





熟悉ORACLE的同学可能都知道列的直方图的概念: 简单地说就是记录了列中数值的分布情况的信息 。
ORACLE 一般常见的直方图有3种: frequency (高频率统计), height balanced(高度均衡直方图), hybrid(混合直方图)
ORACLE 11G 的 ACS 特性,就是直方图为基础信息来实现的执行计划的自由切换。
直方图的信息可以作为统计信息重要的一部分为数据库的 optimizer 生成更好的执行计划 提供了有力的支持。
MYSQL 大叔 是从8.0版本开始的(官方版本8.0.3),引入的列的直方图的信息, 从而来帮助优化器来选择相对更好的执行计划:
mysql的直方图目前有2种形式:
* singleton * equi-height复制
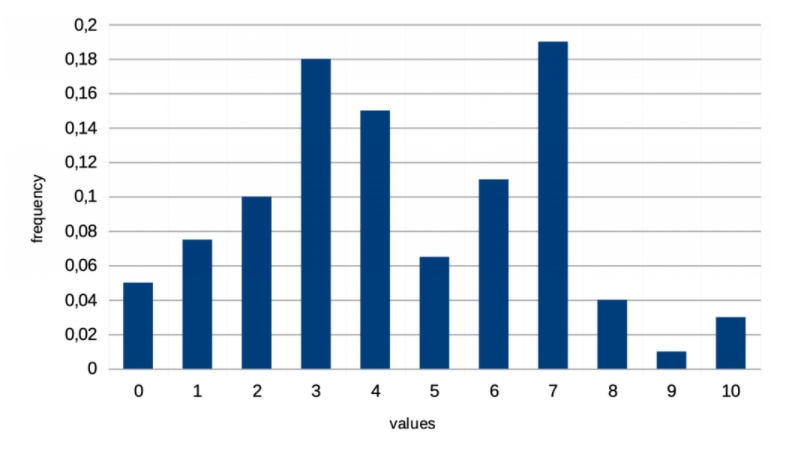
Singleton:
特点是每个值一个bucket,
每个bucket 保存的信息为: 列的值和该值出现的频率
使用场景为:等值查询和范围查询。
示例图:
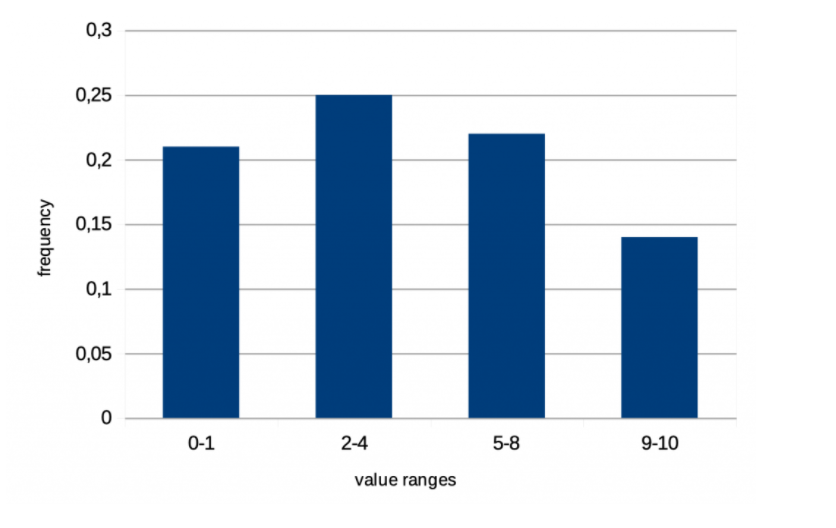
Equi-height:
特点是每个桶里面会保存多个列的值
每个bucket 保存的信息为: 桶中列的最大值和最小值,累计出现该值的频率, NDV (number of distinct value)等信息
使用场景为:范围查询。
示例图:
上面都是一些纯理论上的灌输, 那么我们在实际的数据库表中,什么样的列需要收集直方图的信息呢?
