





大家好,今天和大家分享的是PG的同步复制。
我们还是以oracle 的data guard 复制作为参考, 熟悉oracle 的小伙伴都知道 oracle DG 的模式分为 3 中 :
Maximum performance : 也就是我们常用的异步复制,性能最优。
Maximum availability : 最大可用化,即只要一个从节点成功,则返回成功。 属于同步模式。
Maximum protection : 最大数据保护模式,所有从节点返回成功,才能执行成功。 属于同步模式中的数据最大保护模式。
PG 作为ORACLE 的 开源 mini 版本, 也提供2种同步的模式:
priority-based : 基于优先级的同步方式 : S1,S2 是需要同步复制的
synchronous_standby_names = 'FIRST 2 (s1, s2, s3)'复制
quorum-based: 基于大多数的同步方式 : S1,S2,S3 任意2个节点复制成功,就算成功。
synchronous_standby_names = 'ANY 2 (s1, s2, s3)'复制
从同步复制的角度来看,似乎比老大哥 oracle 配置更为灵活, 尤其是 quorum-based 这种复制方式,与当前很多流行的shared-nothing 架构的分布式数据库 (基于 raft 或者 poxis 协议的)很像了。
我们先来简单的配置和测试一下PG 的同步服务:
现有的一主二从的数据库异步复制结构:
postgres@[local:/tmp]:2002=#5991 select * from pg_stat_replication ;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_ls
n | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+---------+------------------+--------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+---------
---+------------+-----------+-----------+------------+---------------+------------+-------------------------------
13895 | 16384 | repuser | walreceiver | 10.67.39.49 | | 33820 | 2022-09-12 11:25:04.957798+08 | | streaming | 1/240001C0 | 1/240001C0 | 1/240001
C0 | 1/240001C0 | | | | 0 | async | 2022-09-14 16:46:39.195515+08
13896 | 16384 | repuser | walreceiver | 10.67.39.149 | | 36446 | 2022-09-12 11:25:04.97499+08 | | streaming | 1/240001C0 | 1/240001C0 | 1/240001
C0 | 1/240001C0 | | | | 0 | async | 2022-09-14 16:46:41.347217+08
(2 rows)
复制目前是 async 模式的(默认同步模式),我们要修改为 sync 模式的:
1.我们需要修改从库 参数 cluster_name, 如果不设置这个 cluster_name 的话, 默认standby 的 application_name 显示 walreceiver
postgres=# alter system set cluster_name = 'standby149';
ALTER SYSTEM
postgres=# alter system set cluster_name = 'standby49';
ALTER SYSTEM
复制这个参数生效是需要重启实例的。
/opt/postgreSQL/pg12/bin/pg_ctl -D /data/postgreSQL/2002/data restart复制
再次从主库查看2个从库的 application name: 符合我们这时的预期
postgres@[local:/tmp]:2002=#30583 select application_name from pg_stat_replication ;
application_name
------------------
standby149
standby49
(2 rows)
复制2,主库上我们需要修改参数 synchronous_standby_names
我们修改为 quorum-based的 同步模式, standby149,standby49 任意一个同步成功即可。 类似于老大哥oracle 的 Maximum availability 模式
