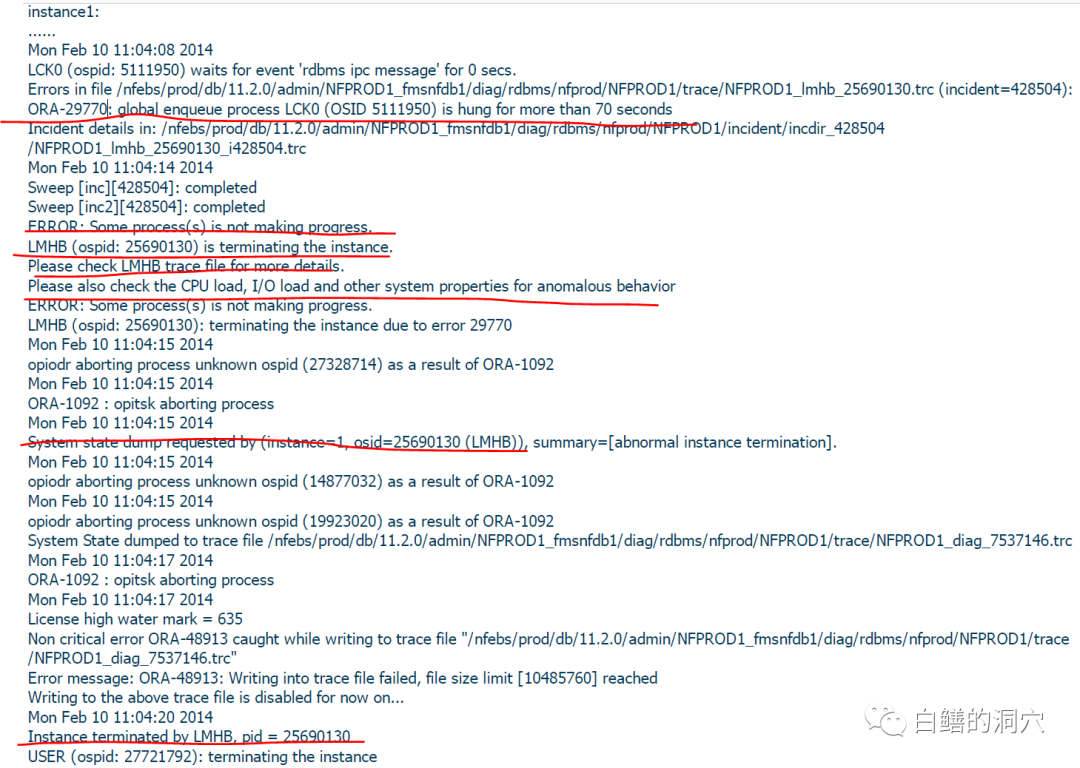
从上面的日志可以看出LCK0等待全局锁,HANG了70秒,一些进程出现了Hang住的现象。需要检查LMHB trace获得更详细的信息。最后LMHB终结了实例。
在LCK0里出现了大佬的ROW CACHE CLEANUP,LATCH SHARED POOL的等待。Oracle OSS的专家经过分析也发现了共享池方面的等待,认为LMHB在清理共享池对象时遇到了问题,和Bug 17599340 - "LCK0 TAKES LONG TIME FOR ROW CACHE CLEANUP AND CONNECTING DB HANGS"有些相似。于是建议用户做如下操作:设置_lm_rcvr_hang_kill=false。