






1 Spark Thrift部署
下载地址:
http://mirrors.hust.edu.cn/apache/spark/spark-2.1.0/spark-2.1.0-bin-hadoop2.6.tgz复制
解压
[root@cdh03 ~]# tar -zxvf spark-2.1.0-bin-hadoop2.6.tgz复制
拷贝至/opt/cloudera/parcels/SPARK2/lib/spark2/jars目录
在集群所有节点上执行
[root@cdh03 ~]# cd root/spark-2.1.0-bin-hadoop2.6/jars/
[root@cdh03 jars]# ll *hive*.jar
[root@cdh03 jars]# cp hive-cli-1.2.1.spark2.jar spark-hive-thriftserver_2.11-2.1.0.jar opt/cloudera/parcels/SPARK2/lib/spark2/jars/
[root@cdh03 jars]# ll opt/cloudera/parcels/SPARK2/lib/spark2/jars/*hive*.jar复制
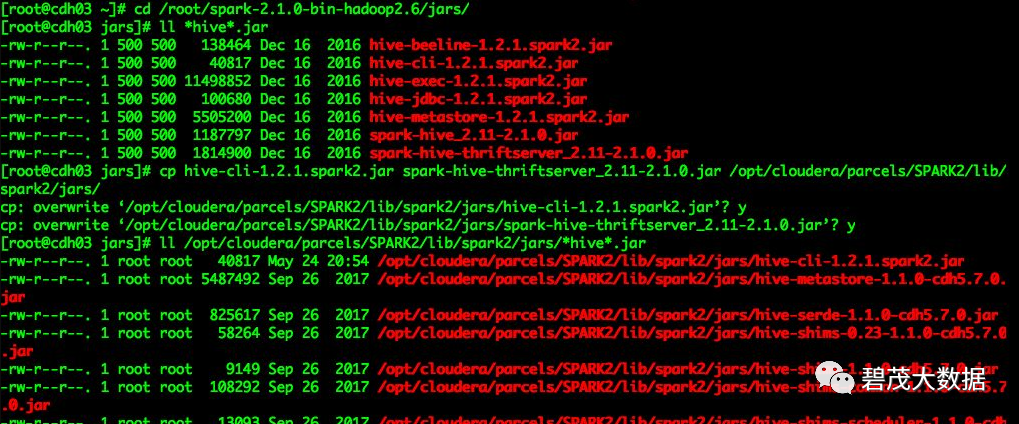
把/opt/cloudera/parcels/SPARK2/lib/spark2/jars目录下的所有jar上传至HDFS
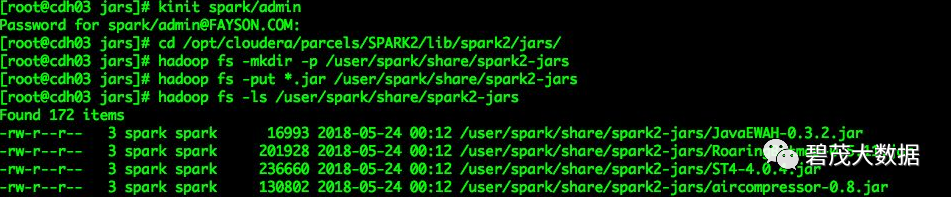
[root@cdh03 jars]# kinit spark/admin
Password for spark/admin@FAYSON.COM:
[root@cdh03 jars]# cd opt/cloudera/parcels/SPARK2/lib/spark2/jars/
[root@cdh03 jars]# hadoop fs -mkdir -p user/spark/share/spark2-jars
[root@cdh03 jars]# hadoop fs -put *.jar user/spark/share/spark2-jars
[root@cdh03 jars]# hadoop fs -ls user/spark/share/spark2-jars复制
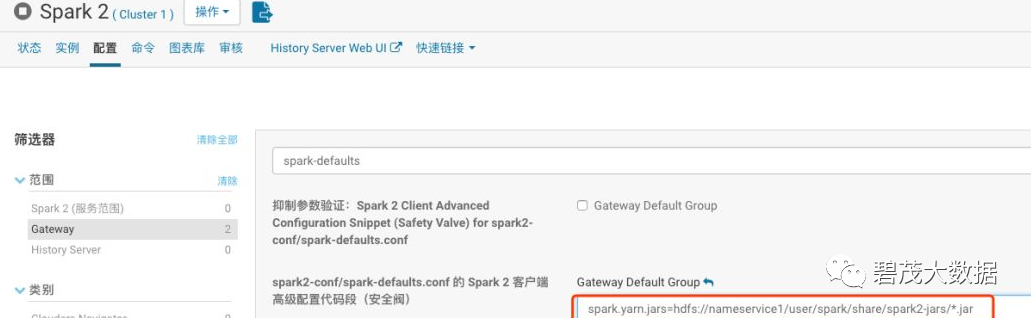
修改Spark的配置
spark.yarn.jars=hdfs://nameservice1/user/spark/share/spark2-jars/*.jar复制
Spark Thrift启动和停止脚本
[root@cdh03 jars]# cd root/spark-2.2.0-bin-hadoop2.6/sbin/
[root@cdh03 sbin]# ll *thrift*.sh
[root@cdh03 sbin]# cp *thrift*.sh opt/cloudera/parcels/SPARK2/lib/spark2/sbin/
[root@cdh03 sbin]# ll opt/cloudera/parcels/SPARK2/lib/spark2/sbin/*thriftserver*复制
修改load-spark-env.sh脚本