synchronous_standby_names = 'ANY 1 (standby149,standby49)'复制
这个参数的作用域是 sighup , 无需重启实例
postgres@[local:/tmp]:2002=#30583 select context from pg_settings where name = 'synchronous_standby_names';
context
---------
sighup
(1 row)
postgres@[local:/tmp]:2002=#30583 alter system set synchronous_standby_names = 'ANY 1 (standby149,standby49)';
ALTER SYSTEM
postgres@[local:/tmp]:2002=#30583 select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
postgres@[local:/tmp]:2002=#30583 show synchronous_standby_names;
synchronous_standby_names
------------------------------
ANY 1 (standby149,standby49)
(1 row)
复制3.测试一下场景:
关闭1个实例,主库提交 commit
从库:
INFRA [postgres@wqdcsrv3354 data]# /opt/postgreSQL/pg12/bin/pg_ctl -D /data/postgreSQL/2002/data stop
waiting for server to shut down.... done
server stopped
复制主库: 执行事务操作不受任何影响
appdb@[local:/tmp]:2002=#41295 create table t1(id int);
CREATE TABLE
appdb@[local:/tmp]:2002=#41295 insert into t1 select 1;
INSERT 0 1
复制关闭2个实例,主库提交 commit
appdb@[local:/tmp]:2002=#41295 insert into t1 select 2; -- 命令会hang住了
复制这个时候,启动任意一个从库:
INFRA [postgres@wqdcsrv3354 data]# /opt/postgreSQL/pg12/bin/pg_ctl -D /data/postgreSQL/2002/data start
复制主库立刻显示 提交成功:
appdb@[local:/tmp]:2002=#41295 insert into t1 select 2;
INSERT 0 1
复制带着大家体验了一下 quorum-based 的同步模式之后, 大家也可以自行测试一下 priority-based 的同步模式。
个人觉得 :
quorum-based 适合同 DC 内, 网络延时较小的环境。 如果是跨DC的混合模式话,建议跨DC的节点设置成 级联复制 (cascade 模式)
priority-based 适合读写分离的模式,指定高优先级的standby 保证数据的一致性。
我们接来在看一下重要的参数 synchronous_commit , 这是一个值得深入研究的参数。
官网文档上写的还是比较详细的 https://www.postgresql.org/docs/14/runtime-config-wal.html#GUC-SYNCHRONOUS-COMMIT
Specifies how much WAL processing must complete before the database server returns a “success” indication to the client. Valid values are remote_apply, on (the default), remote_write, local, and off.
指定WAL处理完成的多少来提示客户端是否返回成功操作。
合法选项的值如下: (根据数据保护优先级从高到低排列,性能排序自然是由底到高)
remote_apply: 数据保护优先级最高,remote standby 节点 apply log 成功之后,才返回返回客户端成功。可以实现读节点与写入节点的数据一致性
on: (开启同步复制之后的默认值) ,WAL 刷新到 remote standby 的OS 的磁盘之后, 才返回客户端成功。 理论上即使主机断电,机器crash掉,重启之后也不会丢数据
remote_write: WAL 刷新到 remote standby 的WAL日志中,才返回客户端成功。 理论上即使PG实例down 机, 重启PG实例也不会丢数据。
local: (异步复制的默认值)WAL 刷新到本地 OS 的磁盘中,就返回客户端成功。 不会等待standby的WAL的处理进度
