




「目录」
数据聚合与分组运算
Data Aggregation and Group Operations
10.1 => GroupBy机制
10.2 => 数据聚合
10.3 => apply:拆分 - 应用 - 合并
10.4 => 透视表和交叉表

交叉表crosstab
这一篇是这一章最后一篇笔记了,原书下一章的内容是时间序列,包括日期和时间数据类型,日期的范围,时区处理啥的。再之后好像就没有什么新内容了,最后一章内容是数据分析案例。这么看的话这个数据分析笔记终于要接近尾声了,还记得当初写这个笔记的目的是整理和总结,加深印象,还有精简一下原书的内容,而且笔记整理到公众号上的话,就不怕丢了,而且花了那么长时间整理了一本书也有一种成就感,哈哈。要是忘了哪个地方,搜索关键字就可以出现对应的笔记了,也很方便,肯定比翻书快。这个笔记写完后,想整理一下SQL的笔记,这个很简单,学的时候应该一星期内就能搞定。
上一篇笔记写的是透视表,交叉表是一种用于计算分组频率的特殊透视表。
import numpy as np
import pandas as pd
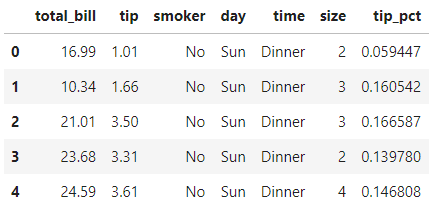
还是之前那个小费的列子:
tips = pd.read_csv(r'.\tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.head()
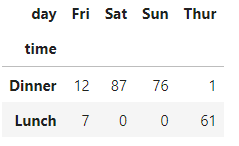
crosstab的前两个参数是行索引index和列索引column,参数可以是Series:
pd.crosstab(tips.time, tips.day)
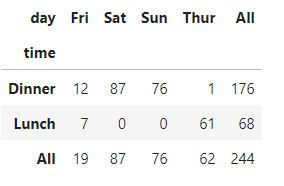
同样可以传入参数margins=True来新增分项总计All:
pd.crosstab(tips.time, tips.day, margins=True)
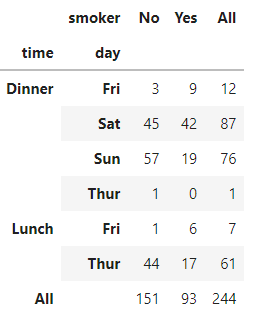
crosstab的前两个参数也可以是数组列表:
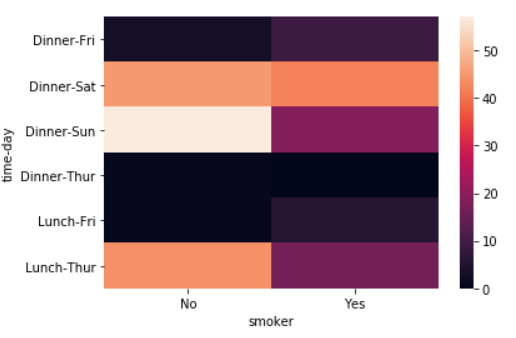
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)
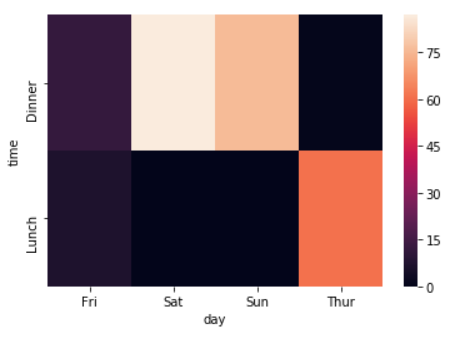
其实上面的交叉表用seaborn的heatmap热力图画出来更直观好看哦
import seaborn as sns
sns.heatmap(pd.crosstab(tips.time, tips.day))
sns.heatmap(pd.crosstab([tips.time, tips.day], tips.smoker))
那我们BYEBYE吧 !
!
往期回顾
Pandas里的透视表


Stay hungry, stay foolish
文章转载自Yuan的学习笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
