




第一章 问题引入分析
在分析客户环境的一条SQL时,发现SQL中访问了不必要的表和数据。造成了性能问题。因此对这里问题进行分析,以避免后续SQL编写过程中的相应问题。
对于关联子查询的SQL写法,通常是为了返回外部查询需要的数据,并与外部查询有一定的关联。当通过子查询编写语句时,需要注意只访问必要的表或视图。也不要做额外的聚合、分组等动作。因为这些动作对主查询SQL并不关心。但相反却可能造成子查询在访问时的性能低效。
数据库版本:ORACLE 11G
问题SQL:
UPDATE T_TMP N
SET N.CHECK_CODE = '2', N.CHECK_INFO = 'XXXX未入库!'
WHERE EXISTS (SELECT 1 FROM T_A B WHERE N.COL1 = B.COL1)
AND EXISTS (SELECT
T.COL_NO,
T.COL_MEI,
T.PROVINCE_AREA,
T.COL_CODE,
T.COLTYPE,
T.VALID_TAG,
T.PRODUCT_ID,
SUM(T.IS_MAINTAIN) IS_MAINTAIN,
SUM(T.MODEL_CODE) MODEL_CODE
FROM (SELECT DENSE_RANK() OVER(PARTITION BY E.COL_MEI ORDER BY E.PROVINCE_AREA DESC) RN,
E.COL_NO,
E.COL_MEI,
E.PROVINCE_AREA,
E.COL_CODE,
E.COLTYPE,
E.VALID_TAG,
E.PRODUCT_ID,
DECODE(F.COL_CODE, '', 0, 1) IS_MAINTAIN,
DECODE(F.RES_SKU_ID, '', 0, 1) MODEL_CODE
FROM (SELECT C.COL_NO,
C.MODEL_CODE,
C.COL_MEI,
C.PROVINCE_AREA,
C.COL_CODE,
D.COLTYPE,
D.VALID_TAG,
D.PRODUCT_ID
FROM (SELECT A.COL_NO COL_NO,
A.RSRV_STR3 MODEL_CODE,
B.COL_MEI,
B.COL_CODE,
B.PROVINCE_AREA
FROM T_TMP A, T_B B
WHERE A.COL_NO = B.COL_MEI(+)
AND A.RECORD_ID = :2) C,
T_D D
WHERE C.COL_CODE = D.COL_CODE(+)) E,
T_F F
WHERE E.COL_CODE = F.COL_CODE(+)
AND E.MODEL_CODE = F.RSRV_STR1(+)) T
WHERE T.RN = 1
AND T.PRODUCT_ID IS NULL
AND T.COL_NO = N.COL_NO
GROUP BY T.COL_NO,
T.COL_MEI,
T.PROVINCE_AREA,
T.COL_CODE,
T.COLTYPE,
T.VALID_TAG,
T.PRODUCT_ID);
分析上述文本,目的是更新目标表。根据条件部分的exists关联子查询,判断需要更新的数据。
执行计划信息如下:
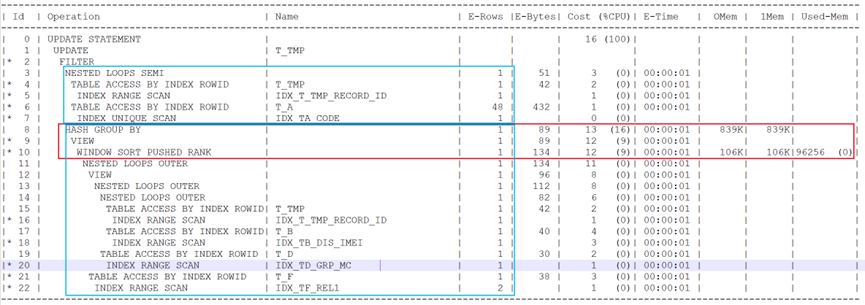