客户认为这个BUG和本案例的相似度不很高,拒绝了OSS的建议,于是让老白协助分析这个问题。自从那次宕机后后续这个系统虽然没有再次宕过,不过有三个类似系统中的两个还是经常会出现LCK0超时的问题,同时系统有时候也会在负载不是很高的情况下突然变慢,十几分钟后可能就恢复了。老白分析了这些资料后,首先把问题放到了共享池方面的等待上,根据经验判断,LCK0的问题有可能和共享池的性能有关,SGA RESIZE是第一怀疑对象。于是让客户采集下V$SGA_RESIZE_OPS的数据。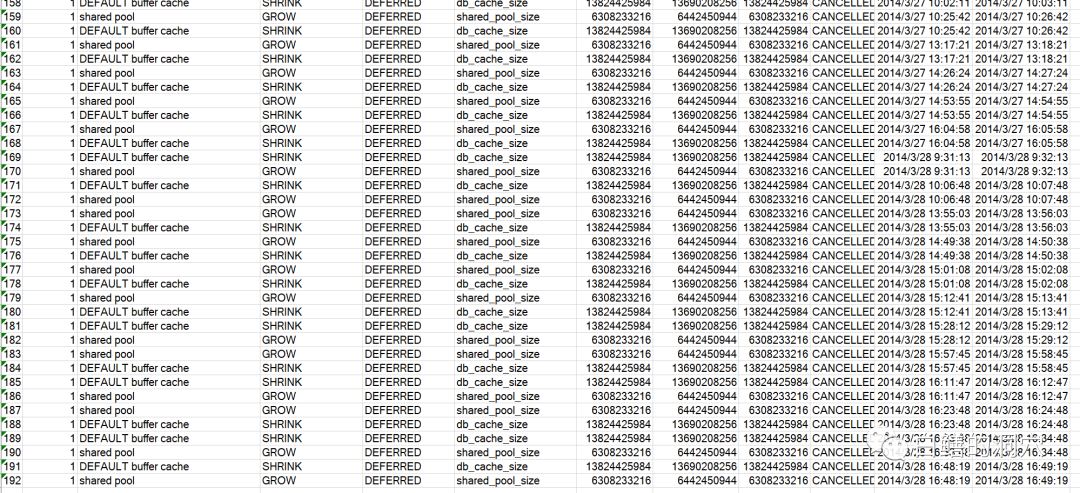
果然,经常有问题的两个数据库都经常出现共享池与DB CACHE之间的RESIZE操作。而且经常是DEFFERED的,有的操作完成需要一分钟才完成。