




关注我们获得更多精彩内容

讲师介绍:李海龙,2012 年加入 Qunar,目前在网站运营中心担任 PostgreSQL DBA 总监。PostgreSQL 中国社区成员,热爱数据库技术, 乐于在公司内外分享使用中的各种经验。

SQL Fundamentals
SQL 全名是结构化查询语言(Structured Query Language),是用于数据库中的标准数据查询语言。传统来讲,SQL 语言分为三个部分:
(1) “数据定义语言”(DDL : Data Definition Language),用于定义 SQL 模式、基本表、视图和索引的创建和撤消操作。
(2)“数据操纵语言”(DML : Data Manipulation Language),数据操纵分为数据查询和数据更新两类。数据更新又分成插入、删除、和修改三种操作。
(3)“数据控制语言”(DCL : Data Control Language),包括对基本表和视图的授权,完整性规则的描述,事务控制等内容。对应的 SQL 语句如下:

还有一类语句,即 BEGIN , COMMIT , SAVEPOINT , ROLLBACK ,这些是基于 ANSI SQL (最新标准为 SQL 2016 )的扩展,属于 Data Transaction Language, 有些资料直接将其归类于 DCL。个人记忆方法:你可以简单粗暴的记忆为:SQL 里就有10个最基本的动词(或者命令),然后分三大类,这样去记忆。
注: 在 Oracle 中 TRUNCATE 属于 DDL, 在 PostgreSQL 中 TRUNCATE 属于 DML。
Optimize Query
发给 DBMS 的所有的 DDL,DML,DCL 的可统称为 Query,俗称 SQL 语句。不是所有的 Query 都可以优化,DCL 基本不存在优化的问题,我们探讨优化的重点是 DML 及 DDL。
注意:
(1)Slow Query 优化, 包括但不限于我们日常实践中优化最多的SELECT语句
