





写在之前
报警规则是 Prometheus 来调用的,触发报警规则后,Prometheus 把报警信息发送给 Alertmanager组件,报警格式如下:(最重要的就是报警规则的编写)
rules.yml: |
groups:
- name: Kubernetes集群资源-监控
rules:
- alert: kubernetes-apiserver打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- name: 物理节点资源-监控
rules:
- alert: 物理节点cpu使用率
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90
for: 2s
labels:
severity: ccritical
annotations:
summary: "{{ $labels.instance }}cpu使用率过高"
description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理"
- alert: 物理节点内存使用率
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_
memory_Cached_bytes)) node_memory_MemTotal_bytes * 100 > 90
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}内存使用率过高"
description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"复制
把相同资源类型的放在一起构成一个组,这里定义了两个组一个是Kubernetes集群资源-监控,一个是物理节点资源-监控。每个组下面配置rules,每个规则常用属性字段如下:
| 报警规则常用属性字段 | 含义 |
| alert | 表示监控的指标名称,方便理解的名称; |
| expr | 表达式,这里主要是使用PromQL语言编写的查询语句,满足条件的即达到触发报警的条件,但是否报警,还需要结合for选项: |
| for | 选项表示expr表达式持续时长多长时间,如果持续时间满足for指定的时长,即立马触发报警; |
| labels | 这个是定义报警的标签,可以根据这个定义报警级别,根据不同的级别发送不同的人员接收,这个后面总结 Alertmanager时,会使用到它; |
| annotations | 注解内容,报送报警时的内容,可以使用邮件、微信、叮叮等方式收到的报警内容,注意这里可以引用变量; |
| summary | 定义一个报警摘要信息,可以引用变量; |