[root@cdh03 sbin]# cd opt/cloudera/parcels/SPARK2/lib/spark2/bin
[root@cdh03 bin]# vim load-spark-env.sh
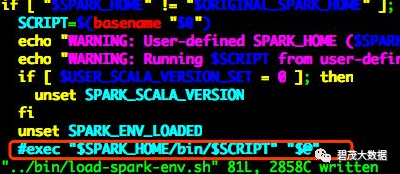
# 该脚本是启动Spark相关服务加载依赖环境复制
内容注释
exec "$SPARK_HOME/bin/$SCRIPT" "$@"复制
部署Spark SQL客户端
[root@cdh03 ~]# cd spark-2.1.0-bin-hadoop2.6/bin/
[root@cdh03 bin]# pwd
[root@cdh03 bin]# cp root/spark-2.1.0-bin-hadoop2.6/bin/spark-sql opt/cloudera/parcels/SPARK2/lib/spark2/bin
[root@cdh03 bin]# ll opt/cloudera/parcels/SPARK2/lib/spark2/bin/spark-sql复制
2 Spark Thrift的启动与停止
创建一个Kerberos账号,导出hive.keytab文件
[root@cdh01 ~]# kadmin.local
kadmin.local: addprinc -randkey hive/cdh03.fayson.com@FAYSON.COM
kadmin.local: xst -norandkey -k hive-cdh03.keytab hive/cdh03.fayson.com@FAYSON.COM复制
查看
[root@cdh01 ~]# klist -e -kt hive-cdh03.keytab复制
文件拷贝hive-cdh03.keytab至Spark2.1 ThriftServer服务所在服务器
[root@cdh01 ~]# scp hive-cdh03.keytab cdh03.fayson.com:/opt/cloudera/parcels/SPARK2/lib/spark2/sbin/复制
启动Thrift Server
cd opt/cloudera/parcels/SPARK2/lib/spark2/sbin
./start-thriftserver.sh --hiveconf hive.server2.authentication.kerberos.principal=hive/cdh03.fayson.com@FAYSON.COM \
--hiveconf hive.server2.authentication.kerberos.keytab=hive-cdh03.keytab \
--hiveconf hive.server2.thrift.port=10002 \
--hiveconf hive.server2.thrift.bind.host=0.0.0.0 \
--principal hive/cdh03.fayson.com@FAYSON.COM --keytab hive-cdh03.keytab复制
检查监听
[root@cdh03 sbin]# netstat -apn |grep 10002复制
Spark ThriftServer服务停止