(2)Query 优化,不都是单纯的将 query 的运行时间提速, 有时候需要在运行时间和 lock 粒度之间做出权衡。
本人以运维实践的角度出发, 将 Query 优化分为2类:
(1)保证 DML 返回的结果集(select)相同 或 更改的结果集(insert update delete) 相同的情况下,将 query 优化使其运行的更快
(2)保证 DML 或 DDL 操作结果相同的情况下,将 lock 的级别降低, lock 的范围变小,提高 DBMS 的并发度。
本文先简单讲一下 Query 优化的基本原则,然后讲讲 Index 的类型及 Index 的维护,最后谈谈一些常见的可调参数。旨在使广大开发同学和初级 DBA 在做 Query 优化时有章可循。
Some Cases in PostgreSQL
下面分类举几个实例,简单讲一下优化方法。
Case 1 Create Index Directly
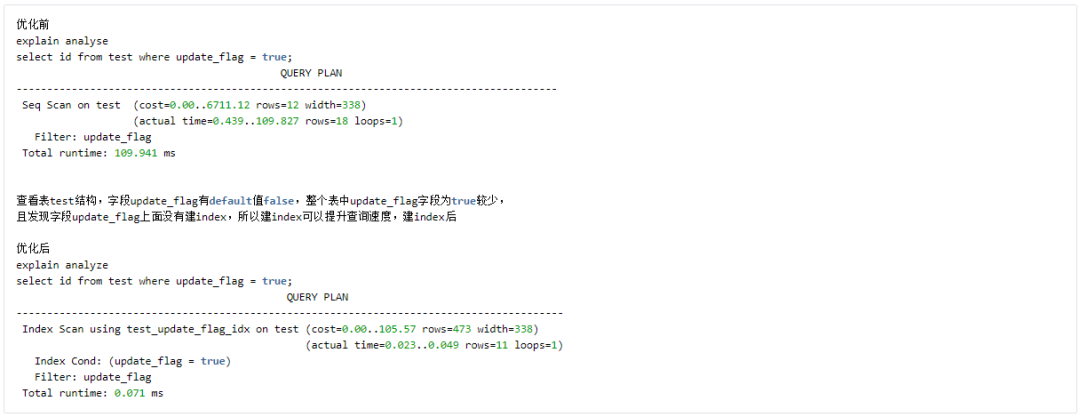
总结: 这种方法是最常用的方法,需要注意一个数据选择比的问题,如果 where 条件是 update_flag = false,那么效果就不会有这么明显,因为如果 update_flag 字段值如果几乎都是 false,那么尽管有 index,其实和 Seq Scan 的时间也没什么差别,或者说差别不大。
Case 2 Change Conditions to Use Index
这类 SQL 就是本来 table 的 column 上有 index,然后 Query 没有用上。
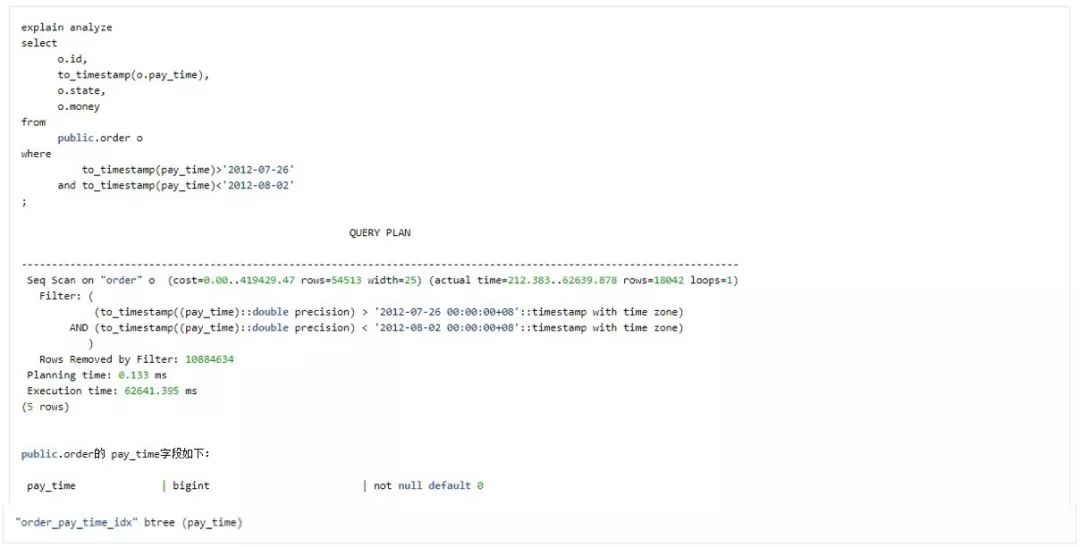
public.order 上在 pay_time 上有 index,且是 bigint 类型,但是使用函数 to_timestamp(pay_time) 转换为 timestamptz 类型后,没有用上这个 index。
那么我们想办法改变 where 条件,使用到 index:
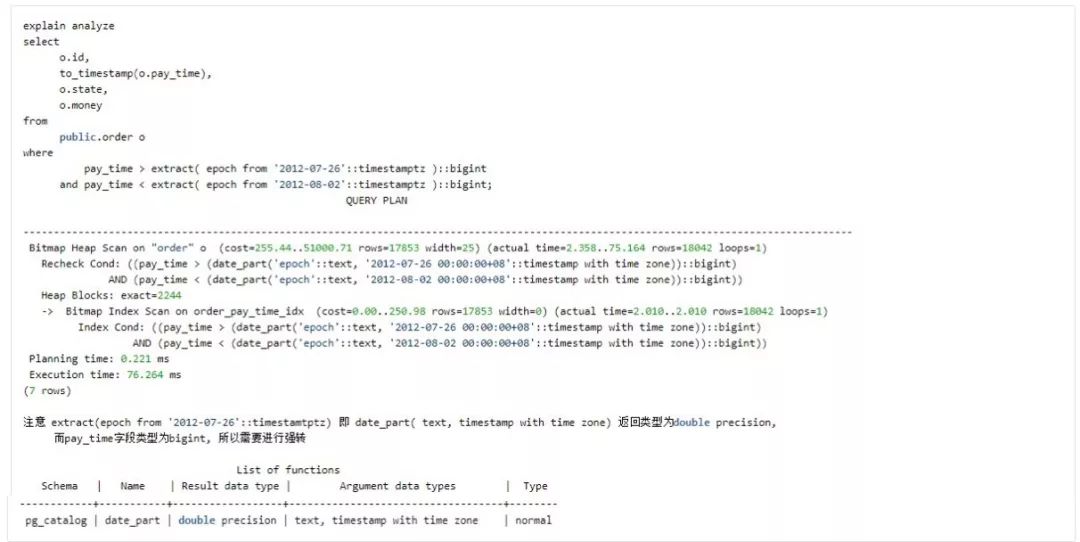
应尽量避免在 where 子句中对字段(索引列)进行运算,这将导致查询规划器放弃使用 index。如
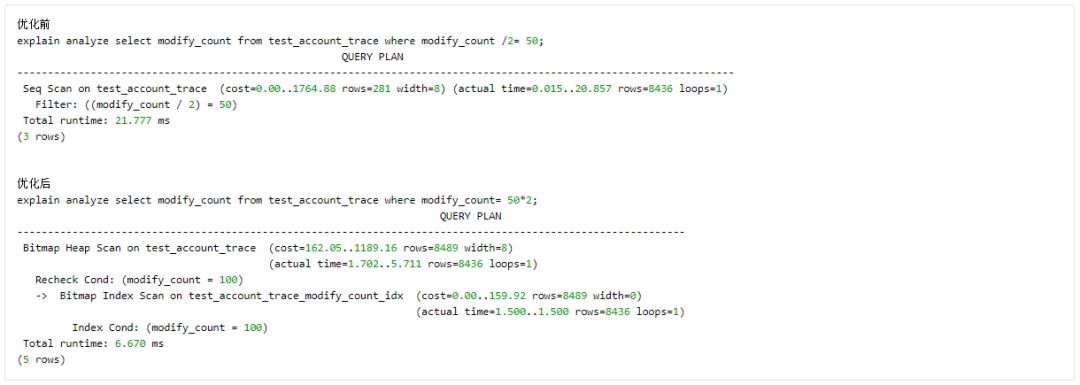
应尽量避免在 where 子句中对字段类型进行强转,进而导致查询规划器放弃使用 index。如

应尽量避免在 where 子句中对字段与不同类型的常量(或字段)进行比较, 将导致隐式类型转换,进而导致查询规划器放弃使用 index。如
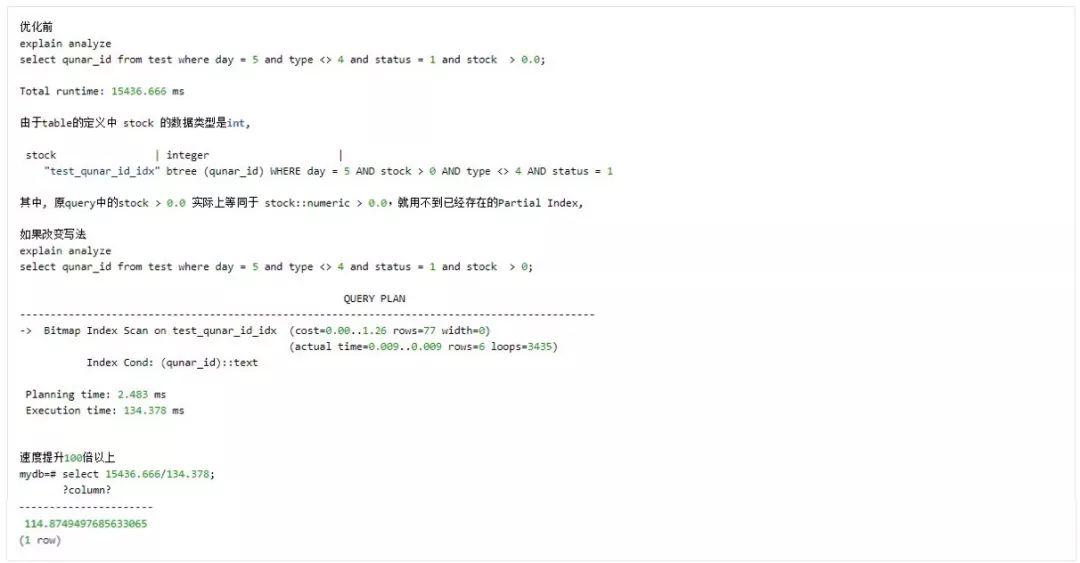
总结:我们要想办法,灵活改变 where 中的查询条件,使用上 index,以加快我们的查询。
Case 3 Removal Unecessary Sub-query and Outer Join
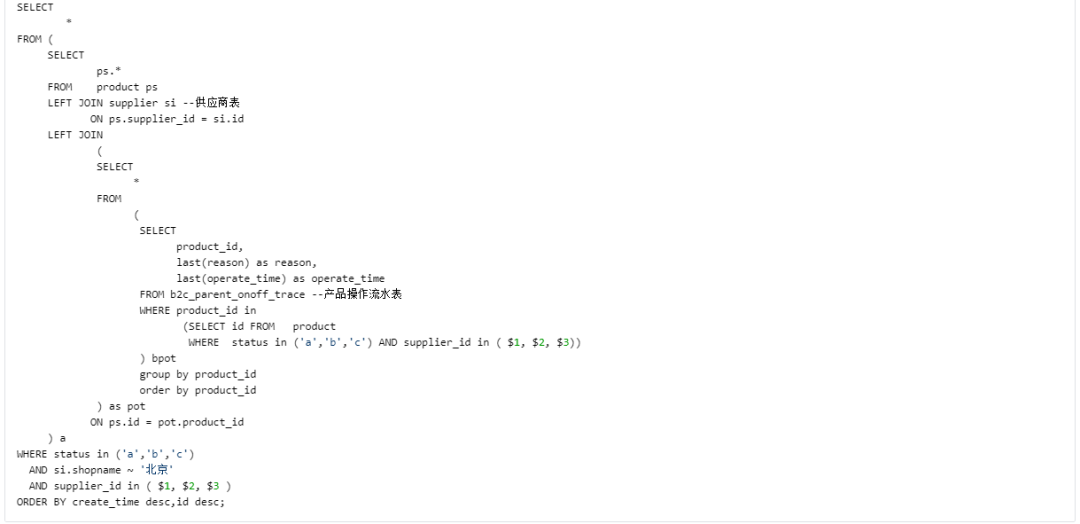

上面的大长 SQL 是一个前端页面的 SQL,原运行时间是 3000ms,优化后 30ms,极大提升了页面的响应时间。
总结: 不影响得到正确的结果集前提下,结合业务逻辑, 少用 Outer Join;减少不必要的 Sub-query 层级数。
Case 4 Eliminating redundant columns
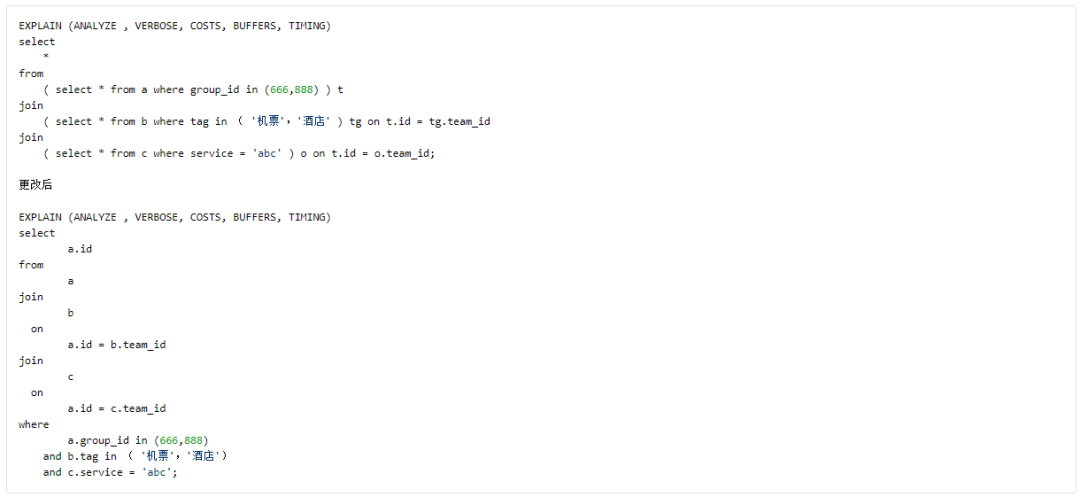
总结: 单纯看 Query 运行时间,可能优化效果并不十分明显,但如果考虑到计算中间结果所需的内存和磁盘空间及网络传输所耗带宽,SELECT * 应坚决避免。
Case 5 Indexes on Expressions
Indexes on Expressions 例1:
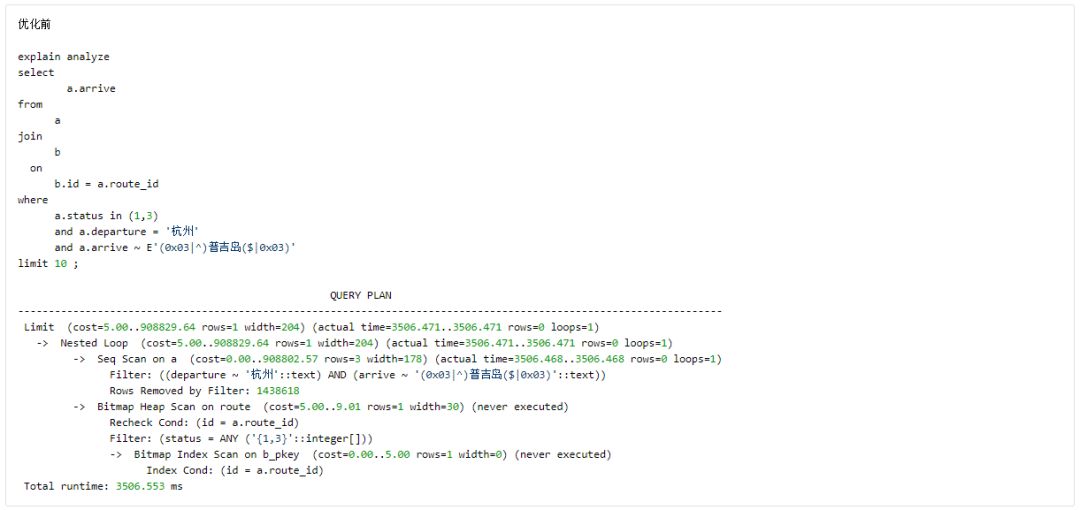

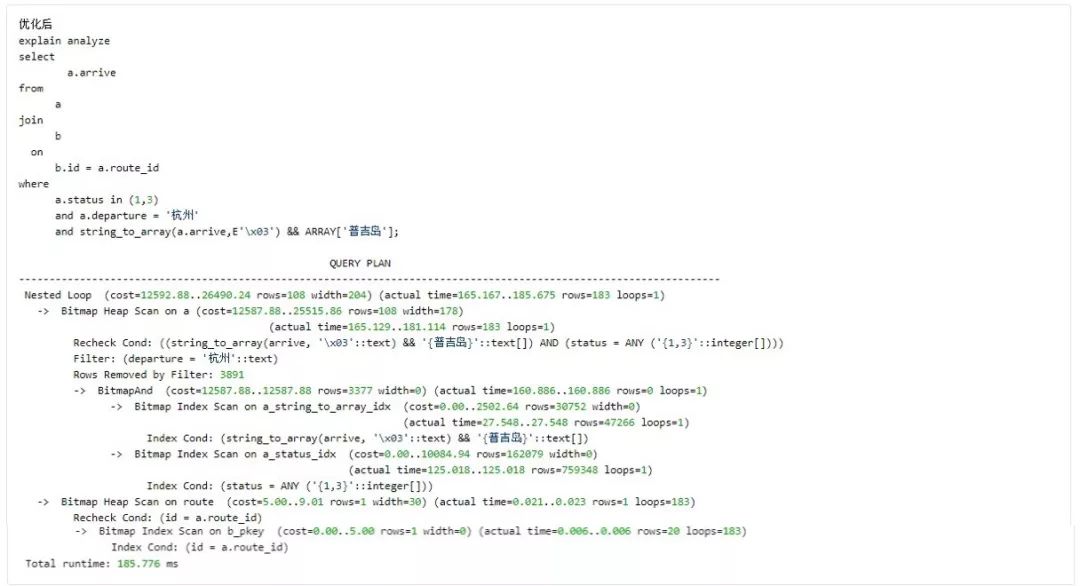
Indexes on Expressions 例2:
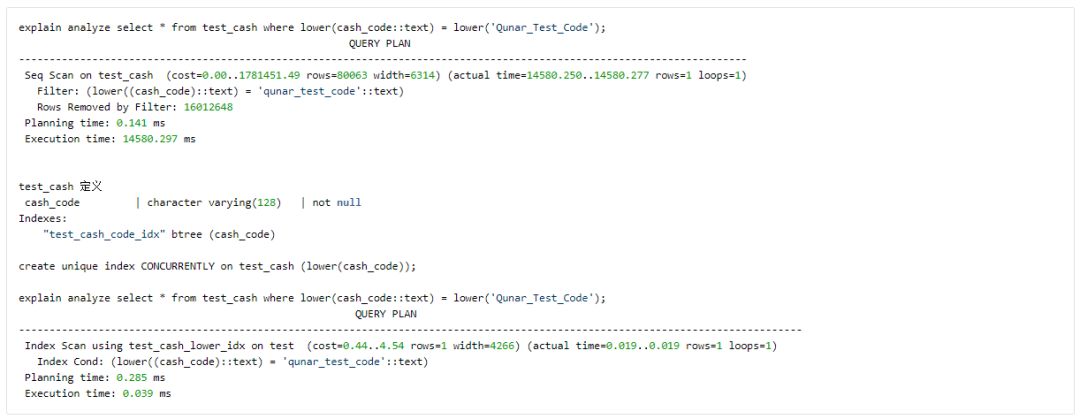
Indexes on Expressions 例3:
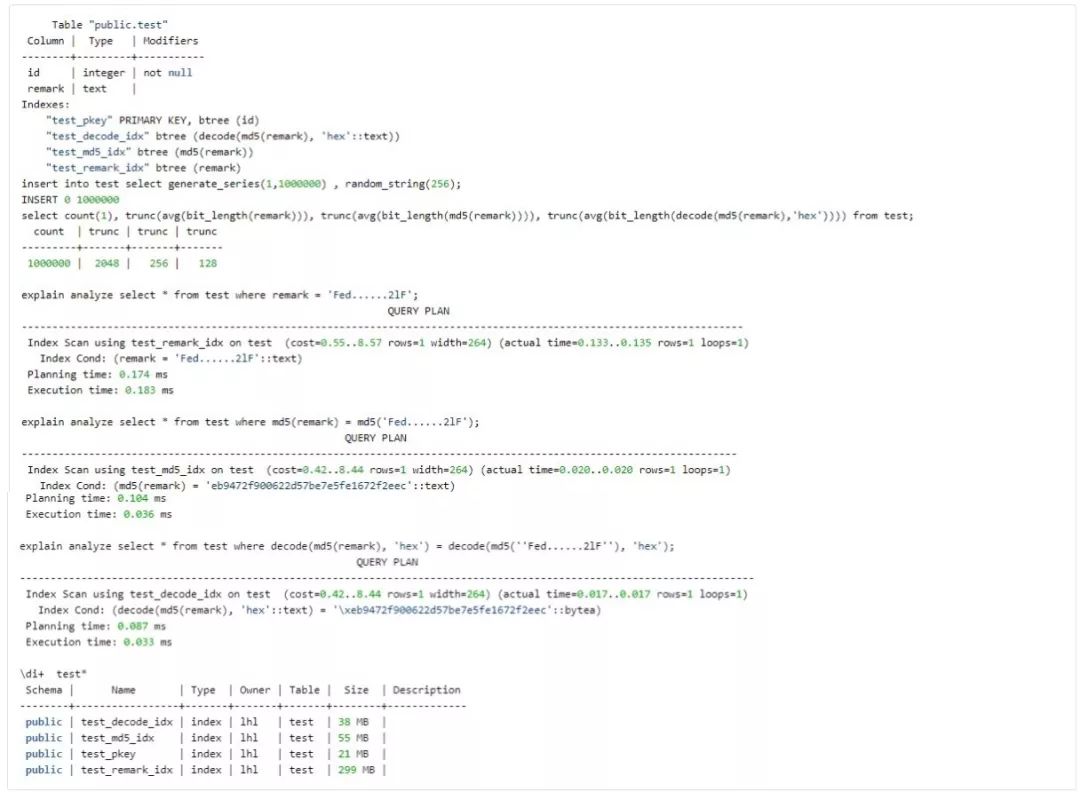
总结: 善于观察字段数据类型的操作符及函数,结合where condition,研究使用表达式index。
Case 6 Partial Indexes
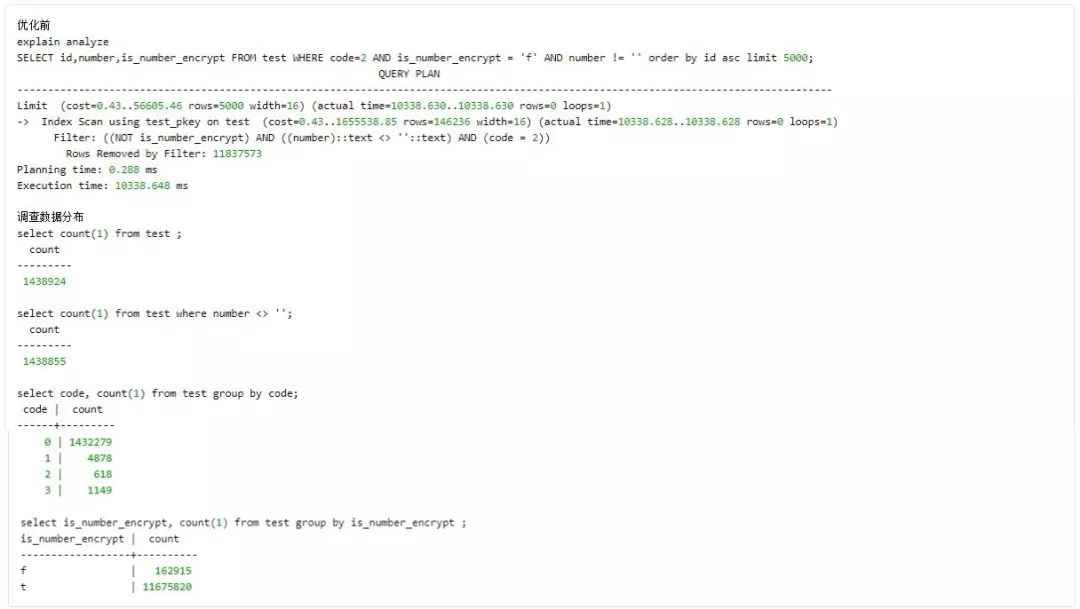
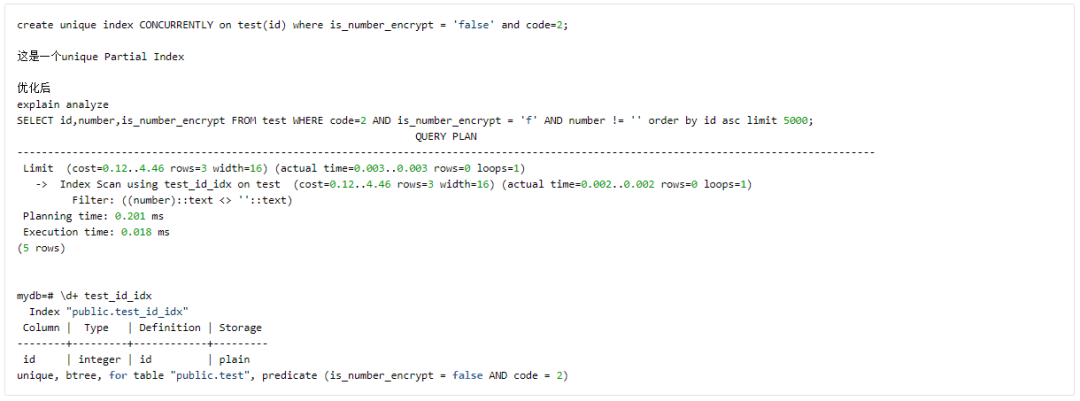
注意: 不是所有的条件比较多的 query 都适合建 Partial Indexes,主要适合场景为: where 中的条件固定,且选择比好的情况下。
Case 7 Decompose DDL
很多 DDL 操作, 需要对 table 加 ACCESS EXCLUSIVE 这种高粒度的 Table-level Locks,所以权衡利弊,可以将其分解执行,以低粒度的 lock 及稍长的执行时间替换高粒度 lock。
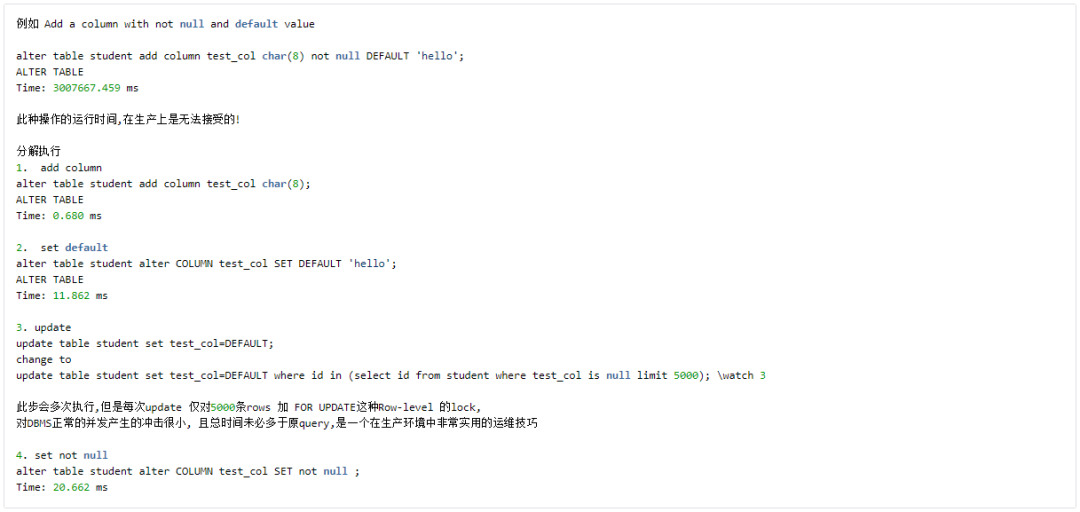
PostgreSQL 11 的 New Feature 中,一个极为实用的特性就是 avoid a table rewrite for ALTER TABLE ... ADD COLUMN with a non-null column default,无论多大的表,都可以秒级搞定。
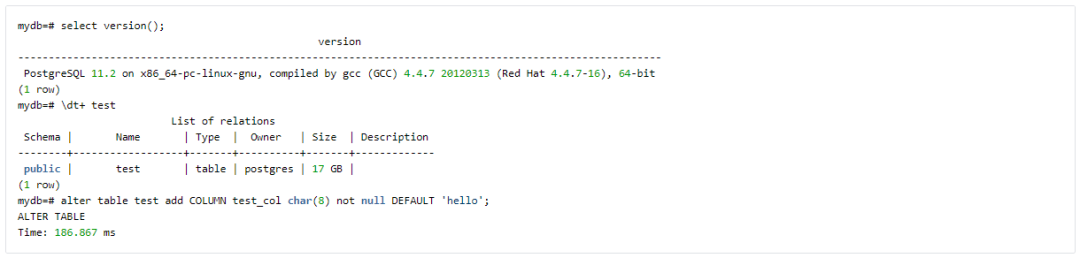
Case 8 Comprehensive optimization
建 Multicolumn Indexes 和 Partial Indexes ,且分解执行
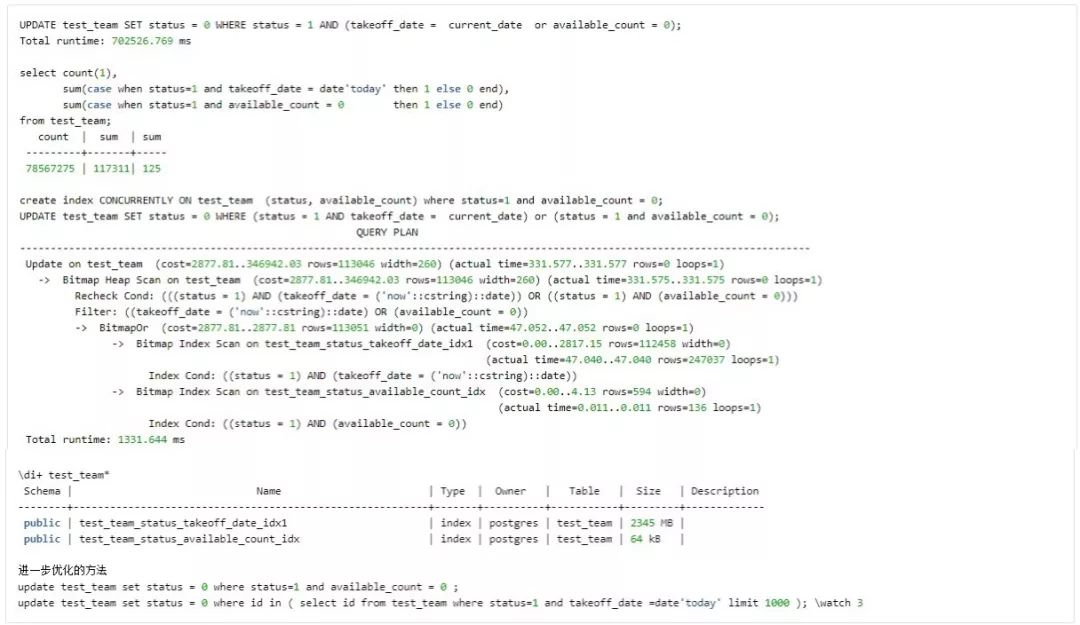
Case 9 Use CTE