| description | 定义一些报警内容,可以引用变量; |
样例
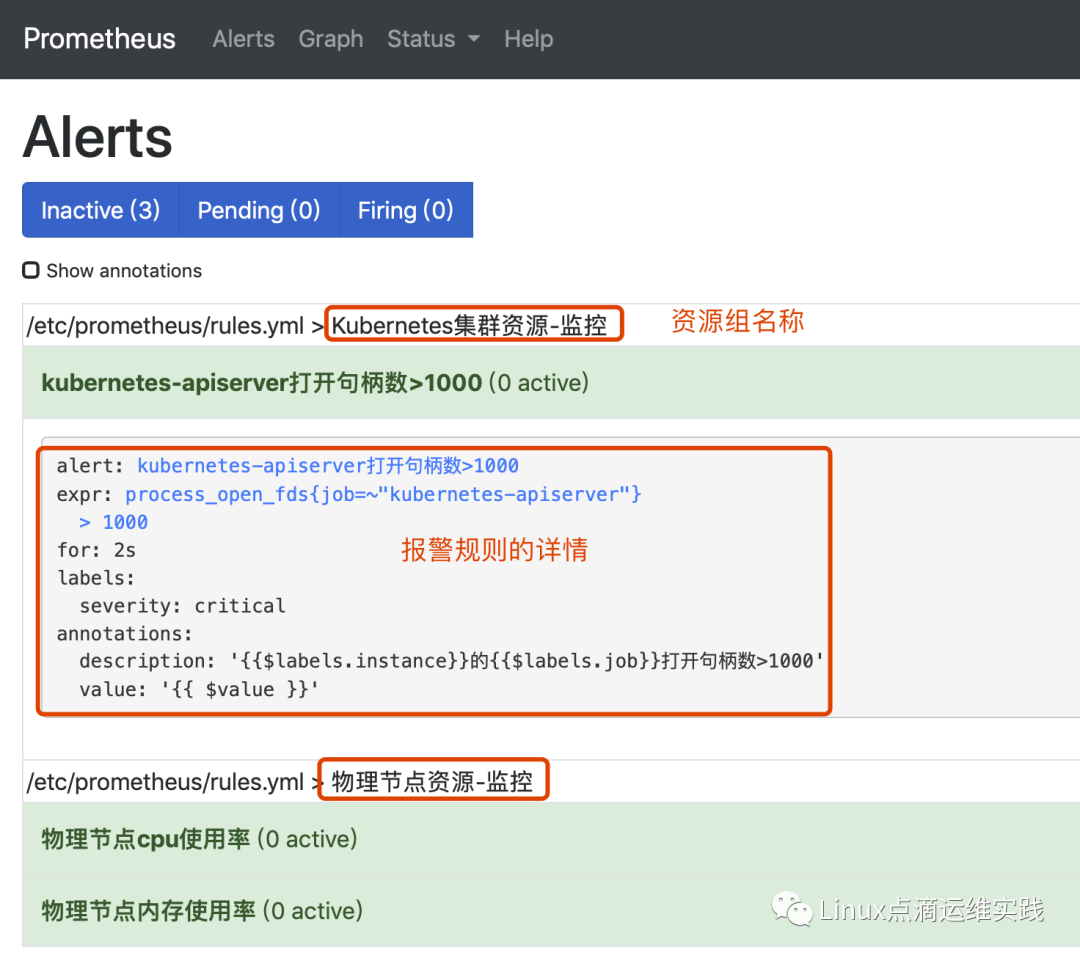
表达式检测条件满足时或不满足时,监控项就会出现三种不同的警报状态,他们分别是:
| 告警状态 | 功能 |
| pending | 警报通知已经被激活,但低于配置的持续时间,这里的持续时间即rule里的FOR字段设置的时间,在此状态下,不发送报警通知 |
| firing | 警报通知已经发送,而且超出设置的持续时间,该状态下发送报警通知 |
| inactive | 正常状态,既不是pending也不是firing的时候状态即inactive |
PromQL语言
PromQL
PromQL(Prometheus Query language)即 Prometheus查询语言的简称,它是 Prometheus 内置的查询语言,Prometheus 作为强大的开源监控系统,它最大的依赖便是PromQL,它是监控数据个性化查询、展示的基础,所以要掌握Prometheus,掌握PromQL是必备的前提。
时间序列
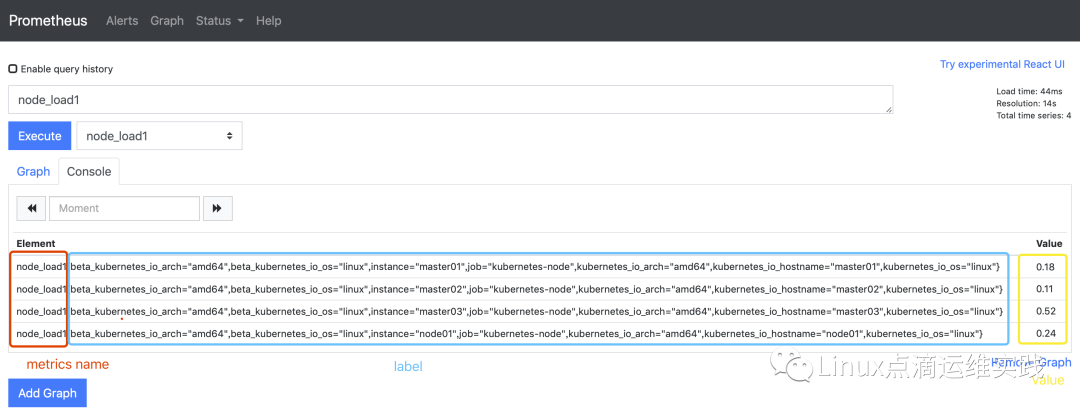
PromQL 操作的对象是时间序列,它是由指标名称(metrics name)和对应的一些label标签组成;指标名称就是定义的监控指标的基本标识,而label则是在基本指标的前提下,提供了一个多种特征的维度,用户可以基于这些特征维度再次过滤、聚合、统计,从而产生新的时间序列。
Prometheus 将采集到的指标数据以时间序列的方式保存在内存数据库中,并且定时的写到硬盘上,时间序列是按照时间戳和值的序列顺序存放的,我们称之为向量(vector)。
在 PromQL 语言中,表达式或子表达式包括以下四种类型:
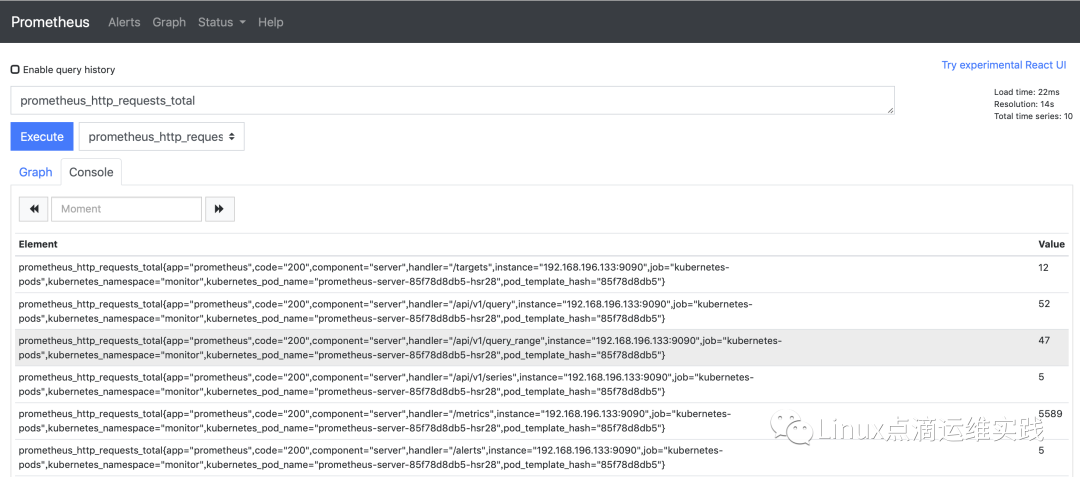
瞬时向量(Instant vector):包含一组时间序列,每个时序只有一个点,例如:http_requests_total;
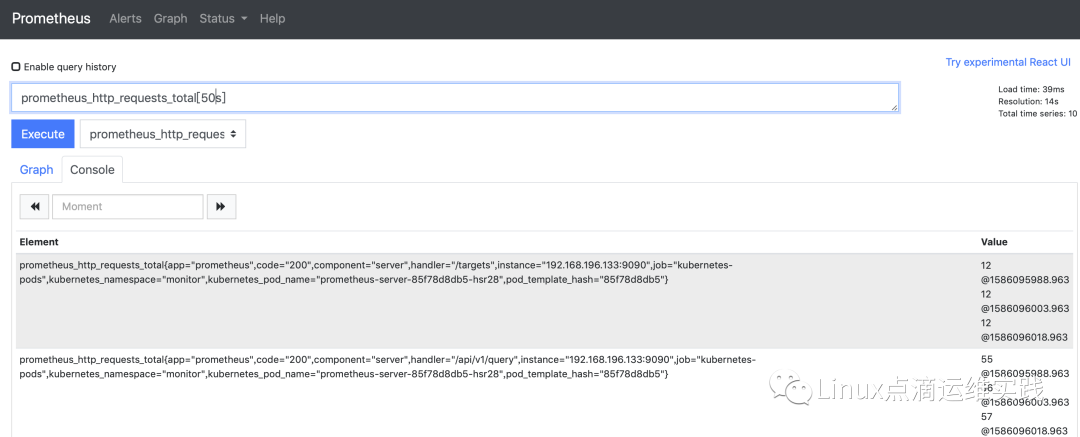
区间向量(Range vector):包含一组时间序列,每个时间序列有多个点,例如:http_requests_total[50s]
标量(Scalar):一个简单的数字浮点值;
字符串(String):一个简单的字符串值;
指标类型
Prometheus 定义了4种不同的指标类型:Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
Counter 类型的指标和计数器一样,只增不减。常见的监控指标,如 http_requests_total、 xxxx_total 都是 Counter 类型的监控指标;
Gauge 类型的指标侧重于反应指标的当前状态;