off: 事务不会等待WAL 刷新到本地磁盘,就返回客户端成功。
参考官网文档上的这个图表,更为清晰。

Percona 公司更为形象的画出了这些不同选项的WAL的完成过程:
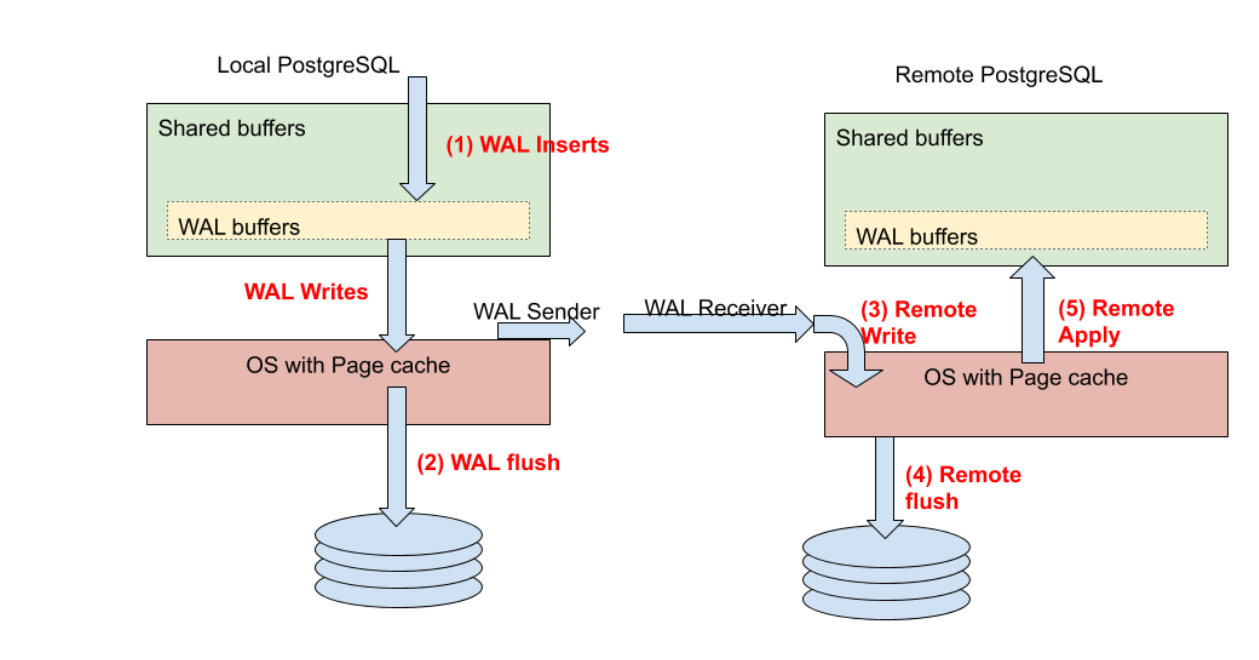
synchronous_commit 参数的作用域可以是 session,user, database,system level, 对于客户端来说的是可以自行灵活调节的。
对于我们开启sync 模式之后(即设置了参数synchronous_standby_names), 默认值是ON 也就说 WAL 刷新到 remote standby 的OS 的磁盘之后, 才返回客户端成功。
postgres@[local:/tmp]:2002=#119202 show synchronous_commit ;
synchronous_commit
--------------------
on
(1 row)
复制我们测试一下设置 session 级别 synchronous_commit = ‘remote_apply’
主库:
postgres@[local:/tmp]:2002=#119202 set synchronous_commit = 'remote_apply';
SET
复制2个从库都暂停 log apply:
postgres=# SELECT pg_wal_replay_pause();
pg_wal_replay_pause
---------------------
(1 row)
复制主库插入数据:命令会hang 住了
postgres@[local:/tmp]:2002=#119202 insert into t1 values (1,'testing remote WAL apply');
复制直到从库解除暂停 log apply,主库才返回插入数据成功。
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)
复制我们把数据安全降级到: synchronous_commit = ‘on’
主库:
postgres@[local:/tmp]:2002=#119202 set synchronous_commit = 'on';
SET
复制从库再次暂停 log apply:
postgres=# SELECT pg_wal_replay_pause();
pg_wal_replay_pause
---------------------
(1 row)
复制主库尝试插入数据 ,这次是成功的。
postgres@[local:/tmp]:2002=#119202 insert into t1 values (1,'testing remote WAL apply');
INSERT 0 1
复制到底如何平衡性能与数据安全性呢? 这个参数要不要设置呢? 引用官网的一句话:
For example, an application workload might consist of: 10% of changes are important customer details, while 90% of changes are less important data that the business can more easily survive if it is lost, such as chat messages between users.
应用端需要衡量重要的数据(比例10%)采用数据安全等级较高的( synchronous_commit 为 on,remote_apply),90%不重要的数据可以接受机器crash 掉丢失的数据可以设置为数据安全等级较低的参数,来获得最大的性能。
看来PG的官方是让具体的业务系统来自己决定数据的重要性,采用session 级别的设置方式是实现数据安全与性能的最大平衡。
个人看来,很多程序员同学往往不会考虑到那么的周全。所以这个 session 级别的设置,不知道在实际生产的项目中用的到底有多少人在用。
=============================================================================================
最后我们进行一个同步和异步的性能测试。 看看性能有多大差距。
测试工具还是我们的老朋友: pgbench+ grafana
测试环境是性能有限的虚拟测试机器:Memory 1GB , CPU : 8 core
测试的命令: pgbench -M prepared -r -c 16 -j 2 -T 300 -U postgres -p 2002 -d pgbench -l
测试的PG主从环境:1 主 + 2 从
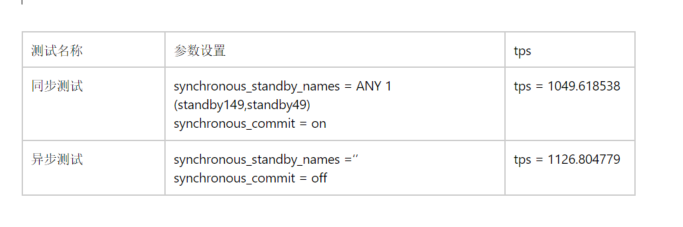
同步测试结果:
quorum-based下的同步测试, tps 略有下降 (1126-1049)/1049 约等于 7.34% 的下降。 这个结果还是可以让人接受的。