CTE(Common Table Expressions),即通用表表达式,在 Slow query 中应用比较多的是 1 个较长 Query 中多次使用的同一 subquery 场景可以单拿出来先做 CTE,使 Query 提速且使 Query 更简洁,但此处谈及的是只使用 1 次的特殊 case。
例1:

总结: in 后面的 subquery 里的返回字段存在很大比例的重复值可以尝试 CTE。
例2:
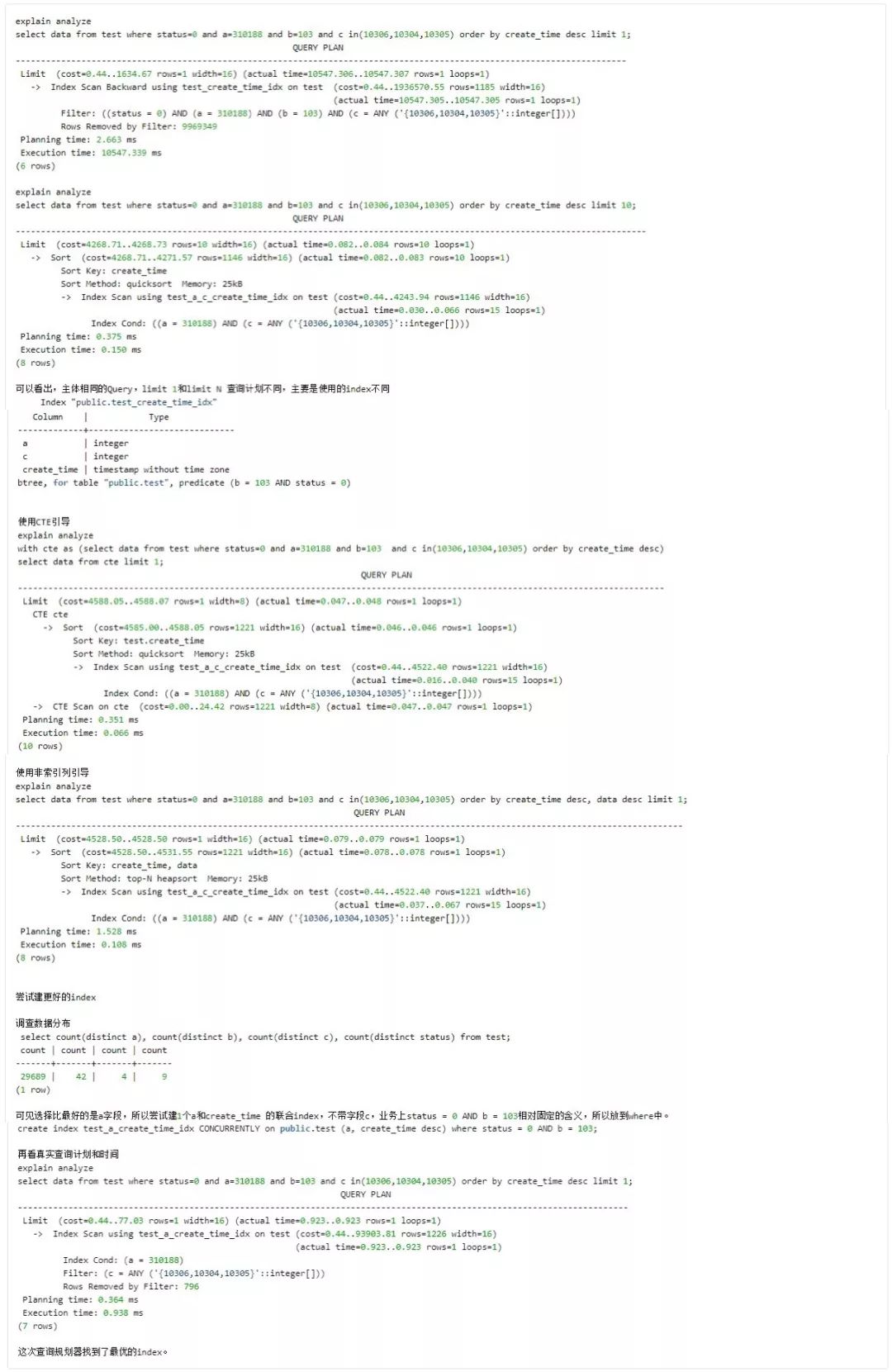
总结: 当发现查询规化器没有使用最优的 index,可以尝试使用 CTE 调整查询计划。
注意: 并不是所有的 Query 使用 CTE 都有性能提升,此 case 更多是提供一个尝试优化的思路。
About Index
对 query 的优化,index 是最核心问题之一。
索引并不是越多越好,存储索引本身也有空间开销,扫描索引本身也有时间开销,索引固然可以提高相应的 query(不限于 select)的执行效率,但同时也降低了写入的效率,因为写入时有可能会维护索引,所以怎样建索引需要慎重考虑,视具体情况而定。

Index Types
PostgreSQL provides several index types: B-tree, Hash, GiST(Generalized Search Tree), SP-GiST(space-partitioned GiST) , GIN (Generalized Inverted Index) and BRIN(Block Range INdexes)。
各自适用范围简要说明:
(1)B-tree: 最常用的 index, 适合处理等值及范围 queries。
(2)Hash: 只能处理简单等值 queries, 但由于在 PostgreSQL 9.6 及之前的版本中, Hash index 的更改无法写入 WAL, 所以一旦实例崩溃重启,可能需要 reindex 或重建, 特别是有 Primary/Standby 结构的集群中,禁止使用 Hash index。注意:在 PostgreSQL10 做了优化,无此限制。