Histogram 和 Summary 主用用于统计和分析样本的分布情况;
PromQL 查询语法
查询条件
= 等于
!= 不等于
=~ 匹配正则表达式
!~ 与正则表达式不匹配
算术运算符
+,-,*,/,%,^

比较运算符
==,!=,>,<,>=,<=
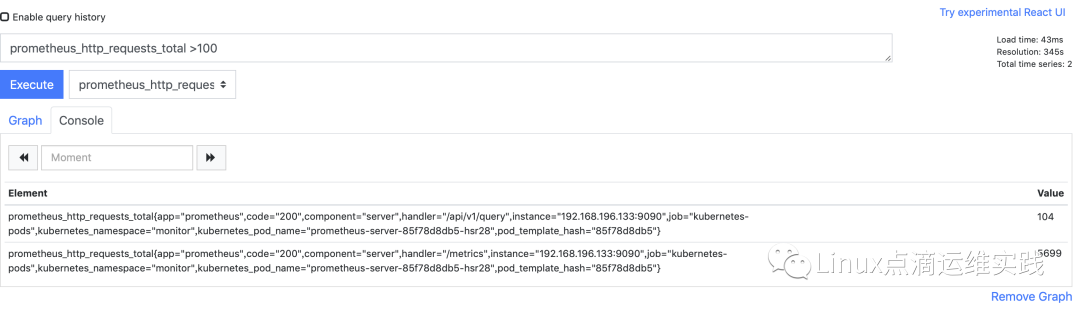
逻辑运算符
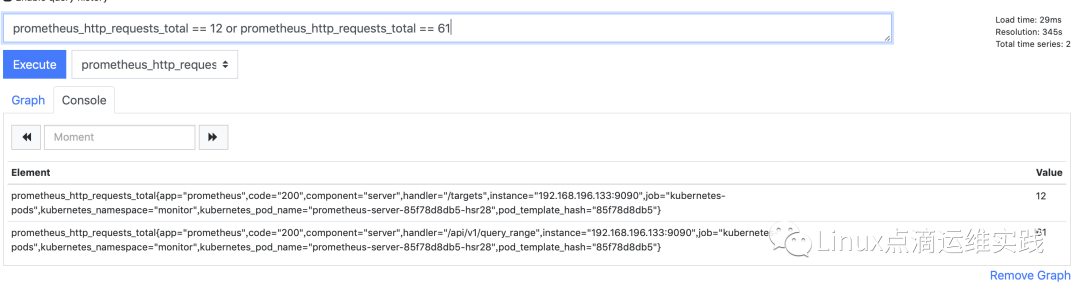
and,or,unless
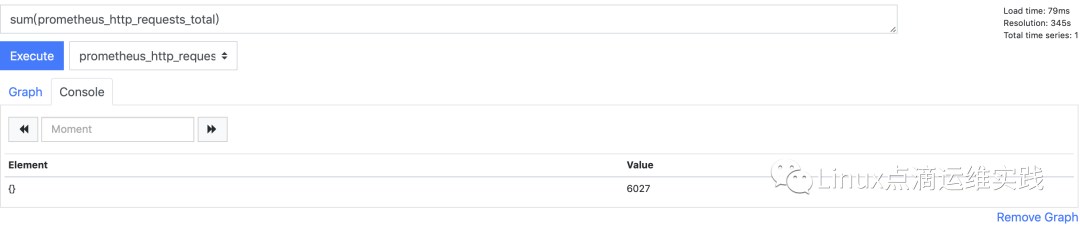
聚合运算符
sum、min、max、avg、stddev、stdvar、count、count_values、bottomk、topk、quantile;
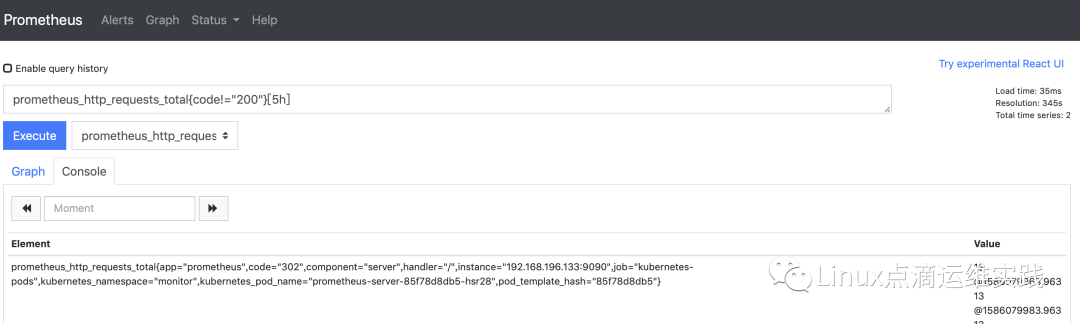
范围选择
s - 秒、m - 分钟、h - 小时、d - 天、w - 周、y - 年
内置函数
floor(avg(http_requests_total{code="200"}))
ceil(avg(http_requests_total{code="200"}))
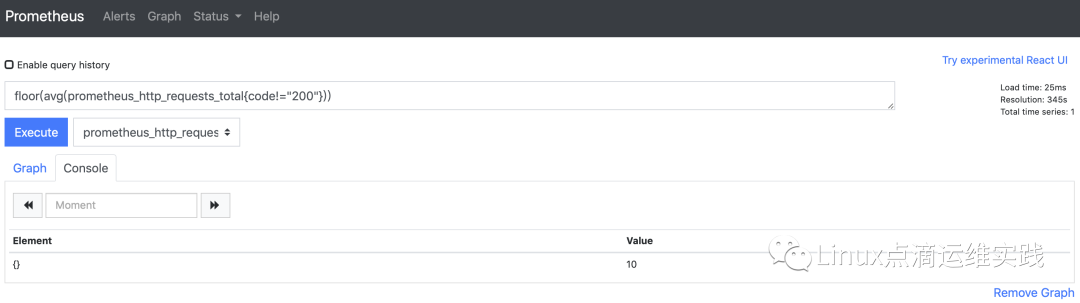
floor()、ceil(),都是将结果由浮点数转为整数,一个是取整,一个是四舍五入;
查看 http_requests_total 5分钟内,平均每秒数据
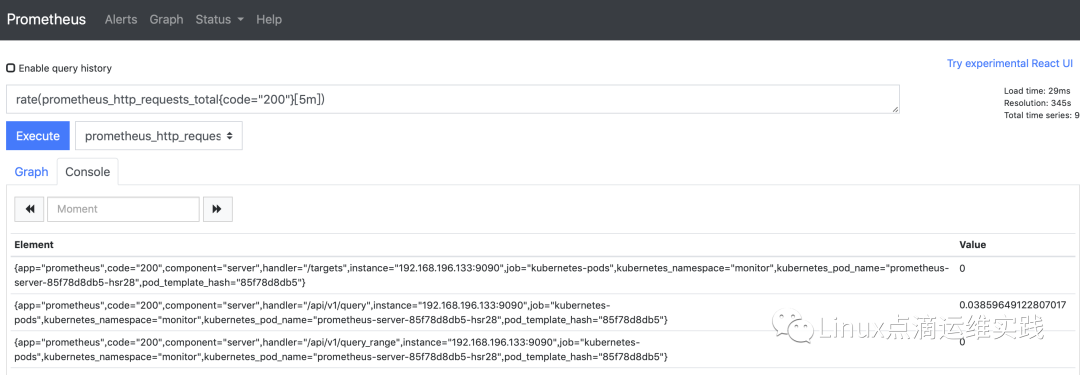
rate(): 计算整个时间范围内区间向量中时间序列的每秒平均增长率;
irate(): 仅使用时间范围中的最后两个数据点来计算区间向量中时间序列的每秒平均增长率, irate 只能用于绘制快速变化的序列,在长期趋势分析或者告警中更推荐使用 rate 函数;
increase(): 计算所选时间范围内时间序列的增量,它基本上是速率乘以时间范围选择器中的秒数;
cAdvisor中获取常用指标说明
| 指标名称 | 类型 | 含义 |
| container_cpu_load_average_10s | gauge | 过去10秒容器CPU的平均负载 |
| container_cpu_usage_seconds_total | counter | 容器在每个CPU内核上的累积占用时间 (单位:秒) |
| container_cpu_system_seconds_total | counter | System CPU累积占用时间(单位:秒) |
| container_cpu_user_seconds_total | counter | User CPU累积占用时间(单位:秒) |