[root@cdh03 sbin]# ./stop-thriftserver.sh复制
3 验证
beeline测试
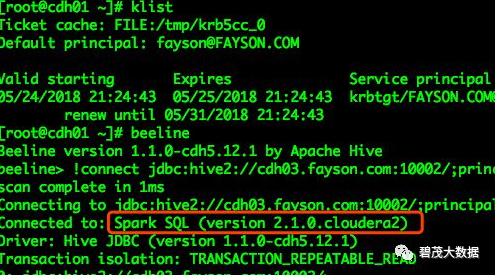
[root@cdh01 ~]# kinit fayson
[root@cdh01 ~]# klist
[root@cdh01 ~]# beeline
beeline> !connect jdbc:hive2://cdh03.fayson.com:10002/;principal=hive/cdh03.fayson.com@FAYSON.COM复制
SQL测试
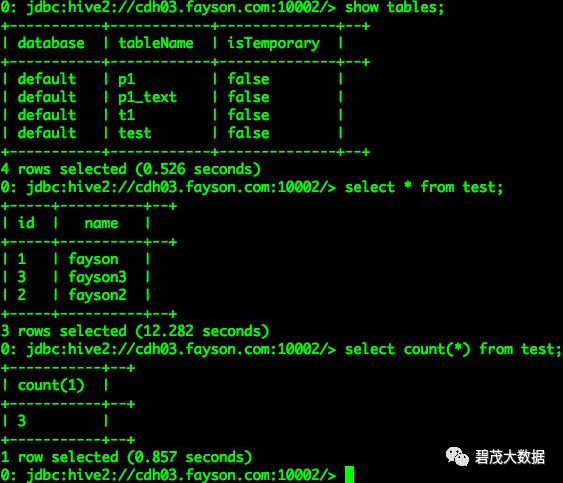
0: jdbc:hive2://cdh03.fayson.com:10001/> show tables;
0: jdbc:hive2://cdh03.fayson.com:10001/> select * from test;
0: jdbc:hive2://cdh03.fayson.com:10001/> select count(*) from test;
0: jdbc:hive2://cdh03.fayson.com:10001/>复制
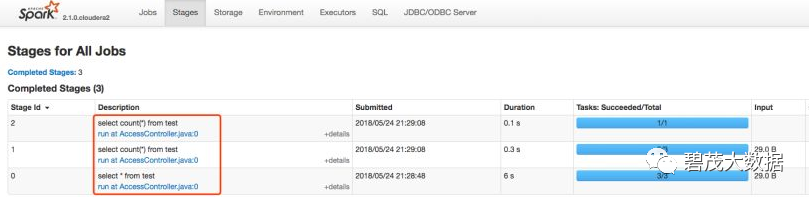
查看SQL操作是否是通过Spark执行
spark-sql验证
[root@cdh03 ~]# kinit fayson
[root@cdh03 ~]# /opt/cloudera/parcels/CDH/lib/spark/bin/spark-sql复制
关注公众号:领取精彩视频课程&海量免费语音课程

文章转载自碧茂大数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
392次阅读
2025-04-17 17:02:24
云和恩墨钟浪峰:安全生产系列之SQL优化安全操作
墨天轮编辑部
246次阅读
2025-03-31 11:08:20
Before & After:SQL整容级优化
薛晓刚
112次阅读
2025-04-14 22:08:44
SQL 优化之 OR 子句改写
xiongcc
100次阅读
2025-04-21 00:08:06
立马耀:通过阿里云 Serverless Spark 和 Milvus 构建高效向量检索系统,驱动个性化推荐业务
阿里云大数据AI技术
83次阅读
2025-04-24 10:51:56
Mysql/Oracle/Postgresql快速批量生成百万级测试数据sql
hongg
78次阅读
2025-04-07 15:32:54
Oracle DBA 必备!这份高效运维的“秘籍”,高频实用 SQL 一网打尽
青年数据库学习互助会
64次阅读
2025-03-31 10:03:00
Oracle数据库常用脚本(七)
lh11811
59次阅读
2025-04-01 08:57:44
“G”术时刻:资深工程师揭秘GBase数据库Hint核心技巧 实现SQL性能跃升
GBASE数据库
54次阅读
2025-04-25 10:10:28
如何高效使用 Text to SQL 提升数据分析效率?四个关键应用场景解析
镜舟科技
47次阅读
2025-04-15 18:58:40