(3)GiST: 不是一种的简单 index 类型,而是一种架构,可以在这种架构上实现很多不同的 index 策略。PostgreSQL 中的几何数据类型有很多 GiST 操作符类。SP-GiST: GiST 的增强,引入新的 index 算法提高 GiST 在某些情况下的性能。
(4)GIN: 反转 index,又称广义倒排 index,它可以处理包括多个键的值, 如数组,Jsonb 等。
(5)BRIN: 首次出现于 9.5 中。
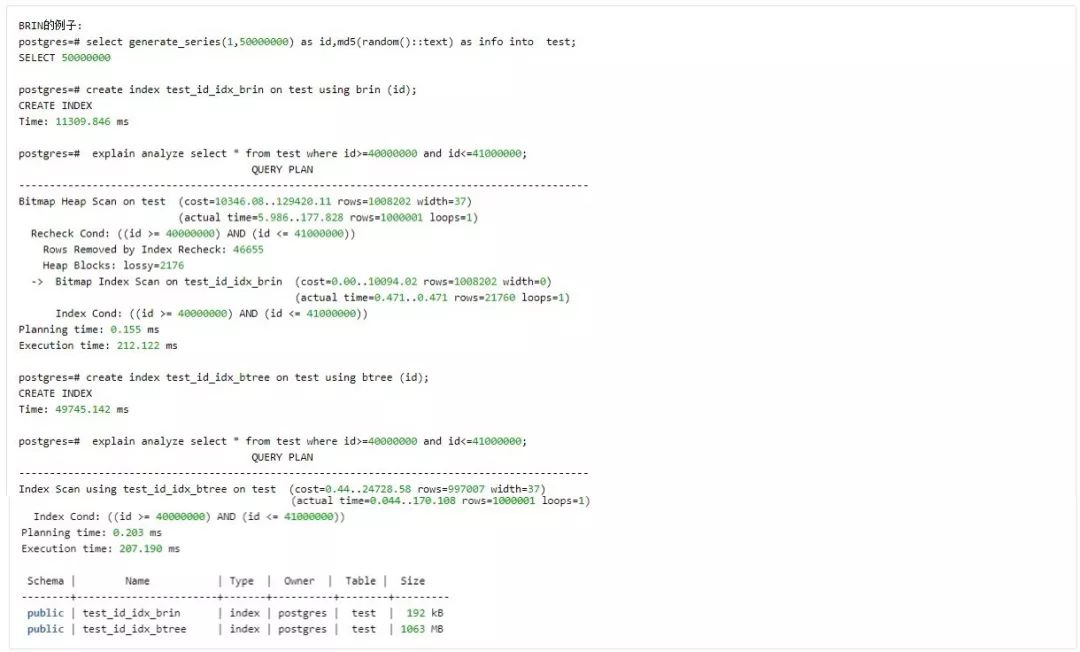
BRIN 索引适用于数据值分布和物理值分布相关性很好的情况,比如我们的订单表中的 create_time 字段,时间的增量和数据位置的偏移一致,那么各块的独立性将会很好,不会出现交叉,这种情况就非常适合 BRIN。同理,流式日志数据的,比如用户行为的日志,大批量的数据按时间顺序不停的插入数据表也非常适合使用 BRIN 索引。BRIN 索引是有损索引,不能直接从索引中匹配需要查询的记录,但通过索引可以将查询范围有效缩小,而且远没有 BTree 索引那么臃肿;且由于 BTree 的维护成本要远高于 BRIN,所以数据插入效率 BRIN 也是高于 BTree 的。
更多信息参见 https://wiki.postgresql.org/wiki/What'snewinPostgreSQL9.5#BRIN_Indexes http://www.postgresql.org/docs/9.5/static/brin.html
Finding the unused index
找出 create 后未使用的 index。
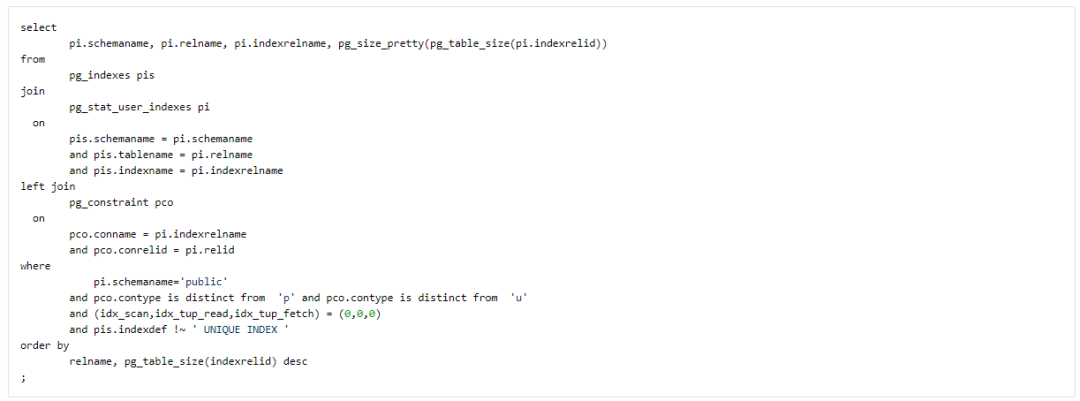
注意:
(1)上面的 SQL 中排除了 Primary key,Unique constraints 及 Unique index,因为这些约束依赖的 index,虽然没有使用,但是作为约束而言,还有约束业务逻辑 unique 的功能, 所以不可以轻易 drop。