| container_fs_usage_bytes | gauge | 容器中文件系统的使用量(单位:字节) |
| container_fs_limit_bytes | gauge | 容器可以使用的文件系统总量(单位:字节) |
| container_fs_reads_bytes_total | counter | 容器累积读取数据的总量(单位:字节) |
| container_fs_writes_bytes_total | counter | 容器累积写入数据的总量(单位:字节) |
| container_memory_max_usage_bytes | gauge | 容器的最大内存使用量(单位:字节) |
| container_memory_usage_bytes | gauge | 容器当前的内存使用量(单位:字节 |
| container_spec_memory_limit_bytes | gauge | 容器的内存使用量限制 |
| machine_memory_bytes | gauge | 当前主机的内存总量 |
| container_network_receive_bytes_total | counter | 容器网络累积接收数据总量(单位:字节) |
| container_network_transmit_bytes_total | counter | 容器网络累积传输数据总量(单位:字节) |
常用PromQL查询语句
# 容器网络接收的字节数(1分钟内),根据名称查询 name=~".+"
sum(rate(container_network_receive_bytes_total{name=~".+"}[1m])) by (name)
# 容器网络传输的字节数(1分钟内),根据名称查询 name=~".+"
sum(rate(container_network_transmit_bytes_total{name=~".+"}[1m])) by (name)
# 查询容器网络接收量(速率)(单位:字节/秒)
sum(rate(container_network_receive_bytes_total{image!=""}[1m])) without (interface)
# 容器网络传输量 字节/秒
sum(rate(container_network_transmit_bytes_total{image!=""}[1m])) without (interface)
# 查询容器内存使用量(单位:字节)
container_memory_usage_bytes{image!=""}
# 所有容器system cpu的累计使用时间(1min钟内)
sum(rate(container_cpu_system_seconds_total[1m]))