下面是另外一个经常有问题的数据库的数据: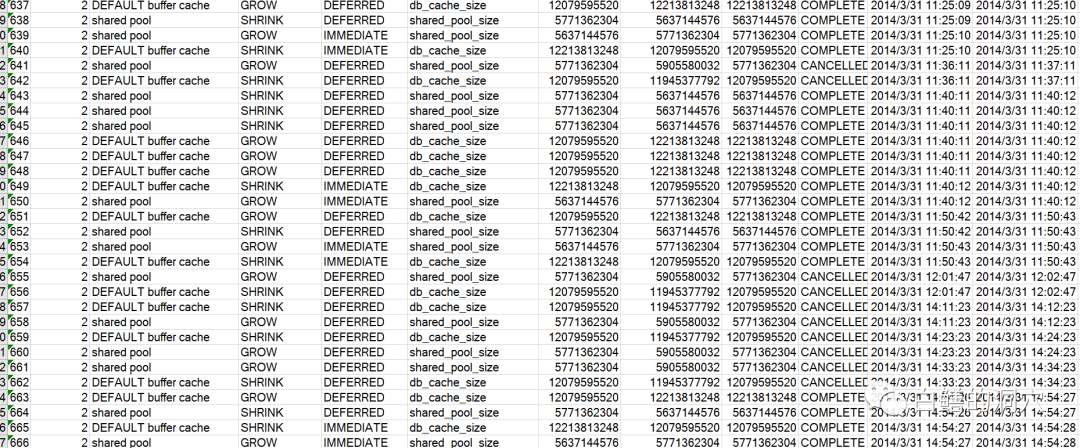
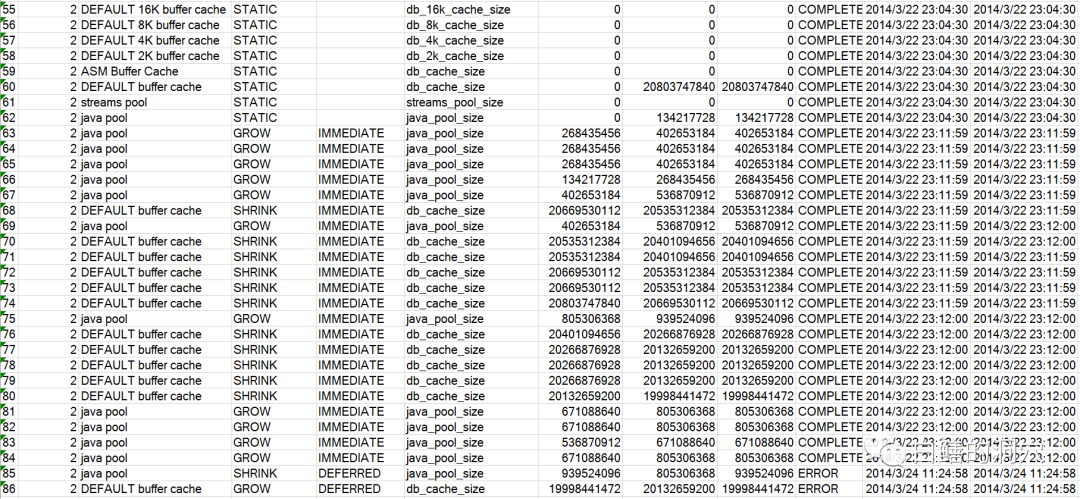
看样子,问题确实和SGA RESIZE有关,于是我让客户采集了共享池的一些信息: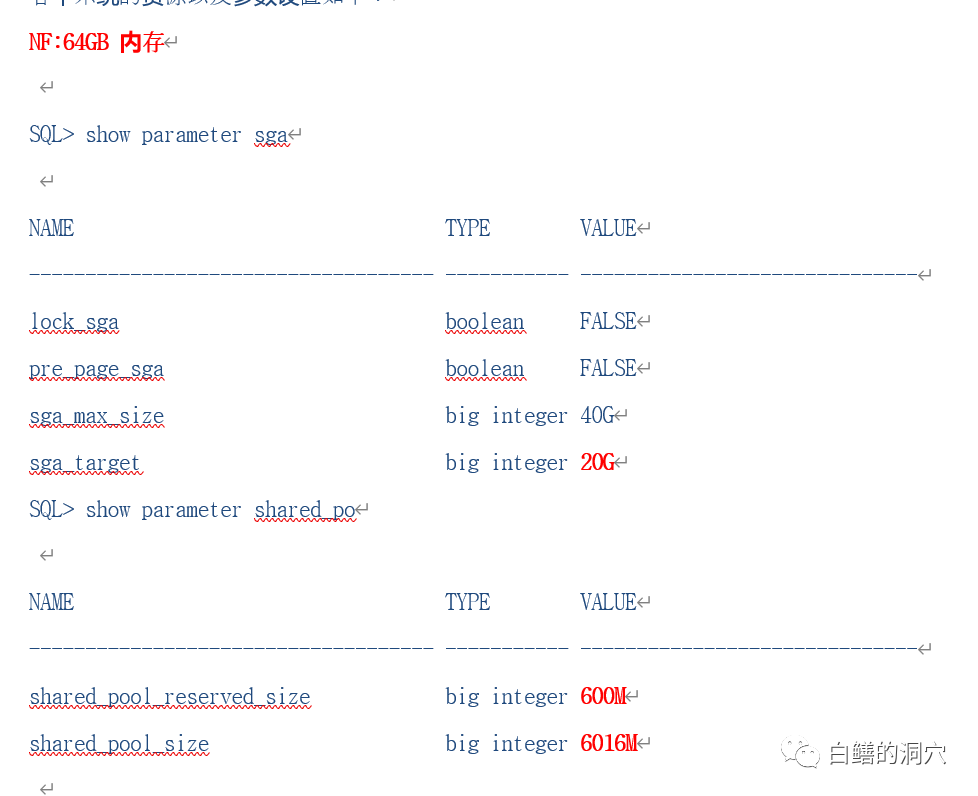


三套系统是一模一样的,由3个业务量类似的子公司在使用,按理说要出问题三个都应该出问题才是,为什么唯独PJ不出问题呢?_enable_shared_pool_durations 这个参数引起了我的注意。这个参数的目的是减少SUB HEAP,让共享池出现碎片的可能性降低。这种情况难道是和共享池碎片有关?