(2)如果一个 index 刚 create 或者 create 不久,那么使用率低是正常的,并且主库和从库的 index 使用情况是不一样的,所以需要全面看。
Finding the duplicate index
找出重复的 index。
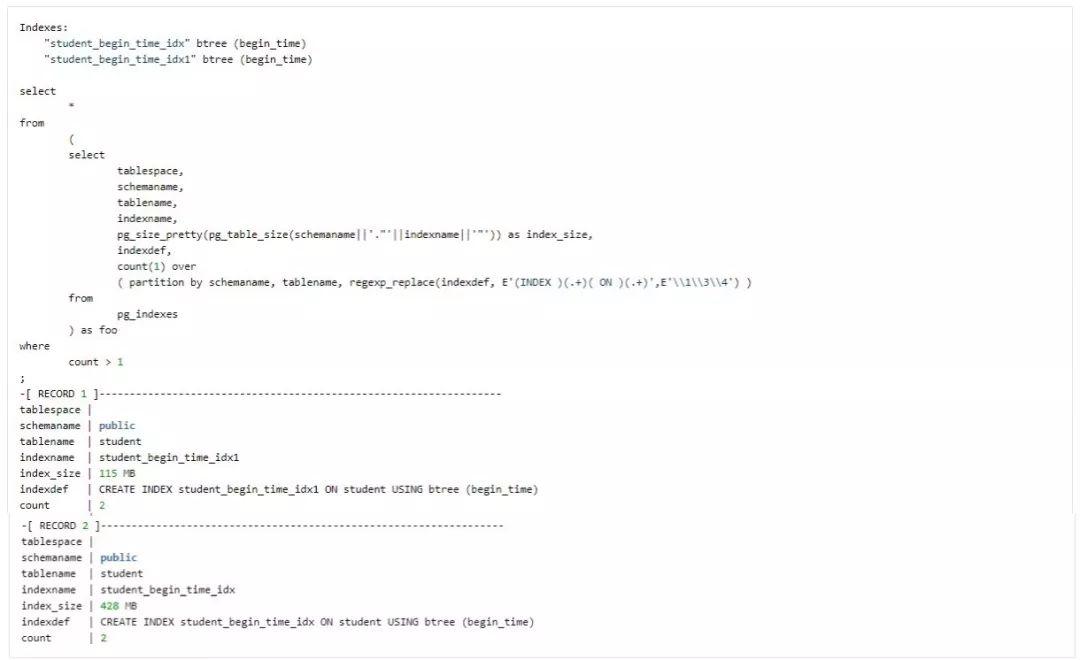
可 drop 掉其中 index_size 大的。
Finding the index needed to maintenance
找出需要维护的 index。(由于 PostgreSQL 的 MVCC 的实现机制,table 经过一段时间 update/delete,index 或出现膨胀) Reference information 1:

找出 tuple_percent 值低的, 比如 50% 以下。
注意: function pgstattuple 执行较慢,如果 table 或 index size 较大, 建议避开 DB Server load 高 或 IO 重的时候执行!
Reference information 2:
仅限于Btree index

找出bloat_pct 或 bloat_mb 值高的。
Auto make Index maintenance SQL
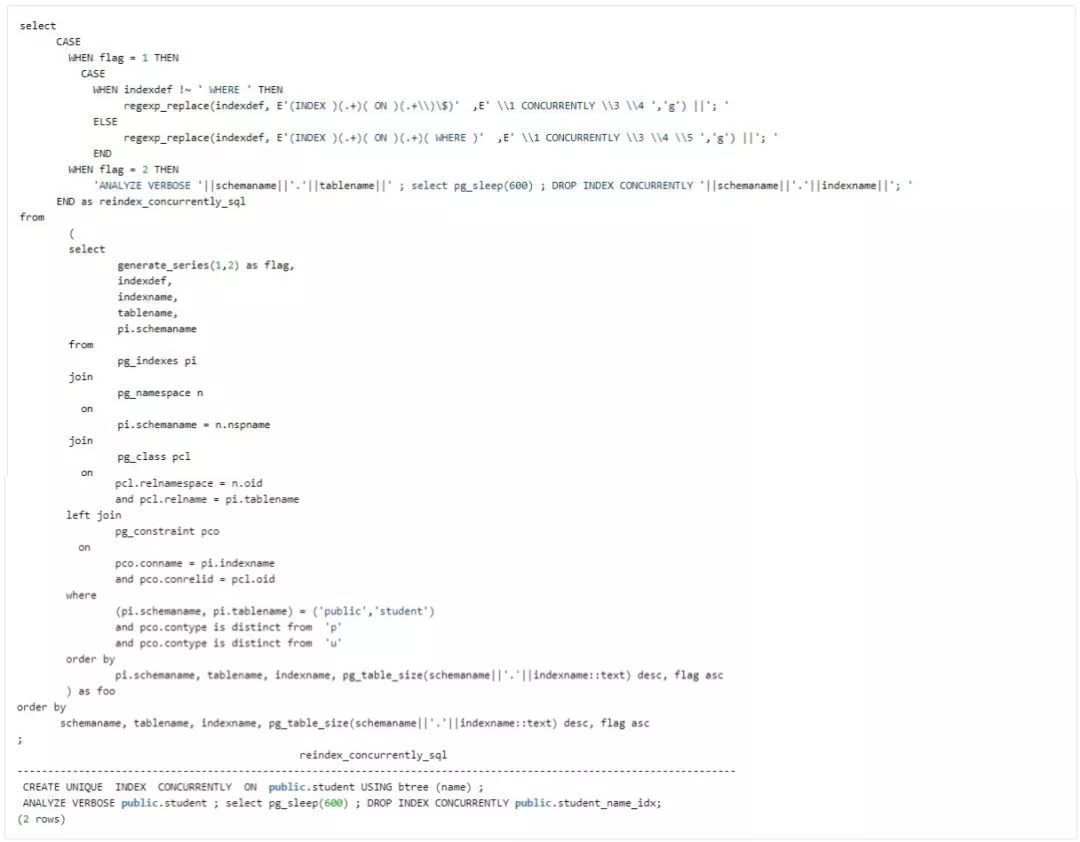
上面的生成的 CREATE INDEX CONCURRENTLY ; DROP INDEX CONCURRENTLY SQL 可以用来方便的进行对用户透明的 REINDEX。此 SQL 排除了对 Unique constraints, Primary key 的维护,因为二者是虽然都带 index,但表面上是以 constraint 的形式存在的。另外,pgsql-hackers 已在即将 Release 的 PostgreSQL 12 中开发了 REINDEX CONCURRENTLY 这个命令,相当值得期待!