# 每个容器system cpu的使用时间(1min钟内)
sum(irate(container_cpu_system_seconds_total{image!=""}[1m])) without (cpu)
# 每个容器的cpu使用率
sum(rate(container_cpu_usage_seconds_total{name=~".+"}[1m])) by (name) * 100
# 总容器的cpu使用率
sum(sum(rate(container_cpu_usage_seconds_total{name=~".+"}[1m])) by (name) * 100)
# 容器文件系统读取速率 字节/秒
sum(rate(container_fs_reads_bytes_total{image!=""}[1m])) without (device)
# 容器文件系统写入速率 字节/秒
sum(rate(container_fs_writes_bytes_total{image!=""}[1m])) without (device)
Node-exporter 获取常用指标说明
| 指标名称 | 类型 | 含义 |
| node_boot_time | gauge | 启动时间相关 |
| node_cpu_seconds_total | counter | 系统CPU使用量 |
| node_disk_io_now | gauge | 磁盘IO相关 |
| node_disk_read_bytes_total | counter | 磁盘读 |
| node_disk_written_bytes_total | counter | 磁盘写指标 |
| node_filesystem_files | gauge | 文件系统用量 |
| node_load1/node_load5/node_load15 | gauge | 系统1分钟、5分钟、15分钟负载 |
| node_memory_MemTotal_bytes | gauge | 内存使用量 |
| node_memory_SwapTotal_bytes | gauge | Swap使用量 |
| node_network* | counter | 网络带宽相关 |
| node_time_* | counter | 当前系统时间 |
| go_*: | counter/gauge | node exporter中go相关指标 |
| process_* | counter/gauge | node exporter自身进程相关运行指标 |
常用 PromQL语句
# Node 节点内存使用量
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) node_memory_MemTotal_bytes * 100