答案大家都知道: 那就是数据分布不均匀的列(skewed & unevent column ),或者从优化器的角度说是 cardinality 小的列。
说了这么多,大表哥来亲自实操感受一下:
大表哥之前做过美丽国的开发项目是关于幼儿园的考勤系统的,美丽国的孩子们还是挺幸福的。。。。
里面有一张核心的表叫考勤表: t_trx_attendance 里面有关于小朋友上学和下学的时间字段: attend_start_time 和attend_end_time.
大家按照常识都知道 一般孩子们的上学时间都是 集中在 7:00 AM -09:00 AM, 放学都是集中在 05:00 PM- 07:00 PM.
当然也会存在 上学迟到,早退的现象。所以在时间字段上 attend_start_time 和attend_end_time 存在数据的倾斜。
下面我们简单的创建一下这个表:
mysql> create table t_trx_attendance (
-> id int not null primary key,
-> name varchar(80) not null,
-> attend_start_time datetime ,
-> attend_end_time datetime
-> );
Query OK, 0 rows affected (0.01 sec)
复制我们写一个脚本load 进去1万条的常规的数据 时间都是 入学: 2022-01-01 08:00:00 放学 :2022-01-01 18:00:00
load_data.sh
for i in {1..10000} do /opt/mysql/product/percona8.0/bin/mysql --login-path=root3021 -e "insert into testdb.t_trx_attendance(id,name,attend_start_time,attend_end_time) values($i,'小朋友$i','2022-01-01 08:00:00','2022-01-01 18:00:00');" done复制
我们查看数据:
mysql> select count(1) from t_trx_attendance;
+----------+
| count(1) |
+----------+
| 10000 |
+----------+
1 row in set (0.00 sec)
复制这时候有个 叫 狗蛋儿的小朋友 上学 迟到了 早上 11点来的 刚睡醒。
我们手动插入 狗蛋儿同学的这条记录:
mysql> insert into t_trx_attendance values (10001,'狗蛋儿','2022-01-01 11:00:00','2022-01-01 18:00:00');
Query OK, 1 row affected (0.01 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
复制这个时候 校长要查一下 : 今天上学迟到的学生 早上10点之后到校的。
mysql> explain select * from t_trx_attendance where attend_start_time > '2022-01-01 10:00:00';
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t_trx_attendance | NULL | ALL | NULL | NULL | NULL | NULL | 9977 | 33.33 | Using where |
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
复制这个时候我们可以看到优化器给出的信息里面 数据过滤比例是 33.33% .
狗蛋儿同学一个人就把mysql 大叔的优化器搞得凌乱了…
我们尝试收集一下表的统计信息:
mysql> analyze table t_trx_attendance;
+-------------------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-------------------------+---------+----------+----------+
| testdb.t_trx_attendance | analyze | status | OK |
+-------------------------+---------+----------+----------+
1 row in set (0.01 sec)
mysql> explain select * from t_trx_attendance where attend_start_time > '2022-01-01 10:00:00';
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t_trx_attendance | NULL | ALL | NULL | NULL | NULL | NULL | 9976 | 33.33 | Using where |
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
复制执行计划里面的信息依然是凌乱的。。。
这个时候我们收集一下列的统计信息:
analyze table t_trx_attendance UPDATE HISTOGRAM ON attend_start_time WITH 8 BUCKETS;
这个时候MYSQL大叔的优化器得到了正确的统计信息。 数据过滤率是 0.01%
这个数值和实际的情况是一致的 狗蛋儿是那些孩子们的 万分之一。
mysql> analyze table t_trx_attendance UPDATE HISTOGRAM ON attend_start_time WITH 8 BUCKETS;
+-------------------------+-----------+----------+--------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+-------------------------+-----------+----------+--------------------------------------------------------------+
| testdb.t_trx_attendance | histogram | status | Histogram statistics created for column 'attend_start_time'. |
+-------------------------+-----------+----------+--------------------------------------------------------------+
1 row in set (0.01 sec)
mysql> explain select * from t_trx_attendance where attend_start_time > '2022-01-01 10:00:00';
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t_trx_attendance | NULL | ALL | NULL | NULL | NULL | NULL | 9976 | 0.01 | Using where |
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
复制我们也可以用 optimizer trace 看一下: “histogram_selectivity”: 0.0001 是符合收集统计信息后的实际情况的。