具体测试过程如下:
同步参数: synchronous_standby_names = ANY 1 (standby149,standby49)
synchronous_commit = on
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 16
query mode: prepared
number of clients: 16
number of threads: 2
duration: 300 s
number of transactions actually processed: 315312
latency average = 15.244 ms
tps = 1049.618538 (including connections establishing)
tps = 1049.626801 (excluding connections establishing)
statement latencies in milliseconds:
0.066 \set aid random(1, 100000 * :scale)
0.061 \set bid random(1, 1 * :scale)
0.059 \set tid random(1, 10 * :scale)
0.064 \set delta random(-5000, 5000)
0.662 BEGIN;
0.900 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
0.623 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
1.252 UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
4.130 UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
0.653 INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
6.327 END;
复制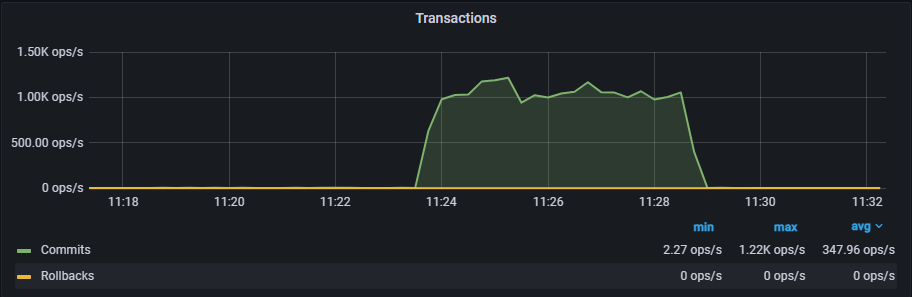
异步模式:
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 16
query mode: prepared
number of clients: 16
number of threads: 2
duration: 300 s
number of transactions actually processed: 338368
latency average = 14.199 ms
tps = 1126.804779 (including connections establishing)
tps = 1126.812964 (excluding connections establishing)
statement latencies in milliseconds:
0.066 \set aid random(1, 100000 * :scale)
0.064 \set bid random(1, 1 * :scale)
0.057 \set tid random(1, 10 * :scale)
0.072 \set delta random(-5000, 5000)
0.843 BEGIN;
1.256 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
0.996 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
1.406 UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
3.339 UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
0.956 INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
4.527 END;
复制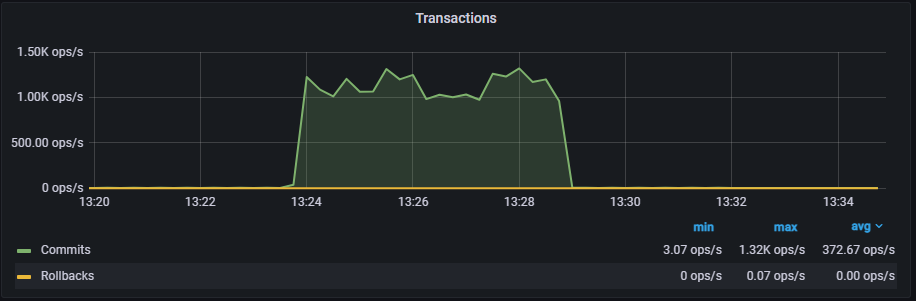
最后总结:
1)PG 的同步复制方案相对老大哥oracle的DG 来说 配置更为灵活,提供了 priority-based 和quorum-based 2种方式
2)PG官网的建议是应用系统根据自身的特点在session 级别设置参数 synchronous_commit 来平衡数据库重要性和性能。
3)同步复制的性能比异步复制会略有下降,前提是同一个DC内的同步复制,如果跨DC的话,网络延时高,强烈不建议同步复制,可以
考虑cascade 复制模式。
Have a fun 🙂 !
评论

 0 点赞
0 点赞 0 点赞
0 点赞