于是我让用户检查了共享池的情况:
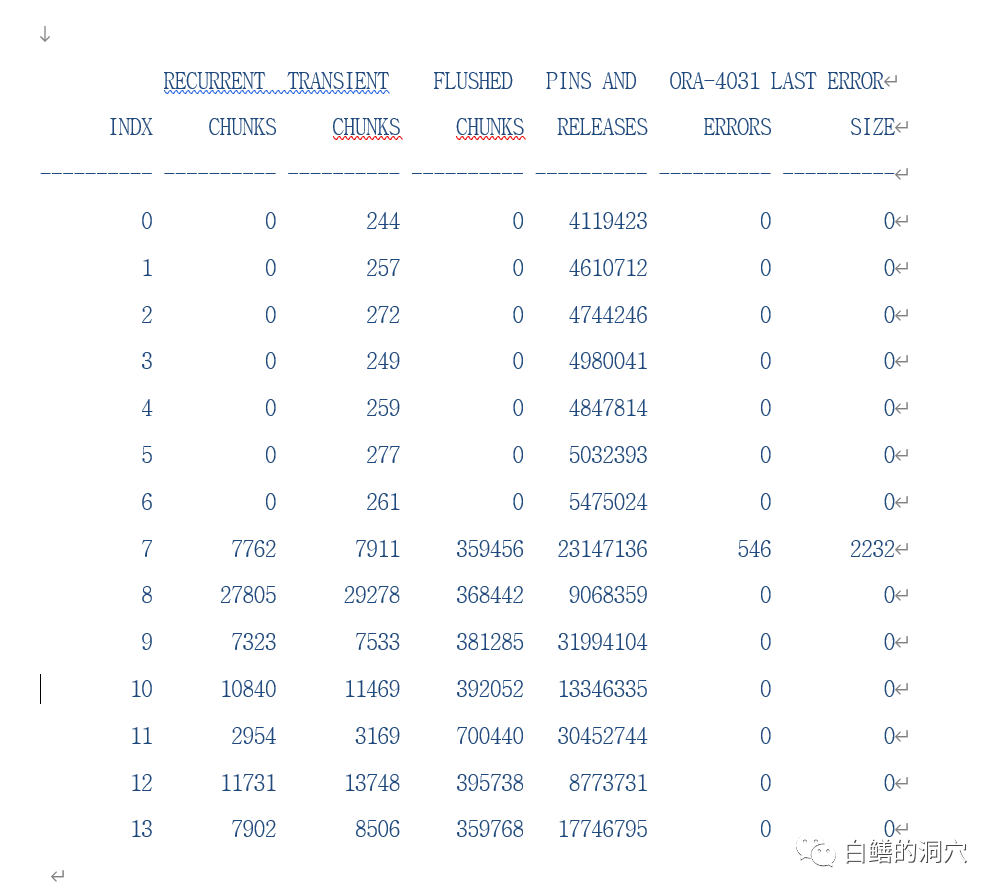
这个共享池被分为14个SUB POOL,其中7号SUB POOL经常出现ORA-4031。从Transient和FLUSHED的数据看,共享池的分配与回收果冻还是很频繁的。不过0-6号池的活动明显偏少。
至此,这个问题已经十分清晰了,因为应用负载变化的原因。这个系统的共享池活动较为频繁,SGA中DB CACHE与SHARED POOL中间经常RESIZE,以适应应用负载的变化。比如上午10点左右的时候并发的小任务突然变多,于是共享池不够用了,于是需要扩大,有时候后台跑批又启动了,DB CACHE又需要扩大了。于是这么来回一折腾,共享池方面的等待就加大了。LOCK0在清理共享池对象时候经常会被HANG住,导致集群GES的性能出现问题。
而当前系统的SGA_MAX_SIZE设置的比较大,但是SGA_TARGET设置偏小。通过简单的加大SGA_TARGET的大小,同时加大SHARED_POOL_SIZE参数,就可以比较有效的改善现在的现状。如果还有问题,可以尝试在有问题的两个数据库中也设置_enable_shared_pool_durations 或者设置_kghdsidx_count 来减少共享池SUB POOL的数量,从而缓解共享池碎片问题。
客户接受了我的建议,通过加大有问题的两个数据库的SGA_TARGET和SHARED_POOL_SIZE设置来尝试接解决这个问题。修改参数后,系统立马恢复正常。LCK0超时再也没有发生,系统也不会出现偶尔卡顿现象了。