通过执行计划可以看出,在窗口函数和聚合步骤中,消耗较多的内存。
待更新表T_TMP先与较小的T_A表关联后,在将满足条件的结果集传入到较复杂的子查询中,进行后续关联查询。
第二章 执行效率情况
分析SQLHC采集数据:

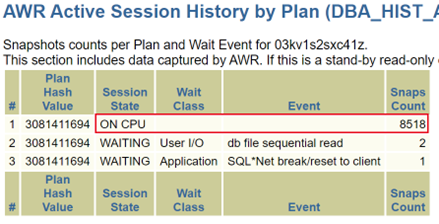
可以看出当前执行效率较低。每次执行20秒左右。主要时间消耗在CPU上面。
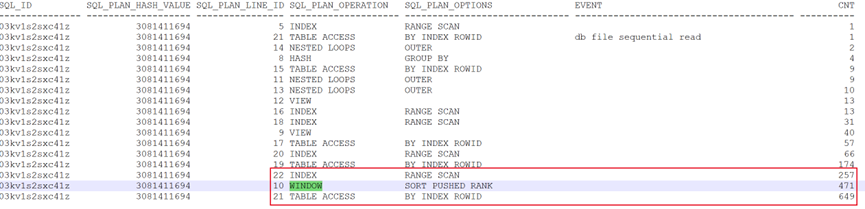
主要耗时发生在计划的第21-22的T_F表的索引访问步骤中。且窗户函数执行也偏慢。
第三章 主要问题分析
首先分析语句结构,待更新表与两个EXISTS关联子查询访问。对于EXISTS关联子查询,只是为了判断是否存在满足关联条件的主表数据。
而本案例中,在子查询中还做了很多额外的不必要动作。如:
1.GROUP BY聚合并求SUM动作;
2.为了获取SUM,还额外访问了T_F表。而该表与主表并没有任何关联条件,仅是为了获取第一步中的SUM求和。但求和在本部分中又是可以去掉的。
因此,上面两部分的查询访问动作,也就都是可以消除的。而根据上面的耗时步骤分析。其中T_F表的索引访问及GROUP BY聚合操作又正好是非常消耗资源的部分。那消除后,正好就省去了大量的执行时间和资源消耗。
因此,去掉原始SQL中的不必要访问动作,并省去多个层次子查询。可以等价的改写为如下写法:
UPDATE T_TMP N
SET N.CHECK_CODE = '2', N.CHECK_INFO = 'XXXX未入库!'
WHERE EXISTS (SELECT 1 FROM T_A B WHERE N.COL1 = B.COL1)
AND EXISTS (SELECT 1
FROM (SELECT DENSE_RANK() OVER(PARTITION BY E.COL_MEI ORDER BY E.PROVINCE_AREA DESC) RN,
A.COL_NO,
B.COL_MEI,
B.PROVINCE_AREA,
D.PRODUCT_ID
FROM T_TMP A, T_B B, T_D D
WHERE A.COL_NO = B.COL_MEI(+)
AND A.RECORD_ID = :2
AND B.COL_CODE = D.COL_CODE(+)) T
WHERE T.RN = 1
AND T.PRODUCT_ID IS NULL
AND T.COL_NO = N.COL_NO);
改写后,保证了子查询中仅访问了必要的查询列及数据。
调整后的执行计划如下:
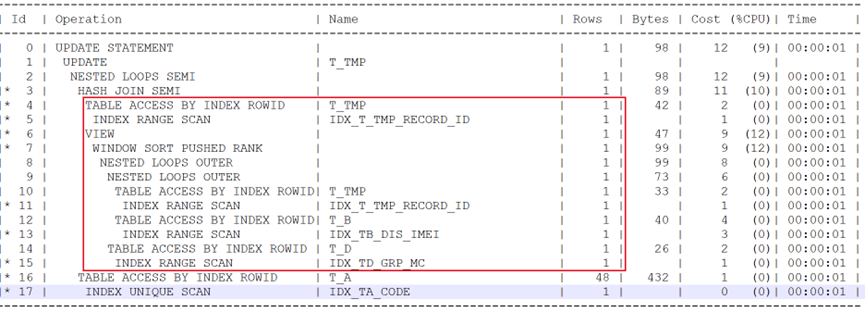
主要区别有如下几部分:
- 去掉了耗时步骤21-22步,对T_F表的访问;
- 去掉了GROUP BY聚合动作;
- 对于下面的子查询部分,直接从FILTER查询变为了HASH半连接,好处是仅会访问一次。避免了多次查询可能出现的性能问题。
基于上述调整:我们预期SQL的执行时间至少会降低2/3以上的执行时间和资源消耗。有效提升了查询效率。
第四章 问题总结
通过上述案例的分析。exist/in 关联子查询,仅是为了返回需要的数据。因此在实际编写SQL的过程中,对于不必要的表查询及动作,能省则省,缩减代码的同时能有效提升查询效率,避免性能问题。