mysql> SET OPTIMIZER_TRACE = "enabled=on";
Query OK, 0 rows affected (0.00 sec)
mysql> SET OPTIMIZER_TRACE_MAX_MEM_SIZE = 1000000;
Query OK, 0 rows affected (0.00 sec)
mysql> explain select * from t_trx_attendance where attend_start_time > '2022-01-01 10:00:00';
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t_trx_attendance | NULL | ALL | NULL | NULL | NULL | NULL | 9976 | 0.01 | Using where |
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> SELECT JSON_EXTRACT(TRACE, "$**.filtering_effect") FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
+---------------------------------------------------------------------------------------------------------------------------------+
| JSON_EXTRACT(TRACE, "$**.filtering_effect") |
+---------------------------------------------------------------------------------------------------------------------------------+
| [[{"condition": "(`t_trx_attendance`.`attend_start_time` > TIMESTAMP'2022-01-01 10:00:00')", "histogram_selectivity": 0.0001}]] |
+---------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
复制关于收集和删除列的统计信息语法如下:
ANALYZE TABLE tbl_name UPDATE HISTOGRAM ON col_name [, col_name] WITH N BUCKETS;
ANALYZE TABLE tbl_name DROP HISTOGRAM ON col_name [, col_name];
复制最后大表哥还要分享几个关于收集列的直方图统计信息的tips:
1) 从业务的角度,考虑收集数据有倾斜的列,(选择率高的,唯一(近似唯一)键值的列,统统不需要收集)
2) N 是 指定 BUCKETS 数量的范围是 1-1024, 默认值是100
ANALYZE TABLE tbl_name UPDATE HISTOGRAM ON col_name [, col_name] WITH N BUCKETS;
复制3) 收集大表的时候可以设置内存参数: 以免创建磁盘的临时IO访问
SET histogram_generation_max_mem_size = 1000000;
复制4)列的统计信息是保存在视图 information_schema. column_statistics 中的 histogram 是JSON 格式的
mysql> desc information_schema.column_statistics;
+-------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-----+---------+-------+
| SCHEMA_NAME | varchar(64) | NO | | NULL | |
| TABLE_NAME | varchar(64) | NO | | NULL | |
| COLUMN_NAME | varchar(64) | NO | | NULL | |
| HISTOGRAM | json | NO | | NULL | |
+-------------+-------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
mysql> select * from information_schema.column_statistics where SCHEMA_NAME='testdb' AND TABLE_NAME='t_trx_attendance'\G
*************************** 1. row ***************************
SCHEMA_NAME: testdb
TABLE_NAME: t_trx_attendance
COLUMN_NAME: attend_start_time
HISTOGRAM: {"buckets": [["2022-01-01 08:00:00.000000", 0.9999000099990001], ["2022-01-01 11:00:00.000000", 1.0]], "data-type": "datetime", "null-values": 0.0, "collation-id": 8, "last-updated": "2022-03-02 07:52:02.768589", "sampling-rate": 1.0, "histogram-type": "singleton", "number-of-buckets-specified": 8}
1 row in set (0.00 sec)
复制我们重点观察一下 HISTOGRAM 这个JSON格式列中的内容 :
HISTOGRAM: {
"buckets": [["2022-01-01 08:00:00.000000", 0.9999000099990001], ["2022-01-01 11:00:00.000000", 1.0]], -- 实际创建的2个bucket, [列的值,在桶内占的比例]
"data-type": "datetime", --列的类型
"null-values": 0.0, --空值的数量
"collation-id": 8, -- 桶的最大个数
"last-updated": "2022-03-02 07:52:02.768589", --收集直方图统计信息的时间
"sampling-rate": 1.0, --数据采样比例是100%
"histogram-type": "singleton", -- singleton 类型的直方图
"number-of-buckets-specified": 8 --手动指定的桶的个数
}
1 row in set (0.00 sec)
复制5)如果要确保MYSQL大叔的优化器读取到列的统计信息,必须要打开变量optimizer_switch中的condition_fanout_filter=on (这个值默认是打开的)
mysql> SELECT @@optimizer_switch\G
*************************** 1. row ***************************
@@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on
1 row in set (0.00 sec)
复制评论

 0 点赞
0 点赞 0 点赞
0 点赞