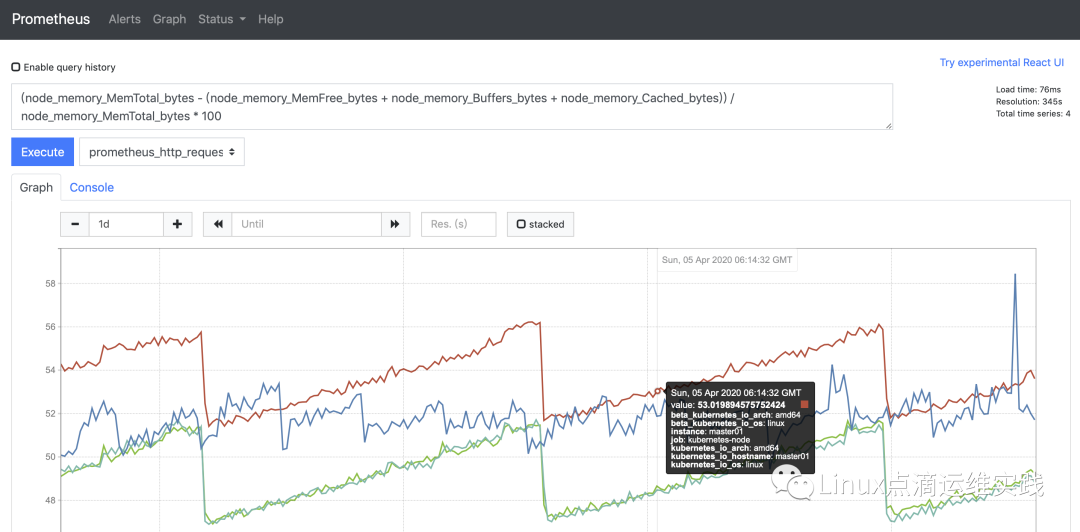
# Node 节点CPU使用率
100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100
# Node 节点启动状态
up == 1为启动,0为停止
# Node 节点IO性能
100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100)
# Node 节点网卡出访流量
((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) 100)
# Node 节点 TCP 会话处于established状态
node_netstat_Tcp_CurrEstab
# Node 节点磁盘使用量
100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100)
kube-state-metrics 监控指标类别
pod metrics、service metrics、endpoint metrics、node metrics 、namespace metrics、job metrics等,都是以 kube_*开头的监控指标。
常用 PromQL语句
# 查看Pod的重启状态
kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor"}
# 查看 Pod 是否处于 waiting 状态
kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"}
# 查看 Pod 是否处于 terminated 状态
kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor"} == 1
# 查看 endpoint 是否为不ready状态
kube_endpoint_address_not_ready{namespace=~"kube-system|default|monitor"}
# 查看 namespace 有哪些
kube_namespace_labels
# 查看 service 的标签(前提是这些service 要暴露metrics接口)
kube_service_labels{kubernetes_namespace="kube-system"}
# 集群节点状态错误
kube_node_status_condition{condition="Ready",status!="true"}==1
# 集群中存在启动失败的Pod
kube_pod_status_phase{phase=~"Failed|Unknown"}==1