Unique constraints, Primary key 的维护
同时,这也是一个 index size 影响 Query Plan 的例子。
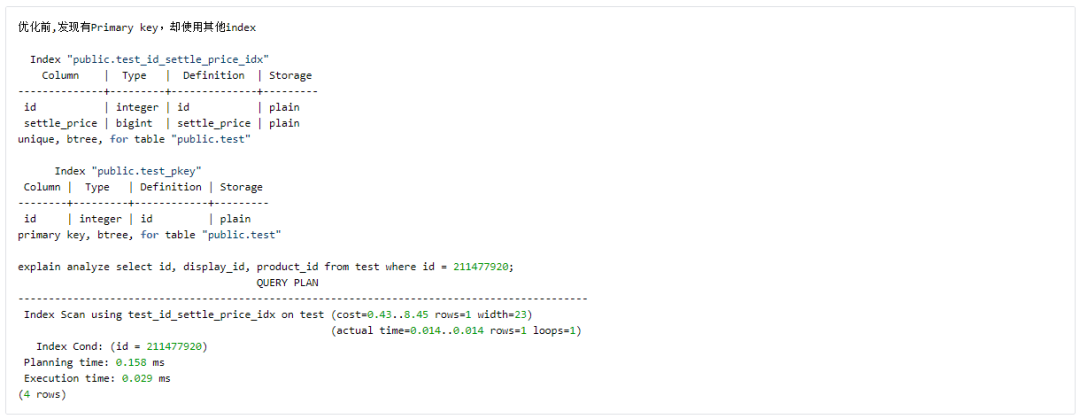
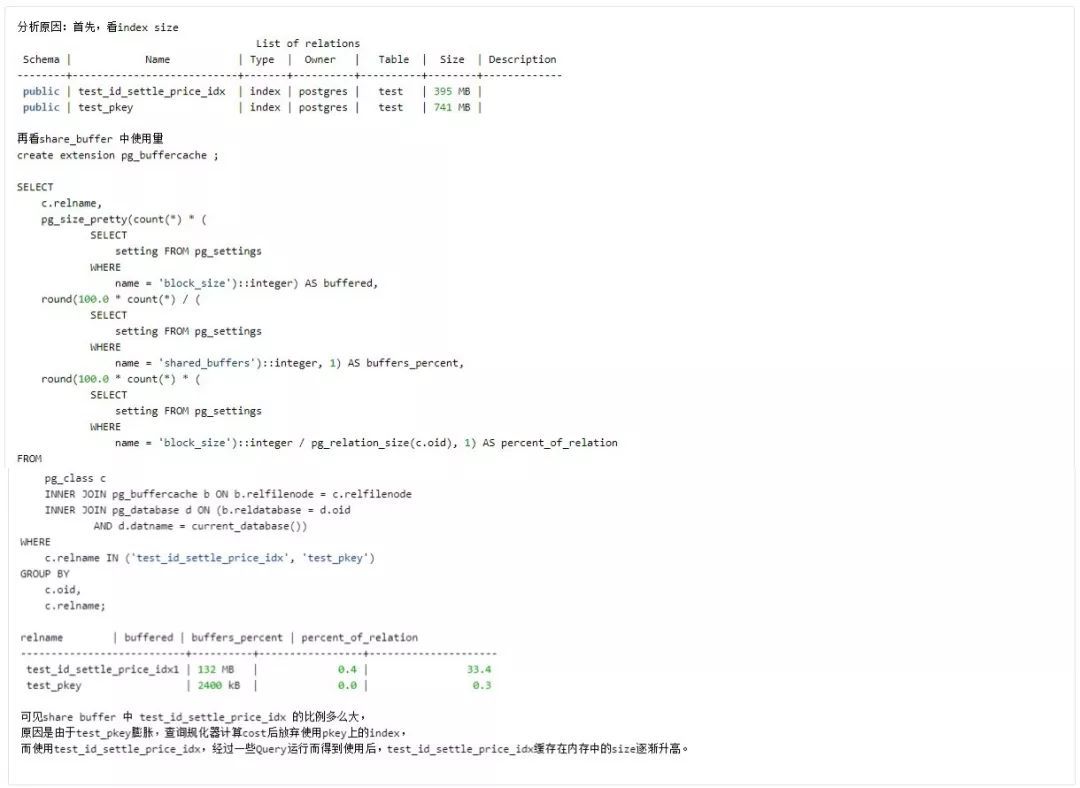
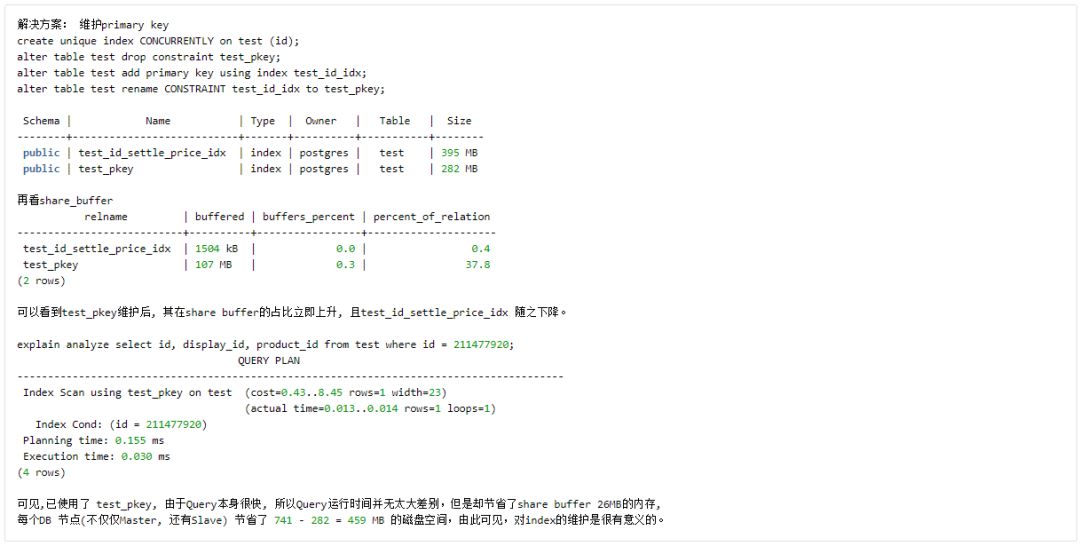
注意:由上例可见,将 Unique constraints, Primary key 替换成 Unique index 的等效形式(其实有细微区别,比如对多列进行 group by 时,id 为 primary key 支持 group by id 的简洁语法,但基本可忽略),可方便后续维护。
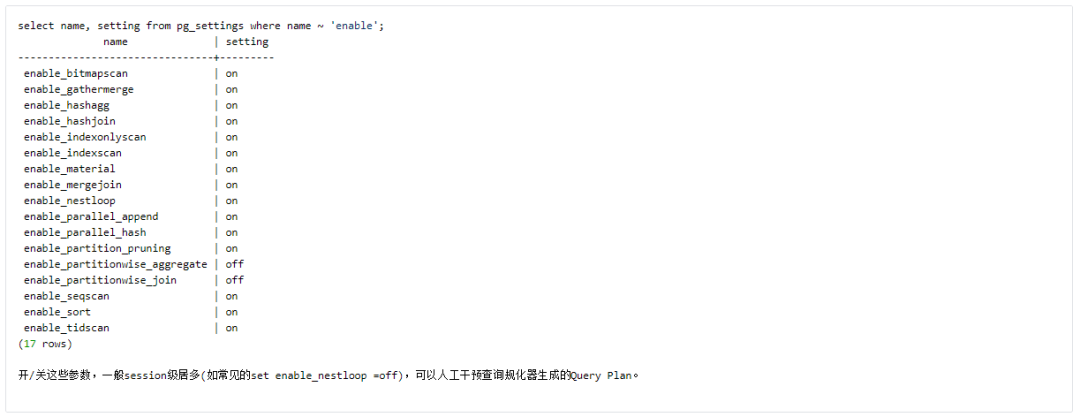
Some parameters that affect the query plan
enable_xxx
default_statistics_target

random_page_cost

另外,还有一些影响 Query Plan 的 cpu、parallel、jit 相关的进阶 cost 参数,一般非专业 DBA 不做调整,有兴趣可以后续探讨。

End