# 最近30分钟内有Pod容器重启
changes(kube_pod_init_container_status_restarts_total[30m])>0
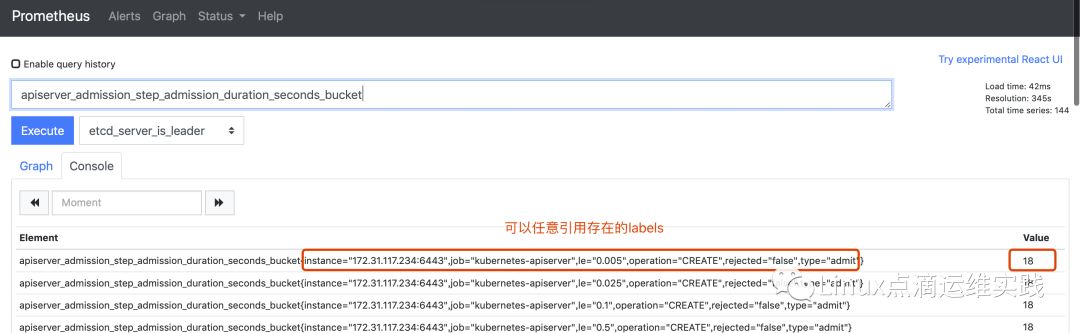
kube-apiserver 获取常用指标说明
常用 PromQL语句
# kubernetes-apiserver CPU使用率
rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80
# kubernetes-apiserver 打开文件句柄数
process_open_fds{job=~"kubernetes-apiserver"}
# kubernetes-apiserver 使用虚拟内存
process_virtual_memory_bytes{job=~"kubernetes-apiserver"}
# kubenetes-apiserver TPS统计
sum(rate(rest_client_requests_total{job=~"kubernetes-apiserve|kube-controller-manager|kube-scheduler|kube-proxy"}[1m]))
etcd 、kube-proxy等等都监控到一些指标数据,我们可以通过Prometheus WebUI查看,并结合 PromQL 语法自己编写一些查询规则,这些规则尽而可以转化为报警规则,还可以转化为grafana出图的规则语句,所以说 PromQL 语法一定要掌握。
配置 Rule 规则
1. 为每个规则起一个有意义的名字;
2. 使用 PromQL 编写一条表达式,使其在不符合预期时,达到触发报警条件;
3. for字段,上面expr表达式,维持多久,才触发报警;
4. labels 标签意义很重要,可用于报警分组;
5. 报警注解中,可以引用一些labels变量标签或者value等;
总结
# HELP node_timex_pps_error_total Pulse per second count of calibration errors.
# TYPE node_timex_pps_error_total counter复制
每个监控指标中前都有两行注释,一行说明这个监控指标的含义是什么,一行说明监控指标的类型;我们通过监控指标的类型,结合 PromQL 语法以及内置函数,编写一些常用查询语句、聚合语句,进而转化为定义报警规则的表达式或者 grafana 展示所用的语句等。

您的关注是我写作的动力

往期分享
kubeadm使用外部etcd部署kubernetes v1.17.3 高可用集群
第三篇 安装 Prometheus/Alertmanager/Grafana
第四篇 详解使用relabel_configs进行动态服务发现k8s 资源
